SQL과 pandas에서는 두 개 이상의 칼럼을 기준으로 JOIN 혹은 merge가 가능하다.
기준이 되는 칼럼을 여러개 지정하면, 각 기준 칼럼의 값이 모두 동일한 행끼리 조인된다.
이는 DB에서 복합 키(composite key)와 유사한 개념이다.
예시
Data Frame 1
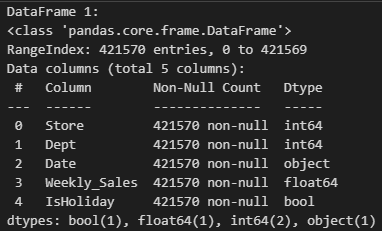
Data Frame 2
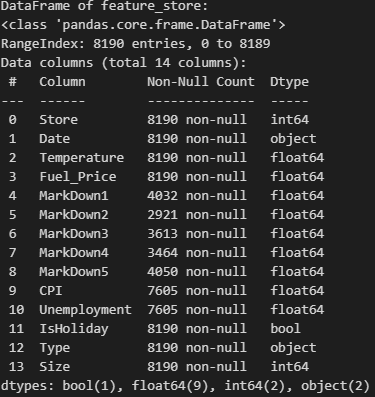
위 데이터 프레임에서 겹치는 칼럼은 총 3개다. [Store', 'Date', 'IsHoliday']
- join에 3개 전부 사용할 때
- 2개만 사용할 때
- 1개만 사용할 때
각각의 차이를 알아보자.
복수의 칼럼 조인 on=['Store', 'Date', 'IsHoliday']
- 데이터: 40만 행
DF1 과 DF2에서 'Store', 'Date', 'IsHoliday' 칼럼의 값이 모두 동일한 행끼리 조인된다.
따라서 정확히 일치하는 데이터가 필요한 분석에 적합하다.
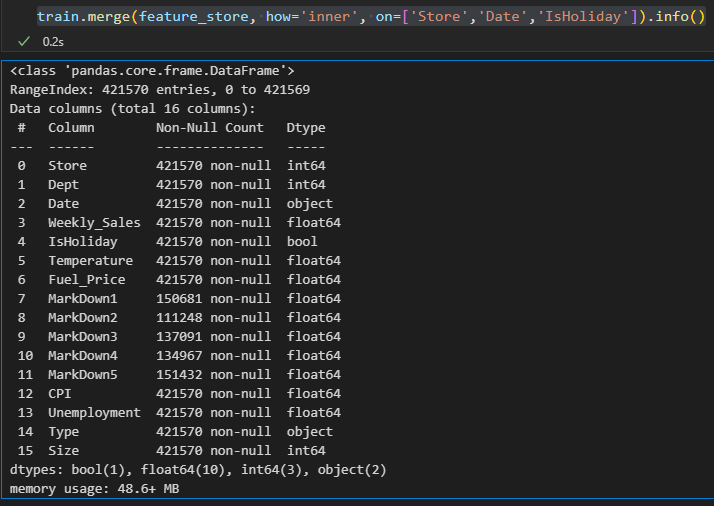
데이터 손실을 최소화하면서도 정확한 데이터 매칭을 제공한다.
두개의 칼럼 조인 on=['Store', 'Date']
- 데이터: 40만 행
두개의 칼럼 값이 동일한 행들끼리 조인되며 같은 store와 date 행이 여러개 있을 경우 각 행이 모두 결합되어 조합이 더 많아질 수 있다.
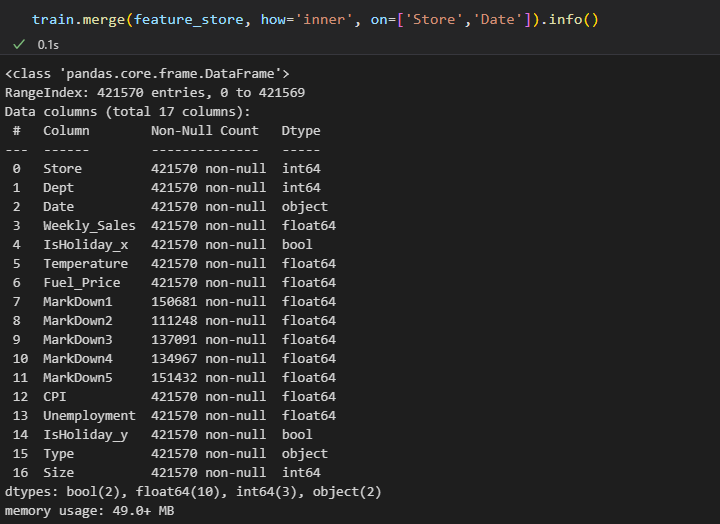
하나의 Store에서 같은 Date에 IsHoliday가 true, false값이 모두 존재하면 더 많은 행이 생겨나게 된다.
예시로 들었던 DF1과 DF2에서는 같은 가게, 같은 날에 2개의 IsHoliday값이 없어 동일하지만,
만약 IsHoliday같은 boolean 데이터가 아니라 수치형 데이터라면 행의 개수가 굉장히 많이 증가할 것이다.
하나의 칼럼 조인 on=['Store']
- 데이터: 7672만 행
엄청나게 많은 중복 행이 포함될 수 있다.
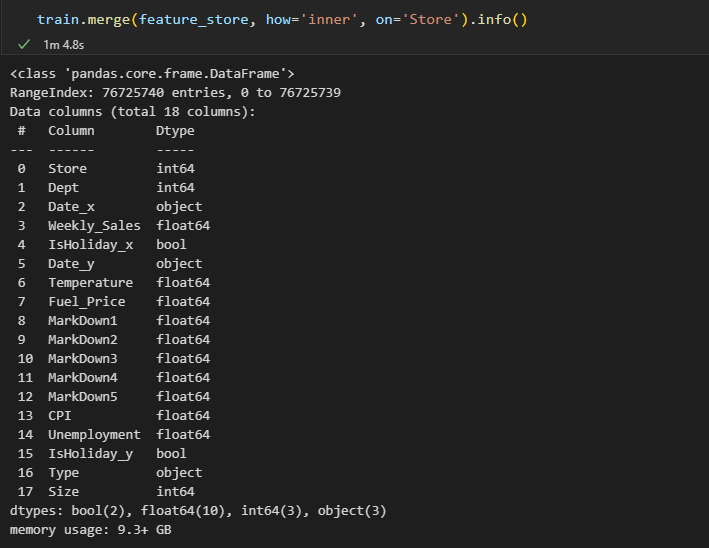
동일한 가게이지만 거래가 이뤄진 날짜가 모두 다를 수 있으며, IsHoliday여부가 다르다면 그 모든 경우의 수가 전부 조합으로 책정되어 데이터가 늘어나기 때문이다.
결과적으로 의미 있는 매칭이 이루어지지 않을 가능성이 높아진다.
요약
- 세 개의 열 (Store, Date, IsHoliday)로 조인:
가장 정확한 매칭 결과를 얻을 수 있습니다. 동일한 날짜와 공휴일 상태에서 정확한 상점 데이터를 결합합니다. - 두 개의 열 (Store, Date)로 조인:
행 수가 증가하고, 동일한 날짜에 다른 공휴일 상태의 데이터가 섞일 수 있어 매칭 정확도가 떨어질 수 있습니다. - 한 개의 열 (Store)로 조인:
조인 결과에 매우 많은 중복이 발생할 수 있으며, 데이터 매칭이 부정확할 가능성이 큽니다. Date와 IsHoliday 정보가 뒤섞여 잘못된 분석을 초래할 수 있습니다.
만약 조인하고자 하는 대상 DF가 동일한 데이터 타입의 칼럼을 복수개 가지고 있다면, 해당 칼럼들을 전부 사용하여 merge해야 정확한 결합값을 제공받을 수 있다.
