1
책 보면서 하는건 잘 기억이 안난다.
실무에 바로바로 찾아 쓰면서 실험적으로 공부 하는게 훨씬 기억에 잘 남는다!
위 사항을 반영한 커리큘럼이다.
파이썬은 한줄씩 한줄씩 사용해볼수도 있다.
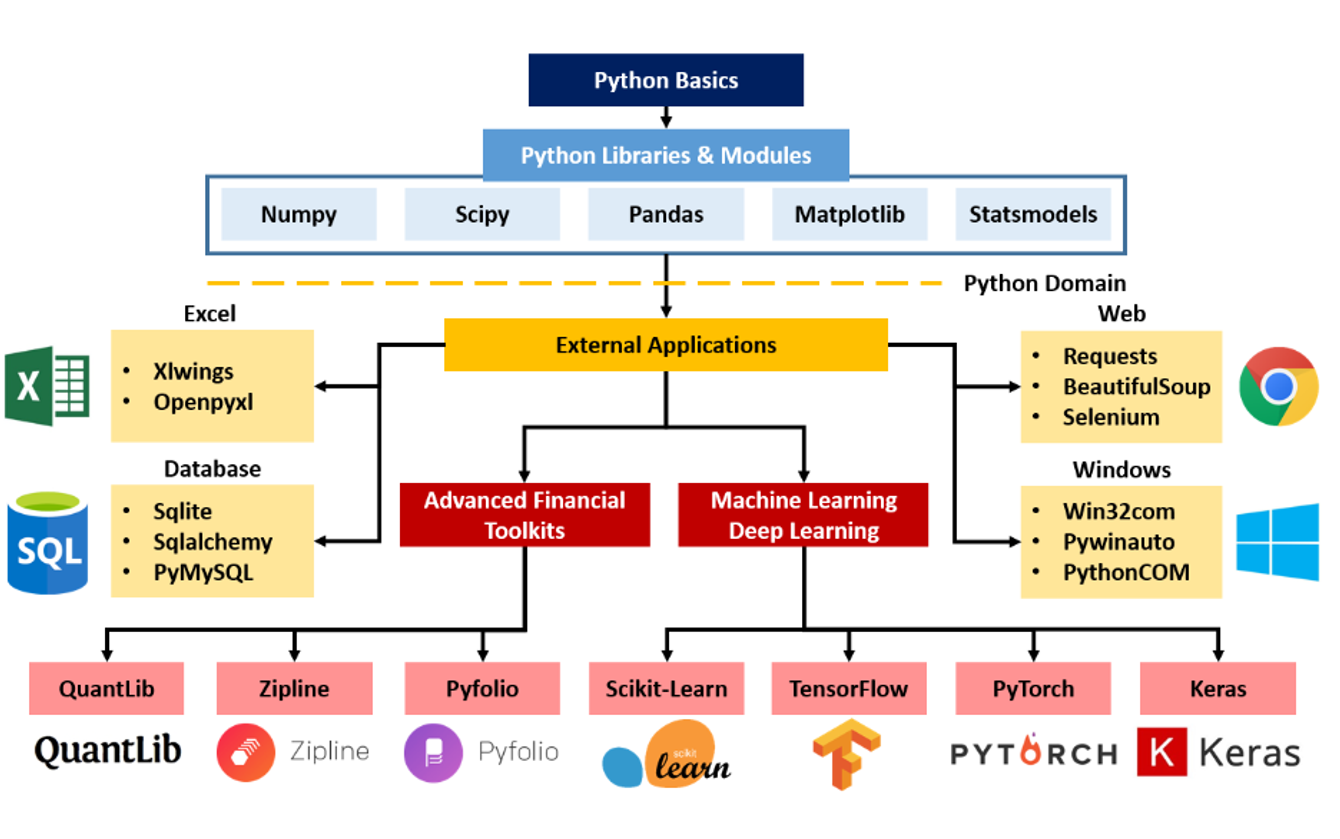
전부 파이썬으로 짜여져 있다.
데이터 분석의 모든 과정에서 파이썬이 사용된다.
colab은 google drive에 보든 코드와 파일을 저장한다.
🟧 Colab 주요 단축키
- 코드 실행: 코드 셀을 실행하려면
Shift + Enter를 누릅니다. - 새 코드 셀 추가: 코드 셀을 추가하려면 코드 셀 위에서
Ctrl + M + A(Windows 및 Linux) 또는Command + M + A(Mac)를 누릅니다. - 코드 셀 삭제: 코드 셀을 삭제하려면 코드 셀 위에서
Ctrl + M + D(Windows 및 Linux) 또는Command + M + D(Mac)를 누릅니다. - 코드 셀 분할: 코드 셀을 분할하려면 코드 셀 위에서
Ctrl + M + 하이픈(-)(Windows 및 Linux) 또는Command + M + 하이픈(-)(Mac)을 누릅니다. - 마크다운: 코드 셀을 마크다운 셀로 변경하려면 코드 셀 위에서
Ctrl + M + M(Windows 및 Linux) 또는Command + M + M(Mac)를 누릅니다. - Ctrl(Command) + Enter : 해당 셀 실행
- Shift + Enter : 해당 셀 실행 + 커서를 다음 셀로 이동
- Alt(Option) + Enter : 해당 셀 실행 + 코드 블록 하단 추가
🟧 변수와 데이터타입
변수 선언
배수를 구할 때 % 를 많이 사용한다.
num1 % num2(3) 을 해서 num1을 반복문으로 계속 돌려 값이 0인 경우만 선택하면
3의 배수를 구할 수 있다.
절대값 구하기:
round로 반올림 하기 .
integer + float = float
boolean
: T / F
NaN 결측값은 자료형은 아니다!
missing value임, not a number.
머신러닝에서 NaN 값이 있으면 아예 돌아가지 않음. 중요하게 알아야 한다.
O으로 나누는 연산, 결측치. -3의 제곱근 등에서 발생
입력문 input()
int() 를 사용하여 정수로 만들어주기
근데 숫자여야 함.
문자 형태의 숫자도 가능
🟧 숫자열 연산
# 숫자열 연산
sum_result = num1 + num2
diff_result = num1 - num2
product_result = num1 * num2
division_result = num1 / num2
integer_division_result = num1 // num2
remainder_result = num1 % num2
print("합:", sum_result)
print("차:", diff_result)
print("곱:", product_result)
print("나누기:", division_result)
print("정수 나누기:", integer_division_result)
print("나머지:", remainder_result)🟧 숫자열과 함수 매서드
abs() : 절댓값 반환
round() : 반올림
등등
# 숫자열 함수와 메서드 활용
num3 = -7.89
abs_result = abs(num3) # 절댓값 계산
round_result = round(num3) # 반올림 계산
print("절댓값:", abs_result)
print("반올림:", round_result)🟧 NaN (결측값)
데이터의 결측치(Missing Value)를 나타내는 값이다.
주로 수치형 데이터에서 발생, 머신러닝 분야에서 데이터 정제 과정에서 자주 다뤄진다.
NaN에 대한 설명
-
NaN은 정의할 수 없는 수치값을 나타냅니다. 예를 들어, 0으로 나누는 연산이나 유효하지 않은 수학적 연산 결과를 나타낼 때 사용됩니다.
-
데이터프레임과 같은 데이터 구조에서는 결측치를 표현할 때 NaN이 사용됩니다.
-
in 수학 연산
# 0으로 나누는 연산
result = 1 / 0
print(result) # 출력: Infinity
import math
# 유효하지 않은 수학적 연산
result = math.sqrt(-1)
print(result) # 출력: nan- in Data Frame
import pandas as pd
# NaN을 포함한 데이터프레임 생성
data = {'A': [1, 2, None],
'B': [3, None, 5]}
df = pd.DataFrame(data)
print(df)
# 출력:
# A B
# 0 1.0 3.0
# 1 2.0 NaN
# 2 NaN 5.0🟧 input()
input() 함수는 사용자로부터 키보드로 입력을 받는 함수다.
name = input("이름을 입력하세요: ")
print("안녕하세요,", name, "님!")marines = input("매끼야!?!")
print("필승!", marines," 입니다! 똑바로 하겠습니다!")
출력
매끼야!?! <- 1144기 입력 후 enter
필승! 1144기 입니다! 똑바로 하겠습니다!num1 = int(input("첫 번째 숫자를 입력하세요: "))
num2 = int(input("두 번째 숫자를 입력하세요: "))
sum = num1 + num2
print("두 숫자의 합은", sum, "입니다.")변수 형태를 맞춰야 하는 이유
age_girl = input("여자친구가 몇 살이죠?")
age_boy = input("친구는 몇 살이죠?")
궁합 = print("당신과 여자친구는", age_girl + age_boy, "점 궁합입니다! ")위 코드에서 age_boy <- 10, age_girl <- 20 을 넣으면 결과는 1020이 나온다.
이는 문자열str끼리의 덧셈이 수행된 결과이다. 우리가 원하는 값은 10+20=20이다.
이러한 문제는 int()함수를 통해 input값을 정수형으로 변환해줌으로써 해결이 가능하다.
age_girl = int(input("여자친구가 몇 살이죠?"))
age_boy = int(input("친구는 몇 살이죠?"))
궁합 = print("당신과 여자친구는", age_girl + age_boy, "점 궁합입니다! ")위 코드는 input함수 작동 시 입력되는 변수의 값을 int 즉, 정수형으로 변환하기 때문에 입력값 끼리의 덧셈이 잘 수행된다.
2
🟧 리스트, 튜블, 딕셔너리
이 세가지 형태 중 하나를 거의 사용한다.
가장 비중이 높은 것은 리스트.
리스트와 튜플의 차이점?
거의 비슷한데 다름.
많은 데이터를 다뤄야 하기 때문에 이를 알아야 한다.
많은 데이터를 일일이 변수 안에 담는다? 말이 안된다.
이들을 다루는 문법을 공부하자.
담고, 정리하고, 꺼낼때 필요하다.
🟧 리스트의 기본 사용법
sequence 타입, 순서대로 담는다.
앵간하면 다 리스트다.
** 대괄호를 사용[ ]
** indexing
python에서 첫번째는 0임.
뒤에서 첫번째는 -1임.
리스트의 다양한 메서드(Methods)
- 리스트에 대해 유용한 여러 가지 메서드를 소개합니다.
append(): 리스트에 항목을 추가합니다. 무조건 맨 뒤. ⭐extend(): 리스트에 다른 리스트의 모든 항목을 추가합니다. 무조건 맨 뒤.insert(): 리스트의 특정 위치에 항목을 삽입합니다. 원하는 위치!remove(): 리스트에서 특정 값을 삭제합니다.pop(): 리스트에서 특정 위치의 값을 제거하고 반환합니다.index(): 리스트에서 특정 값의 인덱스를 찾습니다.count(): 리스트에서 특정 값의 개수를 세어줍니다.sort(): 리스트의 항목들을 정렬합니다.reverse(): 리스트의 항목들을 역순으로 뒤집습니다.- 참고!) ‘반환’이라는 표현은 함수의 결과 값을 밖으로 끄집어 낸다라는 것을 의미합니다. 이에 대한 자세한 내용은 함수에서 다루게 됩니다! 여기서는 ‘결과 값을 얻어냈다’ 정도로만 이해하셔도 충분합니다 🙂
# 리스트 생성
my_list = [1, 2, 3, 4, 5]
#리스트의 다양한 메서드(Methods)
my_list.append(6) # 리스트에 새로운 항목 추가
print(my_list) # 출력: [1, 2, 3, 4, 5, 6]
my_list.extend([7, 8, 9]) # 다른 리스트의 모든 항목을 추가
print(my_list) # 출력: [1, 2, 3, 4, 5, 6, 7, 8, 9]
my_list.insert(2, 10) # 두 번째 위치에 값 삽입
print(my_list) # 출력: [1, 2, 10, 3, 4, 5, 6, 7, 8, 9]
my_list.remove(3) # 값 3 삭제
print(my_list) # 출력: [1, 2, 10, 4, 5, 6, 7, 8, 9]
popped_value = my_list.pop(5) # 다섯 번째 위치의 값 제거하고 반환
print(popped_value) # 출력: 6
print(my_list) # 출력: [1, 2, 10, 4, 5, 7, 8, 9]
print(my_list.index(4)) # 출력: 3 (값 4의 인덱스)
print(my_list.count(7)) # 출력: 1 (값 7의 개수)
my_list.sort() # 리스트 정렬
print(my_list) # 출력: [1, 2, 4, 5, 7, 8, 9, 10]
my_list.reverse() # 리스트 역순으로 뒤집기
print(my_list) # 출력: [10, 9, 8, 7, 5, 4, 2, 1]다 colab에서 직접 돌려보고, 외우지 말고 그냥 이해하고 넘어가라.
리스트 값 삭제 remove, pop +
"몇 번째의 값을 제거할 것이냐??"
dell
"다 삭제해부러"
clear
리스트 값 변경
첫 번째 값 변경
my_list[0] = 8
0번째 리스트 값이 8로 바뀜
my_list = ['apple', 'banana', 'cherry', 'date', 'elderberry']
# 리스트 값 변경하기
my_list[3] = 'dragonfruit'
print(my_list) # 출력: ['apple', 'banana', 'cherry', 'dragonfruit', 'elderberry']중첩된 리스트 indexing
걍 순서대로 조지면 됨.
# 중첩된 리스트에서 인덱싱하기
nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
print(nested_list[1][0]) # 출력: 4 (두 번째 리스트의 첫 번째 항목)🟧 리스트 고급 사용법
Slicing⭐
인덱싱이랑 다르게 리스트 속 여러개의 값을 범위 설정(slicing)을 통해 뽑아온다.
sliced_list = list[start:end:(step)]
sliced_list = list[이상:미만:(step)]
step은 필수가 아님.
보편적으로는 start와 end만 쓰인다.
⭐요놈 헷갈릴듯 ㅎ
end는 +1 해야함. ㅋㅋ "미만" 값임.
0부터 12번째까지를 원하면 list[0:13] 해야함
slicing은 음수 사용 시 "부터"오른쪽으로 진행됨.
indecing 에서는 음수 사용 시 "부터"왼쪽 이었는디
정방향 슬라이싱 이해 똑바로 해라.
my_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 1. 일부분만 추출하기
print(my_list[2:5]) # 출력: [3, 4, 5]
# 2. 시작 인덱스 생략하기 (처음부터 추출)
print(my_list[:5]) # 출력: [1, 2, 3, 4, 5]
# 3. 끝 인덱스 생략하기 (끝까지 추출)
print(my_list[5:]) # 출력: [6, 7, 8, 9, 10]
# 4. 음수 인덱스 사용하기 (뒤에서부터 추출)
print(my_list[-3:]) # 출력: [8, 9, 10]
# 5. 간격 설정하기 (특정 간격으로 추출)
print(my_list[1:9:2]) # 출력: [2, 4, 6, 8]
# 6. 리스트 전체를 복사하기
copy_of_list = my_list[:]
print(copy_of_list) # 출력: [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 7. 리스트를 거꾸로 뒤집기
reversed_list = my_list[::-1] #-2 도 해봐
print(reversed_list) # 출력: [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
# slicing에서 -는 거의 안쓰니까 이해하고 넘어가라. 정렬 method
sort() :
- 기존 리스트를 오름차순으로 정렬, 새롭게 정렬된 리스트를 반환하지 않음.
- 리스트의 항목들이 동일한 형태일 경우에만 정렬됨.
reverse: False-오름차순, True-내림차순
my_list.sort(reverse=False)# 숫자로 이루어진 리스트 정렬 예시
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5]
numbers.sort()
print("정렬된 리스트:", numbers) # 출력: [1, 1, 2, 3, 4, 5, 5, 6, 9]
# 문자열로 이루어진 리스트 정렬 예시
words = ['apple', 'banana', 'orange', 'grape', 'cherry']
words.sort()
print("정렬된 리스트:", words) # 출력: ['apple', 'banana', 'cherry', 'grape', 'orange']
# 내림차순으로 리스트 정렬 예시
numbers = [3, 1, 4, 1, 5, 9, 2, 6, 5]
numbers.sort(reverse=True)
print("내림차순으로 정렬된 리스트:", numbers) # 출력: [9, 6, 5, 5, 4, 3, 2, 1, 1]
# 리스트의 문자열 길이로 정렬 예시
words = ['apple', 'banana', 'orange', 'grape', 'cherry']
words.sort(key=len)
print("문자열 길이로 정렬된 리스트:", words) # 출력: ['apple', 'grape', 'banana', 'cherry', 'orange']오름차순 내림차순 으로 정렬하는거 중심으로 해봐라
테스트, 검증 데이터 슬라이싱으로 나누기 ㅎㅎ
from sklearn.datasets import load_iris
# Iris 데이터셋 불러오기
iris = load_iris()
# Iris 데이터셋에서 특정 범위의 데이터 슬라이싱하기
train_data = iris.data[:100] # 인덱스 0부터 99까지의 데이터 추출
print("학습 데이터:", train_data)
test_data = iris.data[100:] # 인덱스 100부터 끝까지의 데이터 추출
print("학습 데이터:", test_data)🟧 튜플
튜플: 변경할 수 없는 시퀀스 자료형/ 소괄호 사용 ()
리스트: 변경할 수 있는 시퀀스 자료형
--> 데이터를 보호하고 싶을 때 주로 튜플 형태로 데이터를 저장한다.
my_tuple = (1, 2, 3, 'hello', 'world')튜플의 indexing, slicing
⭐Indexing
리스트와 똑같아.
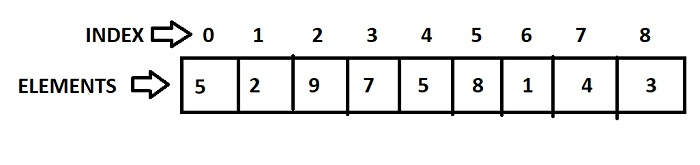
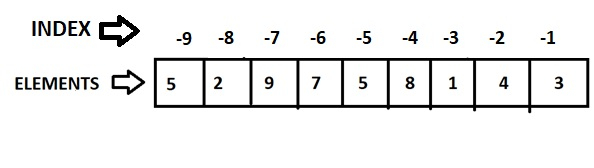
추가, 삭제, 수정은 불가능
⭐Slicing
- 구조:
tuple[Start : Stop : Stride]
ex1
my_tuple = (1, 2, 3, 'hello', 'world')
print(my_tuple[0]) # 첫 번째 요소에 접근
print(my_tuple[-1]) # 마지막 요소에 접근
print(my_tuple[2:4]) # 인덱스 2부터 3까지의 요소를 슬라이싱ex2
my_tuple = ('red', 'green', 'blue', 'yellow')
my_tuple[::-1] # 뒤로 한 단계씩 이동튜플 매서드
count(): 지정된 요소의 개수 반환index(): 지정된 요소의 인덱스 반환
append 같은 건 없다. 변형되니까
다른것들 좀 보고 돌려봐라..
# 튜플 생성
my_tuple = (1, 2, 3, 4, 1, 2, 3)
# count() 메서드 예제
count_of_1 = my_tuple.count(1)
print("Count of 1:", count_of_1) # 출력: 2
# index() 메서드 예제
index_of_3 = my_tuple.index(3)
print("Index of 3:", index_of_3) # 출력: 2튜플 vs 리스트
튜플의 불변성
- 튜플 안에 있는 값을 임의로 수정할 수 없다.
튜플 합치기, 반복하기 가능
tuple1 = (1, 2, 3)
tuple2 = ('a', 'b', 'c')
new_tuple = tuple1 + tuple2 # 두 개의 튜플을 합치기
print(new_tuple)
repeated_tuple = tuple1 * 3 # 튜플을 반복하기
print(repeated_tuple)튜플과 리스트 상호변환
수정이 필요하면 list()써서 리스트로 바꾸고
불변성이 필요하면 tuple()써서 튜플로 잠궈라
튜플에 list()함수를 사용해서 리스트로 바꿨으면 "="를 통한 assignment를 까먹으면 안된다.
# 튜플을 리스트로 변경하기
my_tuple = (1, 2, 3, 4, 5)
my_list = list(my_tuple) #💡assignment 까먹지 마라
print(my_list) # 출력: [1, 2, 3, 4, 5]
# 리스트를 튜플로 변경하기
my_list = [1, 2, 3, 4, 5]
my_tuple = tuple(my_list)
print(my_tuple) # 출력: (1, 2, 3, 4, 5)자유자재로 변경 가능.
🟧 Dictionary
key는 중복될 수 없다.
value는 상관없음.
dictionary는 indexing을 하지 않는다.
key를 넣어서 value를 뽑아낼 뿐.
- 기본 구조
my_dict = {
'key1': 'value1',
'key2': 'value2',
'key3': 'value3'
}- 기본 활용
# 빈 딕셔너리 생성
empty_dict = {}
# 학생 성적표
grades = {
'Alice': 90,
'Bob': 85,
'Charlie': 88
}
# 접근하기
print(grades['Alice']) # 출력: 90
# 값 수정하기
grades['Bob'] = 95
# 요소 추가하기
grades['David'] = 78
# 요소 삭제하기
del grades['Charlie']Dictionary 메서드
keys(): 모든 키를 dict_keys 객체로 반환합니다.values(): 모든 값을 dict_values 객체로 반환합니다.items(): 모든 키-값 쌍을 (키, 값) 튜플로 구성된 dict_items 객체로 반환합니다.get(): 지정된 키에 대한 값을 반환합니다. 키가 존재하지 않으면 기본값을 반환합니다.pop(): 지정된 키와 해당 값을 딕셔너리에서 제거하고 값을 반환합니다.popitem(): 딕셔너리에서 마지막 키-값 쌍을 제거하고 반환합니다.
# 딕셔너리 생성
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# keys() 메서드 예제
keys = my_dict.keys()
print("Keys:", keys) # 출력: dict_keys(['name', 'age', 'city'])
# values() 메서드 예제
values = my_dict.values()
print("Values:", values) # 출력: dict_values(['John', 30, 'New York'])
# items() 메서드 예제
items = my_dict.items()
print("Items:", items) # 출력: dict_items([('name', 'John'), ('age', 30), ('city', 'New York')])
# get() 메서드 예제
age = my_dict.get('age')
print("Age:", age) # 출력: 30
# pop() 메서드 예제
city = my_dict.pop('city')
print("City:", city) # 출력: New York
print("Dictionary after pop:", my_dict) # 출력: {'name': 'John', 'age': 30}
# popitem() 메서드 예제
last_item = my_dict.popitem()
print("Last item popped:", last_item) # 출력: ('age', 30)
print("Dictionary after popitem:", my_dict) # 출력: {'name': 'John'}```list에 append()
list.append() 대괄호 아니고 소괄호, 소괄호 안에 append 하고 싶은 값을 넣는다.
그럼 list 맨 오른쪽에 추가된다.
조건문은 코딩을 많이 해봐야한다.
데이터 분석을 할 때 항상 어떤 조건에 따라 데이터를 분류하는 일을 하게 된다.
그냥 데이터 분석 그 자체
많이 실험해봐라.
마스터하자
반복문, FOR, WHILE
APPEND() 리스트에 값 넣는거 진짜 중요함
items? dictionary의 쌍 들을 나타내는듯. 확인이 필요함
while은 무한반복을 조심해라.
3 데이터 분석 파이썬 종합반
조건문
: 특정 조건이 참(True)인 경우에만 특정 코드 블록을 실행
: if, elif, else
if 조건:
# 조건이 참일 때 실행될 코드
elif 다른조건:
# 다른 조건이 참일 때 실행될 코드
else:
# 위의 조건이 모두 거짓일 때 실행될 코드반복문 (for, while)
for문:
for 변수 in 반복할_데이터:
코드_블록반복할_데이터: 리스트, 튜플, 문자열 등 반복 가능한(iterable)데이터 타입
변수: 각 반복마다 현재 값을 가지는 변수
- 리스트 순회
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)- 문자열 순회
for letter in "hello":
print(letter)while문:
while 조건:
코드_블록조건: True / False. True로 평가될 때까지 코드 블록이 반복적으로 실행.
- 1 부터 5 까지 출력
i = 1
while i <= 5:
print(i)
i += 1 # i = i + 1- 사용자 입력 받기
user_input = ''
while user_input != 'quit':
user_input = input("Type 'quit' to exit: ")
print("You typed:", user_input)-break 문 사용해서 while 루프 끝내기
while True:
user_input = input("Type 'quit' to exit: ")
if user_input == 'quit':
break
print("You typed:", user_input)반복문 실전예제: 데이터 정제 및 전처리
# 결측치 처리 예시
data = [10, 20, None, 30, 40, None, 50]
cleaned_data = []
for d in data:
if d is not None:
cleaned_data.append(d)
print(cleaned_data)💡 range() 함수
: 연속된 정수를 생성하는 내장 함수
반복문, 특히 for 루프와 함께 자주 사용된다.
- range(stop)
# 0부터 시작하여 5 이전까지의 정수 시퀀스 생성
for i in range(5):
print(i, end=' ')
# 출력: 0 1 2 3 4- range(start, stop)
# 2부터 시작하여 7 이전까지의 정수 시퀀스 생성
for i in range(2, 7):
print(i, end=' ')
# 출력: 2 3 4 5 6- range(start, stop, step)
# 1부터 시작하여 10 이전까지 2씩 증가하는 정수 시퀀스 생성
for i in range(1, 10, 2):
print(i, end=' ')
# 출력: 1 3 5 7 9dictionary 순회
person = {"name": "John", "age": 30, "city": "New York"}
for key, value in person.items():
print(key, " : ", value)- items(): 모든 키-값 쌍을 (키, 값) 튜플로 구성된 dict_items 객체로 반환합니다.
조건문과 반복문 사용
- 짝홀수 출력하기: 1~10까지의 숫자 중 짝수와 홀수를 모두 출력한 뒤 이름을 붙여준다.
for i in range(1, 11):
if i % 2 == 0:
print(i, "짝수")
else:
print(i, "홀수")- 1부터 50까지의 숫자 중 3의 배수 출력하기
# 1부터 50까지의 숫자 중 3의 배수 출력하기
for i in range(1, 51):
if i % 3 == 0:
print(i)- 특정 값 걸러내기 / append()
# 1: 리스트에서 홀수 걸러내기
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
odd_numbers = []
for num in numbers:
if num % 2 == 1:
odd_numbers.append(num)
print(odd_numbers)# 2: 범위 안에 있는 홀수 리스트 만들기
even_numbers = []
for i in range(1,100):
if i % 2 == 0:
even_numbers.append(i)
print(even_numbers)-구구단 만들기
# 조건문과 반복문을 복합적으로 활용하여 구구단 출력
for i in range(2, 10):
print(f"{i}단:")
for j in range(1, 10):
print(f"{i} x {j} = {i*j}")연산자
- 비교연산자: 조건을 판단
- > : 초과
- < : 미만
- >= : 이상
- <= : 이하
- == : 같음
- != : 같지 않음
- 논리연산자: 조건을 결합
- and : 모두 참일 때 참
- or : 하나 이상이 참일 때 참
- not : 조건을 부정
x = 9
if x > 0 and x % 3 == 0:
print("3의 배수입니다")
else:
print("3의 배수가 아닙니다")다중조건식 예시
x = 10
y = 5
if x > 5 and y < 10:
print("x는 5보다 크고, y는 10보다 작습니다.")
elif x <= 5 or y > 10:
print("x는 5보다 작거나 같거나, y는 10보다 큽니다.")
else:
print("다른 조건")4 데이터 분석 파이썬 종합반
함수
https://teamsparta.notion.site/SCC-e71a79753e3e4e31a2048f74946542df
def 함수이름(매개변수1, 매개변수2, ...):
# 함수 내부에서 수행할 작업
return 결과값 # (선택적) 함수의 결과를 반환- 예시
# 함수 정의
def greet(name):
message = "Hello, " + name + "!"
return message
# 함수 호출
greeting = greet("Alice")
print(greeting) # 출력: Hello, Alice!- 숫자 리스트에서 최대값을 찾는 함수
def find_max(numbers):
max_num = numbers[0] # 첫 번째 요소를 초기 최대값으로 설정
for num in numbers:
if num > max_num: # 현재 요소가 max_num보다 크면
max_num = num # max_num을 현재 요소로 업데이트
return max_num
# 함수 호출
print(find_max([3, 7, 2, 9, 5])) # 출력: 9위 코드에서 max_num = numbers[0] 부분을 잘 이해하라.
max_num 이라는 변수에 numbers[0]을 넣는다는 것은 숫자0을 넣는 것이 아니다.
numbers 리스트[3, 7, 2, 9, 5] 의 첫 번째 숫자 즉, 3을 넣는 것이다.
그리고 for 문을 순회하며 더 큰 값이 발견되면 그 자리를 바꿔주는 순서이다.
- 실습 평균값 구하는 함수 생성하기
data = [2, 5, 6, 3, 4, 5, 6, 20]
def calculator_mean(x):
total = sum(x)
total_len = len(x)
average = total / total_len
return average
result = calculator_mean(data)
print(f"해당 리스트의 평균값은 {result}입니다")