
웹 크롤링(Web Crawling) / 웹 스크래핑(Web Scraping)
HTML에서 원하는 데이터를 추출하기 위해 사용되는 패키지
Beautiful Soup 시작
파이썬의 Package Manager인 PIP를 이용하여 Beautiful Soup을 설치한다
>> pip install bs4
from bs4 import BeautifulSoup사이트의 정보를 가져오기 위해선 requests가 필요하다
>> pip install requests
import requestsHTML Parsing
import requests
from bs4 import BeautifulSoup
url = "https://python.flowdas.com/tutorial/index.html"
data = requests.get(url)
soup = BeautifulSoup(data.text, "html.parser")requests로 해당 사이트의 요청이 성공하면(response 200) beautifulsoup으로 해당 사이트의 HTML을 parsing할 수 있다
✨Scraping

개발자도구로 해당 HTML의 구조를 확인해본다
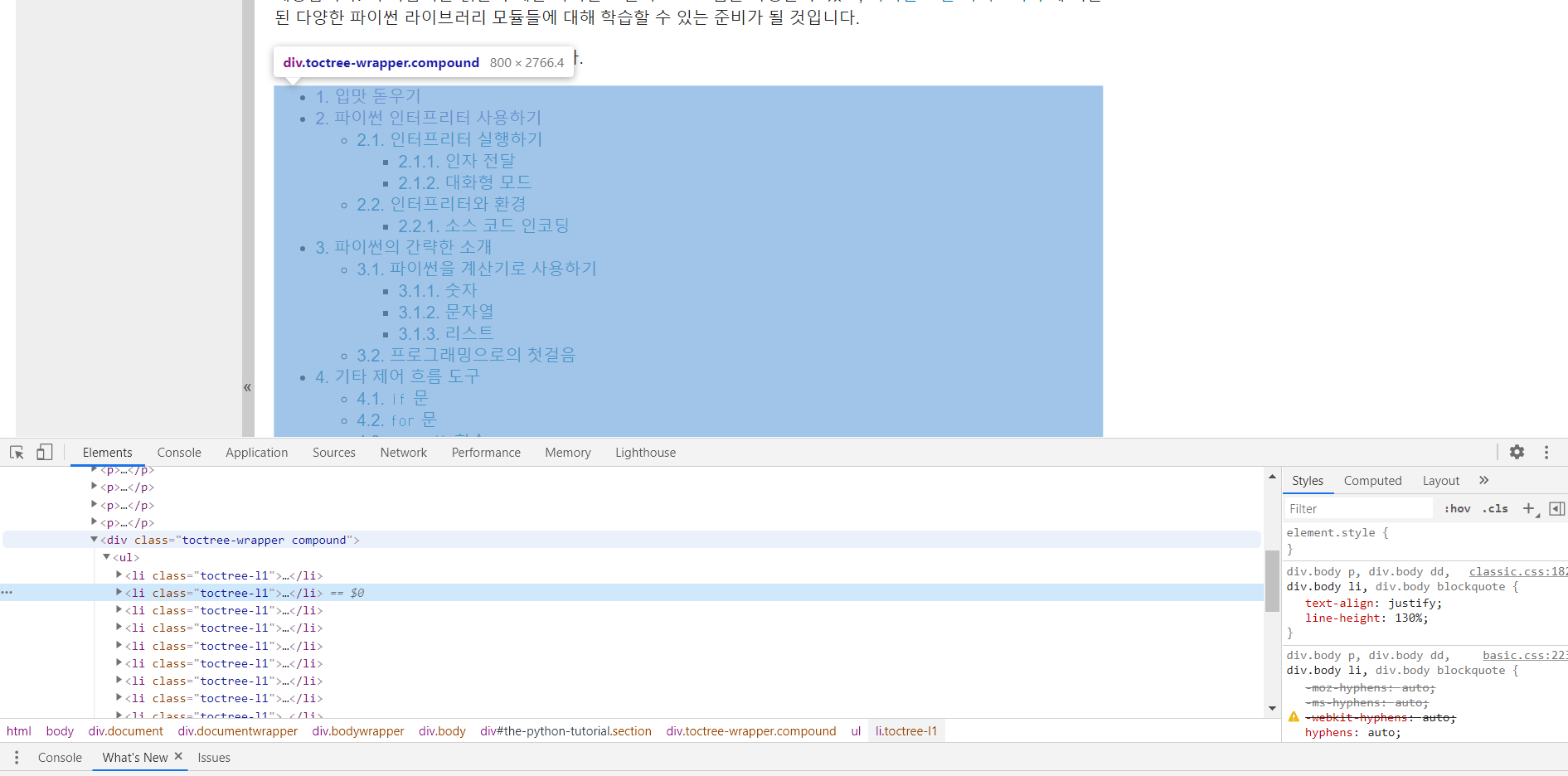
간단하게 몇줄의 code로 사이트의 정보를 원하는 부분만 가져올 수 있다
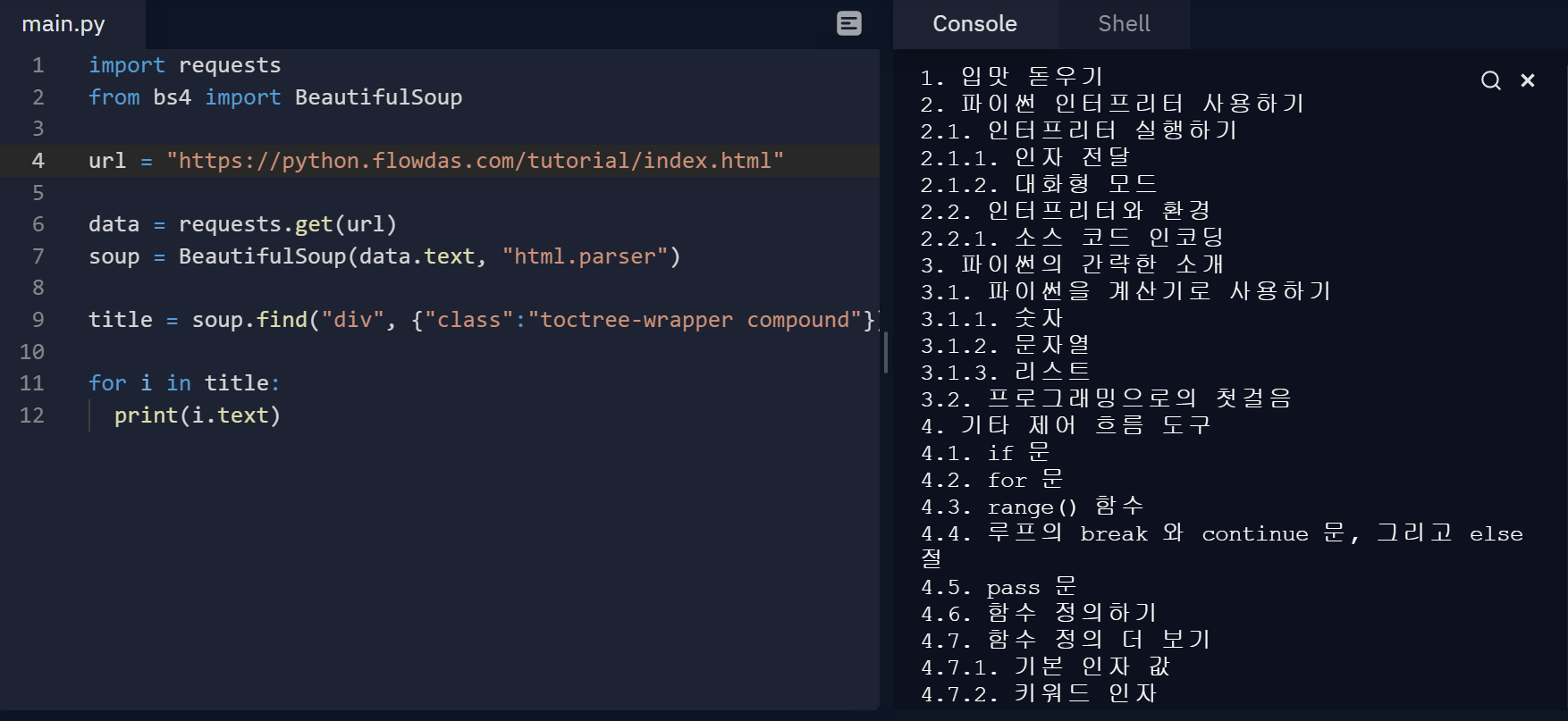
import requests
from bs4 import BeautifulSoup
url = "https://python.flowdas.com/tutorial/index.html"
data = requests.get(url)
soup = BeautifulSoup(data.text, "html.parser")
title = soup.find("div", {"class":"toctree-wrapper compound"}).find_all("a")
for i in title:
print(i.text)☝위 예시는 find()와 find_all()로 찾아보았다
👇CSS selector를 이용하여 찾을 수 있는 select_one()과 select()으로 사용해 볼 수 있다
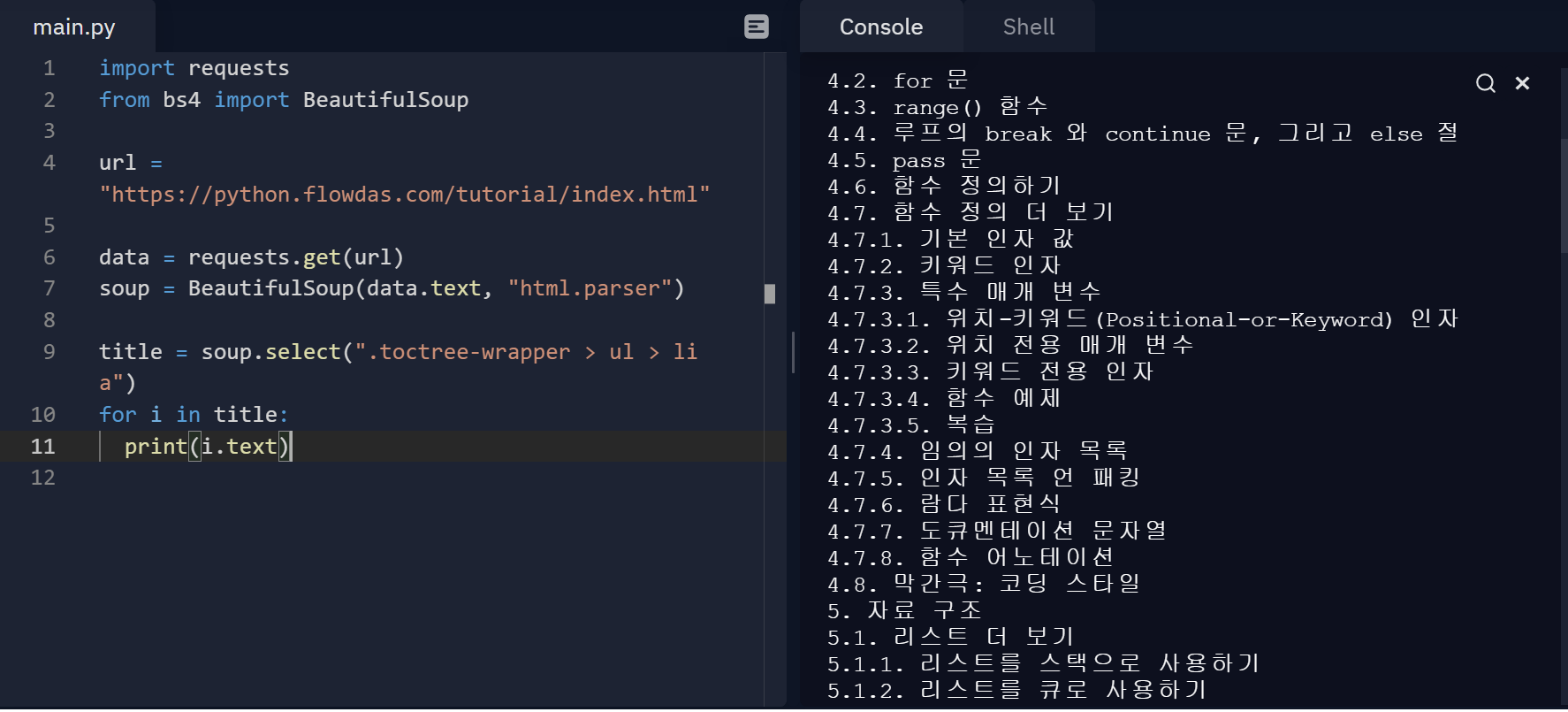
import requests
from bs4 import BeautifulSoup
url = "https://python.flowdas.com/tutorial/index.html"
data = requests.get(url)
soup = BeautifulSoup(data.text, "html.parser")
title = soup.select(".toctree-wrapper > ul > li a")
for i in title:
print(i.text)CSS selector
- 자손 선택자
선택자1 선택자2
선택자1 하위의 선택자2에 해당되는 모든 요소
- 자식 선택자
선택자1 > 선택자2
선택자1 하위의 선택자2에 해당되는 직계 자식 요소

🐜https://action2thefuture.github.io/🐜