
1. 프로세스
Program
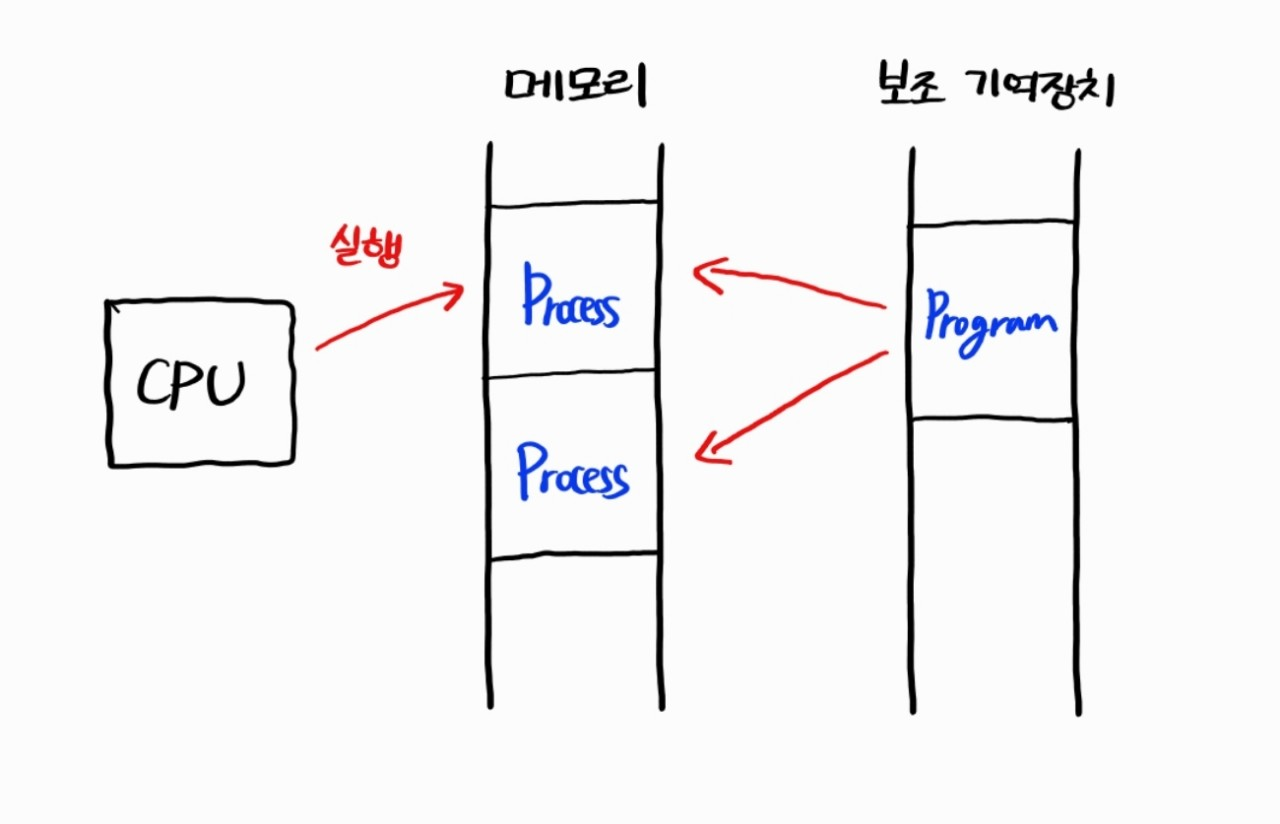
컴퓨터가 특정한 일을 수행하도록 하는 명령어들의 집합
Process
메모리에 적재되어 실행 중에 있는 프로그램
보조 기억장치는 CPU에 비해 속도가 매우 느리다. 때문에 속도가 빠른 RAM에 프로그램을 적재하여 실행한다. 위 그림처럼 하나의 프로그램으로부터 여러개의 프로세스가 생성될 수 있기 때문에 프로세스를 프로그램의 인스턴스라고 부르기도 한다.
ex
- 메모장을 여러개 실행할 수 있음
- 터미널을 여러개 실행할 수 있음
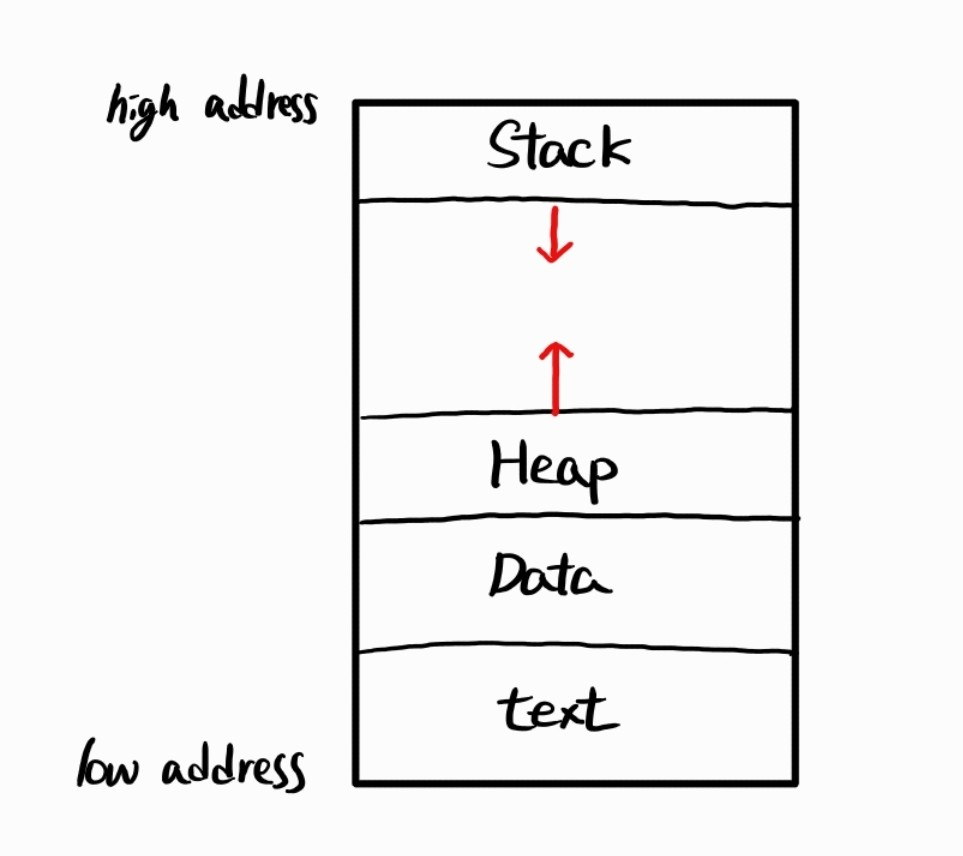
프로세스 메모리 구조
Stack 영역
함수를 수행하는데 필요한 임시 데이터들을 저정한다. 함수 매개변수나 지역변수, 복귀 주소 등이 저장된다. 함수를 호출할 때 마다 메모리를 할당하며 함수 수행이 끝나면 다시 반환한다.
Heap 영역
프로그램을 실행하는 도중 동적으로 할당되는 메모리 영역이다. java의 new 연산자나 C언어의 malloc 함수를 통해 Heap 영역을 늘려갈 수 있다.
Data 영역
전역변수나 정적변수가 저장되는 영역이다. Data 영역은 초기화된 데이터와 초기화 되지 않은 데이터를 저장하는 영역으로 세분화 할 수 있다.
- data 영역 : 초기화된 전역 변수가 위치
- bss 영역 : 초기화되지 않은 전역 변수가 위치
Text 영역
프로그램 즉, 수행할 명령어들이 저장되는 영역이다.
text 영역이나 data 영역의 크기는 런타임 도중에 변경되지 않는다. 반면 stack 영역이나 heap 영역의 경우 런타임 도중 확장되거나 줄어들 수 있다. stack 영역과 heap 영역은 서로를 향하며 확장되는데, 운영체제는 이들이 서로 겹치지 않도록 처리해야 한다.
프로세스의 상태 변화
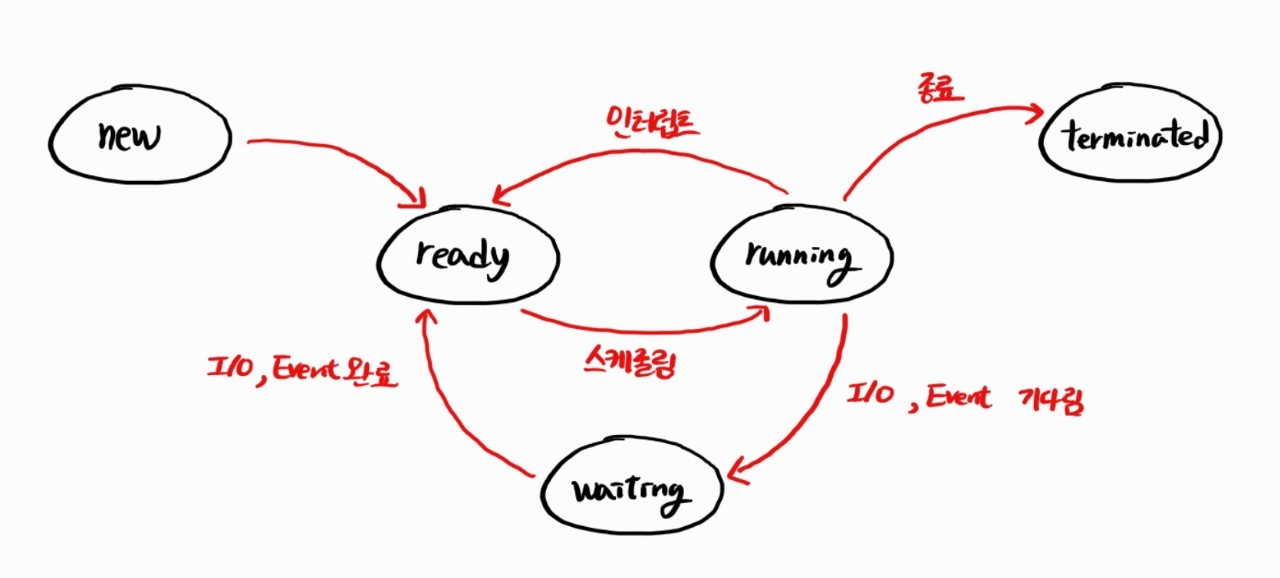
new
프로세스가 생성되는 상태이다. 사용자가 특정 프로그램을 실행하거나, 프로세스가 자식 프로세스를 생성하는 경우가 해당된다.
ready
스케줄러에 의해 선택되기를 기다리고 있는 상태이다. CPU를 할당받으면 running 상태로 진입한다.
running
명령들을 실행하고 있는 상태이다. 여러가지 이유로 상태가 바뀔 수 있다. 할당받은 CPU 시간이 모두 지나면 다시 ready 상태로 바뀌게 된다. I/O나 Event를 기다려야 하는 경우에는 CPU를 양보하고 waiting 상태로 진입한다.
waiting
I/O 작업이 완료되기를 기다리거나 특정 이벤트가 발생하기를 기다리는 상태이다.
terminated
프로세스의 실행이 종료된 상태이다.
Process Control Block
운영체제는 프로그램을 실행하기 위한 여러 정보들을 Process Control Block(PCB)에 저장한다. 주로 다음과 같은 정보들이 저장된다.
-
프로세스 상태 : new, ready, running, ... 등의 상태를 나타낸다.
-
프로그램 카운터 : 다음에 수행할 명령어의 주소를 가리킨다.
-
레지스터 : 누산기, 인덱스, 스택, 범용 등의 레지스터들을 나타낸다. 컴퓨터의 구조에 따라 저장하는 레지스터의 수나 유형이 달라질 수 있다.
-
메모리 관련 정보 : 페이지 테이블 또는 세그먼트 테이블 등이 저장된다.
-
회계 정보 : CPU 사용 시간이나 경과된 시간 등의 정보가 저장된다.
-
입출력 상태 정보 : 프로세스에 할당된 입출력 장치들과 열린 파일의 목록이 저장된다.
2. 문맥 교환
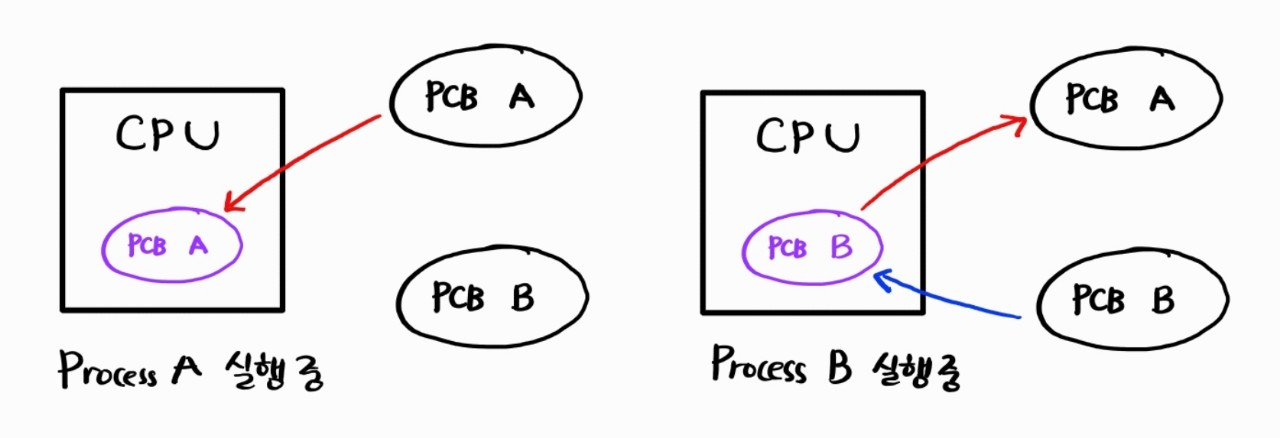
프로세스의 실행 흐름을 나타내는 레지스터들은 PCB에 나타나 있는데, 이를 Context 라고 부른다. 단일 코어 프로세서는 한 순간에 단 하나의 프로그램만을 실행할 수 있기 때문에 여러 프로세스를 지원하려면 Concurrency 하게 실행을 이어나가야 한다. 이를 위해서 CPU는 여러 PCB를 번갈아 가면서 참조하여 여러 프로세스를 실행한다. 이 때 PCB에 따라 CPU 레지스터의 값을 교체하는 작업을 Context Switching : 문맥 교환 이라고 부른다.
overhead
레지스터 값을 교체하는 동안은 프로그램을 실행할 수 없기 때문에 일종의 overhead라 볼 수 있다.
3. 스레드
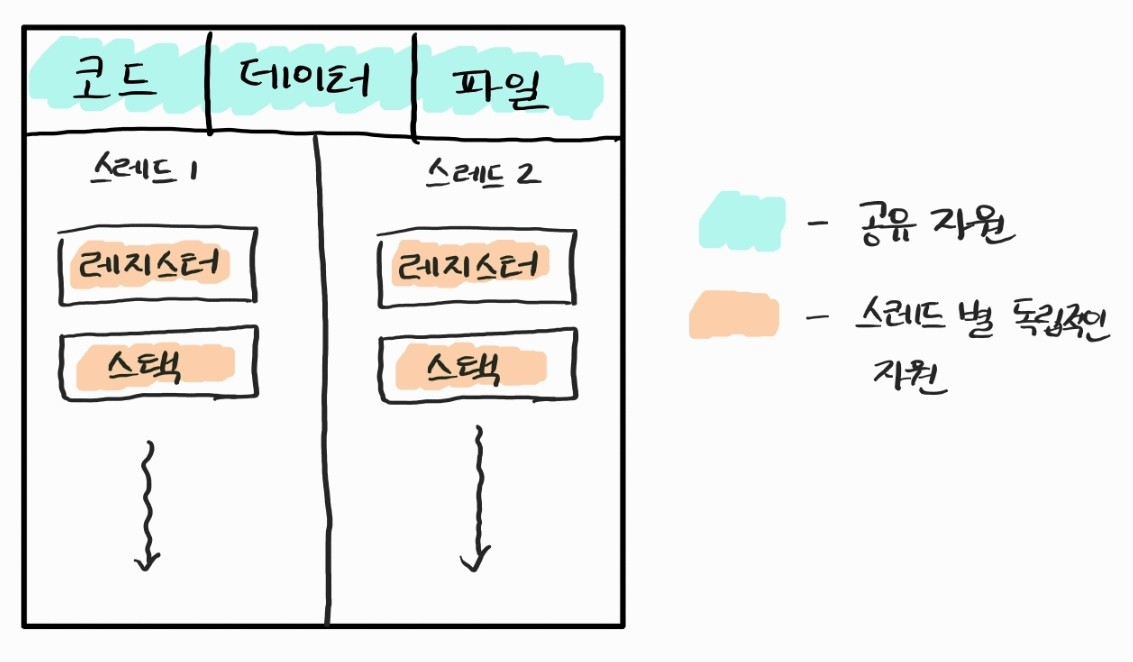
스레드는 프로세스 내의 실행 흐름이라고 볼 수 있다. 멀티 스레드를 적용한다면, 한 프로세스가 내부에 여러개의 스레드를 가질 수 있게 된다. 스레드는 CPU 이용의 기본 단위로서, 스케줄링이 된다. 한 프로세스가 여러 스레드를 가지고 있다면 운영체제는 이들을 각각 스케줄링하며 한 프로세스가 여러 작업을 병행할 수 있게 해준다.
멀티 스레드 적용시 이점
응답성
한 프로세스가 여러 작업을 수행해야 할 때 이를 순차적으로 처리한다면 사용자 응답성이 떨어질 수 있다. 하지만 여러 작업 흐름을 스레드로 분리한다면 이들을 스케줄링하며 병행할 수 있기 때문에 사용자 응답성이 좋아진다.
자원 공유
위 그림을 보면 알 수 있듯이 한 프로세스 내부의 스레드들은 프로세스의 자원을 공유할 수 있다. 이는 프로세스간 데이터를 공유하기 위한 방법(메시지 전달, 공유 메모리, ... ) 보다 쉽게 데이터를 공유할 수 있다.
경제성
새로운 프로세스 생성시 메모리와 자원을 할당하는데 많은 비용이 들어간다. 하지만 스레드는 이미 존재하는 프로세스의 자원을 공유하기 때문에 이러한 오버헤드를 줄일 수 있다. 같은 이유로, 스레드간 context switching이 프로세스간 context switching보다 빠르다.
리눅스에서의 스레드
리눅스에서는 내부적으로 프로세스와 스레드를 구분하지 않는다. 주로 task라는 용어를 사용하며, 이를 표현하기 위해 task_struct 라는 구조체를 사용한다. 그 외에도 여러 자료구조가 연관되어 있다. 주로 clone() 시스템 콜을 호출하여 스레드를 생성할 수 있는데, 인자로 여러 플래그들을 전달하여 부모 태스크와 공유할 자원을 설정할 수 있다. 이 때 아무 인자도 전달하지 않으면 fork()를 수행한 것과 동일하다.
