오늘목표
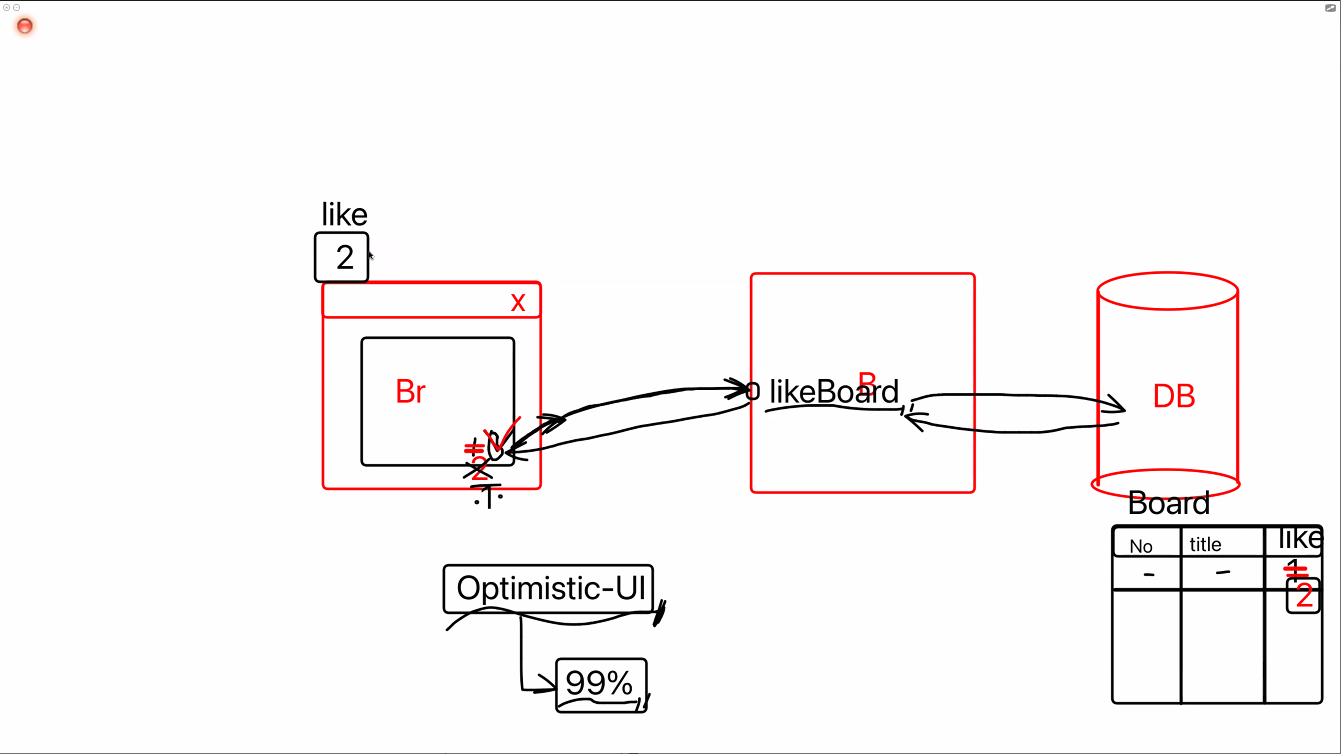
- 옵티미스틱유아이
- 미리보기 ssr
- 검색엔진최적화
- 옵티미스틱유아이
실패할 가능성이 거의 없는 데이터에 사용
- 미리보기 ssr
스크래핑, 크롤링
다른사이트 정보 가져오기
가. get방식으로 https://www.naver.com 으로 해서 html을 받아 올 수 있음
근데 이런짓은 복잡하니까 자동적으로 해주는 라이브러리가 있음
Cheerio, Puppeteer
Scraping 한 번 가져오기 Cheerio를 쓰고
Crawling 꾸준히 가져오기 Puppeteer를 쓰고
og
opengraph
다른 홈페이지의 미리보기
개발자들간의 약속
백에드에서 보통 스크래핑함?
이유는 CORS문제
모든페이지에서 데이터를 불러올 수 없다
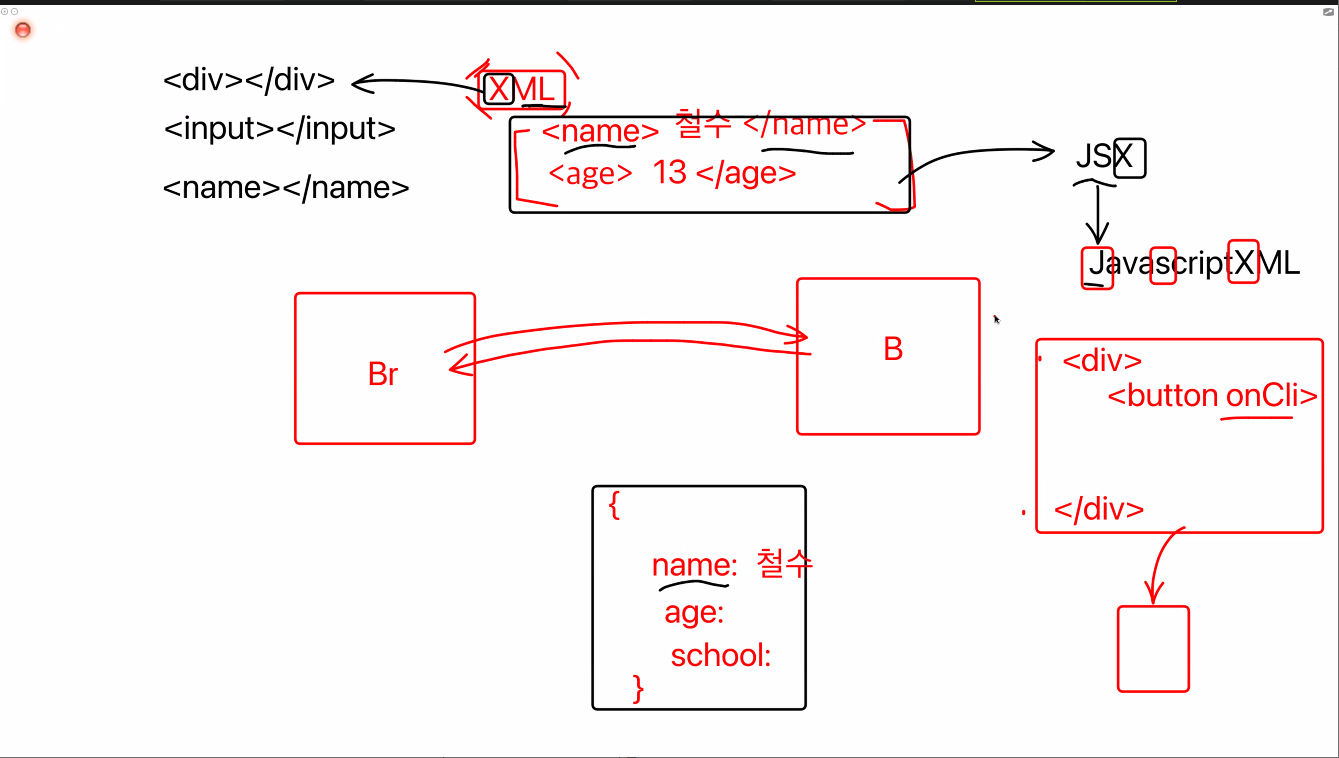
나. opengraph가 ssr과 관련이 있다?
다이나믹라우팅(동적)페이지에서는 meta가 안먹힘
왜?
스크래핑단계에서
axios curl postman이 요청을하면 비어있는 html만 받아옴 이후 쿼리를 날려야 함
html은 비어있으니 og:title을 찾을 수 없음
그럼 어떻게?
애초에 html css js 를 받아올 때 값이 있어야 됨
yarn dev를 했을 때 useQuery까지 해야됨
즉 yarn dev 프로그램이 backend로 요청을 해서 db를 긁고 html css js를 완성시켜서 브라우저로 보내야됨
바닐라 리액트에서는 ssr이 힘듬 nodejs로 따로 서버 만들고 해야됨
next js는 이걸 할 수 있음
리액트18버전에서 가능하지만 아직은 좀 지켜봐야하는 단계임
- 검색엔진 최적화
검색회사는
크롤러봇을 이용해서 꾸준히 axios요청해서 내용들을 가져옴
근데 html데이터가 비어있어서 검색점수가 낮아짐
그래서 데이터가 합쳐진애를 줘야됨
SEO -> SSR이 필요함
검색엔진 최적화를 위해서라도 SSR이 필요함
그럼 모든페이지를 SSR해야되는가?
그건 아님
그렇게 되면 매우 느려짐 옛날방식임
