이번 포스팅부터 순차적으로 성능 향상을 위한 캐싱 기법에 대해서 소개하겠습니다.
순서는 다음과 같습니다.
- 캐싱기법에 대한 소개와 Redis가 아닌 로컬 캐시를 사용해야하는 이유
- Redis에 대해서 공부
- Redis를 적용
캐싱 기법을 사용하는 이유
우선, 캐싱 기법을 사용해야하는 이유에 대해서 설명하고 넘어가겠습니다.
저는 학교 OS시간에 캐싱 기법에 대해서 배운적이 있었지만, 어플리케이션에서 캐싱 기법을 왜? 사용하고, 어떻게 사용 해야하는지는 전혀 알지 못하는 상황이었습니다.
그러던 와중 토스, 네이버, 카카오등의 채용 공고에서,
이런 기술들을 경험 해보신 분들이 와주셨으면 좋겠어요!
아래에
redis, kafka등의 기술들을 사용해 본적이 있었으면 좋겠어요!
라는 문구를 보고 "아! 서비스기업들이 Redis기술을 좋아하니까 빨리 Redis에 대해서 공부해보자"라고 생각이 들었습니다.(다들 그러시지 않나요?)
대부분의 사람들이 Redis는 서비스 기업에서 쓰는 고오급 기술이니까
나도,,, 무조건 알아야하지 않을까?라는 생각에 무턱대고 Redis를 찾아보고 공부하는 사람들이 많을것입니다.

(이러면 안된다.)
그래서 실제로 저도 포스팅 날짜를 보면 유튜브와 구글링을 통해 배운 Redis 기술 내용을 공부한 것을 먼저 적었는데,,, 이는 공부 방식이 완전히 틀렸다는 것을 알게 되었습니다..ㅠ
어떠한 기술 혹은 자료구조를 사용할 때는
왜? 이 기술을 사용하였는지,
왜? 하필 이 자료구조를 사용하였는지? 다른 자료구조는 없는지 생각하는 것이 좋다고 생각이 듭니다.
그렇다면 왜? Redis인가?
일단 Redis에 대해서 알고 넘어가기 전에 캐싱 기법에 대해서 알고 넘어 가봅시다.
우선 학교에서 배운 OS시간에 배운 저장장치 계층 구조 그림에 대해서 살펴 보겠습니다.
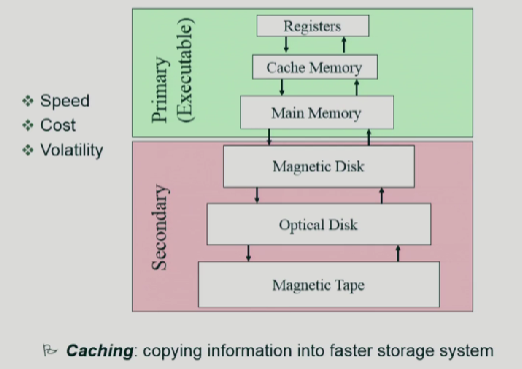
속도: 위로갈수록 빠르고, 아래로 내려올수록 느립니다.
비용: 위로갈수록 비쌉니다. 아래로 내려올수록 쌉니다.
저장을 하기위해서는 아래로 내리고,내리고 해서 저장을하고, 불러올때는 밑에서부터 올리고 올리고 해야합니다.
그런데 이과정이 너무 오래걸리니까, 밑에까지 안내려가고 중간에 저장을 하는것입니다.
그렇게하면 밑에까지 내려가지 않아도 중간에 만약 요청한게 있다면 가져다 쓰면되는것입니다. 만약 없다면, 끝까지 내려가야합니다.
해당 OS지식을 어플리케이션에 적용을 해보겠습니다.
클라이언트A --> 어플리케이션 ---> DB
- 클라이언트 A가 어플리케이션에 요청을 보냅니다.
- 어플리케이션에서 요청의 응답에 필요한 객체를 DB에서 가져옵니다.
- 클라이언트 A에게 반환합니다.
그런데, 이런상황에서 클라이언트 A 뿐만 아니라 A,B,C,D,E,,,,이렇게 많은 사람이 한꺼번에 요청을 보내면 어떻게 될까요?
(치킨 이벤트를 배민에서 한다던지, 톡딜을 한다던지 클라이언트가 요청을 한꺼번에 많이 보내는 상황이 분명 존재할 것입니다.)
만약 캐싱기법을 사용하지 않는다면,
클라이언트 A,B,C,D,E가 동일한 객체를 요청한다면, 매 요청마다 DB로 쿼리를 날려서 해당 엔티티를 가져온다음에, 반환을 하는 과정을 거쳐야 할겁니다.
여기서 저는 이런 생각이 들었습니다.
어? 클라이언트 A각 객체 A를 조회한다.
영속성 컨텍스트에 없으므로 DB에 쿼리를 날려서 영속성 컨텍스트에 올려놓고, 반환한다.
클라이언트 B가 객체 A를 조회시 영속성 컨텍스트에 올려놓은걸 가져오면 되는거 아닌가?
굳이 캐싱기법을 적용하지 않아도 될것 같은데? 라는 궁금증이 들었습니다.
그러나 영속성 컨텍스트는 각 클라이언트 요청마다 독립적으로 생성됩니다.
즉, 각 요청은 자체적인 스레드에서 실행되며, 각 스레드는 고유한 영속성 컨텍스트가 있습니다.
그러므로 클라이언트 B,C,,,들은 A의 영속성 컨텍스트에 접근할 수 없습니다.
고로, 캐싱기법을 사용하지 않으면 클라이언트 B,C,,,모두 DB에 쿼리를 날려야 한다는 겁니다.
어플리케이션의 성능은 대부분 DB가 결정한다고 합니다. 얼만큼 쿼리를 덜 날리는냐, 얼만큼 DB를 빠르게 뒤지느냐가 네트워크 성능을 결정 짓는다고 합니다.
고로, 캐싱 기법을 사용하는 이유는 많은 클라이언트들이 동시에 동일한 객체를 가져오기를 원한다면, DB에 동일한 쿼리를 여러번 날리지 않기 위해서 캐시에서 반환하기 위해서 사용하는 것입니다.
그렇다면 왜? Redis를 사용하면 안되는가?
이제부터 왜? Redis를 사용하면 안되는지에 대해서 설명해보도록 하겠습니다.
Spring의 메모리 캐시와 Redis 캐시는 각각의 특성과 사용 사례에 따라 적합한 상황이 다릅니다.
Redis는 네트워크 기반의 분산 캐시 시스템입니다.
메모리 내에서 데이터를 관리하지만 서버 외부에서 독립적으로 동작합니다.
고로, 여러대의 서버에서 공유할 수 있는 캐시로 사용됩니다.
즉, Redis는 외부 메모리 저장소이기 때문에, 모든 애플리케이션 서버가 네트워크를 통해 해당 Redis 서버와 통신하게 됩니다.
서버가 여러 대라 하더라도 모든 서버는 동일한 Redis 인스턴스에 접근하여 데이터를 캐싱하고 조회할 수 있습니다.
이렇게 Redis가 글로벌 캐시로 동작하기 때문에 여러 서버가 동일한 캐시데이터를 사용할 수 있고, 서버간 일관성을 유지할 수 있게 됩니다.
배달의 민족, 네이버, 토스, 카카오와 같은 기업들이 배포한 애플리케이션이 사용하는 서버는 당연히 여러대 일것입니다.
한번에 요청이 수만, 수십만건이 들어오는데 해당 요청을 하나의 서버가 감당할 수 있을리가 없습니다.
고로, 여러개의 서버를 증설하여 사용하니까 캐시를 사용할때 글로벌 캐시를 두어 여러 서버가 외부 메모리 저장소에 접근하여 동일한 캐시데이터를 사용하는것입니다.
그러나,
대부분의 저와 같은 학생들이나, 서비스를 아직 크게 확장하지 않은경우는 Aws EC2를 한대 빌리고 거기다가 프로젝트 서버를 띄울것입니다.
이는, 지금 애플리케이션 서버를 딱 한대 띄운것과 마찬가지입니다.
지금 서버가 하나만 띄워져 있는상태이고, 애플리케이션으로 들어오는 모든 요청을 하나의 서버 내부에서 처리하고 있습니다.
그러면, 서버가 여러개가 아니라 외부 메모리 저장소를 사용할 필요가 없으므로, Spring 내부의 자체 메모리를 사용하는것이 훨씬더 합리적입니다.
제가 처음에 간과한 점이 이것이었습니다.
Spring boot에서 Local Cache적용하기
저의 Prove Project에서 Cache를 어떤 부분에 적용할지에 대해서 먼저 소개해 드리겠습니다.
메인 페이지에는 STUDY, EXERCISE 등 다양한 태그들이 있으며, 사용자가 원하는 태그를 선택하면 그 태그에 맞는 Prove 게시글 중에서 '좋아요' 순으로 100개의 게시글을 가져와 메인 화면에 표시하는 로직이 있습니다.
문제는, 이벤트로 인해 100만 명이 동시에 STUDY 태그를 선택할 경우, 동일한 100개의 Prove 게시글을 반환함에도 불구하고 100만 건의 쿼리가 데이터베이스에 발생한다는 점입니다.
일반적으로 캐시를 사용 할 때는 Key-Value 방식으로 객체를 저장하고 관리하지만,
저는 Cache Warming 기법을 적용하여 문제를 해결하려 합니다. ProveApplication 서버가 구동될 때, STUDY 태그의 게시글을 '좋아요' 순으로 미리 캐시에 저장해 두는 방식입니다.
실제로 인터파크나 티켓링크 같은 사이트에서는 대규모 요청이 예상되는 상품을 등록할 때, 미리 데이터베이스에서 캐시로 올려놓는 방식을 사용한다고 합니다.
과정 1
build.gradle
implementation 'org.springframework.boot:spring-boot-starter-cache'우선 스프링 부트의 내장 캐시를 사용하기 위해서 라이브러리 추가를 해줍니다.
과정 2
CacheConfig
@Configuration
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
return new ConcurrentMapCacheManager("STUDY", "EXERCISE");
}
}CacheManager를 등록해줍니다. 여기서는 단순하게 STUDY,EXERCISE 두개의 그룹으로만 나누어서 진행했습니다.
여기서 왜? CacheManager를 ConcurrentMapCacheManager를 썻는지 알아야합니다.
ConcurrentMapCahceManager는 기본적으로 ConcurrentHashMap을 사용하여서 Cache를 관리합니다.
그렇다면 HashMap도 있고 ConcurrentHashMap도 있는데 왜? 하필 ConcurrentHashMap을 쓴걸까요?
이건 바로 Java의 멀티스레드 환경에서 동시성을 만족하기 위해서 입니다.
ConcurrentHashMap에서는 Lock 또는 CAS연산을 통해 안전하게 멀티스레드 환경에서 데이터를 읽거나 쓸 수 있습니다.
더 자세한 내용은 해당 포스트를 참고해주세요
과정 3
CacheInitializer
@Component
public class CacheInitializer {
private final ProveRepository proveRepository;
private final CacheManager cacheManager;
@Autowired
public CacheInitializer(ProveRepository proveRepository, CacheManager cacheManager) {
this.proveRepository = proveRepository;
this.cacheManager = cacheManager;
}
@PostConstruct // Bean이 초기화될 때 호출됨
public void init() {
List<Prove> proves = proveRepository.findTop100ByStudyTagOrderByLikeCountDesc(); // DB에서 100개의 Prove 가져오기
//List<ProveDtoV2> proveDtos = makeProveDtos(proves);
Cache cache = cacheManager.getCache("STUDY");
if (cache != null) {
cache.put("top100Proves", proves); // "STUDY" 캐시에 저장
System.out.println("Prove 데이터가 STUDY 캐시에 저장되었습니다.");
}
}
}@PostConstruct 애노테이션을 통해 init메서드를 호출하여, proveRepository에서 Study태그인 Prove에서 좋아요가 많은 순서대로 100개의 계시글을 가져옵니다.
그뒤에 Dto로 변환한후에 STUDY그룹의 캐시에 top100Proves라는 키로 prove List를 저장합니다.
참고
- @PostConstruct
PostConstruct는 Spring에서 객체가 생성되고 나서 초기화 작업을 수행하는데 사용된다.
Spring컨텍스트에서 Bean이 생성되고, Autowired등을 통해 의존성이 주입된 후 바로, 한번만 호출이 된다.
주로 초기화 로직이나 준비작업(예: 캐시 미리로드, 외부 리소스 연결 설정등)을 수행할 때 사용된다.
과정 4
@GetMapping("/api/allProves/v4/STUDY")
public List<ProveDtoV2>getProvesV4(){
return proveService.getProvesWithCache();
} public List<ProveDtoV2> getProvesWithCache() {
Cache cache = cacheManager.getCache("STUDY"); // "STUDY" 캐시 사용
List<Prove> cachedProves = cache.get("top100Proves", List.class);
System.out.println("캐시에서 데이터를 반환합니다.");
return makeProveDtos(cachedProves); // 캐시에서 데이터를 반환
}결과
Hibernate:
select
p1_0.id,
p1_0.color,
p1_0.end_time,
p1_0.importance,
p1_0.open_or_not,
p1_0.short_word,
p1_0.start_time,
p1_0.success,
p1_0.tags,
p1_0.user_id
from
prove p1_0
join
likes l1_0
on p1_0.id=l1_0.prove_id
where
p1_0.tags='STUDY'
group by
p1_0.id
order by
count(l1_0.id) desc
Prove 데이터가 STUDY 캐시에 저장되었습니다.처음에 PostConstruct로 인해 init메서드가 호출되어서 DB로 쿼리를 날리고 캐시에 저장한뒤에 요청을 보내면
2024-10-06T14:32:55.803+09:00 INFO 12856 --- [nio-8080-exec-2] o.s.web.servlet.DispatcherServlet : Completed initialization in 2 ms
2024-10-06T14:32:55.841+09:00 DEBUG 12856 --- [nio-8080-exec-2] o.s.security.web.FilterChainProxy : Securing GET /api/allProves/v4/STUDY
2024-10-06T14:32:56.021+09:00 DEBUG 12856 --- [nio-8080-exec-2] o.s.security.web.FilterChainProxy : Secured GET /api/allProves/v4/STUDY
2024-10-06T14:32:56.024+09:00 DEBUG 12856 --- [nio-8080-exec-2] o.s.web.servlet.DispatcherServlet : GET "/api/allProves/v4/STUDY", parameters={}
2024-10-06T14:32:56.027+09:00 DEBUG 12856 --- [nio-8080-exec-2] s.w.s.m.m.a.RequestMappingHandlerMapping : Mapped to com.prove.domain.Prove.ProveController#getProvesV4()
캐시에서 데이터를 반환합니다.
dot 메서드캐시에서 데이터를 반환하는것을 확인 할 수 있습니다.
그렇다면 마지막으로 Cache의 Expire 타임은 어떻게 될까요?
Spring Boot의 Cache Expire Time
지금까지 Cache의 Expire Time을 설정하지 않았는데, 그렇다면 캐시에 올라간 proveList의 Expire Time은 어떻게 될까요?
Spring Boot의 Cache매니저에서는 Expire Time을 설정할 수 없습니다.
만약 만료 시간을 지정하고 싶다면 기본 CacheManager가 아닌, Caffiene등을 사용해야 합니다.
저의 프로젝트 환경에서는 일반적으로 가장 많은 좋아요 계시글의 순위가 하루에 크게 바뀌지 않기 떄문에,
그냥 새벽에 서버를 한번 내렸다 올렸다. 해서 캐시 워밍을 그때마다 매일매일 하는게 캐시를 저장하고, 만료 후 삭제 이런 과정을 하는것보다 오버헤드가 적다고 생각되어서 캐시 만료는 사용하지 않았습니다.
포스트를 작성하던중 만난 문제를 해결한 포스트는 여기에 있습니다.
