DB1편
JDBC 이해
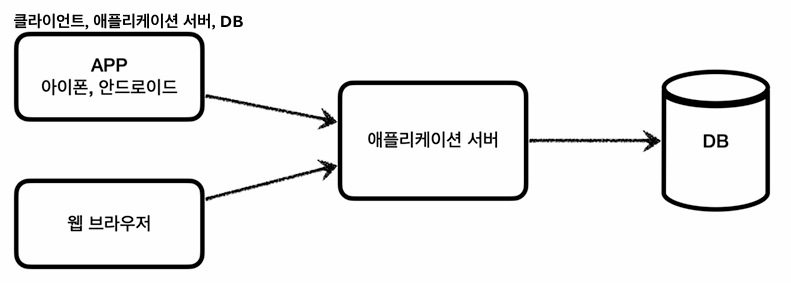
클라이언트가 애플리케이션 서버를 통해 데이터를 저장하거나, 조회하려면 애플리케이션 서버는
- 커넥션 연결: TCP/IP 3way hand-shake
- SQL 전달
- 결과 응답
이러한 로직으로 수행이 된다.
그런데 해당 DB가 Mysql에서 Oracle로 변경되면 각 DB마다 사용법이 다 다르므로 애플리케이션 서버 코드도 변경해야하고, 개발자가 각각 DB마다 사용법을 익혀야한다는 단점도 있다.
그래서 JDBC라는 자바 표준이 등장
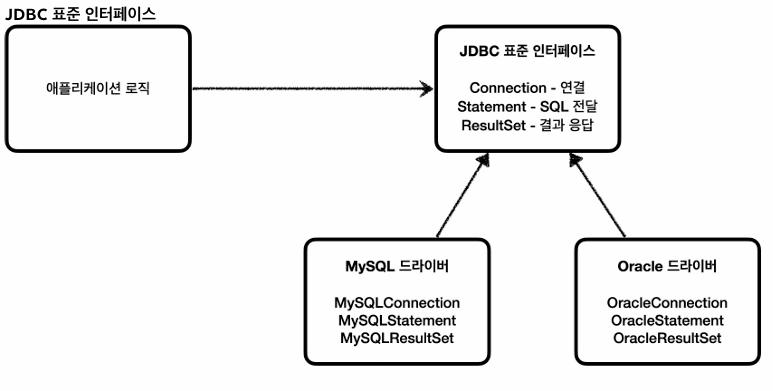
애플리케이션 로직이 DB를 바로 바라보는게 아니라 JDBC표준 인터페이스를 바라보게 한다.
그러면, 우리는 각 DB에 해당하는 Connection Statement ResultSet을 알필요없이 표준 인터페이스만 사용해서 개발하면 된다.
JDBC인터페이스에 대한 구현체는 각 DB회사에서 자신의 DB에 맞춰 구현해서 라이브러리로 제공, 이걸 JDBC 드라이버라고한다.
Mysql이면 Mysql jdbc 드라이버, Oracle이면 Oracle jdbc 드라이버라고 한다.
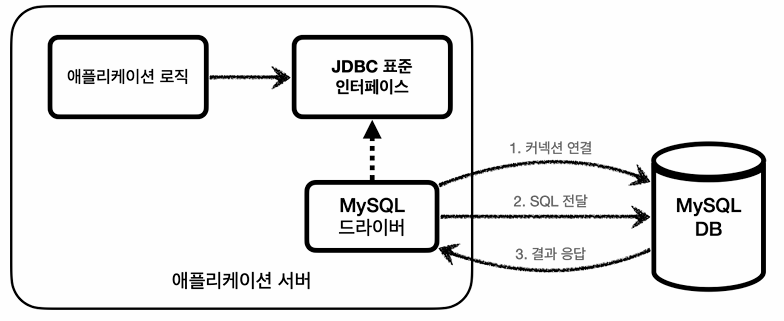
jdbc를 사용하는 방법은 3가지가 있다.
-
직접사용
conn = DriverManager.getConnection(url, username, password); //데이터베이스 연결
// 2. SQL 쿼리 준비
String sql = "SELECT * FROM users" pstmt = conn.prepareStatement(sql);
// 3. 쿼리 실행
rs = pstmt.executeQuery(); -
SQL Mapper(JdbcTemplate,MyBatis)
Jdbc를 편리하게 사용하도록 도와준다, 반복 코드를 제거해준다.
@Autowired
private JdbcTemplate jdbcTemplate;
public List<User> getUsers() {
String sql = "SELECT * FROM users";
return jdbcTemplate.query(sql, new BeanPropertyRowMapper<>(User.class));
}- ORM
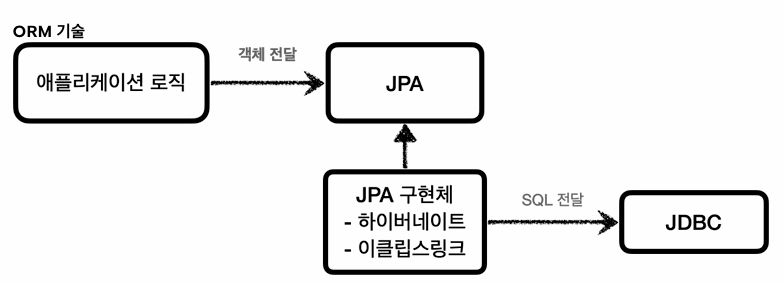
객체를 관계형 데이터베이스 테이블과 매핑해주는 기술,
개발자가 직접 SQL을 작성하지 않고, ORM이 대신 SQL을 만들어서 실행해준다. JPA, 하이버네이트
데이터베이스 연결
클라이언트가 DB를 사용하는 요청을 보내면 각 요청마다 데이터베이스 연결을 맺어야함.
데이터베이스에 연결하려면 DrvierManager.getConnection(...)을 호출하면됨
... -> URL,USERNAME,PASSWORD
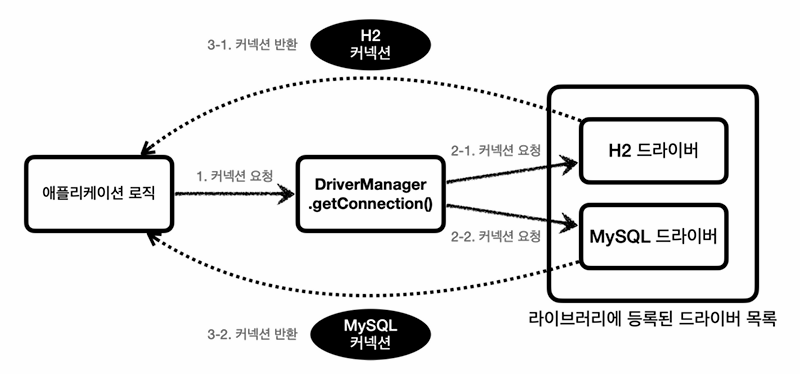
우리가 build.gradle에다가 H2 Driver를 설치해놓으면, DriverManager가 라이브러리에 등록된 드라이버 목록을 자동으로 인식하고,
드라이버한테 설정정보를 넘겨서 커넥션을 획득 할 수 있는지 확인
가능하면 커넥션 구현체가 반환된다.
간단한 JDBC직접 사용코드
등록
@Slf4j
public class MemberRepositoryV0 {
public Member save(Member member) throws SQLException {
String sql = "insert into member(member_id, money) values(?, ?)";//sql쿼리문
Connection con = null;
PreparedStatement pstmt = null;
try {
con = getConnection(); // 커넥션맺고
pstmt = con.prepareStatement(sql); //PreparedStatement로 sql날림
pstmt.setString(1, member.getMemberId()); //?부분 바인딩
pstmt.setInt(2, member.getMoney());
pstmt.executeUpdate(); //실행
return member;
} catch (SQLException e){
log.error("db error",e);
throw e;
}finally {
//항상 finally에 connection종료
close(con,pstmt,null);
}
}
private void close(Connection con, Statement stmt, ResultSet rs) {
//close할때 Connection,Statement,ResultSet 각각 try catch를 사용하여 닫아야함
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {
log.info("error", e);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
log.info("error", e);
}
}
if (con != null) {
try {
con.close();
} catch (SQLException e) {
log.info("error", e);
}
}
}
private Connection getConnection() throws SQLException {
return DBConnectionUtil.getConnection();
}
}항상 getConnection을 통해서 데이터베이스 커넥션을 얻고,
SQL작성하고
prepareStatment를 통해서 준비하고
executeUpdate()날리고
리소스 정리를 항상해줘야한다.
커넥션 풀과 데이터 소스 이해
여러 클라이언트 요청은 각 요청마다 별도의 쓰레드에서 수행이 되고 각 쓰레드마다 데이터커넥션을 얻어야한다.
그런데 각 클라이언트 요청마다 데이터 베이스 커넥션은 맺으면 매우 비효율 적일 것이다.
그래서 해결방법으로 커넥션을 미리 생성해두고 사용하는 커넥션 풀이라는 방법이다.
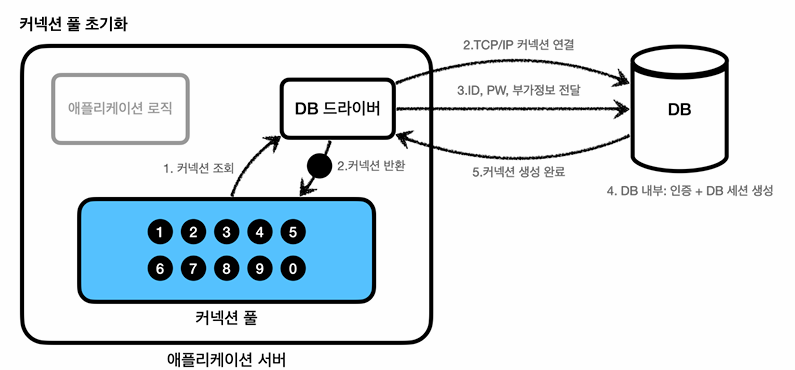
애플리케이션을 시작하는 시점에 커넥션풀은 필요한 만큼 커넥션을 미리 확보해서 풀에 보관한다.
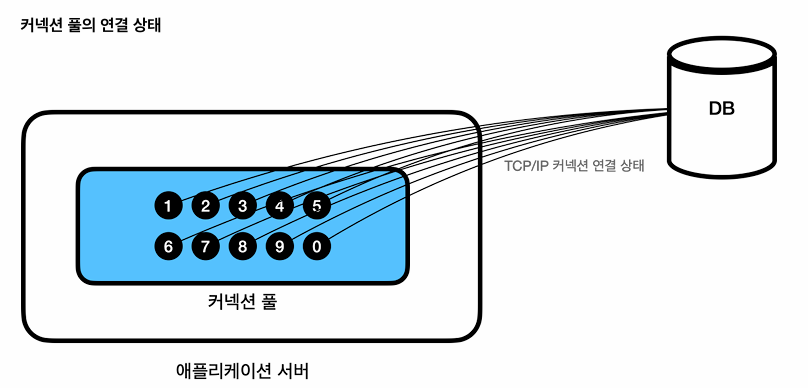
커넥션 풀에 있는 커넥션은 TCP/IP로 DB와 연결되어 있으므로 즉시 SQL을 DB에 전달가능하다.
사용방법:
커넥션을 조회 -> 이미 생성되어 있는 커넥션을 객체 참조로 가져다 쓰면 됨 -> 쓰고나서 커넥션 풀에 반납(종료 X)
스프링 부트에서는 기본적으로 커넥션 풀을 hikariCP를 사용한다.
DataSource
이전에 커넥션을 얻을때, DriverManager를 직접 사용해서 Connection con = getConnection(URL,USERNAME,PASSOWRD)으로 커넥션을 얻었다.
만약 애플리케이션이 직접 DriverManager를 바라보고 있다면, DriverManager에서 HikariCP로 바꾸면 애플리케이션 로직을 전부 직접 다 바꿔야할것이다.
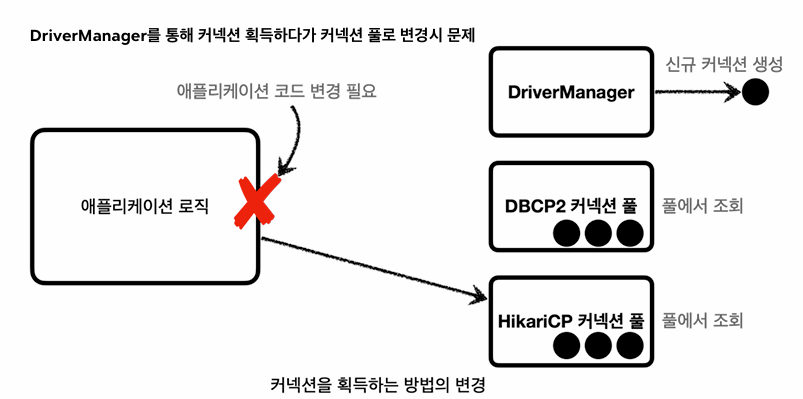
고로, 커넥션을 획득하는 방법을 추상화 해야한다.
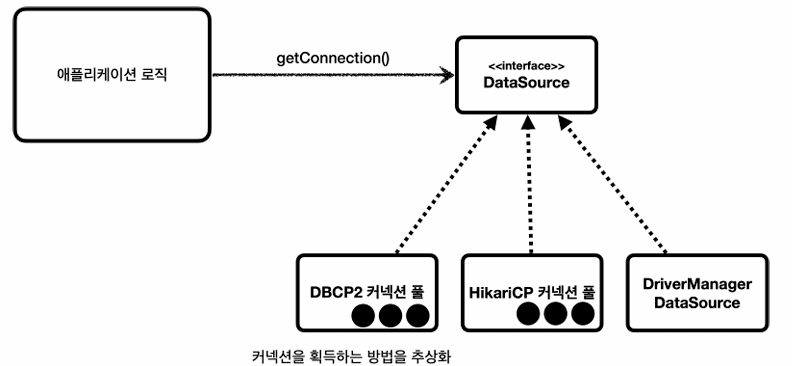
자바에서 이런 문제를 해결하기위해서 DataSource라는 인터페이스를 제공한다.
DataSource는 커넥션을 획득하는 방법을 추상화하는 인터페이스이다.
고로, 우리는 HikariCP 커넥션 풀의 코드를 직접 의존하는게 아니라 DataSource인터페이스에만 의존하도록 애플리케이션 로직을 작성하면 된다.
DriverManager는 DataSource인터페이스를 사용하지 않는다. 직접 사용해야한다. 고로, DriverManager를 사용하다가 DataSource기반의 커넥션 풀을 사용하도록 변경하면 관련 코드를 다 수정해야하므로, 이걸 해결하기 위해서 DriverManager도 DataSource를 통해서 사용할 수 있도록 DrvierManagerDataSource를 제공한다.
커넥션 코드
//Drivermanager로 직접 커넥션맺음
Connection con1 = DriverManager.getConnection(URL, USERNAME, PASSWORD);
Connection con2 = DriverManager.getConnection(URL, USERNAME, PASSWORD);
//DataSource이용 - DrvierManagerDataSource 사용
DriverManagerDataSource dataSource = new DriverManagerDataSource(URL,
USERNAME, PASSWORD);
useDataSource(dataSource);
//Hikari사용
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(URL);
dataSource.setUsername(USERNAME);
dataSource.setPassword(PASSWORD);
dataSource.setMaximumPoolSize(10);
dataSource.setPoolName("MyPool");
useDataSource(dataSource);
//DataSource인터페이스로 파라미터 설정
private void useDataSource(DataSource dataSource) throws SQLException {
Connection con1 = dataSource.getConnection();
Connection con2 = dataSource.getConnection();
log.info("connection={}, class={}", con1, con1.getClass());
log.info("connection={}, class={}", con2, con2.getClass());
}DataSource적용
@Slf4j
class MemberRepositoryV1Test {
MemberRepositoryV1 repository;
@BeforeEach
void beforeEach(){
//Driver Manager사용
//DriverManagerDataSource dataSource = new DriverManagerDataSource(URL,USERNAME,PASSWORD);
//히카리사용
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(URL);
dataSource.setPassword(PASSWORD);
dataSource.setUsername(USERNAME);
repository = new MemberRepositoryV1(dataSource);
}
...@Slf4j
public class MemberRepositoryV1 {
private final DataSource dataSource;
public MemberRepositoryV1(DataSource dataSource) {
this.dataSource = dataSource;
}
...리포지토리에서 커넥션을 가져올때 DriverManagerDataSource를 사용할지, HikariCp를 사용할지 모른다.
그러므로 이런 구현체에 리포지토리가 의존하면안된다.
그래서 MemberRepository에서 DataSource 인터페이스에 의존하는것을 볼 수 있다.
원하고자하는 DataSource구현체를 만든다음에, Repository생성자 주입할때 구현체를 넘겨준다.
생성자 주입에서 인터페이스로 받기때문에, 구현체로 어떤것이 오더라도 애플리케이션 로직 부분을 바꿀이유가 없다. 이것이 DataSource를 사용하는 장점이다.
트랜잭션
트랜잭션은 하나의 요청을 안전하게 처리하도록 보장해주는것을 뜻한다.
A가 5000원을 B한테 이체한다고 치자.
- A의 잔고 5000원 감소
- B의 잔고 5000원 증가
그런데 1번만 성공하고, 2번은 실패하면 문제가 된다.
중간에 하나라도 실패하면 거래 전의 상태로 롤백되어야한다.
ACID
- Atomicity: 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인것처럼 모두 성공하거나 모두 실패해야한다.
- Consistency: 모든 트랜잭션은 일관성있는 데이터베이스 상태를 유지해야한다. ex). 데이터베이스에서 정한 무결성 제약 조건을 항상 만족해야한다.
- Isolation: 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다. ex). 동시에 같은 데이터를 수정하지 못하도록한다. 격리수준 선택가능
- Durability: 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야한다. 중간에 시스템에 문제가 발생해도 로그를 통해 성공한 트랜잭션의 내용을 복구해야한다.
데이터베이스 연결구조와 DB세션
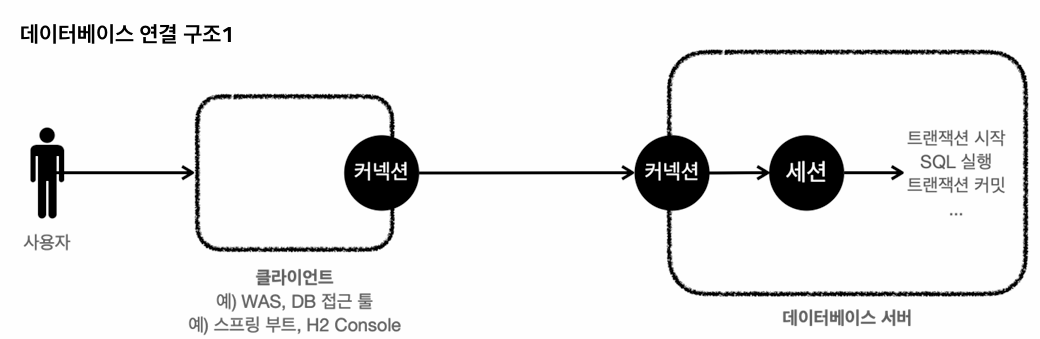
사용자가 DB 서버에 접근해야하면 데이터베이스 서버에 요청을 보내고 커넥션을 맺는다.
이때 세션을 만든다.
앞으로 해당 커넥션을 통한 모든 요청은 해당 세션을 통해서 수행된다.
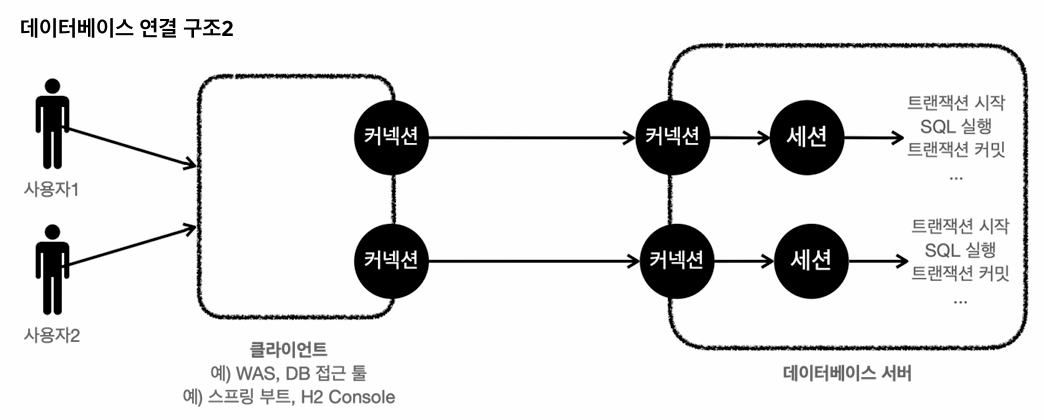
커넥션 풀이 10개의 커넥션을 생성하면, 세션도 10개 만들어진다.
대부분의 DB는 auto commit = ture로 설정되어있다.
트랜잭션 기능을 수행하기 위해서는 수동 커밋을 사용해야한다.
세션 A가 아래의 쿼리를 실행
set autocommit false;
insert into member(member_id,money) values ('data3',1000);
insert into member(member_id,money) values ('data4',1000);commit을 치지 않았으므로,
세션 B에서 data3,data4를 확인 할 수 없다.
commit을해야 해당 내용을 세션 B에서 확인 가능하다.
DB락
세션 A가 트랜잭션을 시작하고, 커밋을 하지 않았는데 세션 B가 동시에 같은 데이터에 접근하게 되면, 문제가 발생한다. 원자성이 깨지게 된다.
세션이 트랜잭션을 시작하고 데이터에 접근할때는 커밋이나 롤백전까지 다른 세션이 해당 데이터 접근을 막아야한다.
세션 A
set autocommit false;
update member set money=500 where member_id = 'memberA';아직 커밋을 안함 memberA에 락을 걸어둔상태
세션 B
SET LOCK_TIMEOUT 60000;
set autocommit false;
update member set money=1000 where member_id = 'memberA';세션 A가 락을 풀지 않았으므로 쿼리가 수행되지 않고 대기
트랜잭션 주요기능
트랜잭션을 적용하기 위해서는 하나의 비즈니스 로직 전체에 트랜잭션을 걸어야한다.
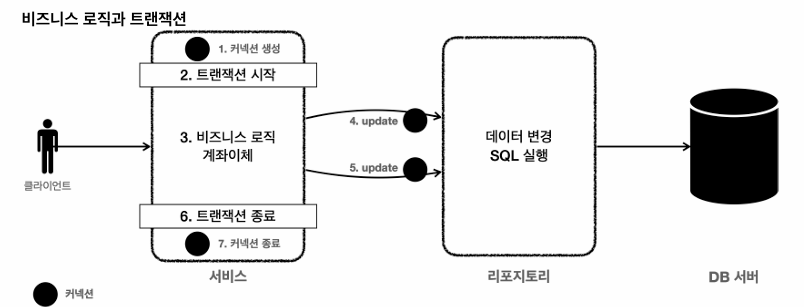
트랜잭션은 비즈니스 로직이 있는 서비스 계층에서 시작,
비즈니스 로직 오류 발생 -> 해당 서비스 전체가 rollback되어야함
트랜잭션을 시작하려면, set auto commit false를 해야하므로, 서비스 계층에서 커넥션을 만들고, 커밋,롤백 후 커넥션 종료
트랜잭션을 사용하는동안 같은 커넥션을 유지해야한다.
트랜잭션 추상화
@Slf4j
@RequiredArgsConstructor
public class MemberServiceV2 {
private final DataSource dataSource;
private final MemberRepositoryV2 memberRepositoryV2;
public void accountTransfer(String fromId, String toId, int money) throws SQLException {
Connection con = dataSource.getConnection();
try{
con.setAutoCommit(false);
bizLogic(con,fromId,toId,money);
}catch (Exception e){
con.rollback();
throw new IllegalStateException(e);
}finally {
release(con);
}
}
private void release(Connection con) {
if (con != null){
try{
con.setAutoCommit(true);
con.close();
} catch (Exception e) {
log.info("error",e);
}
}
}
private void bizLogic(Connection con, String fromId, String toId, int money) throws SQLException {
Member fromMember = memberRepositoryV2.findById(con,fromId);
Member toMember = memberRepositoryV2.findById(con,toId);
memberRepositoryV2.update(con,fromId,fromMember.getMoney()-money);
validation(toMember);
memberRepositoryV2.update(con,toId,toMember.getMoney()+money);
}
private void validation(Member toMember) {
if (toMember.getMemberId().equals("ex")){
throw new IllegalArgumentException("이체중 예외발생");
}
}
}서비스계층에서 getConnection()메서드 호출로 커넥션을 얻고, bizLogic()메서드 호출로 비즈니스 로직을 수행하였다.
문제는 우리는 서비스 계층에는 순수한 비즈니스 로직만 존재하게 하고싶은데, 트랜잭션을 사용하면서, 특정 기술에 의존적이게 된다는것이다.
- try catch에서 SQLException에 의존하고있고
- 여기서는 JDBC 트랜잭션 코드를 사용하였지만, JPA에서 트랜잭션을 시작하는 코드가 다르다. 엔티티 메니저를 얻고 em.getTransaction()을 해야함.
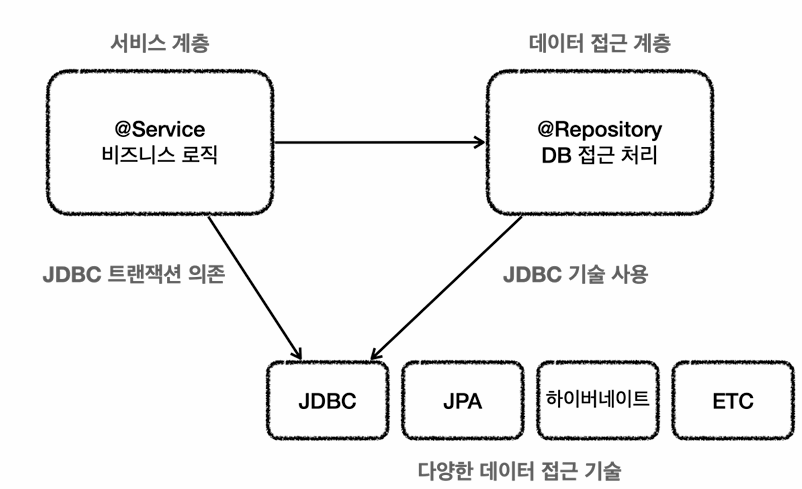
그림과같이 서비스와 repository둘다 JDBC 기술에 의존하여 JDBC 트랜잭션을 사용하였는데,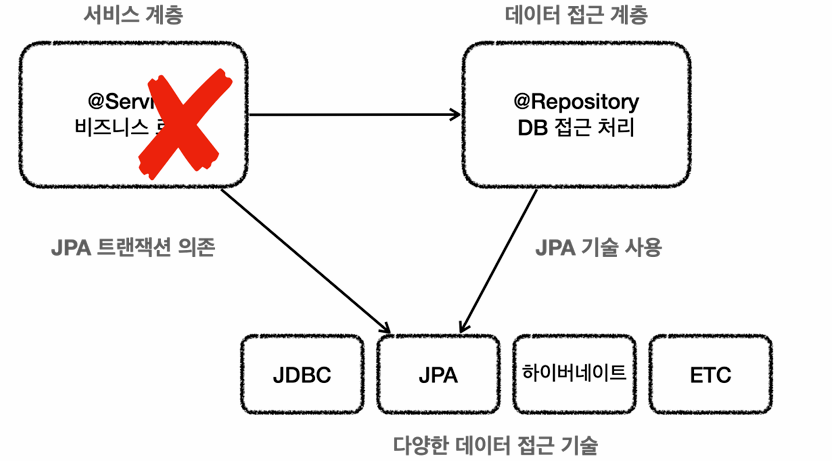
JPA기술로 바꾸면 Service코드 또한 JPA트랜잭션에 의존하도록 전부 수정해야한다.
고로, 트랜잭션을 추상화하고, 각각의 기술에 맞는 구현체를 바꿔 끼우면 된다.
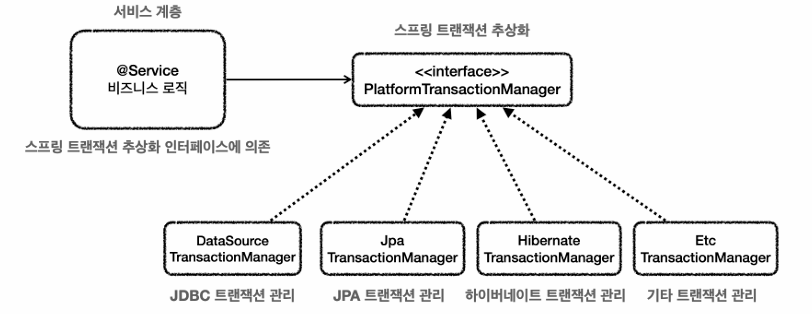
그림처럼 서비스는 트랜잭션 추상화 인터페이스에만 의존하면된다. 스프링이 이미 JPA 트랜잭션 매니저, DataSourceTransactionManager등을 구현을 해두었다.
public interface PlatformTransactionManager extends TransactionManager {
TransactionStatus getTransaction(@Nullable TransactionDefinition definition) throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}우리는 서비스에서 getTransaction,commit(),rollback()만 쓰면된다.
트랜잭션 동기화
JDBC를 이용하는 개발자가 직접 여러개의 작업을 하나의 트랜잭션으로 관리하려면 Connection객체를 공유하는등 상당히 불필요한 작업들이 많이 생길 거다.
예를 들어 커넥션을 서비스에서 만들면, 리포지토리에서 해당 커넥션을 이용하기위해서 리포지토리의 .save()메서드 호출시 파라미터로 항상 커넥션을 넘겨줘야 할것이다.
이러한 문제를 해결하고자 트랜잭션 동기화 기술을 스프링이 제공한다.
쓰레드 로컬을 사용해서 커넥션 동기화를 하는데, 쓰레드마다 별도의 저장소가 부여되어 해당 쓰레드만 데이터 접근가능하다.
동시에 쓰레드가 같은 커넥션을 사용하는 문제가 발생하지 않는다.
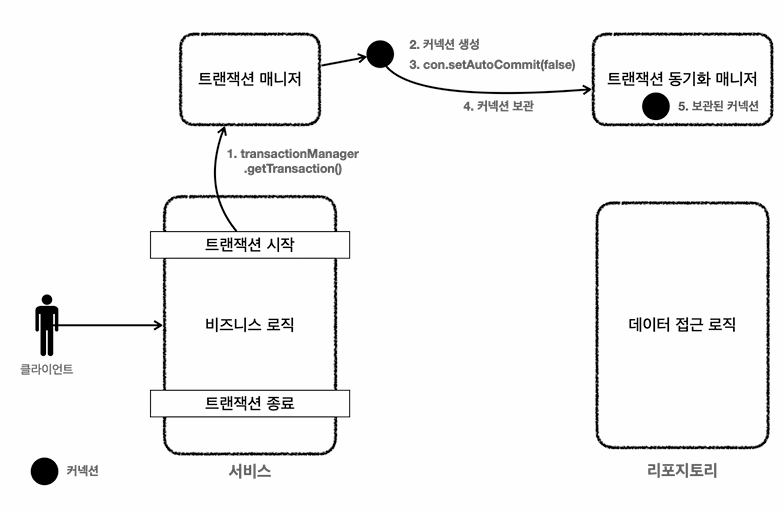
- 서비스 계층에서 transactionManager.getTransaction() 호출해서 트랜잭션 시작
- 트랜잭션을 시작하기 위해서 데이터베이스 커넥션이 필요, 트랜잭션 매니저가 내부에서 데이터 소스를 사용해서 커넥션 생성
- 커넥션을 autocommit false로 변경
- 해당 커넥션을 트랜잭션 동기화 매니저에 보관
- 트랜잭션 동기화 매니저가 쓰레드 로컬에 커넥션 보관
로직수행
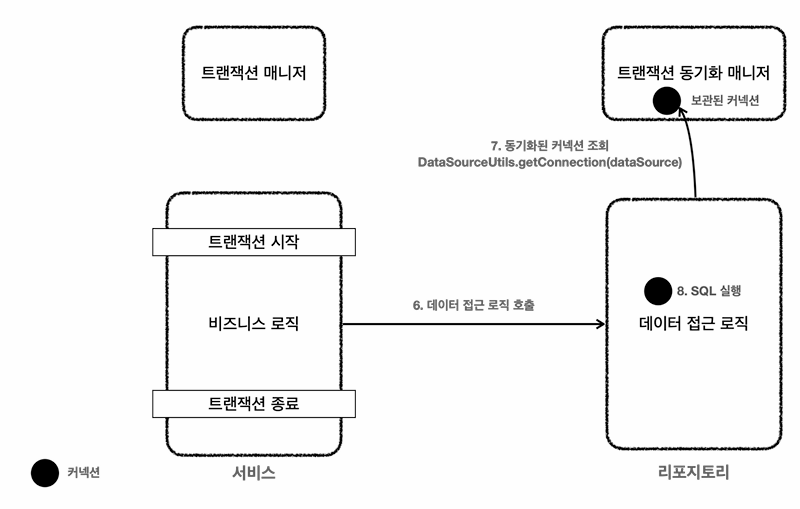
6. 서비스가 리포지토리의 메서드 호출 -> 이때 커넥션을 파라미터로 전달 x
7. 트랜잭션 동기화 매니저가 관리하는 쓰레드를 꺼내서 리포지토리가 사용
8. 획득한 커넥션을 사용하여 SQL을 DB에 전달
트랜잭션 종료
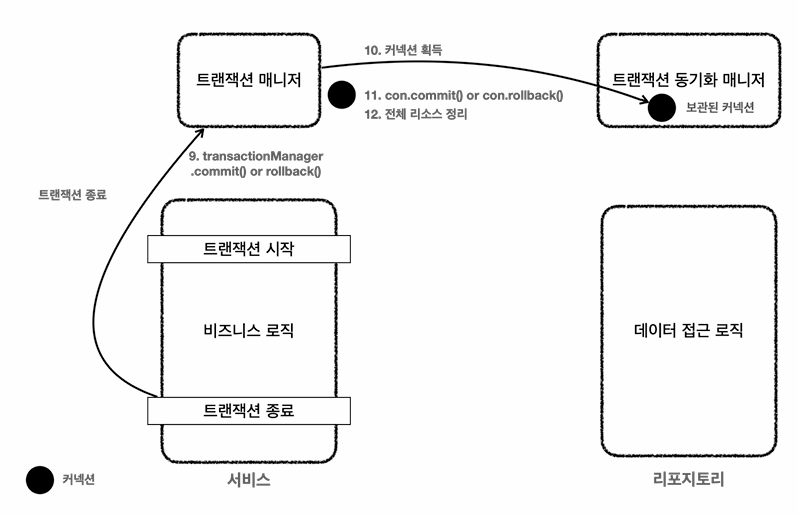
9. 커밋,롤백시 트랜잭션 종료
10. 트랜잭션 동기화 매니저를 통해서 동기화된 커넥션 획득
11. 획득한 커넥션을 통해 DB에 트랜잭션을 커밋 또는 롤백함
12. 전체 리소스 종료 autocommit을 true로 만들고 con.close 호출로 커넥션 종료-> 커넥션 풀에 반환
AOP를 이용한 트랜잭션(Transaction) 분리
스프링 AOP를 통해 프록시를 도입하면,
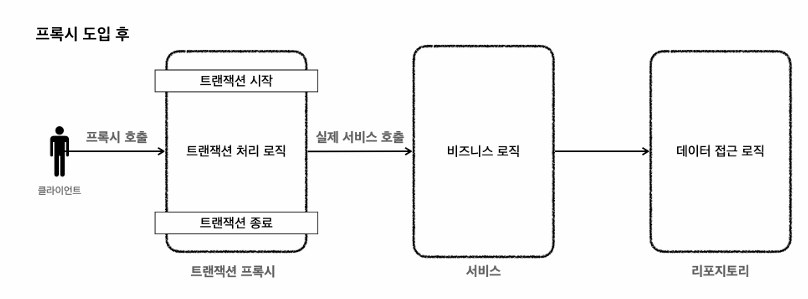
트랜잭션만을 처리하는, 트랜잭션 프록시 객체가 트랜잭션 처리 로직을 모두 가져간다.
스프링이 제공하는 트랜잭션 AOP는 스프링 빈에 등록된 트랜잭션 매니저를 찾아서 사용한다.
@Bean
DataSource dataSource() {
return new DriverManagerDataSource(URL, USERNAME, PASSWORD);
}
@Bean
PlatformTransactionManager transactionManager() {
return new DataSourceTransactionManager(dataSource());
}어? 그런데 우리는 dataSource나 TransactionManager를 등록해준적이 없다.
application.properties
spring.datasource.url=jdbc:h2:tcp://localhost/~/test
spring.datasource.username=sa
spring.datasource.password=스프링 부트는 application.properties에 있는 속성을 사용해서 DataSource를 생성한다.
트랜잭션 매니저 - 자동등록
스프링 부트가 적절한 트랜잭션 매니저를 자동으로 등록한다.
어떤 트랜잭션 매니저를 선택할지 현재 등록된 라이브러리를 보고 판단한다.
- JDBC 사용하면 -> DataSourceTransactionManager
- JPA 사용하면 -> JpaTransactionManager
- 둘다 사용 -> JpaTransactionManager(JDBC기술 지원)
예외처리
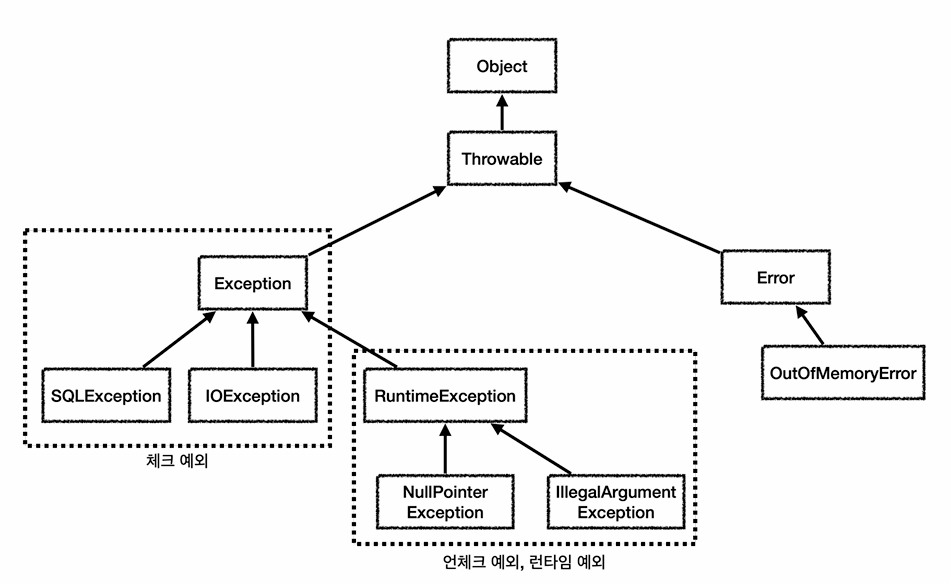
- Object: 예외도 객체다. 모든 객체의 최상위 부모는 Object이다.
- Throwable: 최상위 예외. 하위에 Exception과 Error가있음
- Error: 메모리부족, 심각한 시스템 오류같이 복구 불가능한 예외 -> 개발자는 이 예외를 잡으려 하면 안된다.
- Exception: 체크 예외
컴파일러가 체크하는 예외
애플리케이션 로직에서 사용할 수 있는 실질적이 최상위 예외
-> Throwable을 예외로 잡아버리면 하위 예외까지 잡으므로 Error가 잡혀서 안됨 - RuntimeException: 언체크 예외, 런타임 예외
컴파일러가 체크하지 않는 예외, 하위 자식들 보두 언체크 예외
예외의 기본규칙 2가지
- 예외는 잡아서 처리하거나 던져야한다.
- 예외를 잡아서 던질때 지정한 예외 뿐만 아니라, 그 예외의 자식들도 함께 처리가 된다.
-> Exception을 잡거나 던지면, 그 하위예외도 모두 잡거나 던질 수 있다.
체크 예외
모든 예외는 잡아서 처리하거나, 던져야한다.
단, 체크 예외는 던질때 메서드명() throws예외를 지정해줘야한다.
언체크 예외
언체크 예외를 던질때는 굳이 throw로 명시하지 않아도 알아서 던져준다.
참고로, throws로 명시해줘도 된다. 그냥 개발자한테 이런 예외를 던질거라는것을 알려주는 용도.
체크예외를 써야할까? 언체크 예외를 써야할까?
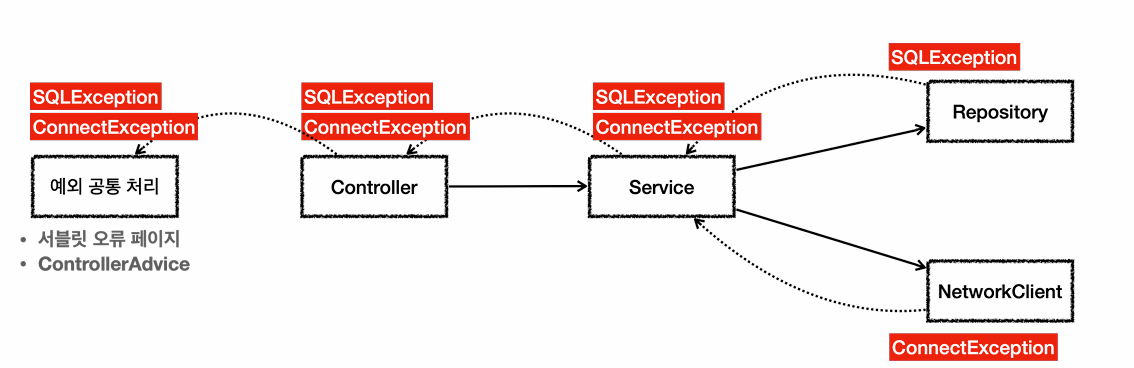
Repository와 NetworkClient에 SQLException,ConnectionException이 각각 터진다고 가졍해보자.
둘다 체크예외이면, Service와 Controller가 해결할수 없음에도 throws를 선언하여 던져야한다.
또한, 의존관계에 대한 문제가 생기는데, Service와 Controller에서 throws를 통해 던지는 예외를 선언하면, java.sql.SQLException에 의존하고 있는데,
향후 리포지토리를 JDBC기술이 아니라 JPA로 바꾸면, SQLException -> JPAException으로 예외를 Service와 Controller에서 모든 코드를 뜯어 고쳐야한다.
SQLException,ConnectionException대신 최상위 예외 Exception을 던지면 안되는 이유
-> 가장 최상위 타입 Exception을 던지면, 중간에 정작 진짜 잡아서 처리해야하는 오류를 Exception으로 뭉뜽그려서 처리하면 원하는 오류 처리 로직을 만들 수 없기 때문이다.
언체크 예외를 사용하면 throws를 선언하지 않아도 되므로, Service나 컨트롤러에 특정 기술에 의존적인 부분이 사라진다.
@Slf4j
public class MemberServiceV4 {
private final MemberRepository memberRepository;
public MemberServiceV4(MemberRepository memberRepository) {
this.memberRepository = memberRepository;
}
@Transactional
public void accountTransfer(String fromId, String toId, int money) {
bizLogic(fromId, toId, money);
}
private void bizLogic(String fromId, String toId, int money) {
Member fromMember = memberRepository.findById(fromId);
}
....
}@Slf4j
public class MemberRepositoryV4_1 implements MemberRepository {
private final DataSource dataSource;
public MemberRepositoryV4_1(DataSource dataSource) {
this.dataSource = dataSource;
}
public Member findById(String memberId) {
String sql = "select * from member where member_id = ?";
PreparedStatement pstmt = null;
ResultSet rs = null;
Connection con = null;
try {
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1, memberId);
rs = pstmt.executeQuery();
if (rs.next()) {
Member member = new Member();
member.setMemberId(rs.getString("member_id"));
member.setMoney(rs.getInt("money"));
return member;
} else {
throw new NoSuchElementException("member not found memberId=" + memberId);
}
}catch (SQLException e){
throw new RuntimeException(e);
}finally {
close(con,pstmt,rs);
}
return null;
}
private void close(Connection con, Statement stmt, ResultSet rs) {
JdbcUtils.closeResultSet(rs);
JdbcUtils.closeStatement(stmt);
DataSourceUtils.releaseConnection(con,dataSource);
}
private Connection getConnection() throws SQLException {
Connection con = DataSourceUtils.getConnection(dataSource);
log.info("get Connection = {}, class = {}",con,con.getClass());
return con;
}
}이런식으로, Repository에서 발생하는 체크예외를 런타임예외로 변환하면서, 인터페이스와 서비스계층의 순수성에 유지 할수 있다.
만약에 throws로 던지는게 아니라, 특정 예외는 복구해서 처리하고 싶으면 어떻게해야할까?
예를 들어 pk Id가 들어왔으면 랜덤으로 숫자를 붙여서 Id를 만들어줄때, 동일한 Pk인 경우 SQLException code:23505를 던진다.
우리는 해당 SQLException(체크예외)이 아니라 언체크예외(MyDuplicateKeyException)로 변환해서 처리할 것이다.
//런타임예외 상속
public class MyDbException extends RuntimeException{
public MyDbException(){
}
public MyDbException(String message) {
super(message);
}
public MyDbException(String message, Throwable cause) {
super(message, cause);
}
public MyDbException(Throwable cause) {
super(cause);
}
}@RequiredArgsConstructor
static class Repository{
private final DataSource dataSource;
public Member save(Member member){
String sql = "insert into member(member_id,money) values(?,?)";
Connection con = null;
PreparedStatement pstmt = null;
try {
con = dataSource.getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setString(1,member.getMemberId());
pstmt.setInt(2,member.getMoney());
pstmt.executeUpdate();
return member;
}catch (SQLException e){
if(e.getErrorCode() == 23505){
throw new MyDuplicateKeyException(e);
}
throw new MyDbException(e);
}finally {
JdbcUtils.closeStatement(pstmt);
JdbcUtils.closeConnection(con);
}
}
}중요!!: 기존 오류인 SQLException을 가져와서 넣어줘야 기존의 오류를 확인 할 수 있다.
SQLException은 체크예외인데 런타임예외로 바꾼것을 확인 할 수 있다.
@Slf4j
@RequiredArgsConstructor
static class Service{
private final Repository repository;
public void create(String memberId){
try{
repository.save(new Member(memberId,0));
log.info("saveId={}",memberId);
}catch (MyDuplicateKeyException e){
log.info("키 중복, 복구 시도");
String retryId = generateNewId(memberId);
log.info("retryId={}",retryId);
repository.save(new Member(retryId,0));
}catch (MyDbException e){
log.info("데이터 접근 계층 예외",e);
throw e;
}
}
private String generateNewId(String memberId) {
return memberId + new Random().nextInt(10000);
}
}서비스에서 MyDuplicateKeyException이 날라온 경우 새롭게 save메서드를 호출하면된다.
그런데 문제가 있다. SQL Error Code는 각 DB마다 다르다. H2를 사용하다가, Mysql로 바꾸면 키 중복 오류코드가 바꾼다.
이러면 또 Repository의 오류코드를 수정해줘야한다.
이를 해결하기 위해서 스프링이 데이터 접근과 관련된 예외를 추상화 해서 제공한다.
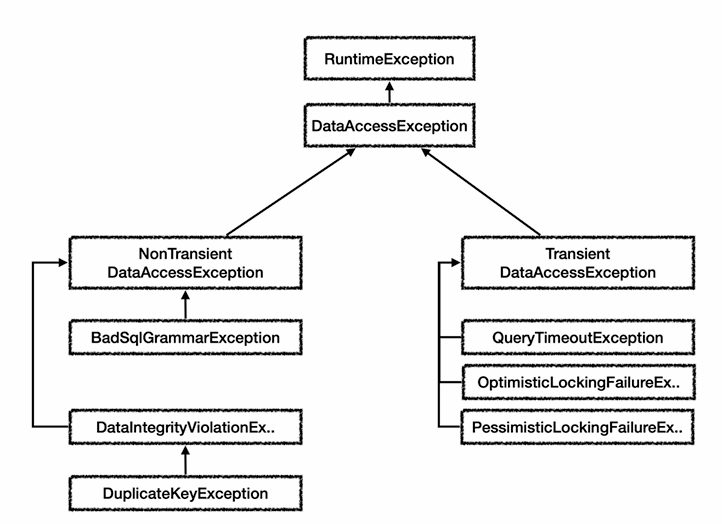
- 각각의 예외들은 특정 기술에 종속적이지 않게 설계, JDBC사용하던 JPA를 사용하던 스프링이 제공하는 예외를 사용하면 된다.
- 최상위는 DataAccessException, RuntimeException을 상속받았으므로 스프링이 제공하는 데이터 접근 계층의 모든 예외는 RuntimeException이다.
- Transient: 일시적 -> 다시 동일한 SQL 실행시 성공할 수도 있음
- NonTransient: 반복해도 실패
TestCode
public class SpringExceptionTranslatorTest {
DataSource dataSource;
@BeforeEach
void init(){
dataSource = new DriverManagerDataSource(URL,USERNAME,PASSWORD);
}
@Test
void exceptionTranslator(){
String sql = "select bad grammer";
try{
Connection con = dataSource.getConnection();
PreparedStatement pstmt = con.prepareStatement(sql);
pstmt.executeQuery();
}catch (SQLException e){
SQLExceptionTranslator exceptionTranslator = new SQLErrorCodeSQLExceptionTranslator(dataSource);
DataAccessException resultEx = exceptionTranslator.translate("select",sql,e);
assertThat(resultEx.getClass()).isEqualTo(BadSqlGrammarException.class);
}
}
}눈에보이는 반환은 최상위 타입인 DataAccessException이지만, 실제로는 구현된 BadSqlGrammarException이 반환된다.
그런데, H2에서의 SqlError코드와 Mysql의 SqlError코드가 서로 다른데 어떻게 스프링은 각 DB마다 에러코드를 보고 해당 오류에 맞는 에러를 반환해줄까?
sql-error-codes.xml
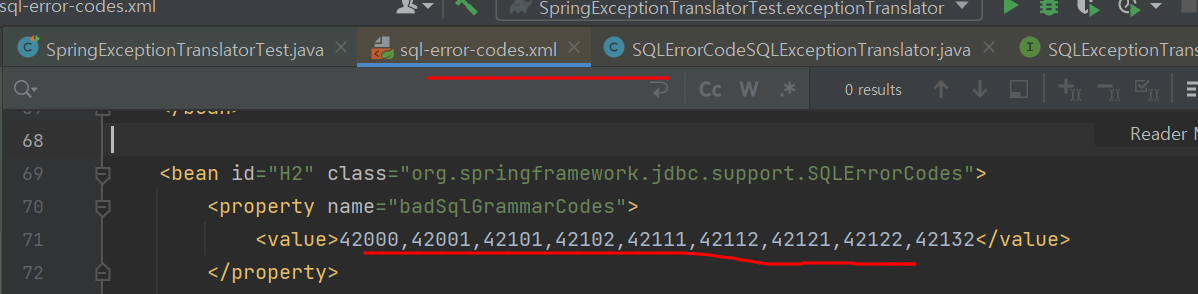
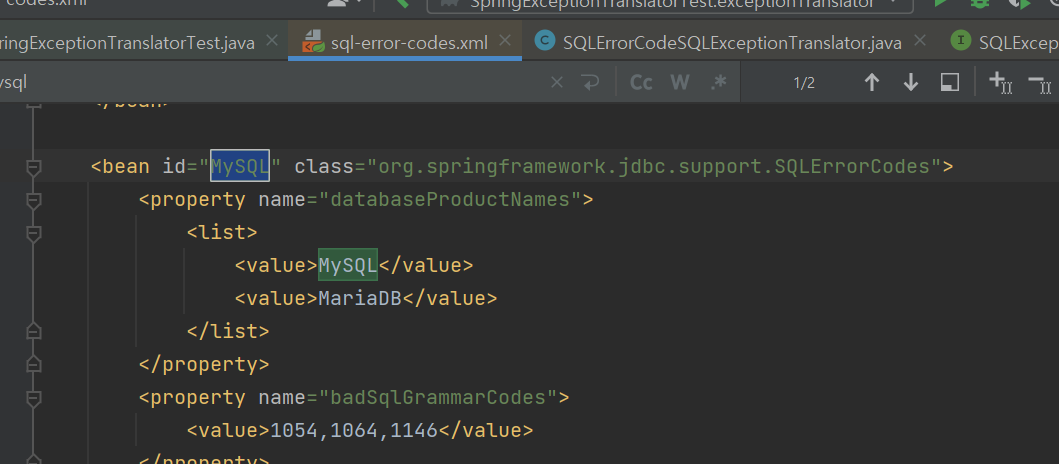
특별히 다른게 없고, 각 DB에 해당하는 에러코드를 파일에 노가다로 넣어둔 것이다.
그래서 에러가 터지면, 스프링이 해당 파일에서 에러코드를 뒤져서 해당 DB에 맞는 에러를 반환해준다.
@Slf4j
public class MemberRepositoryV4_2 implements MemberRepository {
private final DataSource dataSource;
private final SQLExceptionTranslator exceptionTranslator;
public MemberRepositoryV4_2(DataSource dataSource) {
this.dataSource = dataSource;
this.exceptionTranslator = new SQLErrorCodeSQLExceptionTranslator(dataSource);
}
public Member save(Member member) {
String sql = "insert into member(member_id, money) values(?, ?)";//sql쿼리문
Connection con = null;
PreparedStatement pstmt = null;
try {
con = getConnection(); // 커넥션맺고
pstmt = con.prepareStatement(sql); //PreparedStatement로 sql날림
pstmt.setString(1, member.getMemberId()); //?부분 바인딩
pstmt.setInt(2, member.getMoney());
pstmt.executeUpdate(); //실행
return member;
} catch (SQLException e){
throw exceptionTranslator.translate("save",sql,e);
}finally {
//항상 finally에 connection종료
close(con,pstmt,null);
}
}SQLExceptionTranslator는 인터페이스 이므로 생성자 주입을 통해 구현체를 SQLErrorCodeSQLExceptionTranslator로 설정하고, dataSource를 넘겨준다.
정리
SQLException같은 상위 예외 가 발생
- 내가 예외를 커스텀해서 사용하고 싶다. 런타임예외를 상속받은 예외 만들어서 처리
- SQLException에서 예외를 구체화하고 싶다. -> BadSqlGrammarException,DuplicateKeyException등등 으로
해당 오류에대한 오류코드를 각 DB마다 이미 SQLExceptionTranslator가 가지고 있으므로(내가 모든 오류코드를 외워서 try catch할 수 없음),
SQLExceptionTranslator에다가 SQLException을 전달해주면 해당 DB에 맞춰서 오류코드와 세부 예외를 가져올 수 있음
당연히 SQLExceptionTranslator가 던지는 예외는 모두 런타임 예외이다.
JDBCTemplate
리포지토리 메서드를 보면
public void update(String memberId,int money){
String sql = "update member set money=? where member_id=?";
Connection con = null;
PreparedStatement pstmt = null;
try {
con = getConnection();
pstmt = con.prepareStatement(sql);
pstmt.setInt(1,money);
pstmt.setString(2,memberId);
int resultSize = pstmt.executeUpdate();
log.info("resultSize = {}",resultSize);
} catch (SQLException e) {
throw exceptionTranslator.translate("update",sql,e);
}finally {
close(con,pstmt,null);
}
}항상 서비스에서 만든 커넥션을 가져와서 try catch하고 finally에 close하고 이런게 반복되어있다.
@Slf4j
public class MemberRepositoryV5 implements MemberRepository {
private final JdbcTemplate template;
public MemberRepositoryV5(DataSource dataSource) {
this.template = new JdbcTemplate(dataSource);
}jdbc템플릿에 dataSource를 넘겨서 주입
public Member save(Member member) {
String sql = "insert into member(member_id, money) values(?, ?)";//sql쿼리문
template.update(sql,member.getMemberId(),member.getMoney());
return member;
}더 편하게 jdbc를 다룰 수 있다.
트랜잭션과 테스트
@Transactional을 적용하면, 중간에 테스트가 강제로 종료되거나, 테스트가 종료되면,
커밋을 하지 않고 롤백을 적용한다.
그렇게 해서, 테스트를 수행하더라도, 테스트 내의 데이터를 저장하지 않는다.
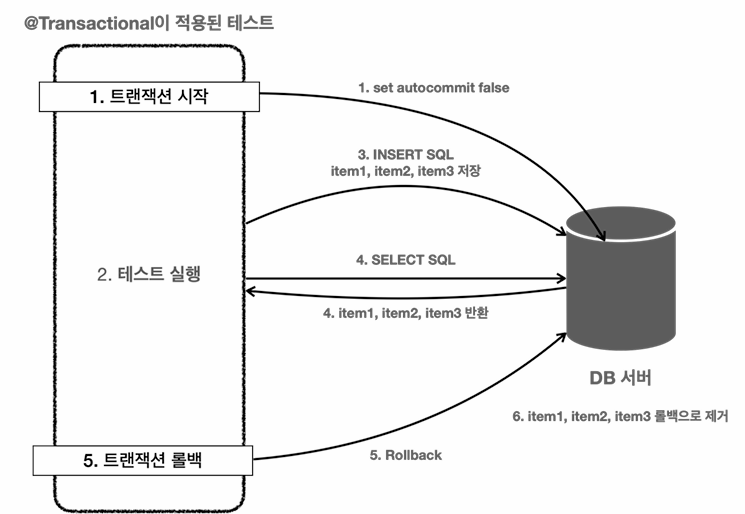
원래 inset SQL도 쓰기지연 저장소에 있다가 flush하거나 commit을 쳐야 해당 쿼리를 날리는데, 롤백하므로 DB에 저장되지 않는다.
어? 그런데 중간에 로직에서 DB에 저장을 하지 않았는데, 어떻게 findById 같은 메서드로 DB에서 엔티티를 불러오냐?
하나의 테스트 안에서는 트랜잭션 동기화 매니저에서 커넥션을 가져다 사용하므로, 같은 커넥션을 사용한다.
고로, 커밋을 치지 않아도, 동일한 트랜잭션이라 데이터를 볼 수 있다.
임베디드 모드
Test DB와 운영 DB를 분리해서 Test하면 좋지만, 너무 비용이 많이들고 복잡하다.
마치 메모리에 올리는것처럼, 동작하게 할 수 있는 방법이 없을까? -> 임베디드 모드
임베디드 모드를 사용하면, In-Memory모드와 달리 데이터가 PC에 저장된다.
Embedded모드를 사용할때는 H2 DB의 연결주소와, JPA의 테이블 생존전략을 Update로 변경해줘야한다.
왜냐하면 메모리 DB에는 Table을 아직 만들기 전상태이기때문에 update를 통해서 Table을 자동으로 만들어주거나, 혹은 update를 사용하기 싫다면, src/test/resources/schema.sql 여기다가 Table create sql을 만들어놓으면 스프링부트가 해당 쿼리문을 보고 Table을 만든다.
임베디드 모드를 직접사용할때는 jdbc:h2:mem:db...로 mem을 적어줘야한다.
임베디드 모드를 직접 사용하는게 아닌 스프링 부트는 데이터베이스에 대한 별다른 설정이 없으면 임베디드 데이터베이스를 사용한다.
test-application.properties에 DB에 대한 설정정보를 아무것도 넣지 않으면, 스프링 부트는 임베디드 모드로 접근하는 데이터 소스를 만들어서 제공한다.
실행시켜보면 conn0: url = jdbc:h2:memb:d8fb3a29-car7...이렇게 mem뒤에 임의의 데이터베이스 이름이 들어가 있는데, 같은 데이터베이스를 사용하면서 발생하는 충돌을 막기위해서 스프링부트가 임의의 이름을 부여한 것이다.
@Repository와 예외변환
JPA의 경우 예외가 발생하면 JPA 예외가 발생한다.
만약 이미 DB에 id가 1인 엔티티가 존재하는데 id가 1인 새로운 엔티티를 저장하면 pk가 1로 동일하므로 persistenceException이라는 JPA예외를 던지게 된다.
서비스에서
try{
}catch(persistenceException e){
}
이런식으로 잡아버리면 서비스가 JPA에 종속적이게 된다.
그러나 실재로 실행을시켜보면 스프링 예외 추상화 DataAccessException이 터진다.
왜일까?
- @Repository의 기능
해당 애노테이션이 붙은 클래스는 컴포넌트 스캔의 대상이 된다.
해당 애노테이션이 붙은 클래스는 예외 변환 AOP의 적용대상이 된다.
스프링과 JPA를 같이 쓰는 경우 스프링이 JPA예외변환기 PersistenceExceptionTranslator를 등록한다.
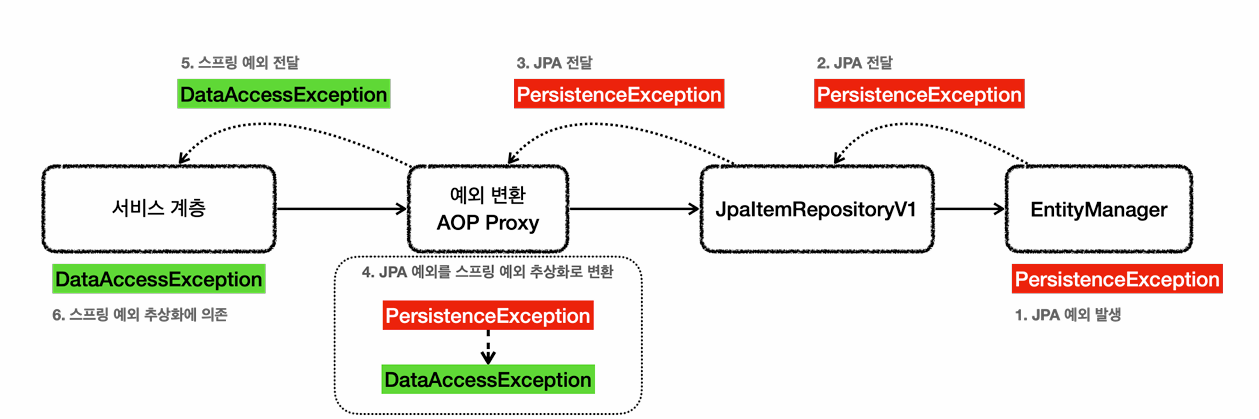
즉 JPA 리포지토리 메서드 안에서는 JPA예외가 터지는데 밖으로 서비스 계층까지 예외를 던질 때에는 프록시가 대신 스프링 예외 변환으로 바꾸어서 던져주는 것이다.
DB2편
스프링 트랜잭션 이해
트랜잭션의 필요성
1. 스프링 트랜잭션 추상화
JDBC와 JPA의 트랝개션 코드가 서로 다르다.
서비스에서 트랜잭션 수행시, JDBC -> JPA면 서비스 모든 코드를 뜯어 고쳐야함
스프링 PlatformTransactionManager라는 인터페이스로 트랜잭션 추상화
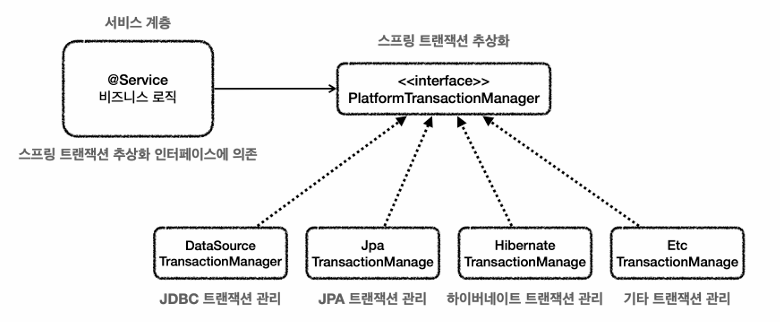
인터페이스에 대한 구현체도 제공.
우리는 라이브러리만 다운받으면, 스프링부트가 어떤 데이터 접근기술을 사용하는지 자동으로 인식해서 적절한 트랜잭션 매니저(구현체) 선택후, 빈으로 등록까지 다해준다.
예를들어 jdbcTemplate,MyBatis를 사용하면 DataSourceTransactionmanager를 빈으로 등록, JPA를 사용하면 JpaTranasactionManager를 빈으로 등록한다.
- PlatformTransactionManager사용법
@Transactional 애노테이션만 사용하면됨, 대부분사용
앞에서 한것처럼 트랜잭션 매니저를 직접 등록해서 사용 - @Transactional 동작방식
원래 서비스계층에서 직접 트랜잭션 사용
TransactionStatus status = transactionManager.getTransaction(new
DefaultTransactionDefinition());
try {
//비즈니스 로직
bizLogic(fromId, toId, money);
transactionManager.commit(status); //성공시 커밋
} catch (Exception e) {
transactionManager.rollback(status); //실패시 롤백
throw new IllegalStateException(e);
}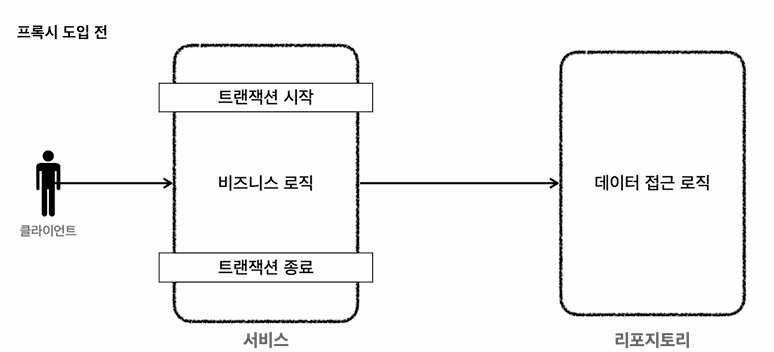
트랜잭션을 처리하기 위한 프록시 사용 -> 트랜잭션 프록시가 트랜잭션 코드를 모두 가져가므로, 서비스에는 순수한 비즈니스로직만 남음
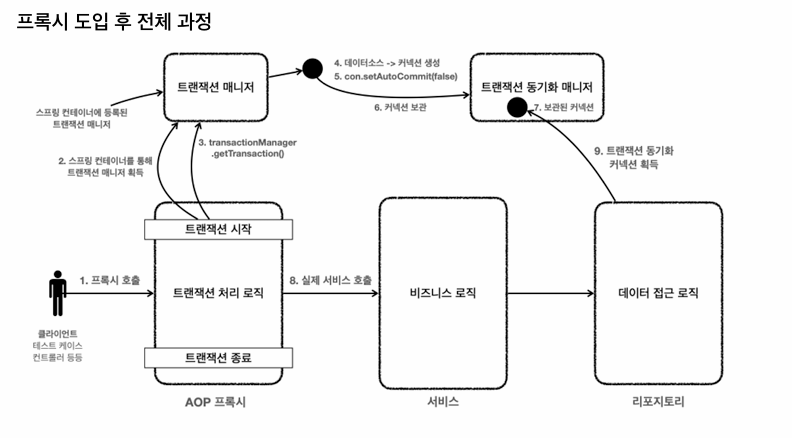
- 트랜잭션은 항상 트랜잭션 매니저가 수행
이 트랜잭션 매니저를 프록시가 부르느냐, 서비스로직에 직접 작성해서 서비스가 부른느냐 이차이.
동일한 트랜잭션유지를 위해 데이터베이스 커넥션을 사용, 이를 위해 트랜잭션 동기화 매니저를 사용
- 트랜잭션은 중요하고 전세계 누구나 사용, 스프링은 트랜잭션 AOP를 처리하기 위한 모든 기능을 @Transactional로 제공
트랜잭션 적용확인
static class BasicService{
@Transactional
public void tx(){
...
}
public void nonTx(){
...
}
}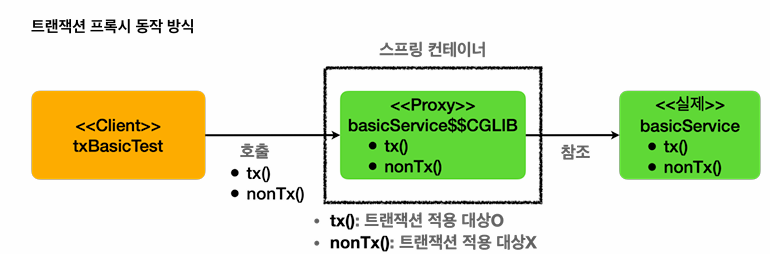
@Transactional 애노테이션이 하나라도 있으면 트랜잭션 AOP는 프록시를 만들어서 스프링 컨테이너에 등록.
실제 basicService객체 대신, 프록시인 basicService$$CGLIB가 등록됨.
이 프록시가 내부에서 실제 basicService를 참조
tx()호출시
프록시의 tx가 호출됨
프록시가 먼저 tx메서드가 트랜잭션을 사용하는지 확인후, 사용하므로
트랜잭션 시작후, 실제 basicService.tx()를 호출, 리턴이 돌아오면 커밋 또는 롤백
nontx()호출시
프록시의 nontx가 호출됨
그러나 트랜잭션 적용 x -> 트랜잭션 적용 대상이 아니면 트랜잭션을 시작하지 않고 바로 basicService에 위임
트랜잭션은 @Transactional을 통해서 스프링에게 해당 기능을 위임하여 사용하는것이다.
스프링이 용빼는 재주가 있는것도 아니고, 해당 기능을 위임시켜 실행하려면 해당 class를 @Bean으로 등록해야한다.
트랜잭션 적용 위치
항상 구체적인것이 우선순위가 높다.
@Slf4j
@Transactional(readOnly = true)
static class LevelService {
@Transactional(readOnly = false)
public void write() {
...
}
public void read() {
...
}
}write에는 readOnly가 false이므로 readOnly가 false이고,
read에는 조건이 없으므로 LevelService에 붙은 transactional을 따라가게 된다.
★★★★트랜잭션 AOP의 주의사항 - 프록시 내부호출★★★★
트랜잭션을 사용하려면 항상 프록시를 통해서 Target객체를 호출해야한다.
만약 프록시를 거치지 않고 대상 객체를 직접 호출하면 트랜잭션이 적용되지 않는다.
@SpringBootTest
@Slf4j
public class InternalCallV1Test {
@Autowired
CallService callService;
@Test
void internalCall(){
callService.internal();
}
@Test
void externalCall(){
callService.external();
}
@TestConfiguration
static class InternalCallV1Config{
@Bean
CallService callService(){
return new CallService();
}
}
@Slf4j
static class CallService{
public void external(){
internal();
}
@Transactional
public void internal() {
}
}
}-
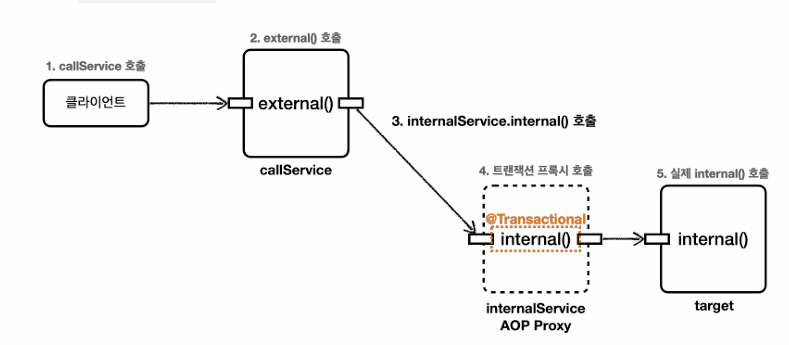
internalCall()
internal에는 @Transactional이 있다.
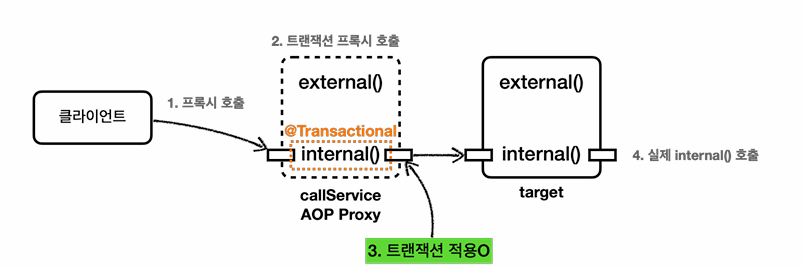
callService의 트랜잭션 프록시가 호출되고, 트랜잭션 적용 후 실제 callService(target)의 internal이 호출된다.
실제 callService가 처리를 완료하면 그후 응답이 트랜잭션 프록시로 돌아오고, 트랜잭션 프록시는 commit 또는 rollback 한다. -
external메서드
internal메서드를 내부에서 호출하는데 internal메서드를 호출했음에도 트랜잭션 로그가 남지 않는다.
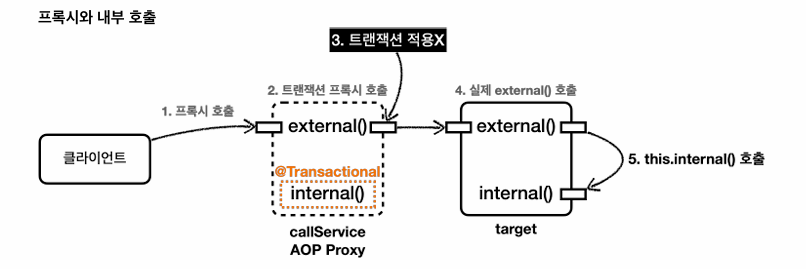
클라이언트가 프로깃의 external()메서드 호출
트랜잭션 적용 x
해당 로직을 실제 target에 위임
메서드 앞에 별도의 참조가 없으면 this라는 뜻으로 자기 자신의 인스턴스를 가르킴
external메서드 내부에서 호출한 internal메서드는 this,internal()로 실제 Target의 메서드임
결과적으로 내부호출은 프록시를 거치지 않고, 트랜잭션 적용안됨
★★★★프록시 방식의 AOP의 한계
@Transactional을 사용하는 트랜잭션 프록시는 메서드 내부호출시에 프록시를 적용할수 없다.
해결방안.
내부호출을 해야하는 매서드는 따로 별도의 클래스로 분리
@SpringBootTest
@Slf4j
public class InternalCallV2Test {
@Test
void externalCall(){
callService.external();
}
@Slf4j
@RequiredArgsConstructor
static class CallService{
private final InternalService internalService;
public void external(){
log.info("call external");
printTxInfo();
internalService.internal();;
}
}
@Slf4j
static class InternalService{
@Transactional
public void internal() {
log.info("call internal");
printTxInfo();
}
}
}
클라이언트가 external()호출 -> Transactional없으므로 실제 callService의 external이 호출됨
현재 InternalService에는 트랜잭션이 적용된 코드가 1개 이상 있으므로 프록시가 만들어져 있고, callService.internal()호출하면, 해당 프록시의 internal메서드를 확인하는데 transactional이 적용되어 있으므로,
트랜잭션 적용후, 실제 target의 internal()메서드를 호출
참고: 스프링 트랜잭션 AOP의 기능은 public메서드에만 적용되도록 기본설정
대부분 비즈니스 로직에서 외부에서 접근가능한 메서드를 트랜잭션 시작점으로 사용하기떄문에, private,protected까지 전부 트랜잭션 거는건 과하다.
public이 아닌곳에 @Transactional이 붙으면 예외가 발생하는게 아니라, 그냥 적용을 무시한다.
주의사항 2 초기화시점
@PostConstruct를 통해 의존성 주입이 완료된 후에 기본 User같은걸 넣는걸 하고 싶을 수 있다.
그러나
@PostConstruct
@Transactional
public void initV1(){
boolean isActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("@PostConstruct tx active={}",isActive);
}해도 isActive를 확인해보면 false임을 확인 할 수 있는데,
그 이유는, 초기화 코드가 먼저 호출되고, 그다음에 트랜잭션 AOP가 적용되기 때문이다.
EventLister를 통해 트랜잭션 AOP를 포함한 모든 스프링 컨테이너가 완전히 생성되고 난 다음에 이벤트가 붙은 메서드를 호출하여 주면 트랜잭션이 적용된것을 확인 할 수 있다.
@EventListener(value = ApplicationReadyEvent.class)
@Transactional
public void initV2(){
boolean isActive = TransactionSynchronizationManager.isActualTransactionActive();
log.info("@PostConstruct tx active={}",isActive);
}예외와 트랜잭션 커밋, 롤백
만약에 Repository에서 예외가 발생시, 내부에서 예외처리를 못하고, 트랜잭션 범위 (@Tranascational이 적용된 AOP)밖으로 예외를 던지면 어떻게 될까?
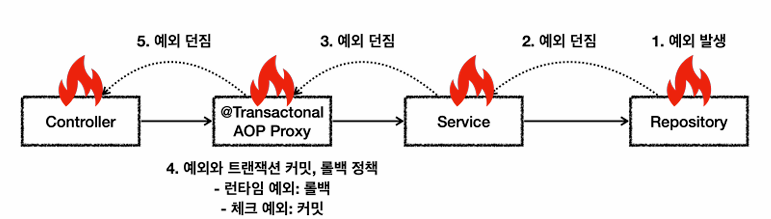
- 체크예외(Exception과 그 하위 예외): 커밋
- 언체크예외(RuntimeException과 그 하위예외): 롤백
스프링은 기본적으로 예외를 두가지로 본다.
- 언체크예외, 런타임 예외: DB 커넥션 오류등 복구가 불가능한 예외
- 체크 예외: 비즈니스 로직 수행중 발생한 예외
만약 고객이 주문을 하는데, DB 커넥션 같은 런타임 에러 발생 -> 롤백을 한다. 복구불가
고객이 주문을 하는데 잔고가 부족하다. -> 롤백을 하지않고, 상태를 결제 대기로 바꾸어 커밋하고, 고객에게 입금계좌를 알려준다.(체크예외, 비즈니스 로직수행중 오류)
이렇게하면 주문정보가 DB에 남기 때문에 다시 고객의 주문정보를 받지 않아도 된다.
그런데 만약 체크 예외가 발생하는데 커밋이 아니라 롤백시키고싶다면
@Transactional(rollbackFor = 체크예외.class)를 사용하면 체크 예외가 발생하더라도 롤백시킨다.
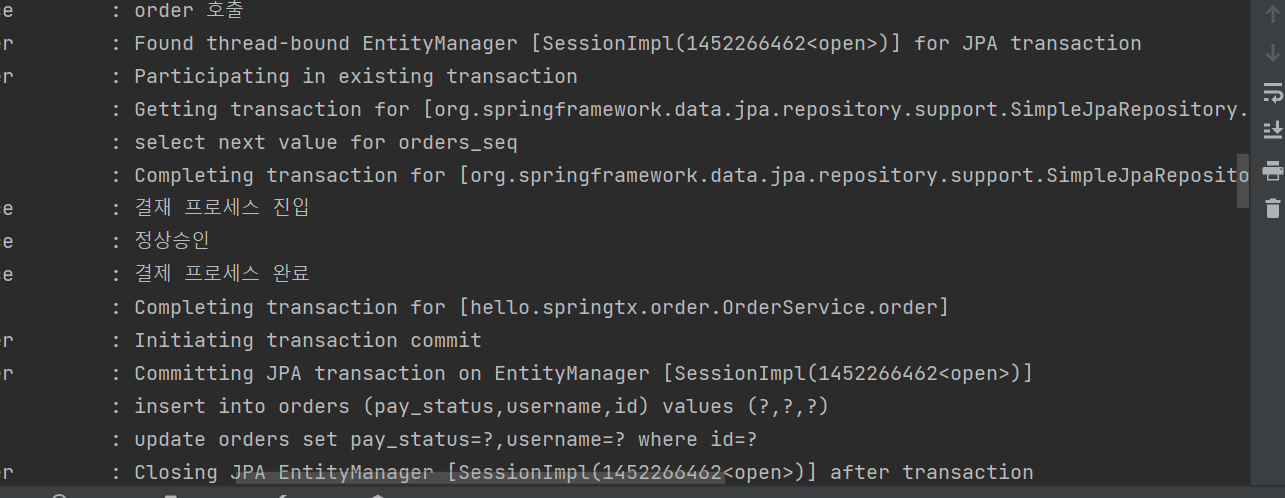
정상로직은 트랜잭션 시작후 커밋하고, insert쿼리까지 날린다.
롤백을 해야하는것은 트랜잭션 시작후 롤백하므로, insert쿼리를 날리지 않고, 당연히 DB에도 반영되지 않는다.
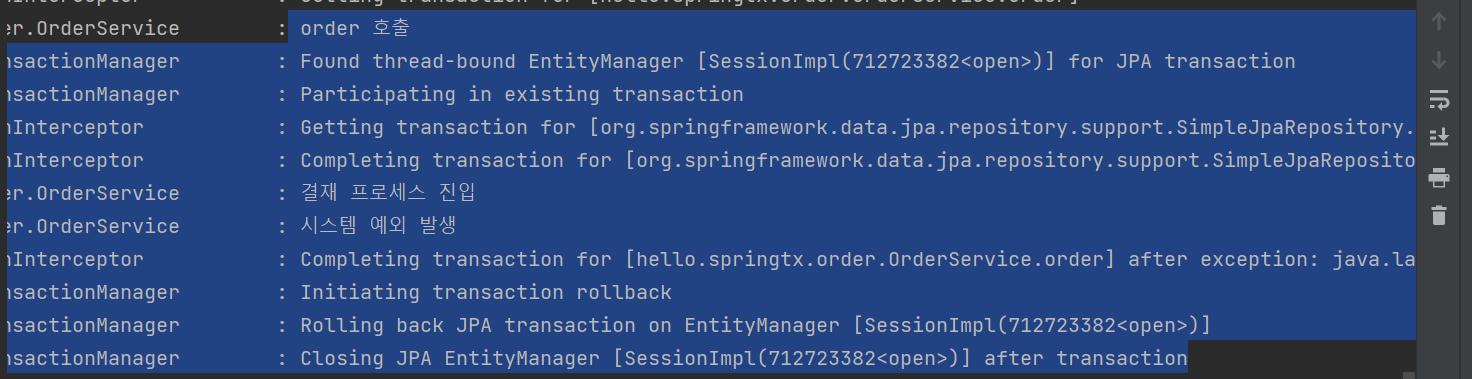
체크예외 발생시에는 로그에 insert쿼리문이 날라간걸 볼 수 있따. 즉 해당 DB에는 고객의 주문정보가 대기로 들어간것이다.
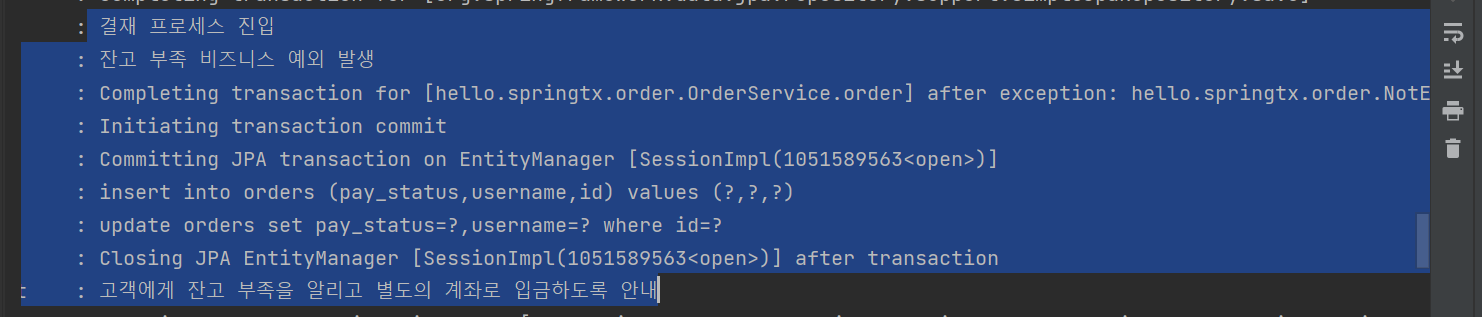
결국 체크 예외는 커밋, 언체크 예외는 롤백한다.
체크 예외를 커밋하는 이유는 -> 비즈니스 로직에 오류가 발생하면, 해당요청을 저장해두었다 쓰라는것이다.
물론, 상황에 맞게 개발자가 rollbackFor로 저장하지 않고 롤백쳐도 된다.
개발자가 상황에 맞게 쓰자.
트랜잭션 전파
- 스프링은 PlatformTransactionManager를 통해서 트랜잭션 수행
- 원래는 DataSource를 자동으로 가져와서 PlatformTransactionManager의 구현체를 자동으로 등록,
- 여기서는 PlatformTransactionManager의 구현체로 JDBC DB접근법인 DataSourceTransactionManager를 등록
- 해당 구현체에는 DB커넥션을 위한 DataSource가 필요하므로 Data Source를 넘겨줌
- DataSource에는 JDBC URL, 사용자명 및 패스워드 등이있음
@Slf4j
@SpringBootTest
public class BasicTxTest {
@Autowired
PlatformTransactionManager txManager;
@TestConfiguration
static class Config{
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource){
return new DataSourceTransactionManager(dataSource);
}
}
...
}트랜잭션 두번사용
@Test
void double_commit(){
log.info("트랜잭션1 시작");
TransactionStatus tx1 = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("트랜잭션1 커밋 시작");
txManager.commit(tx1);
log.info("트랜잭션1 커밋 완료");
log.info("트랜잭션2 시작");
TransactionStatus tx2 = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("트랜잭션2 커밋 시작");
txManager.commit(tx2);
log.info("트랜잭션2 커밋 완료");
}트랜잭션1 시작
2024-07-08T12:51:44.819+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Creating new transaction with name [null]: PROPAGATION_REQUIRED,ISOLATION_DEFAULT
2024-07-08T12:51:44.822+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Acquired Connection [HikariProxyConnection@1282401410 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA] for JDBC transaction
2024-07-08T12:51:44.825+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Switching JDBC Connection [HikariProxyConnection@1282401410 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA] to manual commit
2024-07-08T12:51:44.826+09:00 INFO 18556 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 트랜잭션1 커밋 시작
2024-07-08T12:51:44.827+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Initiating transaction commit
2024-07-08T12:51:44.828+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Committing JDBC transaction on Connection [HikariProxyConnection@1282401410 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA]
2024-07-08T12:51:44.829+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Releasing JDBC Connection [HikariProxyConnection@1282401410 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA] after transaction
2024-07-08T12:51:44.830+09:00 INFO 18556 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 트랜잭션1 커밋 완료
2024-07-08T12:51:44.830+09:00 INFO 18556 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 트랜잭션2 시작
2024-07-08T12:51:44.830+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Creating new transaction with name [null]: PROPAGATION_REQUIRED,ISOLATION_DEFAULT
2024-07-08T12:51:44.830+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Acquired Connection [HikariProxyConnection@1175319617 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA] for JDBC transaction
2024-07-08T12:51:44.830+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Switching JDBC Connection [HikariProxyConnection@1175319617 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA] to manual commit
2024-07-08T12:51:44.830+09:00 INFO 18556 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 트랜잭션2 커밋 시작
2024-07-08T12:51:44.831+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Initiating transaction commit
2024-07-08T12:51:44.831+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Committing JDBC transaction on Connection [HikariProxyConnection@1175319617 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA]
2024-07-08T12:51:44.831+09:00 DEBUG 18556 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Releasing JDBC Connection [HikariProxyConnection@1175319617 wrapping conn0: url=jdbc:h2:mem:6bc194e7-e9b1-4430-8119-7c38240d8887 user=SA] after transaction
2024-07-08T12:51:44.831+09:00 INFO 18556 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 트랜잭션2 커밋 완료tx1 트랜잭션 시작한 후에 conn0커넥션 획득 -> 커밋후 conn0번 반환
tx2 트랜잭션 시작후 conn0커넥션 획득 -> 커밋 후 conn0번 반환
서로 다른 커넥션
구분방법
커넥션 풀에서 커넥션 획득시 -> 내부관리를 위해, 히카리 프록시 커넥션이라는 객체를 생성해서, conn0으로 감싸서 반환
해당 프록시 내부에 실제 커넥션이 포함되어있음
커넥션을 다루는 프록시 객체 주소가 트랜잭션1,2 서로 다름
트랜잭션 전파 기본
트랜잭션 전파: 앞에서 한것처럼, 트랜잭션을 각각 사용하는게 아니라, 이미 트랜잭션이 진행중인데 추가로 트랜잭션이 수행되는것.
스프링은 외부트랜잭션이 수행중인데, 내부트랜잭션이 추가로 수행되면, 외부트랜잭션과 내부 트랜잭션을 묶어서 하나의 트랜잭션으로 만들어준다.
- 물리트랜잭션: 실제 DB에 적용되는 트랜잭션
실제 커넥션을 통해서 트랜잭션 시작(setAutoCommit(false))하고, 실제 커넥션을 통해서 커밋, 롤백하는 단위
처음 트랜잭션을 시작한 신규 트랜잭션 - 논리 트랜잭션
트랜잭션이 진행되는 중에 내부에 추가로 트랜잭션을 사용하는 경우
커밋과 롤백 조건
- 모든 논리 트랜잭션이 커밋되어야 물리 트랜잭션이 커밋된다.
- 하나의 논리 트랜잭션이라도 롤백되면 물리 트랜잭션은 롤백된다.
외부트랜잭션 커밋, 내부 트랜잭션 커밋
@Test
void inner_commit(){
log.info("외부 트랜잭션 시작");
TransactionStatus outer = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("out.isNewTransaction()={}",outer.isNewTransaction());
log.info("내부 트랜잭션 시작");
TransactionStatus inner = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("inner.isNewTransaction()={}",inner.isNewTransaction());
log.info("내부 트랜잭션 커밋");
txManager.commit(inner);
log.info("외부 트랜잭션 커밋");
txManager.commit(outer);
}외부 트랜잭션 시작시 트랜잭션을 만든다. 내부 트랜잭션 시작시 Creating이 아니라 Participating으로 로그 출력 -> 기존 트랜잭션에 참여
내부 트랜잭션 커밋시 -> 실제 커밋 x(내부 트랜잭션에서 물리 트랜잭션 커밋시, 트랜잭션이 끝나버리므로, 트랜잭션을 처음 시작한 외부 트랜잭션까지 이어 갈 수 없기 때문)
외부 트랜잭션이 트랜잭션 매니저한테 커밋 요청 -> 외부트랜잭션은 신규 트랜잭션이므로 실제 커밋 호출, DB에 반영
핵심
- 트랜잭션 매니저에 커밋을 호출한다고, 항상 실제 커넥션에 물리 커밋이 발생 x
신규 트랜잭션(외부 트랜잭션)인 경우에만 실제 커넥션을 사용해서 물리 커밋과 롤백 수행
외부 트랜잭션 롤백, 내부 트랜잭션 커밋
@Test
void outer_rollback(){
log.info("외부 트랜잭션 시작");
TransactionStatus outer = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("out.isNewTransaction()={}",outer.isNewTransaction());
log.info("내부 트랜잭션 시작");
TransactionStatus inner = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("inner.isNewTransaction()={}",inner.isNewTransaction());
log.info("내부 트랜잭션 커밋");
txManager.commit(inner);
log.info("외부 트랜잭션 롤백");
txManager.rollback(outer);
}T10:16:41.708+09:00 INFO 23192 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 외부 트랜잭션 시작
2024-07-09T10:16:41.711+09:00 DEBUG 23192 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Creating new transaction with name [null]: PROPAGATION_REQUIRED,ISOLATION_DEFAULT
2024-07-09T10:16:41.715+09:00 DEBUG 23192 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Acquired Connection [HikariProxyConnection@2099052183 wrapping conn0: url=jdbc:h2:mem:d4191ae1-553c-4476-97e5-b1b8582a2a35 user=SA] for JDBC transaction
2024-07-09T10:16:41.720+09:00 DEBUG 23192 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Switching JDBC Connection [HikariProxyConnection@2099052183 wrapping conn0: url=jdbc:h2:mem:d4191ae1-553c-4476-97e5-b1b8582a2a35 user=SA] to manual commit
2024-07-09T10:16:41.721+09:00 INFO 23192 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : out.isNewTransaction()=true
2024-07-09T10:16:41.721+09:00 INFO 23192 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 내부 트랜잭션 시작
2024-07-09T10:16:41.721+09:00 DEBUG 23192 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Participating in existing transaction
2024-07-09T10:16:41.721+09:00 INFO 23192 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : inner.isNewTransaction()=false
2024-07-09T10:16:41.722+09:00 INFO 23192 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 내부 트랜잭션 커밋
2024-07-09T10:16:41.722+09:00 INFO 23192 --- [springtx] [ Test worker] hello.springtx.propagation.BasicTxTest : 외부 트랜잭션 롤백
2024-07-09T10:16:41.722+09:00 DEBUG 23192 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Initiating transaction rollback
2024-07-09T10:16:41.723+09:00 DEBUG 23192 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Rolling back JDBC transaction on Connection [HikariProxyConnection@2099052183 wrapping conn0: url=jdbc:h2:mem:d4191ae1-553c-4476-97e5-b1b8582a2a35 user=SA]
2024-07-09T10:16:41.724+09:00 DEBUG 23192 --- [springtx] [ Test worker] o.s.j.d.DataSourceTransactionManager : Releasing JDBC Connection [HikariProxyConnection@2099052183 wrapping conn0: url=jdbc:h2:mem:d4191ae1-553c-4476-97e5-b1b8582a2a35 user=SA] after trans내부트랜잭션이 commit요청 하더라도, 신규 트랜잭션이 아니므로, 실제 커밋을 하지 않음
외부 트랜잭션이 롤백을 요청하므로, 전체가 롤백되는것을 확인 할 수 있다.
외부 트랜잭션 커밋, 내부 트랜잭션 롤백
@Test
void inner_rollback(){
log.info("외부 트랜잭션 시작");
TransactionStatus outer = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("out.isNewTransaction()={}",outer.isNewTransaction());
log.info("내부 트랜잭션 시작");
TransactionStatus inner = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("inner.isNewTransaction()={}",inner.isNewTransaction());
log.info("내부 트랜잭션 롤백");
txManager.rollback(inner);
log.info("외부 트랜잭션 커밋");
txManager.commit(outer);
}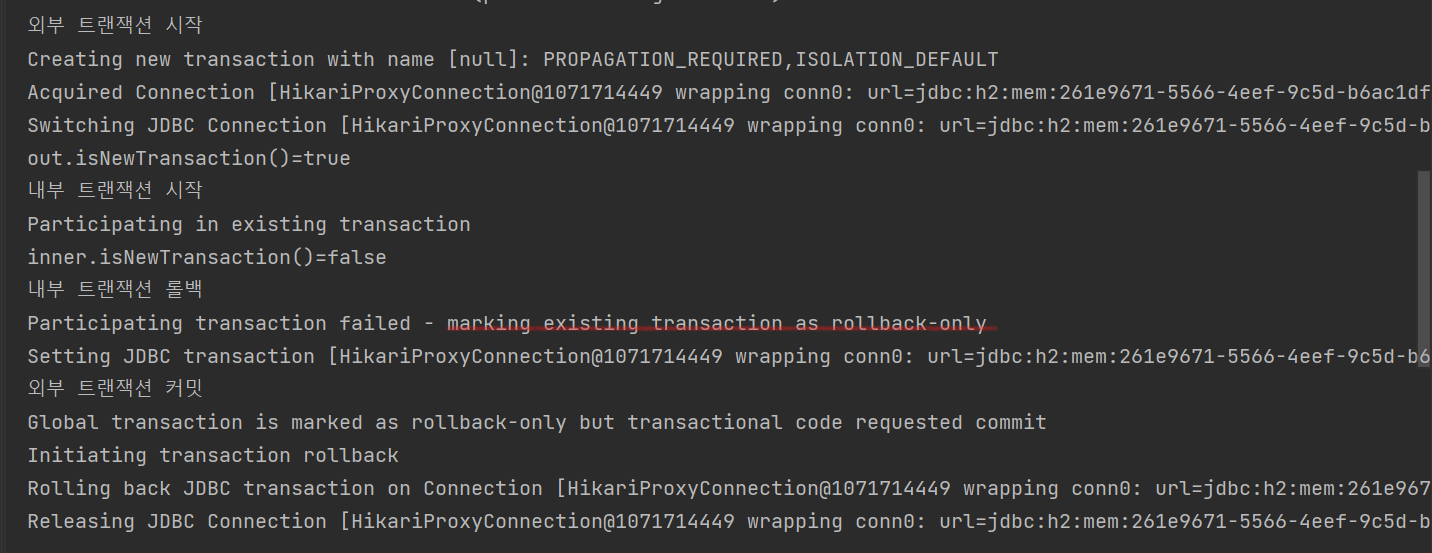
내부트랜잭션이 롤백 요청시 -> 신규트랜잭션이 아니므로, 실제 롤백되지않음 -> transaction에다가 rollback-only마킹
외부트랜잭션(물리트랜잭션)에서 커밋 또는 롤백할때, rollback-onlyy마킹이되어있으면 반드시 rollback을 해줘야한다.
comit요청시 -> UnexpectedRollbackException발생
해결방법 - REQUIRES_NEW
외부트랜잭션과 내부 트랜잭션을 완전히 분리해서 각각의 별도의 물리 트랜잭션을 사용
@Test
void inner_rollback_requires_new(){
log.info("외부 트랜잭션 시작");
TransactionStatus outer = txManager.getTransaction(new DefaultTransactionAttribute());
log.info("out.isNewTransaction()={}",outer.isNewTransaction());
log.info("내부 트랜잭션 시작");
DefaultTransactionAttribute definition = new DefaultTransactionAttribute();
definition.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
TransactionStatus inner = txManager.getTransaction(definition);
log.info("inner.isNewTransaction()={}",inner.isNewTransaction());
log.info("내부 트랜잭션 롤백");
txManager.rollback(inner);
log.info("외부 트랜잭션 커밋");
txManager.commit(outer);
}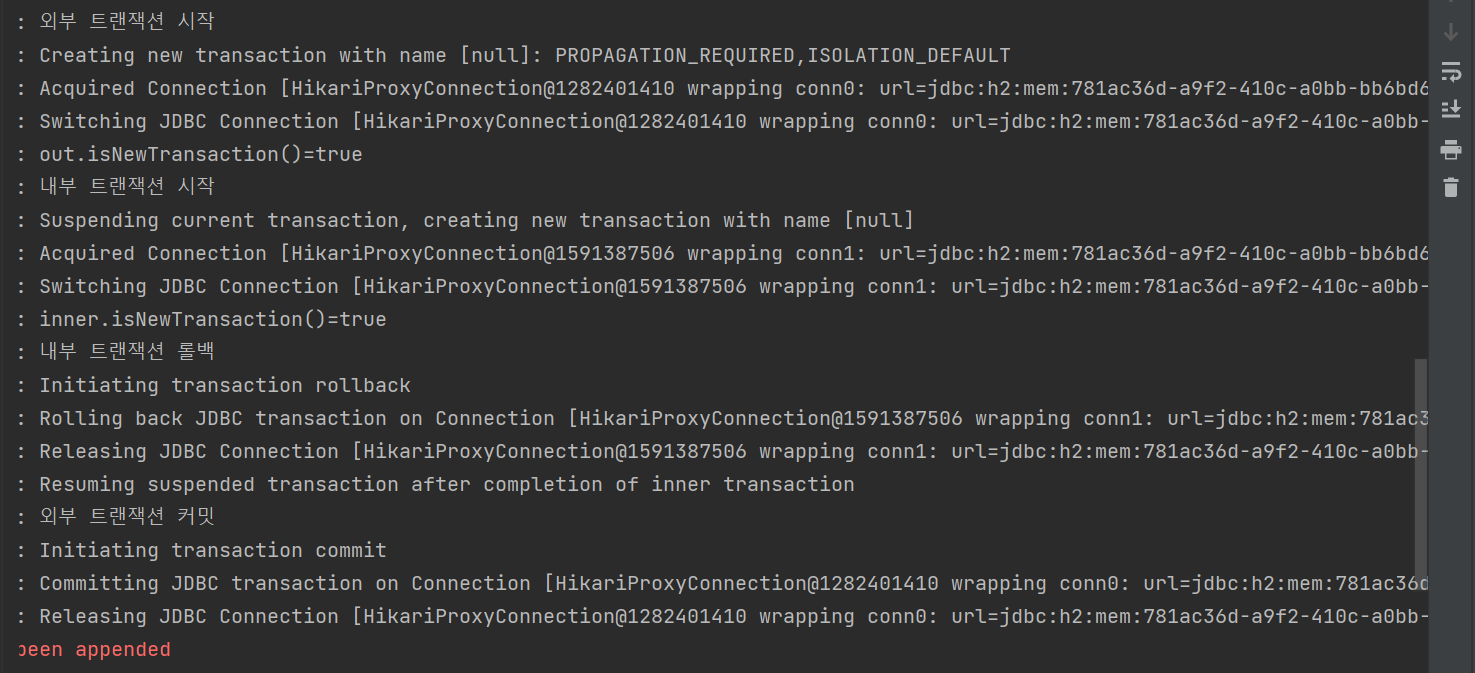
외부트랜잭션 시작 -> conn0번획득
내부트랜잭션 시작 -> current transaction 일시 정지 -> 새로운 커넥션 conn1획득
외부 트랜잭션에 참여 x -> 완전히 새로운 신규 트랜잭션 생성
-
내부 트랜잭션 롤백요청시 -> 신규트랜잭션이므로 실제 물리 트랜잭션에서 롤백함 -> 내부 트랜잭션이 사용하는 conn1반납
-
외부 트랜잭션 롤백요청시 -> 신규트랜잭션이므로 실제 물리 트랜잭션에서 롤백함 -> 외부 트랜잭션이 사용하는 conn1반납
-
Requires_New 옵션을 사용하면 물리트랜잭션이 명확하게 분리된다.
-
Requires_New 를 사용하면 데이터베이스 커넥션이 동시에 2개가 사용되는점을 주의해야한다.
트랜잭션 전파 활용 예제
클라이언트가 주문시
-> order저장
-> 로그저장(만약 order저장 실패하더라도 로그는 저장되게 설계)
@Slf4j
@Repository
@RequiredArgsConstructor
public class MemberRepository {
private final EntityManager em;
@Transactional
public void save(Member member){
log.info("member 저장");
em.persist(member);
}@Slf4j
@Repository
@RequiredArgsConstructor
public class LogRepository {
private final EntityManager em;
@Transactional
public void save(Log logMessage) {
log.info("log 저장");
em.persist(logMessage);
if(logMessage.getMessage().contains("로그예외")){
log.info("log 저장시 예외 발생");
throw new RuntimeException("예외 발생");
}
}@Slf4j
@Service
@RequiredArgsConstructor
public class MemberService {
private final MemberRepository memberRepository;
private final LogRepository logRepository;
public void joinV1(String username){
Member member = new Member(username);
Log logMessage = new Log(username);
log.info("member Repository 호출 시작");
memberRepository.save(member);
log.info("member Repository 호출 종료");
log.info("logRepository 호출 시작");
logRepository.save(logMessage);
log.info("logRepository 호출 종료");
}
public void joinV2(String username){
Member member = new Member(username);
Log logMessage = new Log(username);
log.info("memberRepository 호출 시작 ");
memberRepository.save(member);
log.info("memberRepository 호출 종료");
log.info("logRepository 호출 시작");
try{
logRepository.save(logMessage);
}catch (RuntimeException e){
log.info("log 저장에 실패했습니다. logMessage={}",logMessage.getMessage());
log.info("정상 흐름 반환");
}
log.info("logRepository 호출 종료");
}
}- 정상로직
@Test
void outerTxoff_success() {
//given
String username = "outerTxoff_success";
//when
memberService.joinV1(username);
//then: 저장 정상적으로 완료
assertTrue(memberRepository.find(username).isPresent());
assertTrue(logRepository.find(username).isPresent());
}- 로그에서 예외가 터지는경우
@Test
void outerTxOff_fail(){
//given
String username = "로그예외_outerTxOff_fail";
//when
assertThatThrownBy(()-> memberService.joinV1(username)).isInstanceOf(RuntimeException.class);
//then
assertTrue(memberRepository.find(username).isPresent());
assertTrue(logRepository.find(username).isEmpty());
}- username에 로그예외가 들어가있음 -> RuntimeException발생
- RuntimeException같은 언체크예외 발생시 트랜잭션은 rollback함
- 서로 다른 Transactional로 서로 다른 커넥션을 사용하므로, Member저장은 commit, Log저장은 rollback됨
회원저장은 되지만, 회원 이력 로그는 롤백되는 정합성 문제 발생
해결방안 회원 서비스에만 트랜잭션 적용
@Transactional
public void joinV1(String username){
Member member = new Me
...
}MemberRepository와 LogRepository에는 Transactional제거
MemberService를 시작할때부터 종료할때까지 모든 로직을 하나의 트랜잭션을 사용하게 됨
당연히 MemberService가 MemberRepository와 LogRepository를 호출하므로 이 로직들은 같은 커넥션을 사용하게 된다.
당연히 동일한 트랜잭션 범위에 포함됨
그러나, 따로 Member만 저장되도록 하고 싶을때, MemberRepository.save에는 Transactional이 없으므로 트랜잭션 적용이 안됨
단일로 사용을 하고싶으면, Transactional을 적용한 새로운 메서드를 만들어야함
너무 복잡하므로 트랜잭션 전파 사용
트랜잭션 전파사용
MemberRepository,LogRepository의 save메서드의 Transactional 주석 해제
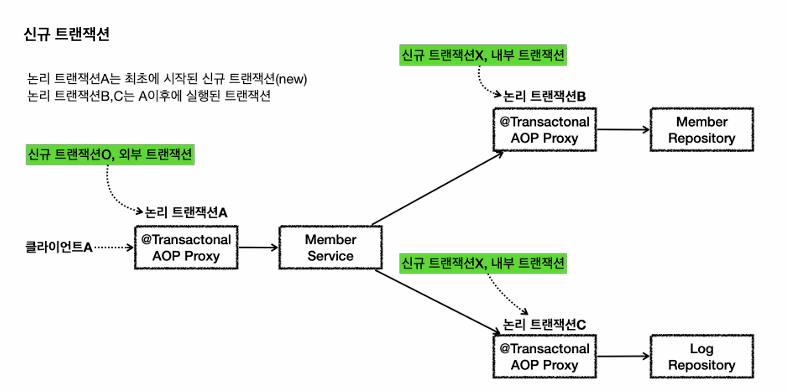
MemberService를 시작하면서 Transactional이 있으므로 신규 트랜잭션 생성후, 물리 트랜잭션 시작.
MemberRepository 호출, LogRepository 호출시 둘다 신규 트랜잭션이 아니므로 기존 트랜잭션에 참여,
만약 Member만 따로 저장하고 싶어서 MemberRepository.save()호출시 여기에 Transactional걸려있어서 따로 하는것도 가능,
BUT, Rollback이 문제
@Test
void outerTxOn_fail() {
//given
String username = "로그예외_outerTxOn_fail";
//when
assertThatThrownBy(() -> memberService.joinV1(username))
.isInstanceOf(RuntimeException.class);
//then: 모든 데이터가 롤백된다.
assertTrue(memberRepository.find(username).isEmpty());
assertTrue(logRepository.find(username).isEmpty());
}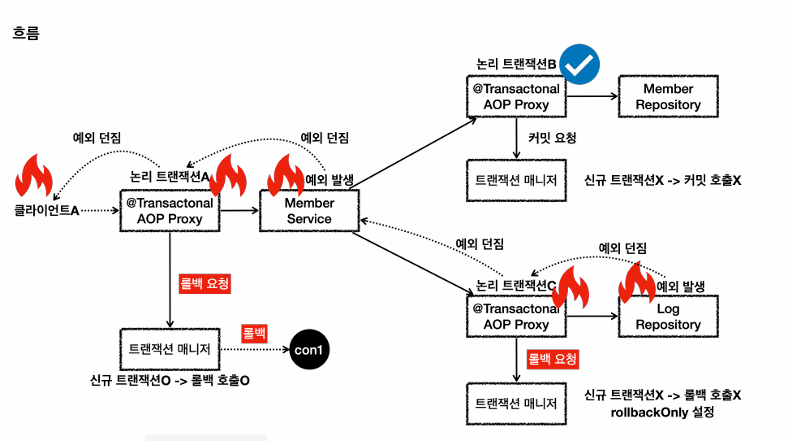
LogRepository 호출시 -> save메서드에 Transactional 존재 -> 이미 트랜잭션이 있으므로 기존 트랜잭션에 참여
LogRepoistory에서는 런타임 예외 발생, 트랜잭션 매니저에 롤백을 요구, 신규 트랜잭션이 아니므로 롤백 호출x 대신에 rollbackOnly마킹
MemberService에서는 LogRepository가 던지 런타임 예외를 받게됨.
그러면 MemberService에서 예외처리를 하지 않았으므로, 런타임 예외가 발생했으므로 트랜잭션 매니저에 롤백을 요구, 신규 트랜잭션이므로 물리 롤백 호출
만약 여기서 커밋 호출시 -> UnexpectedRollbackException발생(이미 rollbackOnly마킹되있음)
처음시작한 신규트랜잭션이자, 물리트랜잭션이 롤백치면 전부가 롤백됨 (정합성 문제 안생김)
예외상황
MemberService의 joinV2메서드
@Transactional
public void joinV2(String username){
Member member = new Member(username);
Log logMessage = new Log(username);
log.info("memberRepository 호출 시작 ");
memberRepository.save(member);
log.info("memberRepository 호출 종료");
log.info("logRepository 호출 시작");
try{
logRepository.save(logMessage);
}catch (RuntimeException e){
log.info("log 저장에 실패했습니다. logMessage={}",logMessage.getMessage());
log.info("정상 흐름 반환");
}
log.info("logRepository 호출 종료");
}LogRepository에서 예외 발생해서 던졌는데,
try catch를 통해서
RuntimeException을 catch하고 정상흐름 로직으로 처리한다 치면, joinV2가 있는 MemberService에서는 LogRepository가 MemberService로 던진 RuntimeException을 외부로 던지지 않는다.
그러면 정상흐름이니까, 메서드 끝나면 커밋쳐야되는거아니냐?
싶을 수 있다.
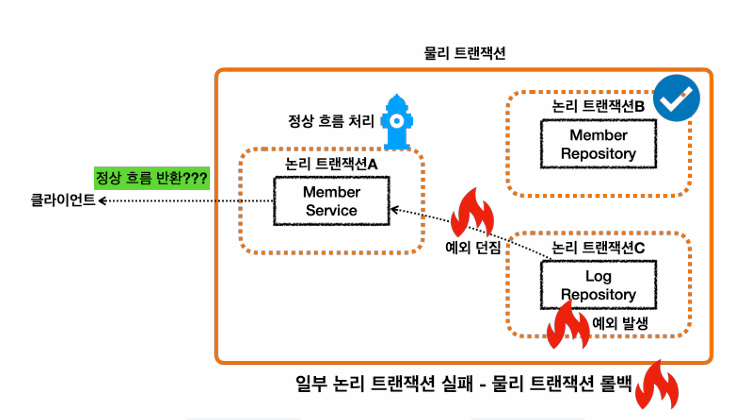
그러나 UnexpectedRollbackException발생
왜냐하면, 이미 LogRepository에서 rollbackOnly마킹이 되어있는데, try catch문으로 예외처리를 해버리면, MemberService의 메서드가 정상적으로 끝나면 commit을 치기 때문이다.
그러면 어떻게하냐?
LogRepository의 save메서드를 실행할때는 REQUIRES_NEW옵션으로 새로운 DB 커넥션을 만들어서 사용하는것이다.
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void save(Log logMessage) {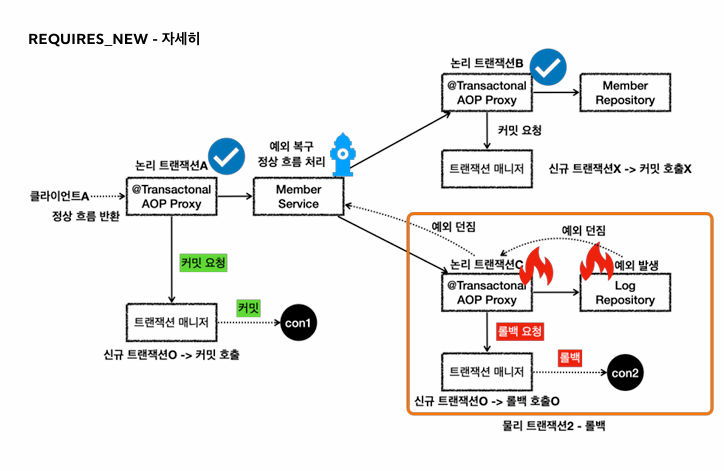
MemberService에서 MemberRepository의 save호출시 -> REQUIRED옵션 없으므로 기존 트랜잭션에 참여
LogRepository의 save호출시 REQUIRED옵션이 있으므로 DB에서 새로운 커넥션을 획득, 해당 커넥션으로 트랜잭션 수행,
신규트랜잭션이므로 rollback수행
MemberSerivce에서 LogRepository가 던진예외 catch부분에서 정상로직으로 수행
rollbackOnl마킹 검사시, memberRepository에서 마킹한게 없으므로 커밋을 한다.
결과적으로 회원의 데이터는 저장, 로그데이터만 롤백됨
주의상항
REQUIRED_NEW를 사용하면 하나의 HTTP요청에 동시에 두개의 데이터베이스 커넥션을 사용하게 된다.
고로 이 옵션을 사용하지 않고 문제를 해결할 단순한 방법이 있다면, 그걸 사용하는게 맞다.
이렇게 서로 다른 물리 트랜잭션을 별도로 가진다는것은 각각의 디비 커넥션이 사용되는것이다. 즉 1개의 HTTP요청에 대해 2개의 커넥션이 사용되는것이다. 내부 트랜잭션이 처리 중일때는 꺼내진 외부 트랜잭션이 대기하는데, 이는 데이터베이스 커넥션을 고갈시킬수있다.
고로, REQURES_NEW옵션 없이 해결할 수 있다면, 별도의 클래스를 두어 사용하는것이 좋다.
예를 들어 AService에서 methodA,methodB를 호출하는데 서로 다른 트랜잭션에서 동작하도록 트랜잭션 전파를 사용하지 않는다면,
@Service
public class AService {
private final AMethodService aMethodService;
private final BMethodService bMethodService;
@Autowired
public AService(AMethodService aMethodService, BMethodService bMethodService) {
this.aMethodService = aMethodService;
this.bMethodService = bMethodService;
}
public void process() {
// AMethodService의 methodA 호출 (별도의 트랜잭션 A에서 실행)
aMethodService.methodA();
// BMethodService의 methodB 호출 (별도의 트랜잭션 B에서 실행)
bMethodService.methodB();
}
}@Service
public class AMethodService {
@Transactional
public void methodA() {
// 트랜잭션 A 로직
System.out.println("Executing methodA in its own transaction.");
// 데이터베이스 작업 수행
}
}@Service
public class BMethodService {
@Transactional
public void methodB() {
// 트랜잭션 B 로직
System.out.println("Executing methodB in its own transaction.");
// 데이터베이스 작업 수행
}
}이런식으로 트랜잭션을 사용할때 별도의 클래스를 두어 관리하면,
methodA를 호출하면 커넥션 풀에서 1번을 가져와서 사용하고 methodA가 끝나면 트랜잭션이 종료되면서 커넥션 1번이 풀에 반납되고
methodB를 호출하면 커넥션 풀에서 1번을 가져와서 사용되므로, 하나의 HTTP요청에서 커넥션을 동시에 2개를 사용하지 않을 수 있다.
다른 전파 옵션들
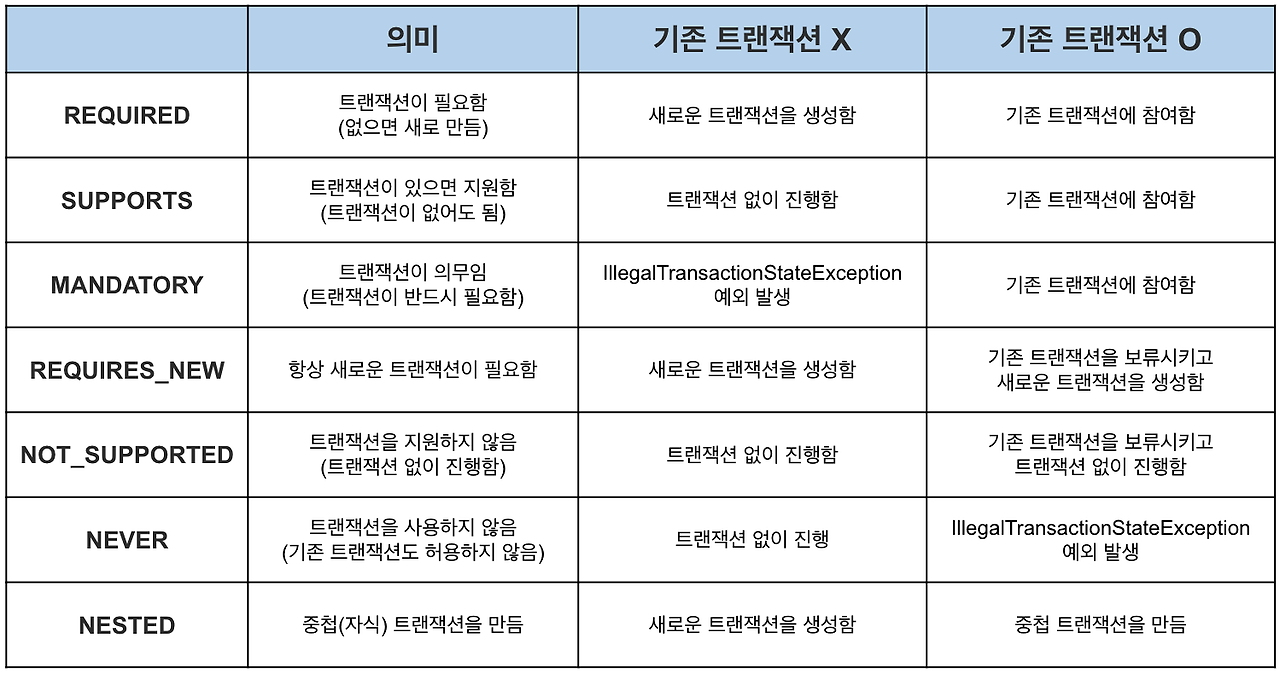
이미지 참고: https://mangkyu.tistory.com/269
