이 글은 prove 프로젝트를 하던중에, JPA를 사용하던 중에 발생한 오류를 해결하면서 배운점을 기록하였습니다.
또한, 현재 JPA를 사용만 할 줄 알지 JPA를 제대로 알지 못하므로 처음부터 차근차근 배워간다는 느낌으로 설명을 진행해보도록 하겠습니다.
문제 1: No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer 오류
우선 기본적인 entity소개를 해드리자면,
Prove
@NoArgsConstructor
@AllArgsConstructor
@Getter
@Setter
@Entity
public class Prove {
@GeneratedValue(strategy = GenerationType.AUTO)
@Id
@Column
private Long id;
...
@JsonManagedReference
@OneToMany(mappedBy = "prove", cascade = CascadeType.ALL)
private List<Image> imgList = new ArrayList<>();
@ManyToOne(fetch = FetchType.LAZY)
private UserEntity user;
Image
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Getter
@Setter
@Entity
public class Image {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
...
@ManyToOne(fetch = FetchType.LAZY)
@JsonBackReference
@JoinColumn
private Prove prove;
}
User
@Entity
@Getter
@Setter
public class UserEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private int id;
...
@JsonManagedReference
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL)
private List<Prove> proves = new ArrayList<>();
}이렇게 엔티티가 있고, Prove를 계시글, Image를 Prove에 들어가는 이미지들, 그리고 User가 있다고 생각해주시면 됩니다.
Controller
//proveID로 가져오기
@GetMapping("/api/{proveId}")
public Prove prove(@PathVariable Long proveId){
Optional<Prove> prove = proveRepository.findById(proveId);
return prove;
}우선 prove에 해당하는 id 103번 계시글을 가져와보도록하겠습니다.
이런식으로 JPA를 사용하여서 Prove 객체를 가져온 뒤에 prove를 반환하면 된다.
라고 간단히 생각하였습니다만,
No serializer found for class org.hibernate.proxy.pojo.bytebuddy.ByteBuddyInterceptor and no properties discovered to create BeanSerializer
이러한 오류가 나왔습니다.
일단은, DTO를 사용하지 않고 해당 엔티티를 그대로 반환하는것은 좋지 않습니다.
그러나 좋고 좋지않고가 문제가 아니라 error가 발생 하였는데
일단 Prove객체에 해당하는 필드 User와 imgList는 Lazy가 걸려있습니다.
참고:~ToMany는 기본적으로 Lazy임
그럼 도대체 일단 Lazy랑 Eager가 뭐냐? Lazy는 지연로딩 Eager는 즉시로딩입니다.
Eager를 사용하면 사전적의미인 열심인 처럼 Prove를 조회하면 연관관계에 있는 User와 Image까지 전부 조회되는 반면에 Lazy는 게을러서 해당 Prove만 조회하고 연관관계에 있는 나머지 데이터는 조회를 미루게됩니다.
그래서 나머지 데이터를 proxy로 가지고 있는 상태에서, 해당 Proxy를 serializer시키려고 하니까 문제가 발생한것입니다.
해결방법 1
application.properties에 spring.jackson.serialization.fail-on-empty-beans=false를 추가하기
이렇게 되면, 실행은 되긴 하는데 우리가 원하지 않는 필드가 생겨서 반환됩니다.
해결방법 2
DTO를 사용하여서 Proxy가 아닌 실제 User와 Image를 DB에서 불러와서 Proxy에서 정상 entity로 반환하는 것입니다.
@GetMapping("/api/{proveId}")
public ProveDtoWithId prove(@PathVariable Long proveId){
Optional<Prove> prove = proveRepository.findById(proveId);
ProveDtoWithId dto = proveService.makeProveDto(prove);
return dto;
}public ProveDtoWithId makeProveDto(Optional<Prove> optionalProve) {
if (optionalProve.isPresent()) {
Prove prove = optionalProve.get(); // Optional에서 Prove 객체를 가져옴
UserEntity userEntity = prove.getUser(); // UserEntity 객체를 가져옴
// UserDto 생성
UserDto userDto = UserDto.builder()
.username(userEntity.getUsername()) // getUsername() 메소드명 주의
.password(userEntity.getPassword()) // 필요한 경우
.role(userEntity.getRole()) // 필요한 경우
.build();
//ProveDtoWithId생성
ProveDtoWithId proveDtoWithId = ProveDtoWithId.builder()
.importance(prove.getImportance())
.level(prove.getLevel())
.tags(prove.getTags())
.startTime(prove.getStartTime())
.endTime(prove.getEndTime())
.success(prove.getSuccess())
.lank(prove.getLank())
.shortWord(prove.getShortWord())
.openOrNot(prove.getOpenOrNot())
.user(userDto)
.imgList(prove.getImgList())
.build();
return proveDtoWithId; // 실제로는 여기서 생성한 ProveDtoWithId 객체를 반환해야 합니다.
} else {
// Optional이 비어있는 경우, 적절한 처리 필요 (예: 예외 던지기)
throw new NoSuchElementException("Prove 객체가 존재하지 않습니다.");
}
}prove.getUser를 사용하여 실제 데이터베이스 조회가 발생하게 됩니다.
이렇게 User와 Image를 가져온다음에 DTO에 넣어서 반환해주는것입니다.
해결방법 3
Eager사용하기
Eager는 앞에서 말했다 싶이 연관된 엔티티까지 애초에 가져와버리니까 문제가 생기지 않는거 아닌가? 맞다. 그런데 이건 지양해야합니다. 왜냐하면, N+1문제가 발생하기 때문입니다.
JPQL 자체가 처음 쿼리를 만들때 연관된 엔티티는 신경쓰지않고 조회 대상이 되는 Entity기준으로만 쿼리를 만듭니다.
그래서 처음에 eager를 설정하더라도 한번에 Prove를 조회하는 query로 User까지 가져오는게아니라. DB에 select from prove로 날리게 되고 다시 엔티티에 결과를 찌를때 어? 연관된 엔티티가 있네? 글로벌 패치 전략이 뭐지? 하고 확인해보니까 Eager인 것입니다.
그러면 다시 Select from User where prove_id =1; 이런식으로 쿼리를 다시 날리게 되는것이다.
문제 2 : N+1문제
그러면 Eager가 N+1이 안생기면, Lazy는 N+1문제가 생기지 않나요?
그건 또 아니다 실제 로그로 확인한번 해보자.
Hibernate:
select
p1_0.id,
p1_0.end_time,
p1_0.importance,
p1_0.lank,
p1_0.level,
p1_0.open_or_not,
p1_0.short_word,
p1_0.start_time,
p1_0.success,
p1_0.tags,
p1_0.user_id
from
prove p1_0
where
(
p1_0.start_time>=?
and p1_0.end_time<=?
)
or (
p1_0.start_time<=?
and p1_0.end_time>=?
)
or (
p1_0.start_time<=?
and p1_0.end_time>=?
)
여기서 prove한번 가져오는거
그다음에 prove에 해당하는 ImageList 가져오는거
Hibernate:
select
il1_0.prove_id,
il1_0.id,
il1_0.img_name,
il1_0.img_url
from
image il1_0
where
il1_0.prove_id=?
Hibernate:
select
il1_0.prove_id,
il1_0.id,
il1_0.img_name,
il1_0.img_url
from
image il1_0
where
il1_0.prove_id=?
Hibernate:
select
il1_0.prove_id,
il1_0.id,
il1_0.img_name,
il1_0.img_url
from
image il1_0
where
il1_0.prove_id=?
Hibernate:
select
il1_0.prove_id,
il1_0.id,
il1_0.img_name,
il1_0.img_url
from
image il1_0
where
il1_0.prove_id=?
이렇게 1개의 Prove와 해당하는 Image갯수만큼 N번 쿼리를 날리는 것을 볼 수 있습니다.
그래서 N+1문제라고 합니다.
N+1: 연관된 엔티티까지 쿼리를 날리는문제
해결방안 1: Join Fetch
그러면 이걸 어떻게 해결하냐?
join fetch를 사용하는것입니다.
public interface ProveRepository extends JpaRepository<Prove, Long> {
@Query("SELECT p FROM Prove p " +
"LEFT JOIN FETCH p.imgList " +
"JOIN FETCH p.user " +
"WHERE (p.startTime >= :startDateTime AND p.endTime <= :endDateTime) " +
"OR (p.startTime <= :startDateTime AND p.endTime >= :startDateTime) " +
"OR (p.startTime <= :endDateTime AND p.endTime >= :endDateTime)")
List<Prove> findAllByDateWithImagesAndUser(@Param("startDateTime") LocalDateTime startDateTime, @Param("endDateTime") LocalDateTime endDateTime);
}
일단 이코드는 where절을 생략하고 생각한다면,
SELECT p FROM Prove p " +
"LEFT JOIN FETCH p.imgList " +
"JOIN FETCH p.user
입니다. 즉 join fetch를 통해서 조회시 바로 가져오고 싶은 Entity 필드를 지정하는것입니다.
join fetch a.원하는 필드
일부러 이 예제를 가져온것이 Prove계시글에서 img가 없을 수도 있습니다.
하지만 반드시 Prove 계시글에는 쓴 User가 있습니다.
그러므로 ImgList가 없는 prove를 고려하여서 LEFT JOIN을 하였습니다.
실제 로그를 살펴보면
Hibernate:
select
p1_0.id,
p1_0.end_time,
il1_0.prove_id,
il1_0.id,
il1_0.img_name,
il1_0.img_url,
p1_0.importance,
p1_0.lank,
p1_0.level,
p1_0.open_or_not,
p1_0.short_word,
p1_0.start_time,
p1_0.success,
p1_0.tags,
u1_0.id,
u1_0.password,
u1_0.role,
u1_0.username
from
prove p1_0
left join
image il1_0
on p1_0.id=il1_0.prove_id
join
user_entity u1_0
on u1_0.id=p1_0.user_id
where
(
p1_0.start_time>=?
and p1_0.end_time<=?
)
or (
p1_0.start_time<=?
and p1_0.end_time>=?
)
or (
p1_0.start_time<=?
and p1_0.end_time>=?
)
하나의 쿼리로 문제를 해결 할 수 있음을 확인 하였습니다.
여기까지가 저의 프로젝트를 사용하는데 생기는 문제를 해결하기위해서 제가 제 프로젝트에서 코드를 수정한것이고, 더 설명하고싶은것이 많아.
새로운 간단한 코드를 따로 만들어 이어서 설명해보도록 하겠습니다.
Store
상점에는 여러개의 상품이있습니다.
@Entity
@Getter
@NoArgsConstructor
public class Store {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(cascade = CascadeType.ALL)
private List<Product> products = new ArrayList<>();
@Builder
public Store(String name, List<Product> products){
this.name = name;
if(products != null){
this.products = products;
}
}
public void addProduct(Product product){
this.products.add(product);
product.updateStore(this);
}
}
여러개의 상품은 하나의 store에 있습니다.
Product
package com.example.jpan11.N1;
import jakarta.persistence.*;
import lombok.Builder;
import lombok.Getter;
import lombok.NoArgsConstructor;
@Entity
@Getter
@NoArgsConstructor
public class Product {
@Id
@GeneratedValue
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
private Store store;
@Builder
public Product(String name, Store store){
this.name = name;
this.store =store;
}
public void updateStore(Store store){
this.store = store;
}
}StoreService
@Service
@Slf4j
public class StoreService {
private StoreRepository storeRepository;
public StoreService(StoreRepository storeRepository) {
this.storeRepository = storeRepository;
}
@Transactional
public List<String> findAllProducts(){
return getProductName(storeRepository.findAll());
}
private List<String> getProductName(List<Store>stores){
log.info("상점내 모든 Product 출력");
return stores.stream()
.map(a -> a.getProducts().get(0).getName())
.collect(Collectors.toList());
}
}서비스에서는 storeRepository에서 저장된 store를 가져온다음에,
그 store에서 .getName()메서드를 호출하여서 쿼리를 다시 날리고 그 다음에 결과를 가져옵니다.
이전에 컨트롤러에서 이 코드를 수행하여서 이미 저장을 완료 하였습니다.
@RequiredArgsConstructor
public class StoreController {
private final StoreRepository storeRepository;
private final StoreService storeService;
@ResponseBody
@GetMapping("/api/getProduct")
public String getProduct(){
List<Store> Stores = new ArrayList<>();
for(int i=0;i<10;i++){
Store store = Store.builder()
.name("상점"+i)
.build();
store.addProduct(Product.builder().name("초콜릿" + i).build());
Stores.add(store);
}
storeRepository.saveAll(Stores);
return "ok";
}
}@Controller
@RequiredArgsConstructor
public class StoreController {
private final StoreRepository storeRepository;
private final StoreService storeService;
@ResponseBody
@GetMapping("/api/getProduct")
public String getProduct(){
storeService.findAllProducts();
return "ok";
}
}요청을 확인해보면,
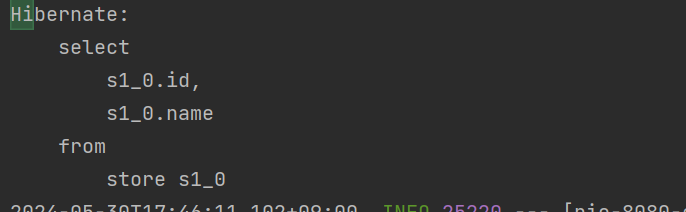
store를 불러오는거 1번,
그리고 나머지 쿼리 10개는 store에 연관된 product를 불러오는 10개의 쿼리를 날렸습니다.
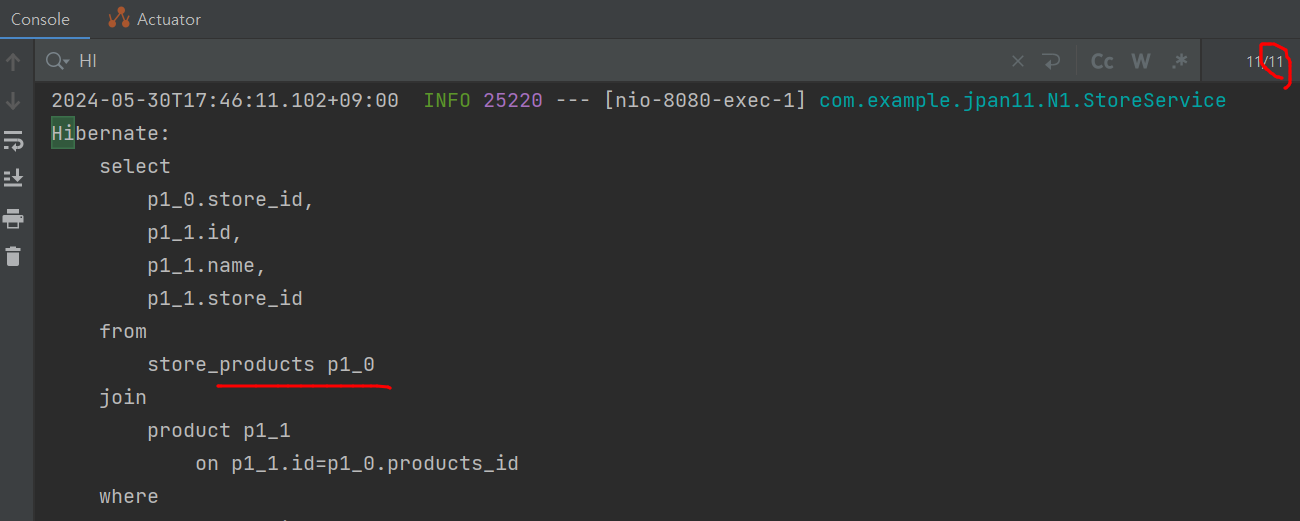
그래서 이 오류를 해결하기 위해서 join fetch를 적용해보면,
public interface StoreRepository extends JpaRepository<Store, Long> {
@Query("select a from Store a join fetch a.products")
List<Store> findAllJoinFetch();
}service에서 메서드 호출 부분 수정
@Transactional
public List<String> findAllProducts(){
return getProductName(storeRepository.findAllJoinFetch());
}결과적으로 한방쿼리가 나옴을 확인 할 수 있습니다.
Hibernate:
select
s1_0.id,
s1_0.name,
p1_0.store_id,
p1_1.id,
p1_1.name,
p1_1.store_id
from
store s1_0
join
store_products p1_0
on s1_0.id=p1_0.store_id
join
product p1_1
on p1_1.id=p1_0.products_id
문제 3: 쿼리 추가
결국 우리는 select * from a 를 하고싶은데 여기서 a.products라고 추가가 되었다. 이게 싫으면 @EntityGraph를 사용하면된다.
public interface StoreRepository extends JpaRepository<Store, Long> {
@EntityGraph(attributePaths = "products")
@Query("select a from Store a")
List<Store> findAllJoinFetch();
}@EntityGraph에 attributePaths에 쿼리 수행시 바로 가져올 필드명을 지정하면 Lazy가 아닌 Eager조회로 가져옵니다.
그러면, select a from Store a에서 원본 쿼리 손상 없이 표현할 수 있습니다.
문제 4 : 중복발생
지금은 상점 1개에, 상품이 1개만 들어있습니다. 만약에 상점 1개에 2개의 상품을 넣으면 어떻게 될까요?
@Controller
@Slf4j
@RequiredArgsConstructor
public class StoreController {
private final StoreRepository storeRepository;
private final StoreService storeService;
@ResponseBody
@GetMapping("/api/getProduct")
public String getProduct(){
List<Store> Stores = new ArrayList<>();
for(int i=0;i<10;i++){
Store store = Store.builder()
.name("상점"+i)
.build();
store.addProduct(Product.builder().name("초콜릿" + i).build());
store.addProduct(Product.builder().name("딸기" + i).build());
Stores.add(store);
}
storeRepository.saveAll(Stores);
return "ok";
}
}해당 요청을 통해서 일단 하나의 상점에 초콜릿과 딸기 product를 넣었습니다.
요청
@ResponseBody
@GetMapping("/api/getProduct")
public String getProduct(){
List<Store> stores = storeRepository.findAllJoinFetch();
log.info("Number of stores: {}", stores.size());
for (Store store : stores) {
log.info("Store ID: {}, Number of products: {}", store.getId(), store.getProducts().size());
}
return "ok";
}결과
Hibernate:
select
s1_0.id,
s1_0.name,
p1_0.store_id,
p1_0.id,
p1_0.name
from
store s1_0
join
product p1_0
on s1_0.id=p1_0.store_id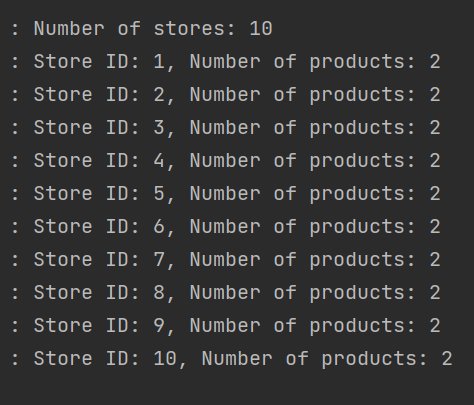
join을 하게 되면 카테시안 곱이 발생하여서 해당 store의 product의 수만큼 store가 중복발생되야한다고 글을 봤는데, 나는 계속 10개로 정상적으로 나오는것이다.
도대체,, 이게 무슨일인지 내가 설정을 잘못했는지 삽질을 시작했고, 결국 한 개발자 커뮤니티에 글을 올리게 되었는데.
JPA N+1 문제 (카티시안 문제)
안녕하세요. 저는 JPA를 공부하고있는 초보 개발자 입니다.
JPA N+1문제를 해결하던 도중, 이전의 블로그 글을 살펴보면서 궁금한 점이 생겼습니다.
Store에는
one to Many로 product가 있고
Product에는
Many to One으로 매핑이 되어있는 상태입니다.
여기서 join fetch를 써서
@Query("select a from Store a join fetch a.products")
List findAllJoinFetch();
이상태에서
List stores = storeRepository.findAllJoinFetch();
이런식으로 쿼리를 날렸는데, 현재 DB에 Store는 10개 Product는 한개의 store당 2개가 있는 상태입니다.
그러면 이전 블로그 글을 보니까 join fetch는 inner join이라 카티시안 곱으로 동일한 store가 2개 생겨서 총 stores에 20개의 store가 생기고, 이걸 방지하려면 distinct를 써야한다고 글 을 읽었습니다.
그러나 문제는, 계속 stores에는 10개의 store가 정상적으로 들어가있고 그 store마다 2개의 상품이 정상적으로 들어있습니다.
gpt한테 물어보니까 쿼리가 20개가 생기는건 맞는데 jpa가 자동적으로 이걸 합쳐서 10개로 돌려준다는 말을 했습니다.
이게 버전이 업그레이드 되면서 이런건지 아니면 원래 20개가 생기는게 맞는데 제가 어딜 잘못 설정한건지 모르겠습니다.
아시는 고..수분들 혹시 도와주세요 ㅠ
한 고수분이 답변을 남겨주셨다..

이제는 하이버네이트가 업데이트 되면서 알아서 distinct를 적용하여서 중복을 제거하여 취합해준다는것이다!!
문제5: MultipleBagFetchException
이번엔 store에 한가지 자식테이블을 또 추가해보도록 하겠습니다.
@Getter
@NoArgsConstructor
public class Store {
@Id
@GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "store", cascade = CascadeType.ALL)
private List<Product> products = new ArrayList<>();
@OneToMany(mappedBy = "store", cascade = CascadeType.ALL)
private List<Employee> employees = new ArrayList<>();여기서 Employee 자식 테이블을 추가하였습니다. 다만 추가할때 OneToMany관계로 설정하였습니다.
이번엔 API요청을 통한 Test가 아닌 Testcode를 작성해볼까요?
@RunWith(SpringRunner.class)
@SpringBootTest
@Slf4j
public class StoreControllerTest {
@Autowired
private StoreRepository storeRepository;
@Autowired
private StoreService storeService;
@After
public void deleteAll() {
storeRepository.deleteAll();
}
@Test
public void 몇개가_조회될까() throws Exception {
//given
Store store1 = new Store("상점1");
store1.addProduct(Product.builder().name("상품1").build());
store1.addEmployee(Employee.builder().name("직원1").build());
store1.addProduct(Product.builder().name("상품2").build() );
store1.addEmployee(Employee.builder().name("직원2").build());
storeRepository.save(store1);
Store store2 = new Store("상점2");
store2.addProduct(Product.builder().name("상품1").build());
store2.addEmployee(Employee.builder().name("직원1").build());
store2.addProduct(Product.builder().name("상품2").build() );
store2.addEmployee(Employee.builder().name("직원2").build());
storeRepository.save(store2);
log.info("Start findTotal Method");
//when
long size = storeService.findTotalProductsAndEmployees();
//then
Assertions.assertThat(size).isEqualTo(8);
}
} 이렇게 하면 결과가 8이 나옵니다.
하이버네이트 쿼리를 한번 봐볼까요?
2024-06-02T15:46:46.654+09:00 INFO 2600 --- [ main] c.example.jpan11.N1.StoreControllerTest : Start findTotal Method
Hibernate: //store 1개 조회
select
s1_0.id,
s1_0.name
from
store s1_0
Hibernate: //store 1 product1 조회
select
p1_0.store_id,
p1_0.id,
p1_0.name
from
product p1_0
where
p1_0.store_id=?
Hibernate: //store 1 employee1 조회
select
e1_0.store_id,
e1_0.id,
e1_0.name
from
employee e1_0
where
e1_0.store_id=?
Hibernate: //store 1 product2 조회
select
p1_0.store_id,
p1_0.id,
p1_0.name
from
product p1_0
where
p1_0.store_id=?
Hibernate: //store 1 employee2 조회
select
e1_0.store_id,
e1_0.id,
e1_0.name
from
employee e1_0
where
e1_0.store_id=?
Hibernate: //store2조회
select
s1_0.id,
s1_0.name
from
store s1_0
Hibernate: //store2 employee1조회
select
e1_0.store_id,
e1_0.id,
e1_0.name
from
employee e1_0
where
e1_0.store_id=?
Hibernate: //store2 product1조회
select
p1_0.store_id,
p1_0.id,
p1_0.name
from
product p1_0
where
p1_0.store_id=?
Hibernate: //store2 employee2조회
select
e1_0.store_id,
e1_0.id,
e1_0.name
from
employee e1_0
where
e1_0.store_id=?
Hibernate: //store2 product2 조회
select
p1_0.store_id,
p1_0.id,
p1_0.name
from
product p1_0
where
p1_0.store_id=?
여기서도 결과적으로 N+1문제가 발생하군요.. 앞에서 배운것처럼 join fetch를 적용해보도록 하겠습니다.
Repository 수정
public interface StoreRepository extends JpaRepository<Store, Long> {
@Query("select a from Store a join fetch a.products join fetch a.employees")
List<Store> findAllJoinFetch();
}
Store service에서 findAll()메서드가 아닌 findAllJoinFetch메서드 이용
@Transactional(readOnly = true)
public long findTotalProductsAndEmployees() {
List<Store> stores = storeRepository.findAllJoinFetch();
long total = 0;
for (Store store : stores) {
int productsSize = store.getProducts().size();
int employeesSize = store.getEmployees().size();
total += productsSize + employeesSize;
}
return total;
}Test code 결과
org.springframework.dao.InvalidDataAccessApiUsageException: org.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [com.example.jpan11.N1.Store.employees, com.example.jpan11.N1.Store.products]
at org.springframework.orm.jpa.EntityManagerFactoryUtils.convertJpaAccessExceptionIfPossible(E결과로 MultipleBagFetchException 오류가 발생함을 볼 수 있습니다.
JPA에서 Fetch Join의 조건은
-
ToOne은 몇개든 사용 가능합니다.
-
ToMany는 딱 1개만 사용이 가능합니다.
그러나 우리는 ToMany를 Employee와 Product에 두개를 사용하였습니다.
그러면 어떻게 MultipleBagFetchException오류 없이 N+1문제를 회피할 수 있을까요?
해결책 1: Hibernate default_batch_fetch_size
default_batch_fetch_size 옵션을 통해서 해결할 수 있습니다.
JPA문제를 다시한번 봐볼까요?
결국 N+1문제는 부모엔티티와 연관된 자식엔티티까지 각각 조회쿼리를 날리는게 문제입니다.
select from store
-> select from product where store_id =1;
-> select * from employee where store_id =1;
select from store
-> select from product where store_id =2;
-> select * from employee where store_id =2;
부모엔티티의 key하나하나를 자식 엔티티 조회에 사용하기 때문인데 이 1개씩 사용되는 조건문을 in절로 묶어서 조회하면
select from store
-> select from product where store_id in (1,2);
-> select * from employee where store_id in (1,2);
hibernate.default_batch_fetch_size 옵션에 지정된 수만큼 in절에 부모 Key를 사용하게 해줍니다.
만약 100개로 지정하면 100개 단위로 in절에 부모 Key가 넘어가서 자식 엔티티가 조회되는것입니다.
그러면 대략 1/100개 정도 쿼리수행수가 줄어들게 됩니다.
TestCode
@RunWith(SpringRunner.class)
@SpringBootTest
@Slf4j
@TestPropertySource(properties = "spring.jpa.properties.hibernate.default_batch_fetch_size=100") // 옵션 적
public class StoreControllerTest {
@Autowired
private StoreRepository storeRepository;
@Autowired
private StoreService storeService;
@After
public void deleteAll() {
storeRepository.deleteAll();
}
@Test
public void 몇개가_조회될까() throws Exception {
//given
Store store1 = new Store("상점1");
store1.addProduct(Product.builder().name("상품1").build());
store1.addEmployee(Employee.builder().name("직원1").build());
store1.addProduct(Product.builder().name("상품2").build() );
store1.addEmployee(Employee.builder().name("직원2").build());
storeRepository.save(store1);
Store store2 = new Store("상점2");
store2.addProduct(Product.builder().name("상품1").build());
store2.addEmployee(Employee.builder().name("직원1").build());
store2.addProduct(Product.builder().name("상품2").build() );
store2.addEmployee(Employee.builder().name("직원2").build());
storeRepository.save(store2);
log.info("Start findTotal Method");
//when
long size = storeService.findTotalProductsAndEmployees();
//then
Assertions.assertThat(size).isEqualTo(8);
}
}여기서는 @TestPropertySource를 이용해서 hibernate.default_batch_fetch_size을 이 테스트에만 적용되도록 하였습니다.
그리고 Service에서는 joinfetch가 아닌 findAll()로 가져와야합니다.
@Transactional(readOnly = true)
public long findTotalProductsAndEmployees() {
List<Store> stores = storeRepository.findAll();
long total = 0;
for (Store store : stores) {
int productsSize = store.getProducts().size();
int employeesSize = store.getEmployees().size();
total += productsSize + employeesSize;
}
return total;
}결과 쿼리를 확인하시면
2024-06-02T16:14:33.185+09:00 INFO 16268 --- [ main] c.example.jpan11.N1.StoreControllerTest : Start findTotal Method
Hibernate: //store1조회
select
s1_0.id,
s1_0.name
from
store s1_0
Hibernate: store1의 product조회
select
p1_0.store_id,
p1_0.id,
p1_0.name
from
product p1_0
where
p1_0.store_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: store1의 employee조회
select
e1_0.store_id,
e1_0.id,
e1_0.name
from
employee e1_0
where
e1_0.store_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: //store2조회
select
s1_0.id,
s1_0.name
from
store s1_0
Hibernate: //store2의 employee조회
select
e1_0.store_id,
e1_0.id,
e1_0.name
from
employee e1_0
where
e1_0.store_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
Hibernate: //store2의 product조회
select
p1_0.store_id,
p1_0.id,
p1_0.name
from
product p1_0
where
p1_0.store_id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
이렇게 쿼리가 원래는
store1 ->1
store1 product1 ->2
store1 product2->3
store1 employee1->4
store1 employee2->5
store2 ->6
store2 product1 ->7
store2 product2->8
store2 employee1->9
store2 employee2->10
총 10개가 나왔지만 여기서는 총 6개로 줄어든것을 확인 할 수 있습니다.
만약 store1개에 product 10,000개 employee 10,000개가 있고,batch size가 10,000개라면
- 옵션 미적용시
- 총 20,001개의 쿼리 수행
- store 1번
- product 10,000번
- employee 10,000번
- 옵션 적용시
- 총 3번의 쿼리 수행
- store 1번
- product 1번 (10,000/10,000)
- employee 1번 (10,000/10,000)
만약 스프링 부트 옵션으로 적용시
spring.jpa.properties.hibernate.default_batch_fetch_size=1000이런식으로 설정할 수도 있습니다.
번외
그러면 이제 fetch join을 쓰지않고 Batch_size만 쓰면 되나요?
그건 아닌게 fetch Join은 한방쿼리로 해결이 되는데 Batch_size를 사용하면 쿼리를 줄일 수 있으나 한방쿼리까지는 안될 수도 있다.
왜? 자식엔티티갯수가 해당 batch_size를 넘어가는경우 쿼리를 하나 또 만들어서 날려야하니까
결국 결론을 내리자면
-
hibernate.default_batch_fetch_size를 글로벌로 설정해서 N+1문제를 최대한 in쿼리로 성능보장을 한다.
-
OntoOne이나 ManytoOne같이 1관계 자식 엔티티에서는 Fetch Join을 적용하여서 한방쿼리를 갈긴다.
-
OneToMany,ManytoMany와 같이 ToMany의 경우에서는 가장 데이터가 많은 자식쪽에 Fetch Join을 실시한다.
왜냐하면 -> 가장 많은 데이터를 가진얘는 Fetch join을 통해서 한방쿼리를 실시하고, 나머지 Fetch Join이 없는 자식엔티티는 글로벌로 설정해놓은 Batch_size를 통해서 쿼리 성능을 보장한다.-끄읕-
