Prove 프로젝트를 진행하던 중에, 캐싱을 사용하여서 검색속도를 높이는 과정이 필요하게 되었다.
이번 글에서는 Redis란 무엇이고, 캐싱전략이 무엇인지 소개하고,
다음 글에서 실제 프로젝트에 어떻게 사용되었는지 설명하는 시간을 가져보겠다.
Redis에 대해서 간략하게 설명하자면, 캐싱을 사용하는 것이다.
만약 클라이언트가 운동에 관련된 계시글을 조회할때, 가장 좋아요가 많은 운동 계시글을 응답으로 보내준다면,
클라이언트가 요청을 할때마다, DB에다가 select * from prove where tags="Excersice" order By likes limit 1이런식으로 쿼리를 날리는게 아니라,
가장 좋아요가 많은 운동계시글은 캐싱을 해둬서 DB까지 내려가지 않고 캐시에서 가져와서 반환하면 속도가 빠를것이다.
이런 점을 숙지를 하고 이제부터 Redis에 대해서 설명해보도록 하겠다.
캐시
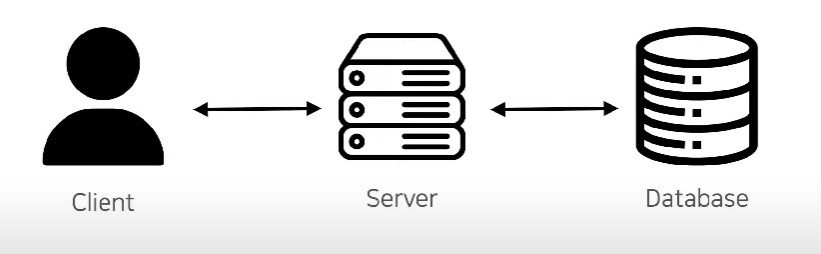
우리는 대부분 Client - server -DB로 되어있는 3 Tier 아키텍처를 대부분 사용한다.
서비스에 클라이언트가 증가함에따라서 요청이 많아지고, 이렇게 되면 DB에 많은 부하가 올것이다.
그러므로 서버와 DB사이에 캐시를 도입하면 DB의 부하를 줄이고, 성능적인 이점을 가져갈 수 있다.
그렇다면 캐시란 무엇인가?
캐시
데이터나 값을 미리 복사해놓는 임시 저장소이다.
이러한 캐시는 DP, 영속 컨텍스트 이런곳에서 사용이 된다.
JPA는 직접 DB에 접근하지 않고, 영속 컨텍스트에서 데이터를 가져와서 성능적인 이점을 가져올 수 있다.(당연히 캐시에 없으면 DB를 뒤져야한다.)
캐시 히트와 캐시 미스
애플리케이션이 원하는 데이터를 얻기위해서 캐시를 먼저 조회하게 됩니다.
- 캐시 히트
캐시에 데이터가 있어서 바로 받아올 수 있는 경우 - 캐시 미스
캐시에 데이터가 없어서 DB로 직접 찾아가서 조회를 해야하는 경우
캐시 전략 패턴
실제 캐시를 도입할 때 상황에 맞춰 적용될 수 있는 전략 패턴
읽기 전략
Look Aside
캐시에 데이터가 없을때 Aside(옆)에 해당하는 DB를 보는것.
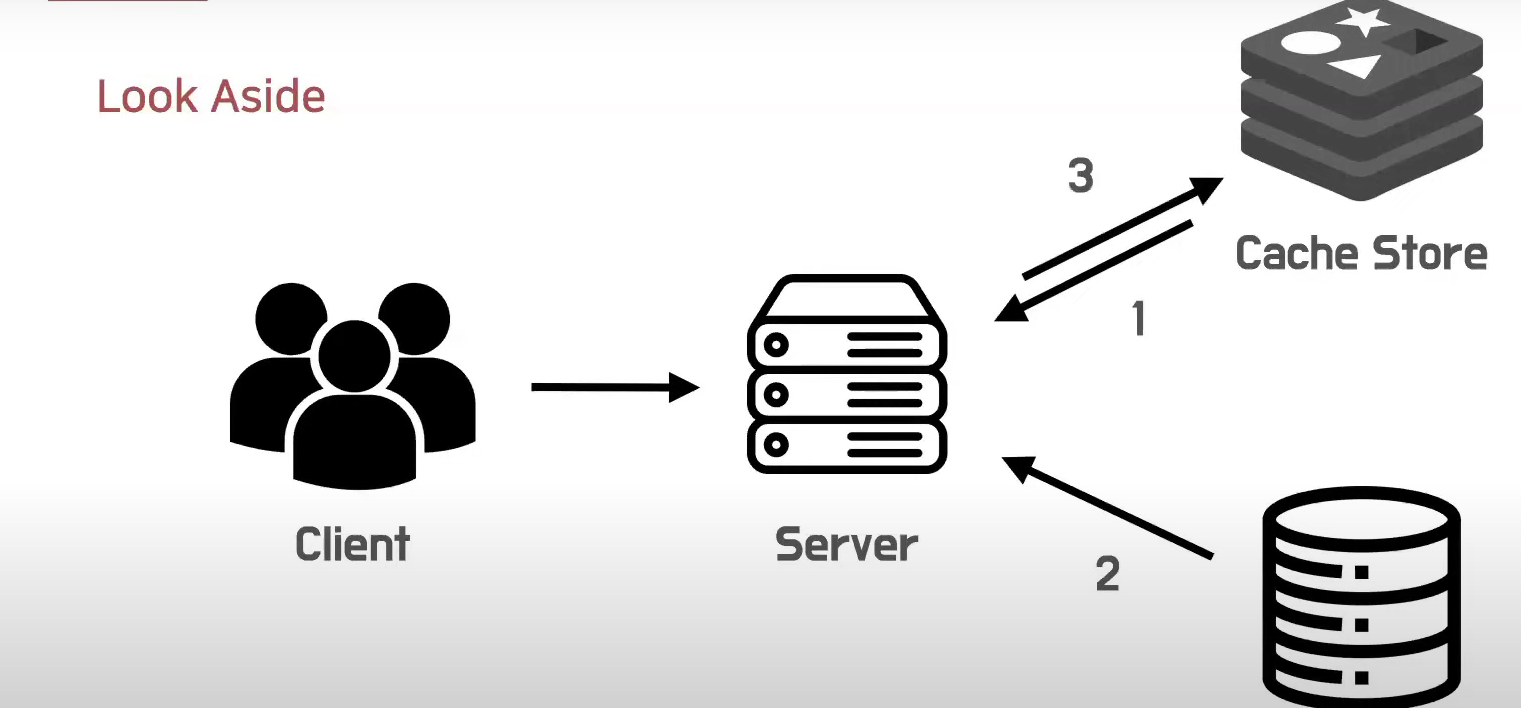
client가 서버에 데이터를 요청한다.
첫번째로 서버는 캐시를 본다.
만약 캐시에 해당 데이터가 없으면 DB에서 데이터를 읽어온다.
그리고, 해당 데이터를 캐시에 올려놓는다.
- 장점
캐시에 문제가 생기는 경우 DB로 요청을 위임 - 단점
DB와 캐시를 직접 잇는 연결점 즉, 동기화가 되지 않기 때문에 데이터 정합성 유지가 어렵다.
예를들어, DB에서 캐시로 member 1을 올려뒀는데, DB에서 member1을 지운다면, 현재 캐시에서는 member1이 있고, DB에는 없기 때문에 데이터 정합성이 어긋나는 상황이 발생 할 수 있다.
Read Through
항상 캐시를 통해 읽는 전략
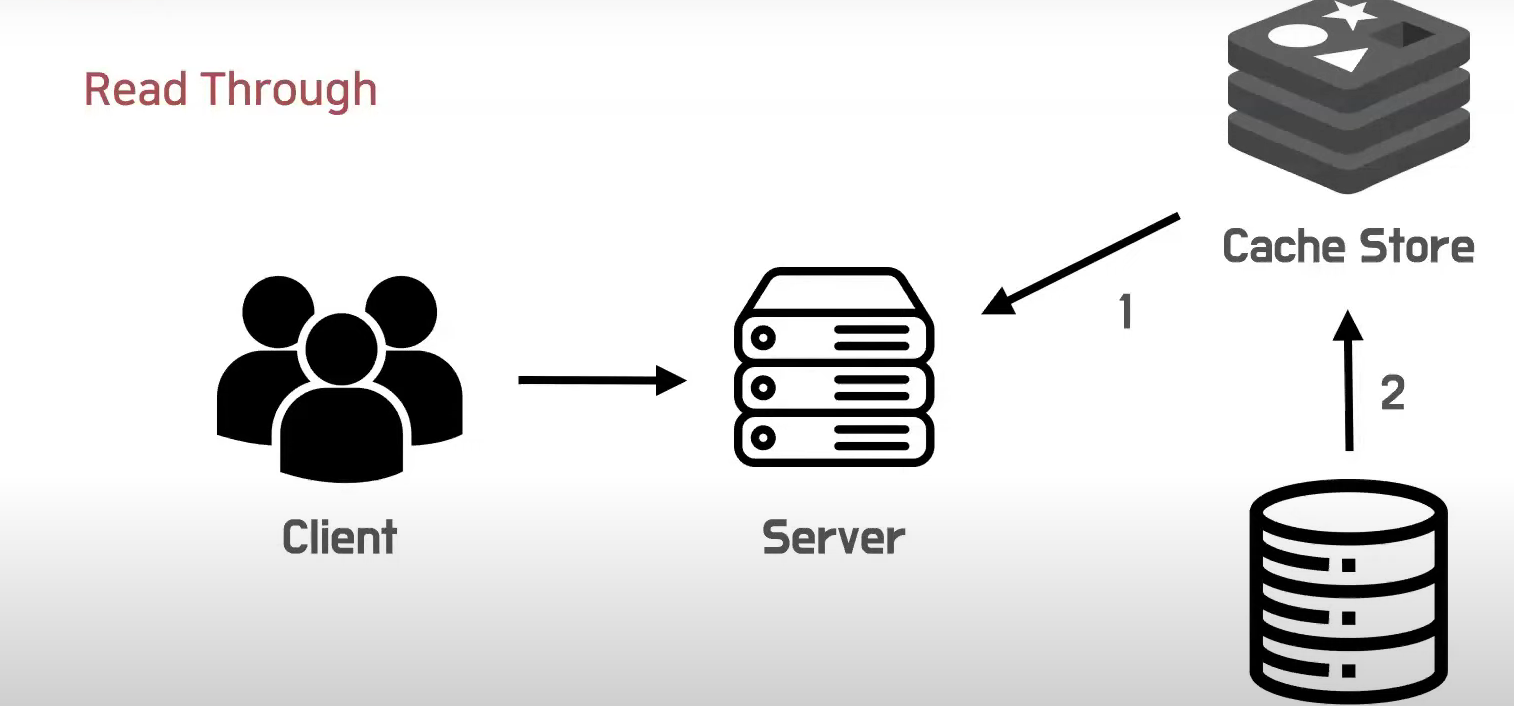
애플리케이션은 캐시 스토어로부터 데이터를 읽어온다.
만약 데이터가 캐시에 없다면, 캐시가 직접 데이터베이스로부터 직접 데이터를 가져온다.
그리고 그 데이터를 애플리케이션이 읽게 된다.
-
장점
캐시와 DB간에 연결점이 있기 때문에 정합성을 보장한다. -
단점
캐시가 죽어버리면 애플리케이션도 문제가 발생한다.
쓰기전략
Write Around
쓰기를 우회한다. 즉, 캐시를 우회해서 직접 쓴다는말.
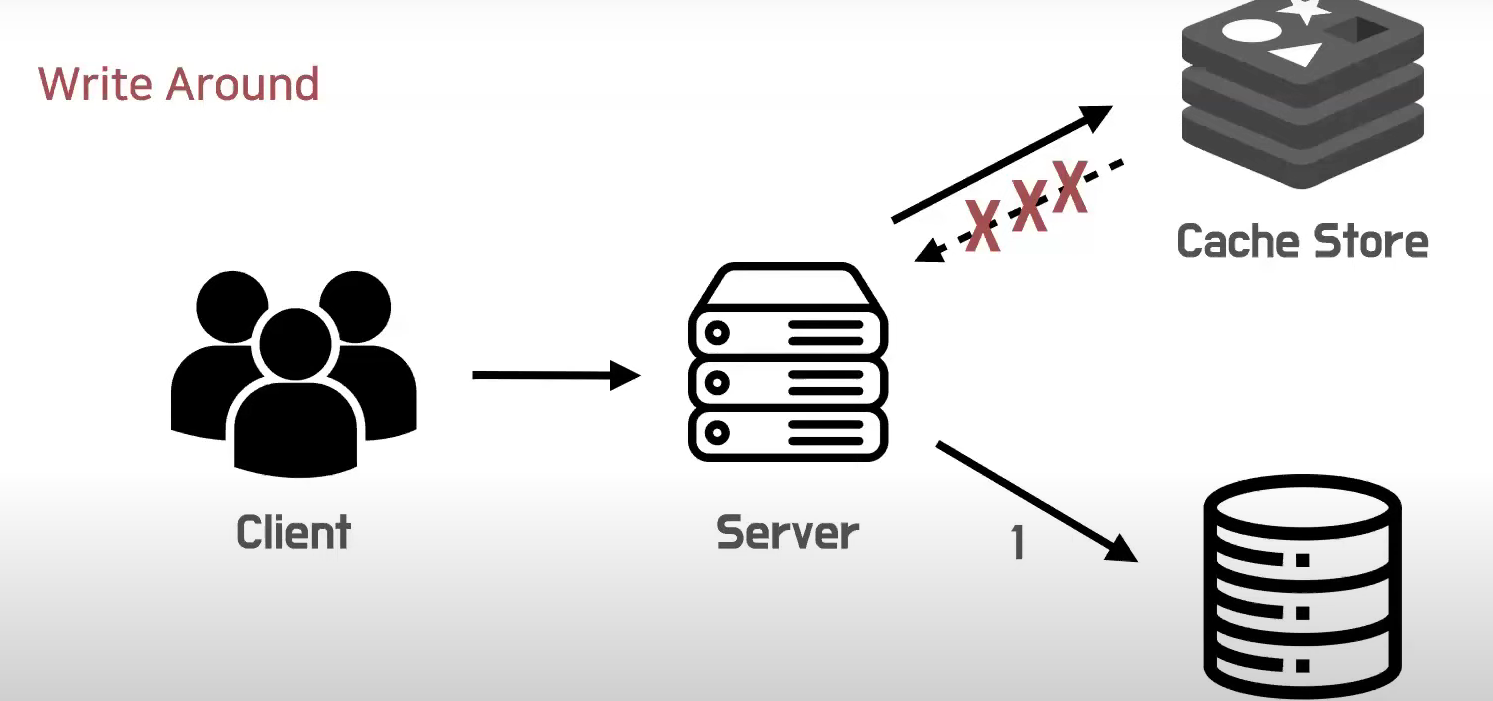
애플리케이션이 직접 데이터베이스에 바로 쓴다.
캐시전략과는 맞지 않게 캐시에 직접 쓰지 않고, DB에 직접 쓴다.
하지만, 이것을 읽기 전략과 혼합해서 사용할때는 캐시 미스가 발생하면 데이터를 캐시 스토어에서 쓰기도 한다.
장점
- 성능이 좋다. 왜냐하면 DB에 직접 쓰기 때문, 또한 불필요한 데이터를 캐시에 올리지 않고 바로 쓸 수 있기 때문에 리소스를 아낄 수 있다.
또한 캐시를 거쳐서 쓰지 않으므로 성능이 좋은 것도 있다.
단점 - 캐시와 DB에 연결점이 없기 때문에 데이터 정합성 유지가 어렵다.
Write Back
나중에 쓰다. 캐시에 데이터를 미리 한꺼번에 써 놓고 나중에 DB에 쓰기 작업을 진행한다.
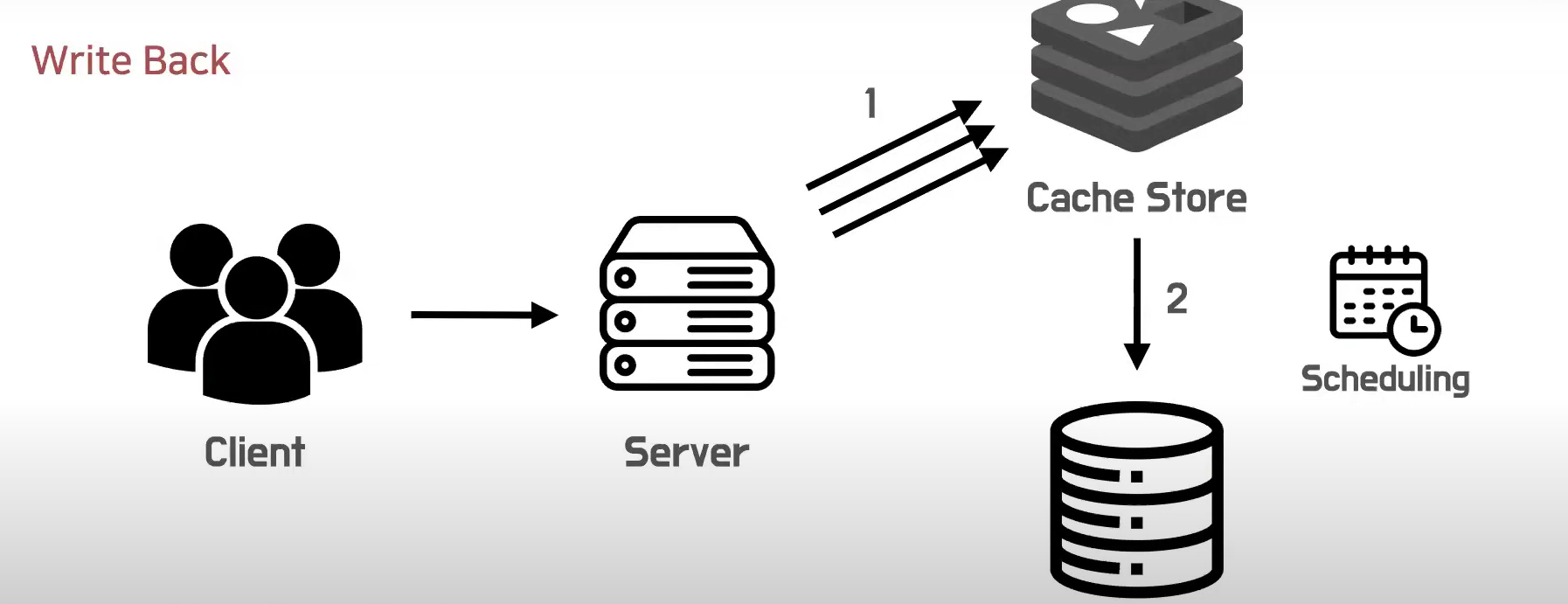
캐시에 쓰기 작없을 진행하는데, 많은양을 캐시에 써놓은 다음에 나중에 DB에서 쓰기 작업을 진행한다.
이떄, Scheduling이라는 방식을 사용한다.
일정시간이 지난 뒤에 한꺼번에 많은 양의 데이터를 한번의 쓰기 요청으로 해결할 수 있다.
장점
- 쓰기 횟수 비용을 줄일 수 있다.
이거 플젝에 적용(고민 부분),Redis내용 설명, Reids 적용, 더 깊이 생각 이거
원래 많은 양의 데이터를 쓰게 되면, insert문이 여러개 나가서 성능적으로 문제가 생길 수 있는데, 하나의 insert문으로 묶어서 데이터를 처리하게 되니까 성능적으로 이점을 가져갈 수 있다.
단점
** 캐시 스토어에만 데이터를 써놓은 상태에서, 캐시가 죽어버리게 된다면 데이터가 DB까지 직접 쓰이지 않으므로, 데이터 유실 문제가 발생할 수 있다.
Write Through
~통하여 쓰다. 즉, 항상 캐시를 통해서 쓰기를 진행한다.
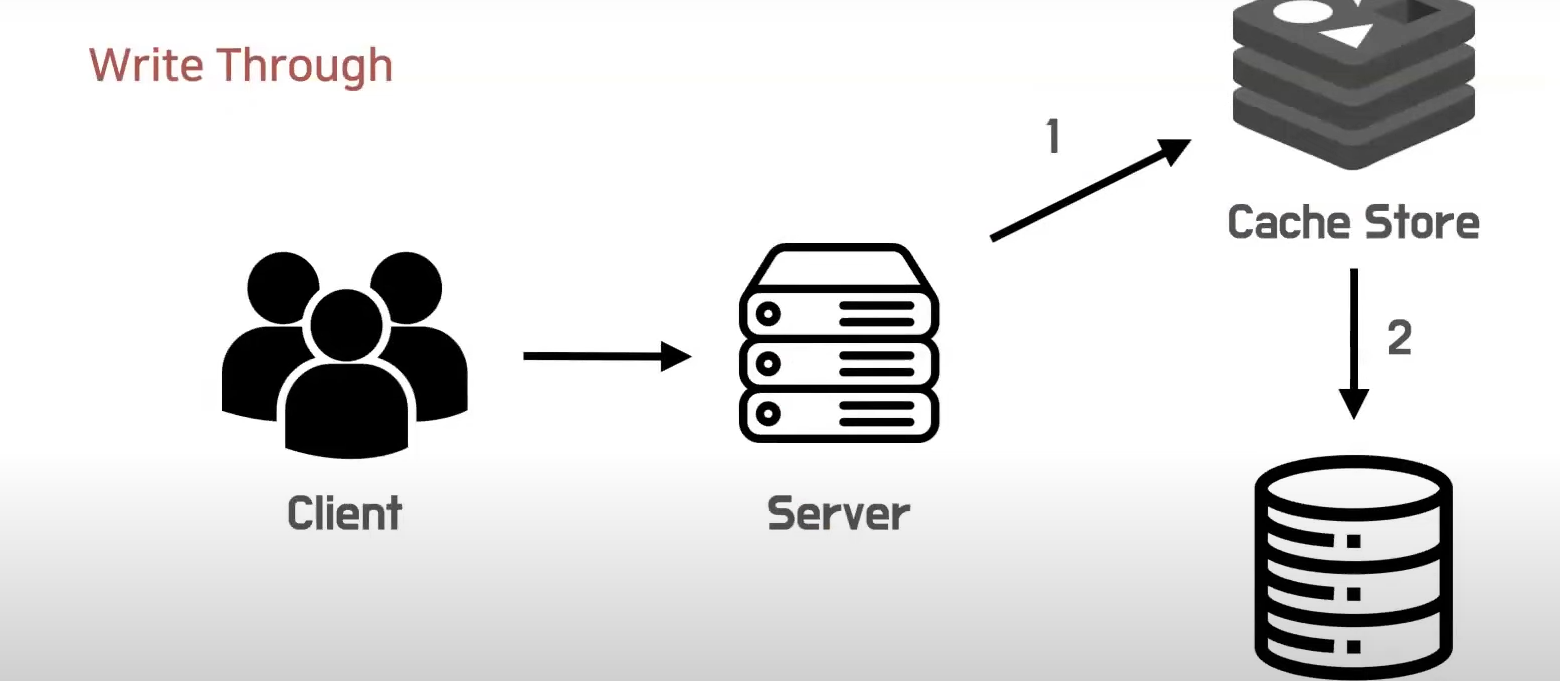
항상 캐시를 거치고 데이터 베이스로 가기 때문에, 데이터 정합성이 보장된다.
그러나 무조건 필수적으로 두번 쓰기가 되기 떄문에, 성능 문제를 고려해서 사용해야한다.
캐시 사용시 주의사항
어떤것을 캐싱해야할까?
- 자주 사용되면서 변경이 되지 않는 데이터
- 유실되어도 크게 문제가 없는 데이터
- 데이터베이스와 함께 사용할 때 데이터 정합성 문제를 고려
Redis
Redis - Remote Dictionary Server
외부에 사전 형태로 저장하는 서버
사전 형태: key-value
자바 컬렉션의 Hashmap과 유사
레디스를 메모리에 저장하는 Key-Value 기반의 NoSQL DBMS라고 할 수 있다.
그렇다면 Redis와 캐시는 어떤 상관관계를 가지고 있을까?
캐시: 데이터나 계산 결과를 미리 저장하여 빠른 액세스와 높은 성능을 제공하기 위한 저장소
캐시 구현방법: Memcached,Redis,Local Memory Cache등
즉 Redis는 캐시를 구현하는 방법 중 하나라고 할 수 있다.
그러나 Redis가 캐시용도로만 사용하는건 아니다.
캐싱용도 뿐만 아니라, 임시 작업 큐, 실시간 채팅, 메시지 브로커등의 역할을 수행한다고 한다.
Redis의 특징
-
빠른속도
Redis는 디스크가 아닌 메모리에 저장되어 빠른 속도로 접근이 가능하다.
단순 Get/Set과 같은 경우 1초당 10만번의 명령을 수행 가능하다. -
Data Structure
앞서 Redis는 Key-Value 형식이라고 하였는데 Value에 다양한 자료구조를 제공한다.
Key: String Value: Hash,List Set, Sorted Set ,,,, -
Single Tread
레디스는 싱글 스레드로 동작하여서 한번에 하나의 명령만을 처리한다.
그러므로 Race Condition이 거의 발생하지 않는다.Race Condition이란?
두개 이상의 프로세스가 동시적으로 하나의 리소스에 접근하여서 서로 경쟁하는 상태멀티스레드의 경우 각 스레드가 동시에 같은 자원에 접근하는 경우 오류가 생길 수 있다.
예를들어 스레드 A가 카운터 변수 0을 읽어들이고 +1을 하였는데, 중간에 스레드 B가 카운터 변수를 읽어들이면 +1된 상태에서 +1을 또하므로 스레드 A는 1을 원하는데 2가 되어있을 수 있다.그러나 Redis는 싱글스레드이므로 모든 명령이 직렬화 되어서 실행되므로 데이터 일관성이 보장된다.
-
Persistence
Redis는 앞서 메모리에 Data를 올리니까 항상 휘발성으로 데이터가 날라갈 수 있다 생각 할 수 있는데, 메모리에 저장된 데이터를 디스크에 영속화 할 수 있다.고로 서버에 치명적인 문제가 발생하더라도 복구가 가능하다.
해당 persistence 기능의 옵션으로 RDB,AOF 두가지 옵션이있다.
RDB: 현재 Redis메모리에 존재하는 데이터의 스냅샷을 남기는 방식
데이터를 모두 압축하여 저장하므로 AOF 방식보다는 크기가 작고, 데이터 자체를 저장하므로, 로딩하고 복구하는 속도가 빠르다.
단점으로는 백업중에 서버가 죽어버리면 특정한 간격으로 저장하므로 그 사이에 발생한 데이터에 대한 유실 가능성이 존재한다.
AOF: 데이터 변경이 일어나는 insert,update,delete와 같은 명령어가 실행될때마다, 해당 명령어를 로그파일에 기록한다.
장점으로는 저장속도가 빠르고, RDB와 달리 실시간 데이터 백업이 가능하여, 데이터 손실이 거의 일어나지 않는다.
단점으로는 모든 명령들을 파일로 기록하므로 파일 크기가 크고, 데이터를 저장하는게 아니라 명령을 저장하므로 복구 소요시간이 길다.
Redis를 어떻게 사용하면 좋을까?
데이터 타입에 대한 적절한 자료구조 사용
//이거 플젝에 사용하고 리뷰, 더 깊이 더 넓게 깊게 생각
//단순히 redis를 사용하여서 캐시 히트해서 빠르게 가져오는게 아니라, Redis의 자료구조를 사용하면 더 나은 성능을 뽑아낼 수 있음
만약 user_id가 1인 사용자의 최근 검색목록 3개를 조회하고 싶다고 치자.
그렇다면 DB에 쿼리를 날릴때는 어떻게 해야할까?
select * from search where user_id = 1 Order By reg_date DESC LIMIT 3
이런식으로 쿼리를 날려야 할 것이다.
그러나 중복데이터를 제거해야하는 부분도있고, 사용자 별로 데이터 갯수를 확인한 다음에 오래된 검색어를 삭제하는 작업까지 필요하다.
그러나 Redis의 Sorted Set을 사용하면 가중치를 기준으로 오름차순으로 정렬된다는 특징을 가지고 있으므로, 가중치를 날짜로 두면, 가장 나중에 검색한 data가 마지막 인덱스로 들어가는 것을 확인 할 수 있으므로, 마지막 인덱스의 data만 가져오면 된다.
또한, 사과,사과 로 검색을 하더라도 중복된 데이터를 저장하지 않는 Sorted Set 특징을 활용하면 성능을 더욱 높일 수 있다.
O(N)명령어를 주의해야한다.
Redis는 싱글 스레드로 작동하므로, KEYS/FLUSHALL/FLUSHDB/DELETE COLLECTIONS/ GET ALL COLLECTIONS와 같은 O(N)명령어를 사용하면 그 다음 명령어들이 해당 명령이 처리 될때까지 대기상태로 전환되므로, Redis를 빠른 성능을 위해서 사용했찌만 더 느린 성능이 제공될 수 있다.
메모리관리
Redis의 경우 인메모리 데이터 스토어 이므로 메모리관리가 필수적이다.
메모리 특성상 메모리 단편화가 발생한다.
메모리 단편화란 메모리가 작은 공간으로 나누어져 관리되므로 사용가능한 공간이 충분한대도 해당 메모리를 할당하지 못하는 상태를 의미한다.
그래서 실제 사용은 7Kb하는데, 차지하는 공간은 10Kb라고 인지할 수 있다.
따라서 우리는 실제 물리 메모리 사용량을 나타내는 RSS값을 모니터링하여서 메모리 관리를 해줘야한다.
Redis를 목적성에 맞게 사용하기
Redis를 캐시용으로 사용할지 저장소용으로 사용할지 목적을 명확히 하여 사용해야한다.
Persistence기능인 RDB,AOF가 장애 발생 가능성이 높은것으로 알려져 있다.
따라서 REdis에 저장되었던 데이터가 없어져도 문제가 없는지 일부 값이 유실되어도 치명적이지 않은지등을 판단해서 캐시용으로만 사용한다면 해당 Persistence기능을 off하는게 좋다.
