지난 글로벌 캐시로 redis 사용해보기 + 동시성 제어 2편
에는 동시성 문제를 해결하기 위해서 Synchronized 키워드에대해서 알아보았습니다. 그러나, Synchronized 키워드를 통해서는 분산환경에서는 사용될 수 없다는 것도 배웠습니다.
이번 포스팅에서는 데이터베이스 Lock과 레디스를 사용한 분산락을 통해서 어떻게 동시성을 해결 할 수 있는지 알아보겠습니다.
분산락이란?
분산 락이란 다수의 서버(또는 프로세스)가 동시에 같은 자원에 접근할 때 발생할 수 있는 동시성 문제를 해결하기 위해서 사용되는 동기화 메커니즘 이다.
분산 락의 핵심은 하나의 자원에 대해 한번에 하나의 서버만 작업을 수행할 수 있다는 것입니다. 이를 통해서 데이터의 동시 변경을 막고, 시스템 전체의 데이터 일관성을 유지하게 됩니다.
Pessimistic Lock - DB Level
DB에서 지원하는 Pessimistic Lock을 사용하여서 실제 DB에다가 Exclusive lock을 걸어서 데이터 정합성을 보장할 수 있습니다.
-
Exclusive Lock
배타적 잠금, 쓰기 잠금이라고 불립니다. 어떤 트랜잭션에서 데이터를 변경하고자 할때 해당 트랜잭션이 완료 될때 까지 해당 테이블 또는 Row에 다른 트랜잭션이 읽거나 쓰지 못하게 한다.
=> Exclusive Lock이 걸리면 Shared Lock을 걸 수 없다.
=> Exclusive Lock에 걸린 테이블,레코드등의 자원에 대해 다른 트랜잭션이 Exclusive Lock을 걸 수 없다. -
Shared Lock
읽기 잠금, 어떤 트랜잭션에서 데이터를 읽고자 할때 다른 Shared Lock을 허용하지만, Exclusive Lock은 불가능하다.
=> 다른 사용자가 Data를 동시에 읽을 수 있게 하되 변경은 불가능하게 한다.
=> 해당 자원에 Shared Lock이 동시에 여러개 적용될 수 있다.
=> 어떤 자원에 shared Lock이 하나라도 걸려 있으면, Exclusive Lock을 걸 수 없다.
JPA에서 @Lock 어노테이션을 사용하여서 LockMode Typed을 PESSIMISTIC_WRITE로 설정ㅇ하여서 Pessimistic Lock을 활용한 조회를 한다.
다른 트랜잭션에서 조회한 데이터를 읽거나 쓸 수 없다.
LockMode Type
- OPTIMISTIC: 낙관적 락으로 트랜잭션 시작 시 버전 점검이 수행되고, 트랜잭션 종료 시에도 버전 점검이 수행된다.
- OPTIMISTIC_FORCE_INCREMENT: 낙관적 락을 사용하면서, 추가로 버전을 강제로 증가시키는 방법PESSIMISTIC_READ: 비관적락을 사용하면서, 다른 트랜잭션에게 읽기만 허용한다. (Shared Lock을 건다)
- PESSIMISTIC_WRITE: 비관적락을 사용하면서, Exclusive Lock을 이용해서 락을 건다. 다른 트랜잭션에서 쓰지도 읽지도 못한다.
- PESSIMISTIC_FORCE_INCREMENT: Exclusive Lock을 이용해서 락을 걸고 동시에 버전을 증가시킨다.
public interface StoreLikeRepository extends JpaRepository<Store,Long> {
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Store s where s.id = :storeId")
Store findByPostIdWithPessimisticLock(Long storeId);
}@Service
public class StoreService {
private final StoreLikeRepository storeLikeRepository;
// 생성자를 통한 StoreLikeRepository 주입
public StoreService(StoreLikeRepository storeLikeRepository) {
this.storeLikeRepository = storeLikeRepository;
}
@Transactional
public void increaseWithPESSIMISTIC_WRITE(Long postLikeId) {
Store store = storeLikeRepository.findByPostIdWithPessimisticLock(postLikeId);
store.increase();
}
}@RequiredArgsConstructor
@Controller
public class StoreController {
private final StoreService storeService;
private final OptimisticLockStoreFacade optimisticLockStoreFacade;
@GetMapping("/like")
public ResponseEntity<String> like(){
storeService.increaseWithPESSIMISTIC_WRITE(100L);
return new ResponseEntity<>("success", HttpStatus.OK);
}
}@Test
void increase_with_100_request_to_multi_server() throws InterruptedException {
// given
int threadCount = 100;
RestTemplate restTemplate = new RestTemplate();
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
// when
for (int i = 0; i < threadCount; i++) {
final int ii = i;
executorService.submit(() -> {
try {
int port = (ii % 2 == 0) ? 8080 : 8081;
ResponseEntity<Void> responseEntity = restTemplate.getForEntity(
"http://localhost:" + port + "/like",
Void.class);
} finally {
latch.countDown();
}
});
}
latch.await();
}인텔리제이 IDE환경에서 서버를 2개 두고 요청을 보내는건, 2편글에서 설명해두었으니, 그 부분에서 확인하면 되곘다.
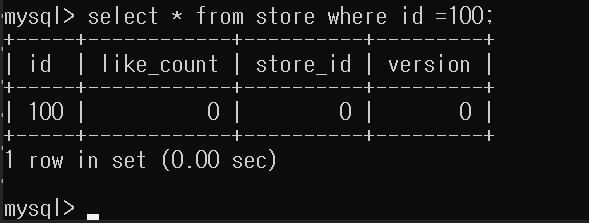
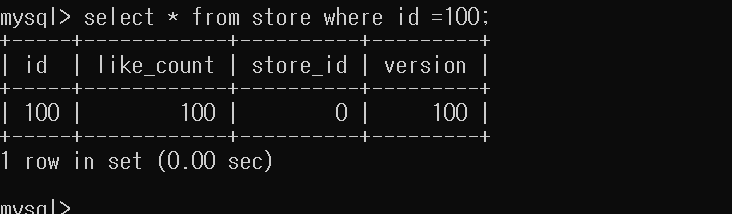
정상적으로 100으로 나오는 것을 확인 할 수 있다.
일단 근데 데이터 정합성은 보장하지만, 데이터 테이블이나 Row에 자체적으로 Lock을 거니까, 다른 트랜잭션은 읽기나 쓰기를 하지 못하므로 대기한다. 고로, 성능이 좋지는 않다.
Optimistic Lock - Applicaiton Level
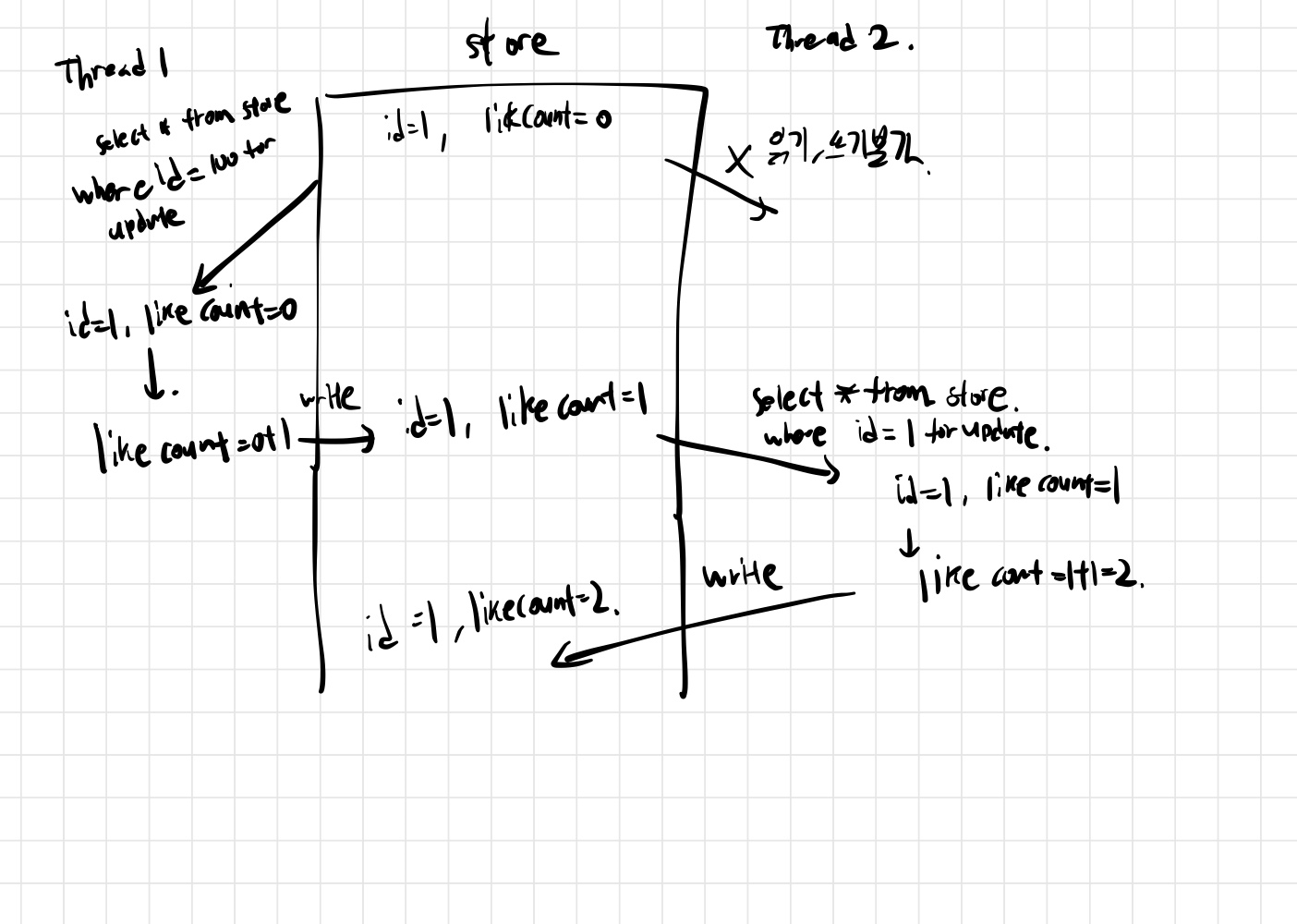
해당방법은 Pessimistic Lock과는 달리 실제 데이터 베이스에다가 Lock을 거는게 아니라, 버전등의 구분 칼럼을 사용하여서 정합성을 맞추는 방법이다.
데이터를 읽은 후, 업데이트를 수행할때, 읽었던 버전을 where절에 추가하여서 데이터 정합성이 맞는지 확인하고 업데이트를 진행한다.
그림처럼, 만약 다른 스레드에 의해서 버전이 증가하였고, 현재 스레드 버전 값이 데이터 베이스의 데이터 버전과 일치하지 않는다면 실패한다.
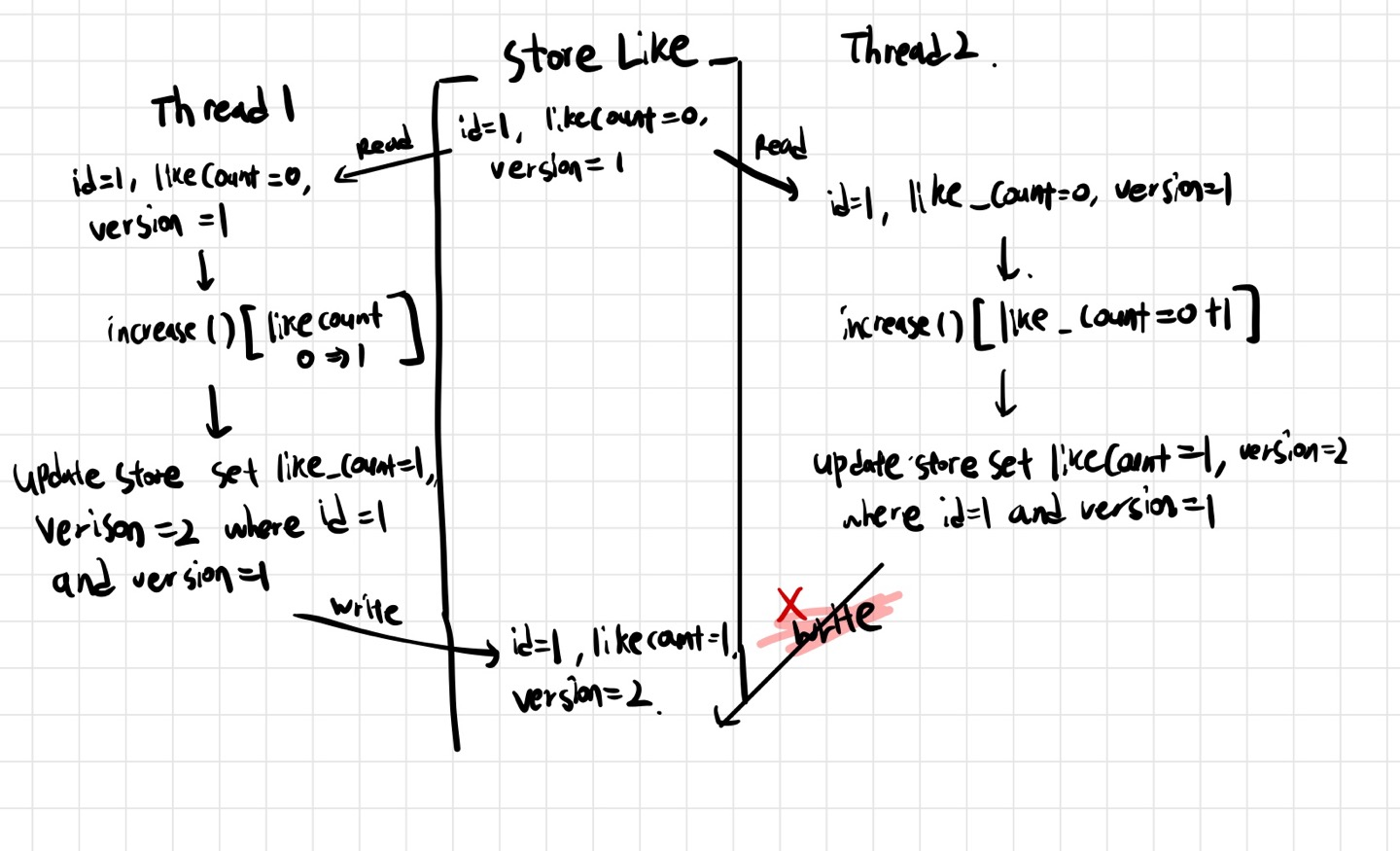
Opitimistic Lock을 사용하면, 개발자는 버전 불일치로 인한 실패시 어떻게 대응할 것인지 예외(복구)로직을 작성해야한다.
@Entity
@Getter
@Setter
@Table(name = "store")
public class Store {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
private Long storeId;
@Column(nullable = false)
private Long likeCount;
@Version
private Long version=0L;
private static final long DEFAULT_INCREASED_LIKE_COUNT = 1;
// 기본 생성자 (JPA에서 사용)
protected Store() {}
public Store (long id,Long lcount){
storeId=id;
likeCount=lcount;
}
// 좋아요 수 증가 메서드
public void increase() {
this.likeCount += 1;
System.out.println("증가");
}
}리포지토리
@Lock(LockModeType.OPTIMISTIC)
@Query("select s from Store s where s.id = :storeId")
Store findByStoreIdWithOptimisticLock(Long storeId);서비스
@Service
public class StoreService {
private final StoreLikeRepository storeLikeRepository;
private final Lock lock = new ReentrantLock();
// 생성자를 통한 StoreLikeRepository 주입
public StoreService(StoreLikeRepository storeLikeRepository) {
this.storeLikeRepository = storeLikeRepository;
}
@Transactional
public void increaseWithOptimistic_Write(Long storeId) {
Store store = storeLikeRepository.findByStoreIdWithOptimisticLock(storeId);
store.increase();
}
}좋아요 update를 실행할때, 버전이 불일치하면 org.springframework.dao.OptimisticLockingFailureException이 발생한다.
해당 예외를 Catch하여 재시도 로직을 작성하기 위해서 Facade서비스를 만들었다.
현재 로직에서는 버전이 불일치하여 로직이 실패하면, 로그를 찍고 0.05초 후에 재시도한다.
@Component
public class OptimisticLockStoreFacade {
private final StoreService storeService;
public OptimisticLockStoreFacade(StoreService storeService) {
this.storeService = storeService;
}
public void increase(Long storeId) {
while (true) {
try {
storeService.increaseWithOptimistic_Write(storeId);
break;
} catch (OptimisticLockingFailureException exception) {
try {
System.out.println("Exception 발생 Thread sleep");
Thread.sleep(50);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
}
}
}Controller
@RequiredArgsConstructor
@Controller
public class StoreController {
private final StoreService storeService;
private final OptimisticLockStoreFacade optimisticLockStoreFacade;
private final StoreFacadeService storeFacadeService;
@GetMapping("/like")
public ResponseEntity<String> like(){
optimisticLockStoreFacade.increase(100L);
return new ResponseEntity<>("success", HttpStatus.OK);
}
}
TestCode
@Test
void increase_with_100_request_to_multi_server() throws InterruptedException {
// given
int threadCount = 100;
RestTemplate restTemplate = new RestTemplate();
ExecutorService executorService = Executors.newFixedThreadPool(40);
CountDownLatch latch = new CountDownLatch(threadCount);
// when
for (int i = 0; i < threadCount; i++) {
final int ii = i;
executorService.submit(() -> {
try {
int port = (ii % 2 == 0) ? 8080 : 8081;
ResponseEntity<Void> responseEntity = restTemplate.getForEntity(
"http://localhost:" + port + "/like",
Void.class);
} finally {
latch.countDown();
}
});
}
latch.await();
}Testcode 실행전
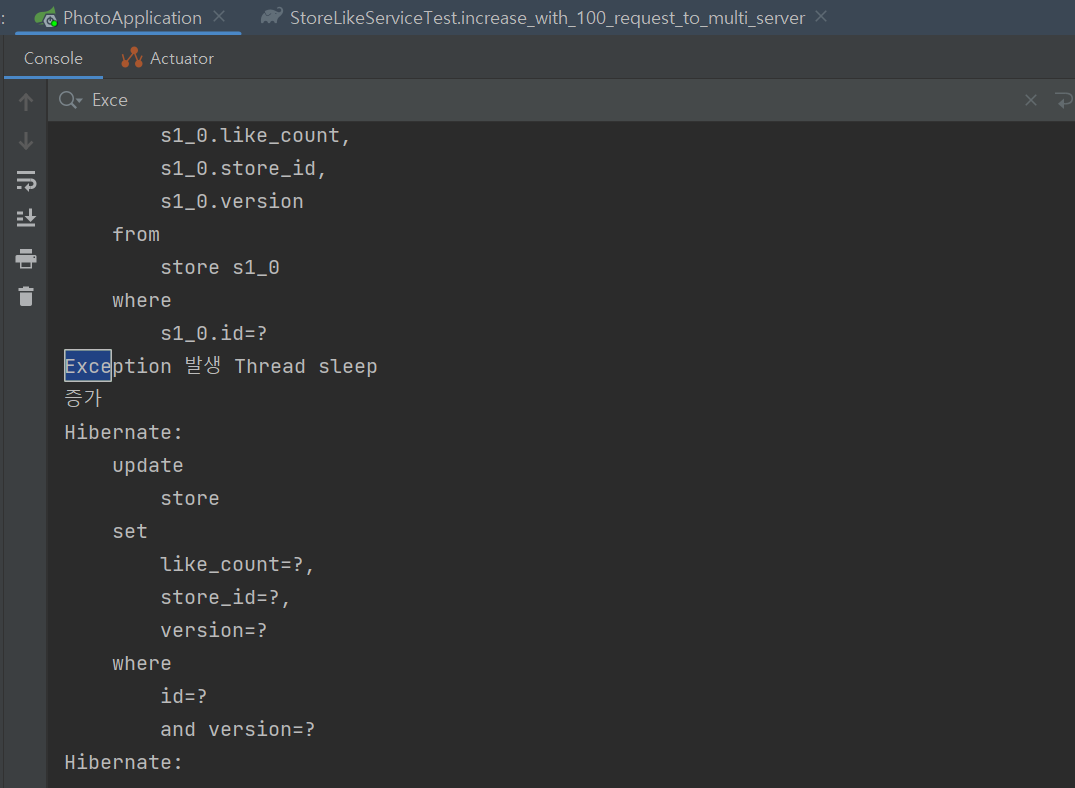
Exception이 발생하면, Thread를 sleep시키고 while문을 통해 다시 시도한다.
Test code 실행후
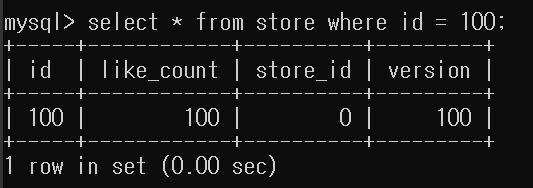
정확하게 100의 count가 증가한것을 확인할 수 있다.
Optimisitc Lock은 별도의 Lock을 잡지 않아서(DB에다가 락을 치지 않음) 성능 상 장점이 있을 수 있지만, 업데이트가 실패하면 개발자가 직접 복구 로직을 작성해야 한다는 번거로움과 충돌이 빈번하면 복구 로직으로 인해 오히려 성능이 안 좋아진다는 단점이 존재한다.
그럼 Pessimistic Lock과 Optimisitc Lock 중 어느 것을 사용해야할 까?
만약 충돌이 빈번하게 발생한다면, 복구 로직으로 인해 평균 응답속도가 증가한, Optimisitc Lock 대신 Pessimistic Lock을 사용하는것이 좋다.
반면에 충돌이 빈번하지 않다면, 실제 데이터 베이스에 락을 거는 것이 아닌 Optimistic Lock을 사용하는 것이 좋다.
Named Lock 사용 - Database Level
Named Lock은 이름을 가진 metadata Locking이다. 이름을 가진 Lock을 획득한 다음에 해제할 때까지 다른 트랜잭션에서는 해당 Lock을 획득할 수 없도록 해서 동시성을 보장한다.
Pessimistic Lock처럼 DB에다가 락을 거는게 아닌, 테이블이나 레코드, 데이터베이스 객체에다가 락을 걸지 않고, 사용자가 지정한 문자열에 대해 락을 획득하고 반납한다.
storeId가 100이면, 100이라는 이름의 락이 생성된다. 해당 락은 해당 데이터베이스 내의 모든 세션에서 동일한 이름을 사용할 경우 공유된다.
Named Lock의 장점은 Redis를 사용하기 위한 인프라 구축, 유지보수 비용이 발생하지 않고, MySQL을 사용해 분산 락을 구현할 수 있다.
단점으로는 Lock이 자동으로 해제되지 않기 때문에, 별도의 명령어로 해제를 수행하거나, 선점 시간이 끝나야 해제가 된다.
또한, 일시적인 락의 정보가 DB에 저장되고, 락을 획득,반납하는 과정에서 DB에 부하가 올 수 있다.
제일 중요한건, 락과 비즈니스로직의 트랜잭션을 분리해야한다.
락과 비즈니스 로직의 트랜잭션을 분리하면서 문제가 생긴다.
실제 로직을 내가 구현하였는데, release()메서드를 통해서 Lock을 해제하고, checkResult()메서드를 통해서 결과를 살펴봤는데, 락이 제대로 해제되지 않고 오류가 계속 발생하였다.
해당 문제를 해결하기 위해서 거의 1주일을 소비했는데, 로직은 정확한데 도저히 에러가 왜 발생하는 지 몰랐는데 문제의 이유는 커넥션관리를 제대로 못했기 때문이다.
네임드 락을 사용할때는 커넥션 관리에 주의를 해야한다. 왜냐하면, 네임드 락을 사용할때는 일반적인 락보다는 더 많은 커넥션을 소모하기 때문이다.
Named Lock을 한번 할때 커넥션을 2개를 사용한다. 앞에서 락과 비즈니스 로직의 트랜잭션을 분리한다고 했는데, 이 때문에 Lock 획득할때 Connection을 1개 쓰고, Transaction에 필요한 커넥션 1개 해서 한번 Lock을 걸고, 비즈니스 로직을 수행할때마다 2개의 커넥션을 쓴다.
네임드 락을 사용하는 커넥션이 락을 유지하는 동안 종료되지 않고 유지되어야하므로, Get_Lock을 호출하여서 락을 얻고 락을 반납하기 전까지 계속 커넥션을 점유하게 된다. 이러면 트랜잭션을 수행할때 커넥션을 한개 더 가져다 쓰면, 커넥션 풀의 크기가 작은 경우, 네임드 락과 트랜잭션 요청이 동시에 몰리면서 커넥션 풀이 빠르게 소진될 수 있으므로, 별도 데이터 소스를 고려하거나 커넥션 풀을 넉넉하게 설정해야한다.
spring:
datasource:
hikari:
maximum-pool-size: 40Repository
@Repository
public class StoreLockRepository {
private static final String GET_LOCK = "SELECT GET_LOCK(:storeId, 3)";
private static final String RELEASE_LOCK = "SELECT RELEASE_LOCK(:storeId)";
private static final String EXCEPTION_MESSAGE = "LOCK을 수행하는 중 오류가 발생하였습니다.";
private final NamedParameterJdbcTemplate jdbcTemplate;
public StoreLockRepository(final NamedParameterJdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
public <T> T executeWithLock(final String storeId, final Supplier<T> supplier) {
try {
final int lockNumber = getLock(storeId);
if (lockNumber == 1) {
return supplier.get();
}
throw new IllegalStateException("이미 다른 프로세스에서 락을 획득했습니다.");
} finally {
releaseLock(storeId);
}
}
private int getLock(final String storeId) {
final Map<String, Object> params = new HashMap<>();
params.put("storeId", storeId);
return jdbcTemplate.queryForObject(GET_LOCK, params, Integer.class);
}
private void releaseLock(final String storeId) {
final Map<String, Object> params = new HashMap<>();
params.put("storeId", storeId);
final Integer result = jdbcTemplate.queryForObject(RELEASE_LOCK, params, Integer.class);
checkResult(result);
}
private void checkResult(final Integer result) {
if (result != 1) {
throw new RuntimeException(EXCEPTION_MESSAGE);
}
}
}
해당 StoreLockRepository에서 락을 획득하고 해제하는 로직이 있다.
-
executeWithLock메서드
해당 메서드는 storeId에 대해 락을 시도하고, 락을 얻으면 파라미터로 넘어온 increas()메서드를 실행해 비즈니스 로직을 수행한뒤, 락을 해제한다.storeId는 네임드 락 이름으로 사용된다.
-
getLock메서드
Get_LOCK SQL쿼리를 통해서 락을 시도한다.
GET_LOCK(:storeId,3)쿼리는 만약 storeId가 100이 넘어온다면, 100이라는 네임드 락이 생성되고, 3초 동안 락을 기다린다.네임드 락은 MySQL 서버 내부 메모리에 저장되며, 특정 테이블이나 파일에 저장되지 않는다.
3초동안 기다린다는 것은, 락이 이미 다른 프로세스에 의해 사용 중일 때, 요청한 프로세스가 락을 기다리는 최대시간을 설정한 것이다. StoreId가 100인 락이 이미 다른 프로세스에서 사용중일 경우, 새로 락을 요청하는 프로세스는 최대 3초동안 해당 락이 해제되기를 기다린다.
@Service
@RequiredArgsConstructor
public class StoreFacadeService {
private final StoreLockRepository storeLockRepository;
private final StoreService storeService;
@Transactional
public void addLikeCount(Long storeId) {
// StoreLockRepository를 통해 락을 얻고, 락을 얻은 후에 StoreService의 increase 메서드를 실행
storeLockRepository.executeWithLock(storeId.toString(), () -> {
storeService.increase(storeId);
return null; // 반환값은 없으므로 null을 반환
});
}
}@Service
public class StoreService {
private final StoreLikeRepository storeLikeRepository;
// 생성자를 통한 StoreLikeRepository 주입
public StoreService(StoreLikeRepository storeLikeRepository) {
this.storeLikeRepository = storeLikeRepository;
}
@Transactional
public void increase(Long storeLikeId) {
try {
Store store = storeLikeRepository.findById(storeLikeId)
.orElseThrow(() -> new NoSuchElementException("Store not found with id: " + storeLikeId));
store.increase();
} catch (NoSuchElementException e) {
System.err.println("Error: " + e.getMessage());
}
}
}지금 현재는 addLikeCount에서 Transactional을 시작해서 StoreService의 increase메서드에 Transactional이 있지만 하나의 트랜잭션을 묶어서 트랜잭션을 진행하였다.
처음에 당연히 StoreFacadeService의 increase메서드에도 Transactional을 사용하여서 실제 비즈니스 로직까지 트랜잭션을 묶어서 실행해야 한다고 생각했다.
그러나, 이렇게 하면 NamedLock이 하나도 동작하지 않는다.
왜냐하면, increase()메서드를 통해서 store의 like_count값을 바꾼다고 해도, 변경되지 않는다.
왜냐하면 StoreFacadeService의 increase()메서드랑 트랜잭션을 묶어놨기때문에 StoreService의 increas()메서드를 나와서 StoreFacadeService의 increase()가 끝나고 Commit을 치는데, 이때 다른 트랜잭션이 수행되면, 해당 변경 내용을 즉시 반영 할 수 없기 때문이다.
고로, 첫번째 메서드(StoreService의 increase())가 끝났음에도 불구하고 변경된 데이터가 커밋되지 않아, 이후 메서드 호출에서 최신 데이터를 반영하지 못한다.
REQUIRES_NEW 전파 옵션사용
@Service
public class StoreService {
private final StoreLikeRepository storeLikeRepository;
// 생성자를 통한 StoreLikeRepository 주입
public StoreService(StoreLikeRepository storeLikeRepository) {
this.storeLikeRepository = storeLikeRepository;
}
@Transactional(propagation = Propagtion.REQUIRES_NEW)
public void increase(Long storeLikeId) {
try {
Store store = storeLikeRepository.findById(storeLikeId)
.orElseThrow(() -> new NoSuchElementException("Store not found with id: " + storeLikeId));
store.increase();
} catch (NoSuchElementException e) {
System.err.println("Error: " + e.getMessage());
}
}
}그러면, 이렇게 storeService의 increase메서드의 전파옵션만 바꾸면 될까?
그런데 여기선 큰 문제가 있다.
만약 커넥션풀의 커넥션이 3개라고 가정하면,
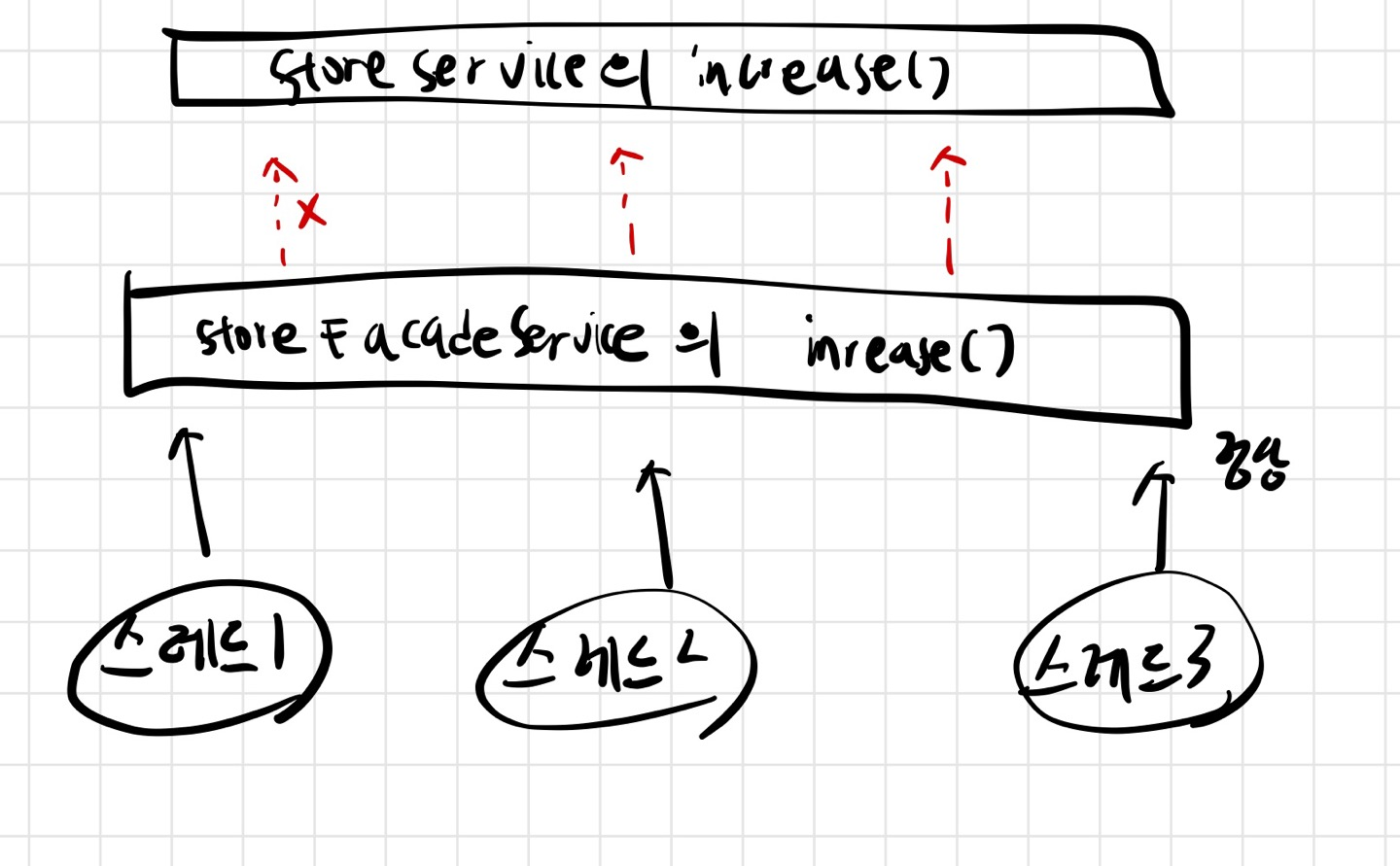
처음 StoreFacadeService의 increase메서드에 스레드 1,2,3이 커넥션을 할당해서 사용한다.
그러나, 두번째 StoreService의 increase메서드는 전파속성이 NEW이므로 3개의 스레드 모두 어느 하나 커넥션이 반환되기를 기다리지만, 서로 메서드가 끝나야지만 커넥션이 반환된다. 고로 데드락이 발생한다.
그러면 FacadeService의 transaction을 빼면되는거 아닌가? 라고 생각 할 수 있다.
@Service
@RequiredArgsConstructor
public class StoreFacadeService {
private final StoreLockRepository storeLockRepository;
private final StoreService storeService;
public void addLikeCount(Long storeId) {
// StoreLockRepository를 통해 락을 얻고, 락을 얻은 후에 StoreService의 increase 메서드를 실행
storeLockRepository.executeWithLock(storeId.toString(), () -> {
storeService.increase(storeId);
return null; // 반환값은 없으므로 null을 반환
});
}
}그러나 NamedLock에서는 Release_Lock을 하면 해당 GET_LOCK을 할때 가져온 Connection에 락을 반환해야한다.
고로, GET_LOCK을 할 때 가져온 Connection을 그대로 RELEASE_LOCK을 할 때 사용해야한다.
고로, 이렇게 구현을 해버리면, StoreService에서 increase()메서드가 종료된 후에 Connection을 반환하면서 획득한 Lock을 반환하지 못하는 경우가 발생한다.
그러므로 GET_LOCK과 RELEASE_LOCK을 할 때 동일한 Connection을 사용해야한다.
최종코드
@Repository
public class StoreLockRepository {
private static final String GET_LOCK = "SELECT GET_LOCK(:storeId, 3)";
private static final String RELEASE_LOCK = "SELECT RELEASE_LOCK(:storeId)";
private static final String EXCEPTION_MESSAGE = "LOCK을 수행하는 중 오류가 발생하였습니다.";
private final NamedParameterJdbcTemplate jdbcTemplate;
public StoreLockRepository(final NamedParameterJdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Transactional
public <T> T executeWithLock(final String storeId, final Supplier<T> supplier) {
try {
final int lockNumber = getLock(storeId);
if (lockNumber == 1) {
return supplier.get();
}
throw new IllegalStateException("이미 다른 프로세스에서 락을 획득했습니다.");
} finally {
releaseLock(storeId);
}
}
private int getLock(final String storeId) {
final Map<String, Object> params = new HashMap<>();
params.put("storeId", storeId);
return jdbcTemplate.queryForObject(GET_LOCK, params, Integer.class);
}
private void releaseLock(final String storeId) {
final Map<String, Object> params = new HashMap<>();
params.put("storeId", storeId);
final Integer result = jdbcTemplate.queryForObject(RELEASE_LOCK, params, Integer.class);
checkResult(result);
}
private void checkResult(final Integer result) {
if (result != 1) {
throw new RuntimeException(EXCEPTION_MESSAGE);
}
}
}@Service
@RequiredArgsConstructor
public class StoreFacadeService {
private final StoreLockRepository storeLockRepository;
private final StoreService storeService;
public void addLikeCount(Long storeId) {
// StoreLockRepository를 통해 락을 얻고, 락을 얻은 후에 StoreService의 increase 메서드를 실행
storeLockRepository.executeWithLock(storeId.toString(), () -> {
storeService.increase(storeId);
return null; // 반환값은 없으므로 null을 반환
});
}
}
@Service
public class StoreService {
private final StoreLikeRepository storeLikeRepository;
// 생성자를 통한 StoreLikeRepository 주입
public StoreService(StoreLikeRepository storeLikeRepository) {
this.storeLikeRepository = storeLikeRepository;
}
//원래는 그냥 @Transactional, NameLock에서 조건 추가
@Transactional(propagation = Propagation.REQUIRES_NEW, timeout = 10)
public void increase(Long storeLikeId) {
try {
Store store = storeLikeRepository.findById(storeLikeId)
.orElseThrow(() -> new NoSuchElementException("Store not found with id: " + storeLikeId));
store.increase();
} catch (NoSuchElementException e) {
System.err.println("Error: " + e.getMessage());
}
}
}여기서 timeout을 설정해 데드락과 동시성을 제어하였다.
@RequiredArgsConstructor
@Controller
public class StoreController {
private final StoreService storeService;
private final OptimisticLockStoreFacade optimisticLockStoreFacade;
private final StoreFacadeService storeFacadeService;
@GetMapping("/like")
public ResponseEntity<String> like(){
storeFacadeService.addLikeCount(100L);
return new ResponseEntity<>("success", HttpStatus.OK);
}
}전파옵션이 NEW이기 때문에
update문이 바로 날라가는것을 확인할 수 있다.
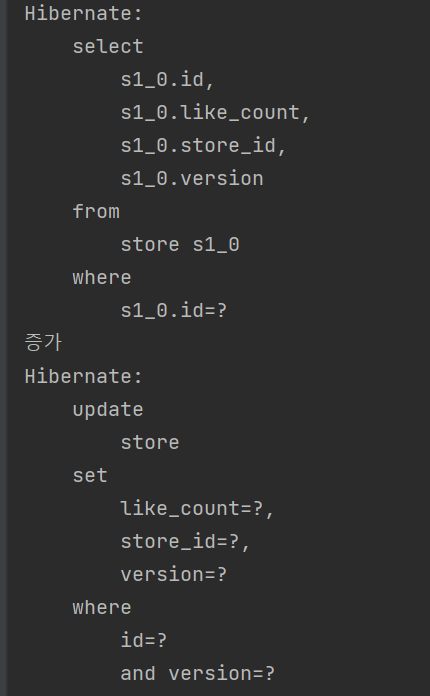
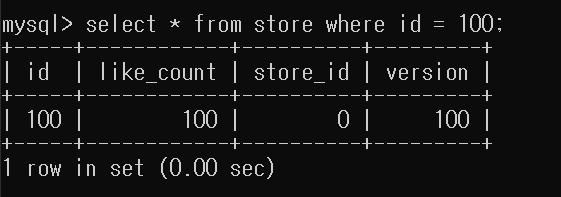
정합성 또한 맞는다.
Redis를 활용한 분산락 제어
지금까지는 데이터 베이스 Lock을 활용하여서 동시성을 해결하였다.
그러나, 데이터베이스에다가 직접 락을 걸기에는 결국, 디스크 I/O가 발생하기 때문에 성능이 느리다는 단점이 존재한다.
그러므로, Redis를 활용하면 App - Redis - DB 이런식으로 계층이 형성되므로, DB까지 가지 않고 Redis에서 Lock을 치므로, 성능을 개선할 수 있다.
Redis Lettuce 라이브러리 활용
Redis의 Lettuce 라이브러리를 사용하면 Spin Lock 방식을 사용하여서 동시성을 만족한다.
그렇다면, Spin Lock이란 무엇일까?
Spin Lock
Race Condition 상태에서 Lock이 반환될 때까지, 즉 Critical section에 진입이 가능할 때까지 프로세스가 재시도하며 대기하는 상태를 말한다.
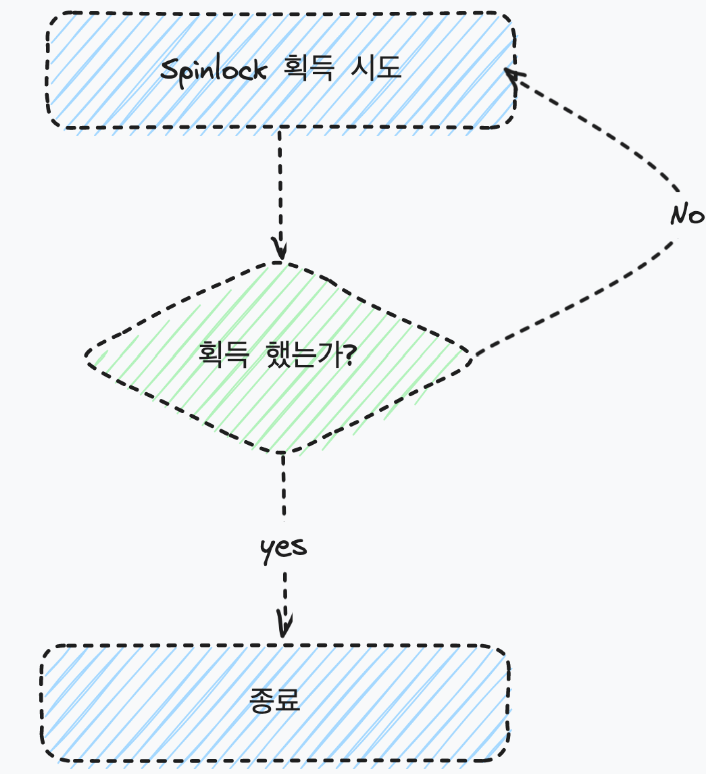
스핀락은 대기 중인 스레드가 공유 자원의 상태를 무한 루프를 이용해 확인하는 방식이다.
그래서, 공유자원에 락이 걸려있지 않은 상태에서 스레드 1이 공유자원에 접근하면, Lock을 걸고
그 상태에서 스레드 2가 해당 공유자원에 접근할때 while문을 돌면서 스레드 1이 Lock을 풀때까지, 확인을 하면서 대기하는 것이다.
while문을 돌면서 계속 확인하기 때문에, time out interrupt가 발생하지 않는 이상 스레드가 대기 상태에 들어가지 않기 때문에, 해당 스레드에 대한 Context switching이 일어나지 않는다.
고로, 문맥 교환에 필요한 CPU의 오버헤드를 줄일 수 있다. 또한 무한 루프 속에서 반복해서 락을 확인하므로 락 획득이 빠르다.
다만, 락을 획득할때까지 무한 루프를 도므로, CPU를 많이 잡아 먹는다는 단점이 있다.
구현
Spring에서 Redis를 사용하기 위해서 의존성을 추가한다. 이때 Default로 Lettuce 라이브러리를 사용하게 된다.
implementation("org.springframework.boot:spring-boot-starter-data-redis")@Component
public class RedisLikeRepository {
private final RedisTemplate<String, String> redisTemplate;
@Autowired
public RedisLikeRepository(RedisTemplate<String, String> redisTemplate) {
this.redisTemplate = redisTemplate;
}
public boolean lock(Long key) {
boolean isLocked = Boolean.TRUE.equals(
redisTemplate.opsForValue().setIfAbsent(
key.toString(),
"lock",
Duration.ofMillis(3000L)
)
);
if (!isLocked) {
System.out.println("Lock failed for key: " + key);
}
System.out.println(isLocked);
return isLocked;
}
public void unlock(Long key) {
redisTemplate.delete(key.toString());
}
}lock 메서드
setIfAbsent: redis의 SETNX 명령과 유사하다, 키가 존재하지 않는 경우에만 Key와 value를 설정하고, 성공 시 true를 반환, 실패시 false를 반환한다.
세 번째 매개변수로 락의 유효기간을 3초로 설정하였다. 이는 락이 너무 오래 유지되지 않도록 하기 위한 것이다.
락 성공 여부를 isLocked로 확인하고 성공시 true 실패시 false를 반환한다.
unlock메서드에서 delete명령을 수행하여서 키를 삭제하여 락을 해제한다.
@Service
public class PostLikeService {
private final StoreLikeRepository postLikeRepository;
@Autowired
public PostLikeService(StoreLikeRepository postLikeRepository) {
this.postLikeRepository = postLikeRepository;
}
@Transactional
public void increase(Long postLikeId) {
System.out.println("two");
Store postLike = postLikeRepository.findById(postLikeId)
.orElseThrow(() -> new NoSuchElementException("PostLike not found"));
postLike.increase();
}
}@Component
public class LettuceLockPostLikeFacade {
private final RedisLikeRepository redisLikeRepository;
private final PostLikeService postLikeService;
@Autowired
public LettuceLockPostLikeFacade(RedisLikeRepository redisLikeRepository, PostLikeService postLikeService) {
this.redisLikeRepository = redisLikeRepository;
this.postLikeService = postLikeService;
}
public void increase(Long postLikeId) {
try {
// lock이 성공할 때까지 반복
while (!redisLikeRepository.lock(postLikeId)) {
Thread.sleep(100);
}
// 잠금이 성공하면 좋아요 증가 로직 실행
postLikeService.increase(postLikeId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt(); // 스레드의 인터럽트 상태 복원
System.out.println(e);
} finally {
redisLikeRepository.unlock(postLikeId); // 반드시 잠금 해제
}
}
}increase메서드에서 lock이 성공할 때까지 while문을 반복한다.
lock메서드에서 false를 반환할 경우, 100ms 동안 대기후 다시 시도한다.
짧은 대기와 재시도는 서버 리소스를 소모 시킬 수 있으므로, 재시도 간격을 점진적으로 증가시키는 지수백오프 알고리즘을 적용할 수 있다.
@Test
void increase_with_100_request_to_multi_server() throws InterruptedException {
// given
int threadCount = 100;
RestTemplate restTemplate = new RestTemplate();
ExecutorService executorService = Executors.newFixedThreadPool(40);
CountDownLatch latch = new CountDownLatch(threadCount);
// when
for (int i = 0; i < threadCount; i++) {
final int ii = i;
executorService.submit(() -> {
try {
int port = (ii % 2 == 0) ? 8080 : 8081;
ResponseEntity<Void> responseEntity = restTemplate.getForEntity(
"http://localhost:" + port + "/like",
Void.class);
} finally {
latch.countDown();
}
});
}
latch.await();
}@RequiredArgsConstructor
@Controller
public class StoreController {
private final StoreService storeService;
private final OptimisticLockStoreFacade optimisticLockStoreFacade;
private final StoreFacadeService storeFacadeService;
private final LettuceLockPostLikeFacade lettuceLockPostLikeFacade;
private final RedissonLockPostLikeFacade redissonLockPostLikeFacade;
@GetMapping("/like")
public ResponseEntity<String> like(){
lettuceLockPostLikeFacade.increase(100L);
return new ResponseEntity<>("success", HttpStatus.OK);
}
}정합성 또한 맞는 것을 확인 할수 있다.
Lettuce를 활용한 분산락은 구현이 간단하지만, Spin Lock 방식은 Redis에 부하를 줄 수 있다.
Redis Redisson 라이브러리 활용하기
Redisson 라이브러리는 Pub-Sub 기반으로 Lock을 구현할 수 있다.
그러면, Pub-Sub가 도대체 뭐냐?
Publish / Subscribe는 특정한 주제(topic)에 대해 해당 topic을 구독한 구독자에게 메시지를 전부 다 발송하는 방식이다.
한명의 Client가 메시지를 Publish하게 되면, 해당 Topic과 연결된 다른 모든 Client에게 메시지가 전송된다.
Yotube 채널 구독과 비슷하다. 원하는 유튜버의 채널을 구독하면, 해당 채널이 새로운 영상을 올리면, 채널을 구독한 구독자 모두에게 새로운 영상 업로드 알림을 보내는것과 동일하다.
다만, 유의할 점이 있는데 redis의 pub/sub 시스템은 매우 단순한 구조로 되어있다.
Pub/Sub 시스템에서 채널에 구독 신청을 한 모든 subscriber에게 메시지를 전달할때, 메시지를 던지는 시스템이므로 메시지를 따로 보관하지 않는다.
즉, 수신자가 메시지를 받는 것을 보장하지도 않고, 일반 메시지 큐처럼 수신대상이 메시지를 제대로 수신하였는지 확인도 하지 않는다.
고로, 전송 보장을 하지 않는 단순한 구조이다.
그러나, 이러한 단순한 기능을 제공하니까 쓸모가 있냐라고 생각 할수 있는데 웹소켓을 이용하면 추가적인 네트워크 통신이 필요하므로 딜레이가 발생한다.
반면, 레디스는 In-Memory 기반이므로 매우 빠르게 메시지를 받을 수 있다.
따라서 현재 접속중인 Client에게 짧고 간단한 메시지를 빠르게 보내고 싶을 때, 그리고 전송된 메시지를 저장하거나 수신확인이 필요하지 않을 때, 100%전송을 보장하지 않아도 되는 데이터를 보낼때 해당 기능을 사용하면 좋다.
https://inpa.tistory.com/entry/REDIS-%F0%9F%93%9A-PUBSUB-%EA%B8%B0%EB%8A%A5-%EC%86%8C%EA%B0%9C-%EC%B1%84%ED%8C%85-%EA%B5%AC%EB%8F%85-%EC%95%8C%EB%A6%BC
pub - sub에 대한 실슴은 해당 블로그에서 잘 써놓은것 같다 참고해보자.
구현
implementation("org.redisson:redisson-spring-boot-starter:3.23.4")Spring에서 Redisson을 사용하기 위해서 redisson-spring-boot-starter의존성을 넣어준다.
@Component
public class RedissonLockPostLikeFacade {
private final RedissonClient redissonClient;
private final PostLikeService postLikeService;
public RedissonLockPostLikeFacade(RedissonClient redissonClient, PostLikeService postLikeService) {
this.redissonClient = redissonClient;
this.postLikeService = postLikeService;
}
public void increase(Long postId) {
RLock lock = redissonClient.getLock(postId.toString());
try {
// 락을 시도하고 10초 동안 대기, 락을 획득하면 1초 후에 자동 해제됨
boolean available = lock.tryLock(10, 1, TimeUnit.SECONDS);
if (!available) {
System.out.println("Lock 획득 실패");
return;
}
// 락을 획득했다면 좋아요 증가 작업 수행
postLikeService.increase(postId);
} catch (InterruptedException e) {
Thread.currentThread().interrupt(); // 스레드 인터럽트 상태 복원
System.out.println("인터럽트 발생: " + e.getMessage());
} finally {
// 락을 해제
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}로직은 매우 간단합니다. redissonClient를 사용하여서 특정 키를 기반으로 락 객체를 생성합니다.
여기서는 상점 Id로 100을 넘겨주니까 100이라는 키를 기반으로 락 객체가 생성됩니다.
lock.tryLock메서드를 통해서 락을 획득하려고 시도합니다.
락을 획득할 때까지 최대 10초 동안 대기, 락을 획득하면 1초 후에 자동해제합니다.
이렇게 타임아웃을 설정하여서 데드락을 방지합니다. 혹여나 락이 해제되지 않더라도 자동으로 해제되기 때문에 다른 스레드에서 락을 획득할 수 있기 때문입니다.
락을 해제 할때는 isHeldByCurrentTread()로 락의 소유권을 확인하고 해제합니다. 이는 다른 스레드의 락을 잘못 해제하는 상황을 방지하기 위함입니다.
여기서 어디서 Pub-Sub가 사용되었냐 하면, redisson은 redis의 pub/sub시스템을 이용합니다. 락이 해제될 때마다, subscribe중인 클라이언트에게 락 획득을 시도해도 된다라는 메시지를 보냅니다.
고로, 이전에 스핀락은 락 획득 실패시 다시 while문을 재진입하며 락 획득을 다시 시도하는데 이는 레디스에게 계속 요청을 보내므로 부담을 주게 됩니다.
그러나, 지금은 redis가 락 획득을 시도해도 된다는 메시지를 보내므로, 락 획득에 실패할 때마다 일일이 레디스에 요청을 보내는 과정이 사라지는 것이다.
@RequiredArgsConstructor
@Controller
public class StoreController {
private final StoreService storeService;
private final OptimisticLockStoreFacade optimisticLockStoreFacade;
private final StoreFacadeService storeFacadeService;
private final LettuceLockPostLikeFacade lettuceLockPostLikeFacade;
private final RedissonLockPostLikeFacade redissonLockPostLikeFacade;
@GetMapping("/like")
public ResponseEntity<String> like(){
redissonLockPostLikeFacade.increase(100L);
return new ResponseEntity<>("success", HttpStatus.OK);
}
}정상적으로 동시성이 제어 된것을 볼 수 있습니다.
Redisson을 활용한 분산락은 메시지가 올때만 Lock을 획득하려는 장점이 있지만, 별도의 라이브러리를 사용해야 한다는 단점이 있습니다.
내 생각
그렇다면, Redis를 쓰는게 좋은가 아니면, MySql에 직접 락을 거는게 좋은가? 이런 생각이 들었다.
소규모 프로젝트나, RDB만 사용하고 있다면, Redis를 이용한 분산락은 인프라 구축에 대한 비용 + 유지보수 비용을 감당해야한다.
고로 이런 경우는 차라리 그냥 NameLock을 사용하는게 좋을 것 같다.(만약 MYSQL을 사용하고 있다면)
하지만 이미 Redis를 사용중이라면, in-memory 캐싱, pub/sub시스템등 Redis가 가지고 있는 장점을 활용할 수 있는 상태, 즉 이미 Redis를 쓰고 있다면 그냥 라이브러리르 가져다 쓰는게 좋은거 같다.
근데 또, 여기서 Lettuce를 쓸건지 Redisson을 쓸건지 약간 고민이 될 수 있을 것같다.
Lettuce는 아까 위에처럼 SpinLockd를 사용하니까 redis에 부하가 많이 올꺼 같고, Redisson 라이브러리는 메시지가 오면 Lock을 요청하니까 부하는 적은데 이게, Lettuce는 레디스 인스턴스에 커넥션만 되면 바로 명령어를 요청할 수 있는데, Redisson은 Bucket,Map,RLock과 같은 구현체만을 제공하므로 DataType에 맞는 메소드를 선택해야한다.
예를 들어 레디스에 SET 명령을 요청하면 getBucket()을 써야하고, LPUSH명령을 요청하면 getDeque()나 getList()를 써야한다. 그러므로 이 학습비용이 커진다는 단점이 있다.
느낀점
1,2,3편의 글을 쓰면서
-
성능향상을 위한 Cache 시스템 도입
-
Cache 시스템중 redis, memcache 차이점
-
동시성제어 - 단일 인스턴스
-
Test Code에서 @Transaction
-
트랜잭션 전파
-
동시성 제어 - 다중 인스턴스
등으로, 생각의 꼬리를 물고 거의 1달동안 공부를 했던것 같다.
