커넥션 풀이란?
클라이언트가 요청을 보낼때 마다 데이터베이스 커넥션을 맺으면 매우 비효율적일 것이다.
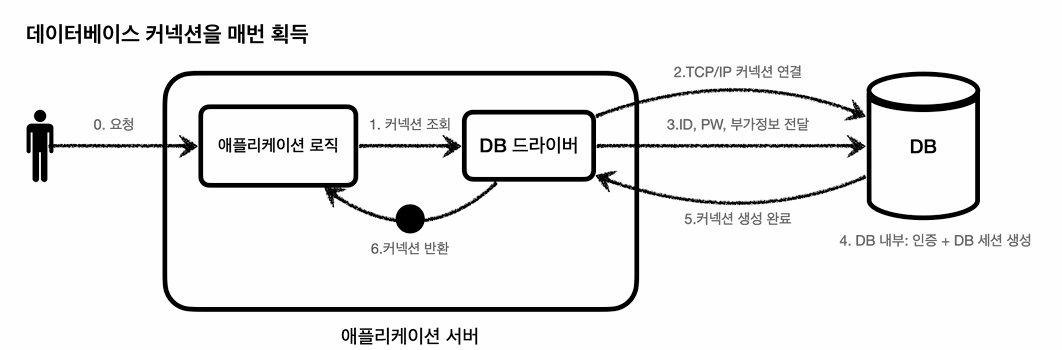
TCP/IP 커넥션을 생성하기위해서 리소스를 매번 사용하는것은 매우 비효율적.
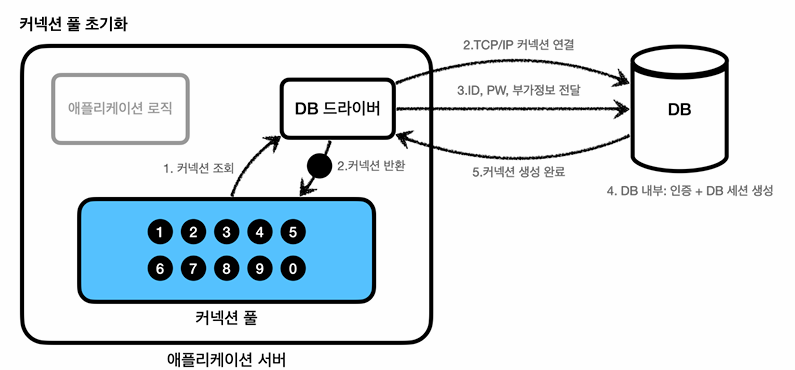
그래서 이 문제를 해결하기 위해서 커넥션을 미리 생성해두고 사용하는 커넥션 풀이라는 방식이다.
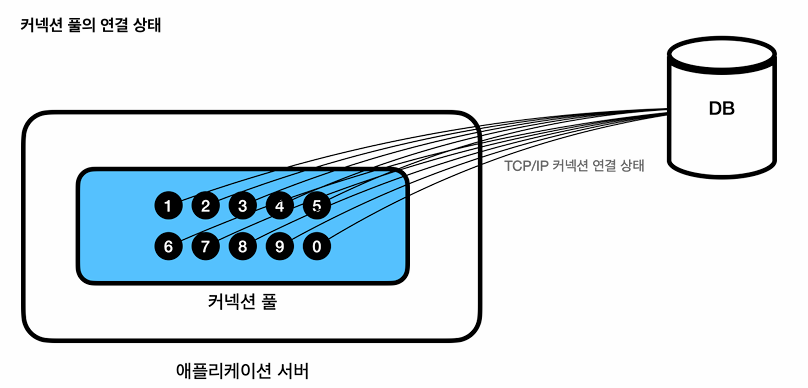
커넥션 풀에 있는 커넥션은 TCP/IP로 DB와 연결되어 있으므로 즉시 SQL을 DB에 전달 가능하다.
사용방법:
커넥션을 조회 -> 이미 생성되어 있는 커넥션을 객체 참조로 가져다 쓰면 됨 -> 쓰고나서 커넥션 풀에 반납(종료 X)
스프링 부트에서는 기본적으로 커넥션 풀을 hikariCP를 사용한다.
DataSource란?
그렇다면 DataSource란 무엇일까?
내가 커넥션을 얻을때 Drivermanager을 쓴다고 해보자, 이전에 Connection con = getConnection(URL,USERNAME,PASSOWRD)으로 커넥션을 얻었다.
어플리케이션이 직접 Drivermanager를 바라고보있다면, Drivermanager에서 hikariCP로 바꾸면 이 어필리케이션 로직을 직접 다 바꿔야할것이다.
그래서 커넥션을 획득하는 방법을 추상화하였다.
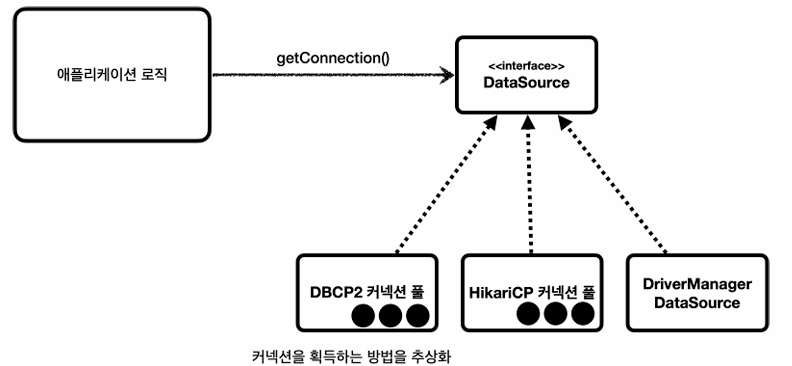
개발자는 DriverManagerDataSource, HikariCP의 코드를 직접 의존하는게 아니라, DataSource 인터페이스에만 의존
-> 커넥션 풀 구현기술을 변경하고싶으면 해당 구현체로 바꾸기만 하면된다.
참고: 왜 DrivermanagerDataSource 사용하는가? DriverManager는 DataSource인터페이스를 사용하지 않으므로, 스프링이 DriverManager도 DataSource를 통해서 사용할 수 있도록 DrivermanagerDataSource제공
실제 인터페이스 맛보기
일단 DrivermanagerDataSource를 사용해보자.
이전에 Drivermanager를 직접 사용할때는
Connection connection =DriverManager.getConnection(URL,USERNAME,PASSWORD);
커넥션을 획득할때마다, 리소스를 같이 넘겨줬는데,
TestCode
@Test
void dataSourceDriverManager() throws SQLException {
DriverManagerDataSource dataSource = new DriverManagerDataSource(URL,USERNAME,PASSWORD);
useDataSource(dataSource);
}
private void useDataSource(DataSource dataSource) throws SQLException {
Connection connection1 = dataSource.getConnection();
Connection connection2 = dataSource.getConnection();
log.info("connection={},class={}",connection1,connection1.getClass());
log.info("connection={},class={}",connection2,connection2.getClass());
}처음에 DriverManagerDataSource를 생성할때만 리소스를 넘겨주고, DriverManagerDataSource를 인자로 넘겨줄때, useDataSource메서드에서 DataSource(★인터페이스★)로 받는다.
그러면 커넥션을 가져올때는 리소스에 대해서 전혀 몰라도 된다.
dataSource.getConnection();
중요한것은 어플리케이션이 인터페이스에 의존하여서 설정(DataSource구현체에다가 필요한 속성 URL,USERNAME,PASSWORD를 설정)과 사용(설정 신경 x 인터페이스의 getConnection()만 호출)을 분리 시켰다는점이다.
커넥션풀 사용
@Test
void dataSourceConnectionPool() throws SQLException {
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(URL);
dataSource.setUsername(USERNAME);
dataSource.setPassword(PASSWORD);
dataSource.setMaximumPoolSize(10);
dataSource.setPoolName("MyPool");
useDataSource(dataSource);
}우리는 인터페이스에 의존하고 있기 때문에 그냥 해당 HikariDataSource객체를 만들어서 넘겨주기만하면, 인터페이스에서 getconnection()으로 커넥션을 얻는다. 전혀 설정정보들을 몰라도 된다.
만약 10개 PoolSize를 넘는 connection요청이 들어오면 -> 요청이 Blocked되고 얼마나 더 기다릴껀지 설정 정보에 따라서 기다렸다가 오류 발생 고로, 해당 MaximumPool과 기다리는 시간 커스텀이 중요!
DataSource 적용
커넥션을 얻는 방법은 앞서 학습한 JDBC DriverManager를 직접 사용하거나, 커넥션풀을 사용하는등 다양한 방법이 존재한다.
@Slf4j
public class MemberRepositoryV1 {
private final DataSource dataSource;
public MemberRepositoryV1(DataSource dataSource) {
this.dataSource = dataSource;
}
...private void close(Connection con, Statement stmt, ResultSet rs) {
JdbcUtils.closeResultSet(rs);
JdbcUtils.closeStatement(stmt);
JdbcUtils.closeConnection(con);
}private Connection getConnection() throws SQLException {
Connection con = dataSource.getConnection();
log.info("get Connection = {}, class = {}",con,con.getClass());
return con;
}- DataSource를 사용할때는 의존관계주입시에 인터페이스로 받는것이 중요하다.
- close메서드에서는 이제 우리가 직접 try catch를 작성하는것이아닌, JdbUtils에서 구현해놓은 close메서드를 사용한다.
- getConnection메서드에서는 dataSource의 getConnection메서드를 호출한다. 그러면 각 구현체에 해당하는 오버라이드된 getConnection이 호출된다.
@Slf4j
class MemberRepositoryV1Test {
MemberRepositoryV1 repository;
@BeforeEach
void beforeEach(){
//Driver Manager사용
//DriverManagerDataSource dataSource = new DriverManagerDataSource(URL,USERNAME,PASSWORD);
//히카리사용
HikariDataSource dataSource = new HikariDataSource();
dataSource.setJdbcUrl(URL);
dataSource.setPassword(PASSWORD);
dataSource.setUsername(USERNAME);
repository = new MemberRepositoryV1(dataSource);
}
...히카리를 사용하던 DriverManagerDataSource를 사용하던 상관없다.
만든 다음에 repository생성자 주입할때 구현체를 넘겨줌
->생성자 주입에서 인터페이스로 받기 때문에,
->구현체가 어떤것으로 바뀌더라도 애플리케이션 로직부분을 바꿀 이유가 없다.
이것이 DataSource를 사용하는 장점이다.
