[generation][23.4][85] Trace and Pace: Controllable Pedestrian Animation via Guided Trajectory Diffusion
realistic traffic agent modeling
목록 보기
5/6
0. 바쁘신 분들을 위한 3줄 요약
- TRACE는 diffusion기반 보행자 궤적 생성기 (2초마다 planning) 이고, PACER은 이를 입력으로 받아 물리법칙 기반 휴머노이드를 제어하는 RL 기반 제어기 (주기적 동작)
- TRACE는 classifier-free sampling을 통해 주변 semantic map에 얼마나 의존한 궤적을 만들지 조절할 수 있으면서도, test-time guidance를 (clean trajectory)에 적용하여 사용자 요청 controllable 궤적도 생성 가능하다.
- PACER은 다양한 humanoid model, 다양한 지형(계단, slope 등)을 고려하여 사람을 RL 제어하며, 학습 시 얻은 value function을 이용해서 TRACE를 guide 할 수 있다. (속도가 느릴것 같은데 꼭 필요한진 의문)
1. Introduction

- 기존 학습 기반 궤적 생성 연구에서, controllability를 달성하기 위해,
latent space 탐색(traversal) 접근을 사용- [49]에서 언급된 방법처럼, VAE 같은 확률적 모델에서 잠재 변수를 입력하면 모델이 궤적을 생성합니다.
- 제어를 위해서는, 목표(예: 장애물과 충돌 최소화, 특정 지점 도달 등)를 만족하도록 ‘잠재 변수’를 조정(탐색, optimization)해야 합니다.
- 이 과정이 고차원 공간에서의 최적화가 될 수 있는데, 일반적으로 “비용이 큰(= 계산량이 많거나 복잡도가 높은)” 방식으로 진행됩니다.
- 왜냐하면,
- 잠재 공간은 보통 고차원이고, 모델의 forward/backward를 반복적으로 수행해야 하며,
- 추가적인 손실 함수를 설정(예: 충돌 회피)해놓고 이를 역전파로 미분하면서 잠재 벡터를 계속 수정해야 하기 때문입니다.
- 즉, 원하는 제어를 위해서는, 특정 조건마다 추가 학습 과정이 계속 필요합니다.
- 결과적으로 실시간/상호작용적인 제어가 쉽지 않으며, 제어가 가능하더라도 매우 비효율적일 수 있습니다.
- 키네마틱(kinematic) 방식의 애니메이션 기법들 [21, 30, 46]
- 구현이 간단하고 효율적
- 실시간 성능이 좋음
- 단점: 지형에 따른 움직임 반영이 어려움
- 기존 물리 기반(physics-based) 방식 [13, 30, 43-45, 65]
- 더 자연스러운 움직임(예:
지형의 영향, 충돌 시 반응, 다양한 이동 속도나 궤적 변화 시 미묘한 동작 변형 등)을 실시간으로 반영할 수 있다는 강력한 장점이 있다. - 문제는, 물리 기반 애니메이션 모델을 “제어”하려면(즉, “이런 임무를 해”, “이 지형 위에서 움직여”, “이 체형을 가진 캐릭터를 움직여” 등),
- 각 task나 지형·캐릭터 타입마다 플래너(planner)를 새로 짜고 재학습해야 한다.
- 즉, “확장성”이나 “재활용성”이 떨어진다.
- 더 자연스러운 움직임(예:
- 논문에서는,
task, 지형, 캐릭터 종류가 바뀌어도 하나의 PACER 제어기로 대응할 수 있게 학습하였다.
2. Related work
2.1. Diffusion models and guidance
- CTG 논문과 비교했을 떄, 본 연구의 장점?
- Diffusion으로 궤적을 생성할 때, ‘환경 지도를’ 피처 그리드 형태로 인코딩해두고, denoising 단계마다 (x,y)에 해당하는 피처를 찾아 쓰는 방식으로 지도 정보를 활용한다.
- 즉, 점진적으로 노이즈를 걷어낼 때마다, 현재 궤적 상 각 프레임의 (x, y)가 맵의 어느 위치인지 확인하고, 해당 위치의 피처가 궤적 생성에 반영됩니다.
- 우리는 classifier-free sampling을 통해, 시멘틱 맵 라벨이 없는 데이터셋에서도 학습할 수 있습니다.
- 우리는 test-time guidance 를 clean model output에서 수행합니다.
- 우리는 PACER에서 학습한 value-function을 이용해서, TRACE를 가이드 함으로써, terrian을 고려한 궤적을 생성할 수 있습니다.
- Diffusion으로 궤적을 생성할 때, ‘환경 지도를’ 피처 그리드 형태로 인코딩해두고, denoising 단계마다 (x,y)에 해당하는 피처를 찾아 쓰는 방식으로 지도 정보를 활용한다.
3. Method
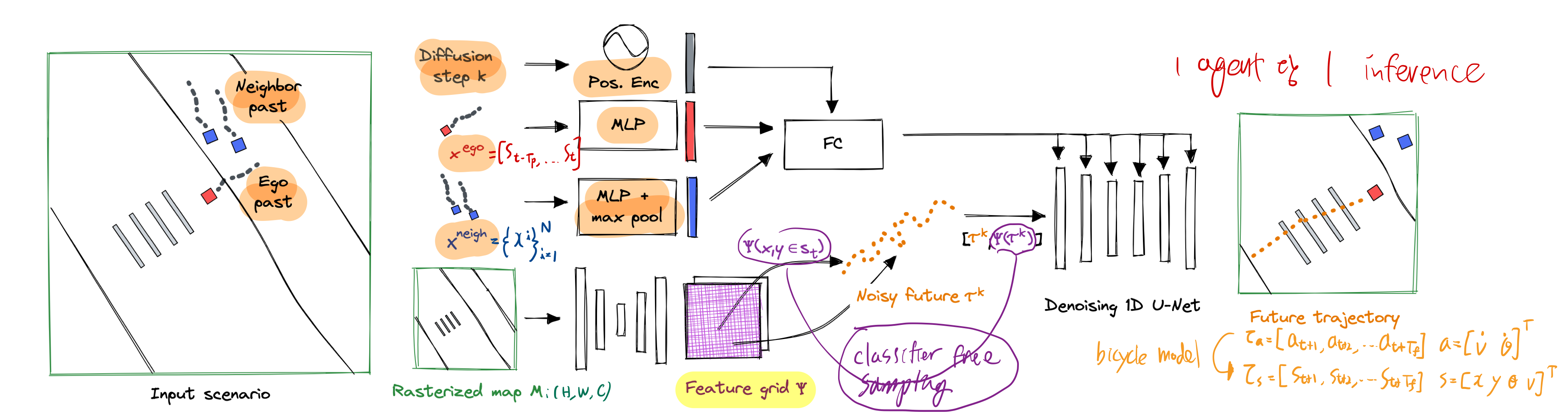
3.1. TRACE
- trajectory diffusion model for 사람 (high level planner)
- output trajectory를 PACER에게 전달합니다.
trajectory diffusion model
Training and Classifier-free Sampling
- DDPM + DDIM 스타일의 접근법을 취함
- (2)
- 식 (2)의 분산은 학습하지 않고, fixed schedule를 활용 (DDPM 처럼)
- DDIM 처럼, 매 denoising step마다
final clean trajectory생성- 이를 활용해서 를 계산합니다. (DDIM처럼)
- 이를 활용해서, loss function을 매 step 계산합니다. (TODO: 이게 수학적으로 올바른지는 모르겠음. 보통은 noise를 맞추는 식으로 학습하던데...)
- (3)
classifier-free sampling- TRACE 학습 시, semantic map 을 포함()하거나, 하지 않거나() 번갈아가면서 학습
- test time에서는 아래 수식을 이용하여 생성
- (4)
- 는 input을 생성하기 위해, clean trajectory에서 얼마나 많은 noise를 추가했는지 예측한 값
- : semantic map을 더 많이 고려, 다양성 감소 (: purely conditional)
- : semantic map을 덜 고려, 다양성 증가 (: purely unconditional)
- 장점
- inference 시,
다양한 궤적을 생성<->주변 환경을 고려한 궤적 생성의 정도를 조절할 수 있음! - 여러 데이터셋을 이용해서 학습이 가능해짐! (semantic map 정보가 없는 데이터셋에 관해서도 사용가능!)
- inference 시,
Controllability through Clean Guidance
-
Test-time guidance- test-time에, 사용자가 원하는대로 guidance를 줄 수 있음
- 목표 속도 / 목적지 / 충돌 회피 / social groups
- loss function으로
- 학습된 것을 쓸 수 도 있지만,
- 우리는
analytical loss fuctions를 도입해서 test-time에 guidance 적용
- test-time에, 사용자가 원하는대로 guidance를 줄 수 있음
-
(2)
-
-
과거 연구에서는 아래 식을 사용해였고, noisy mean에서 cost function 를 평가하였습니다.
- 이 방식은, 다양한 noise level에서 loss function이 학습되어야 한다는 단점
- numerical 불안전성의 단점
- (5)
-
논문에서는 대신, clean model prediction 위에서 임의의 loss function을 평가합니다.
-
매 denoising step 에서, 네트워크로부터 clean trajectory()를 예측한 후, 거기에 guidance를 아래와 같이적용
-
(6)
-
그리고 위 를 이용해서, 매 denosing step의 평균 를 구합니다.
-

3.2. Physics-Based Pedestrian Animation
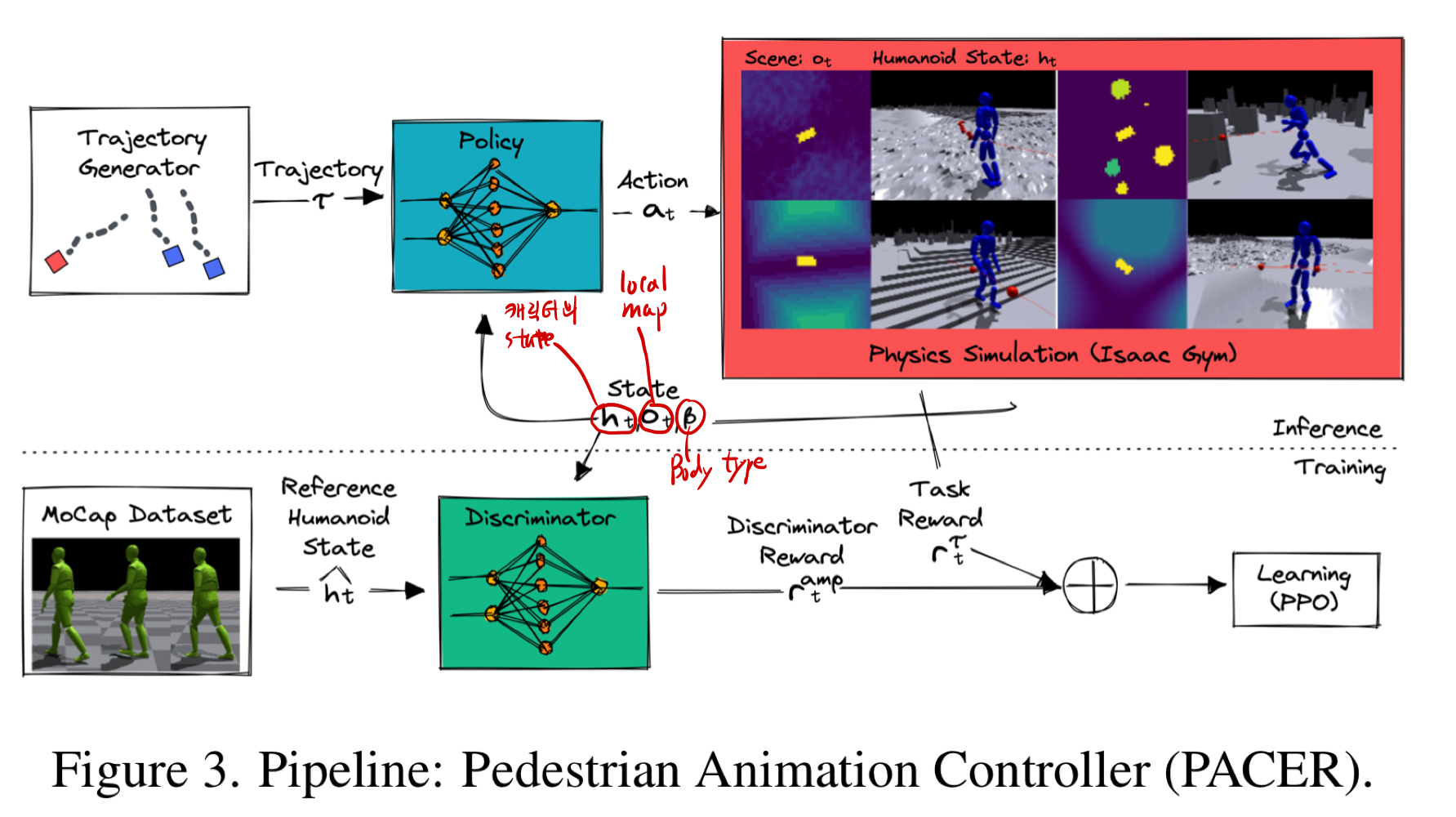
- PACER = Pedestrian Animation ControllER
- physics-based (full-body)humanoid controller (RL based)
- 2D waypoints를 입력으로 받아서, 휴머노이드를 제어합니다. (policy 학습, PPO 썻다고 함)
- 캐릭터의 관절 제어 값을 출력하는 것임
- 우리는
kinematic structure of SMPL[31] 이라는 humanoid model을 사용했음- [68] 과 같은 과정을 통해 자동적으로 생성된다고 함
- 다양한 지형(예: 계단) 에서 trajectory를 따라가도록, 사람(다양한 body types)을 학습시킵니다.
- realistic 3D scenes은 아래의 것들로 생성 가능
- scans, neural reconstructions, artist-created meshes
- 지형과 social-awareness를 고려함

realistic Motion through Adversarial Learning
- motion quality 향상
- 자연스럽고 현실적인 움직임 생성을 위해, adversarial motion learning을 기반으로 적은 데이터셋에서 학습했습니다.
- 이 모션 데이터는 사람이 걷고 뛰는 등의 짧은 클립을 녹화한 뒤, 관절(힙, 무릎, 발목, 상체 등)의 움직임으로 만든 것입니다.
- 이 데이터가 보행 스타일, 보폭, 상하체 동작 등을 반영하는 ‘참고’ 역할을 합니다.
- Adversarial(적대적) 학습 기법
- 흔히 GAN의 아이디어와 유사하게 ‘판별자(Discriminator)()’를 두어 ‘진짜 사람다운 동작인가’를 분별하게 만드는 방식
- 이전 연구인 AMP(Adversarial Motion Prior)[45] 기법 등을 인용
- 정책(Policy): 캐릭터가 걸어가도록 관절을 제어하는 신경망(= PACER)
- 판별자(Discriminator): 현재 캐릭터 동작이 “모션 캡처 데이터(사람 실제 동작)”와 얼마나 유사한지 판별하는 모델. (motion style reward 생성)
- 자연스럽고 현실적인 움직임 생성을 위해, adversarial motion learning을 기반으로 적은 데이터셋에서 학습했습니다.
- : trajectory following reward
- : energy penalty
- (7)

- 캐릭터 형태는 AMASS dataset으로부터 (성별과 body type을 sampling함으로써) 가져옵니다.
- policy와 discriminator은 SMPL 성별과 body shape 에 conditioned 됩니다.
3.3. Controllable Pedestrian Animation System
- TRACE+PACER 사용법
- 사용자가 목표 waypoints나 social group 같은걸 요구하면,
- 시스템은 physics based full body human motion을 생성함
- TRACE는 2초 마다 re-planning하고, PACER은 이를 따라갑니다.
Value Function as Guidance
- inference 시,
- PACER에서 RL training시 학습완료한 value function을 이용해서, TRACE sampling시 guidance를 주어
- -> 다양한 지형(계단, slope, 평평하지 않은 땅) / body pose 등을 고려한 trajectory sampling을 생성할 수 있도록 합니다.
- 결과적으로 현재 지형에 맞는 따라가기 쉬운 trajectory를 sampling할 수 있다.
- 우리는 매 step clean trajectory를 이용해서 guidance를 수행하기 떄문에, value function guide 도 쓸 수 있는 것이다.
5. 한계점
- diffusion network 속도 느림
- diffusion model distillation [38] 같은거 써봐라.
- PACER을 그냥 direct하게 diffusion으로 학습시키고, TRACE을 버리는 방향도 좋다.

ad_official