Scenario Dreamer: Vectorized Latent Diffusion for Generating Driving Simulation Environments
realistic traffic agent modeling
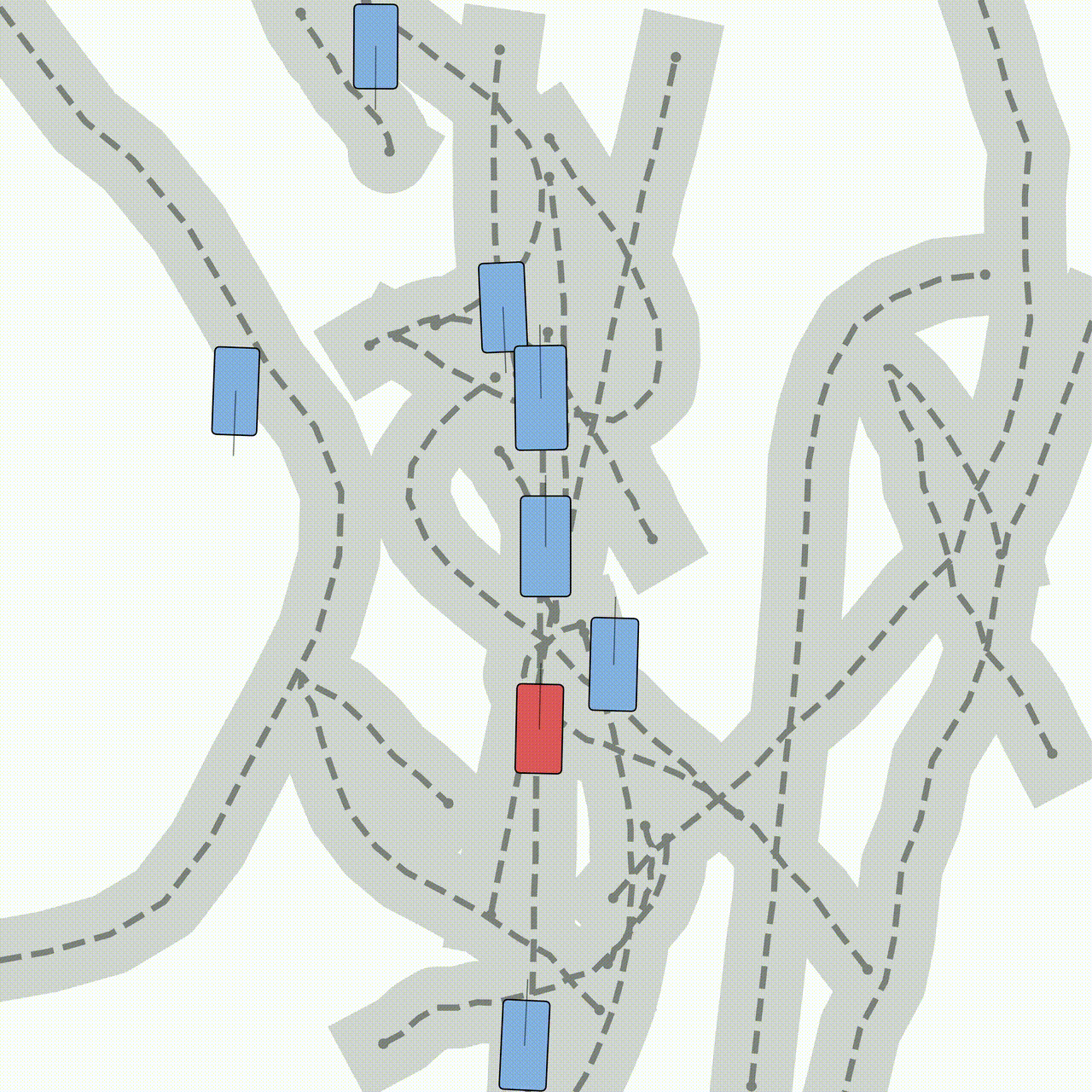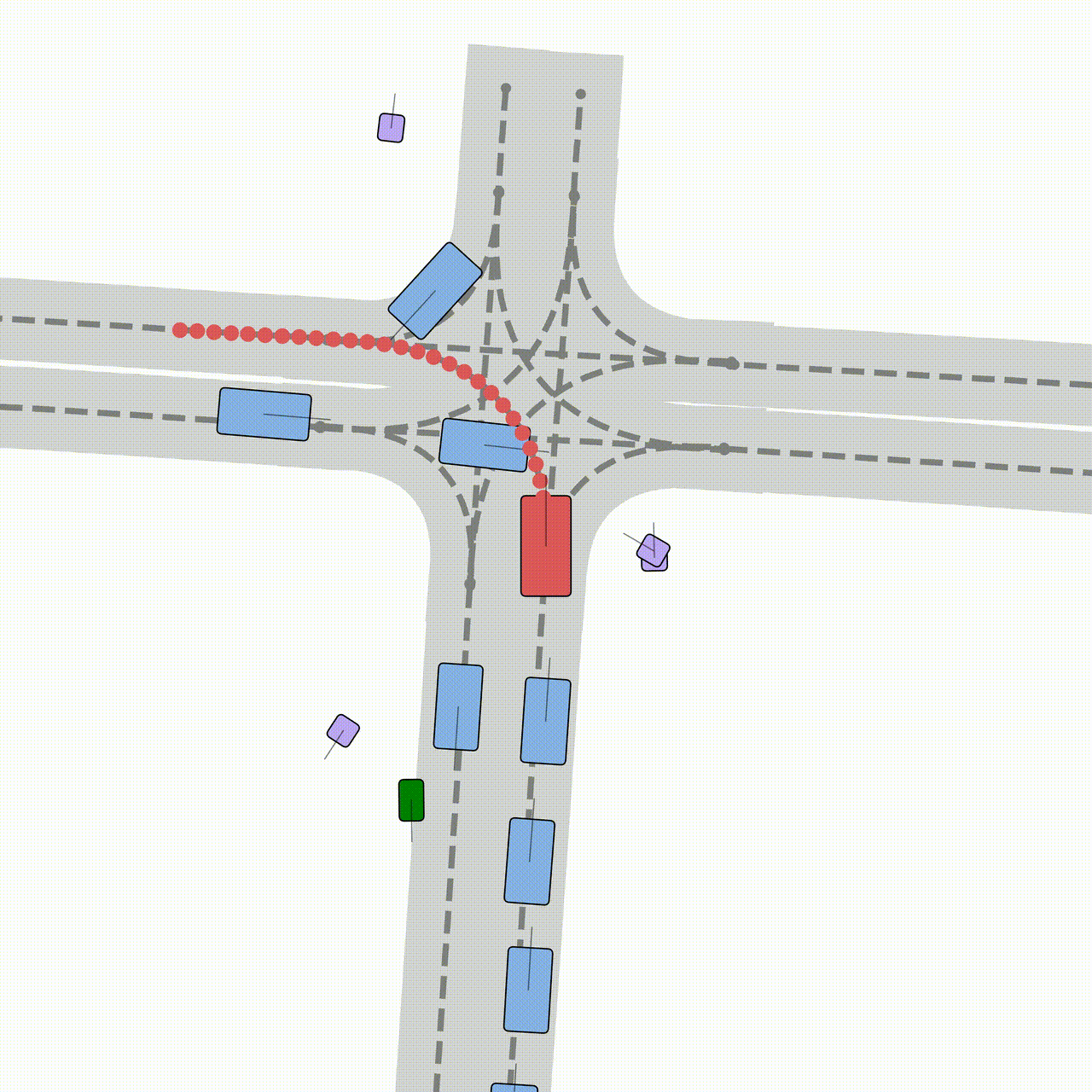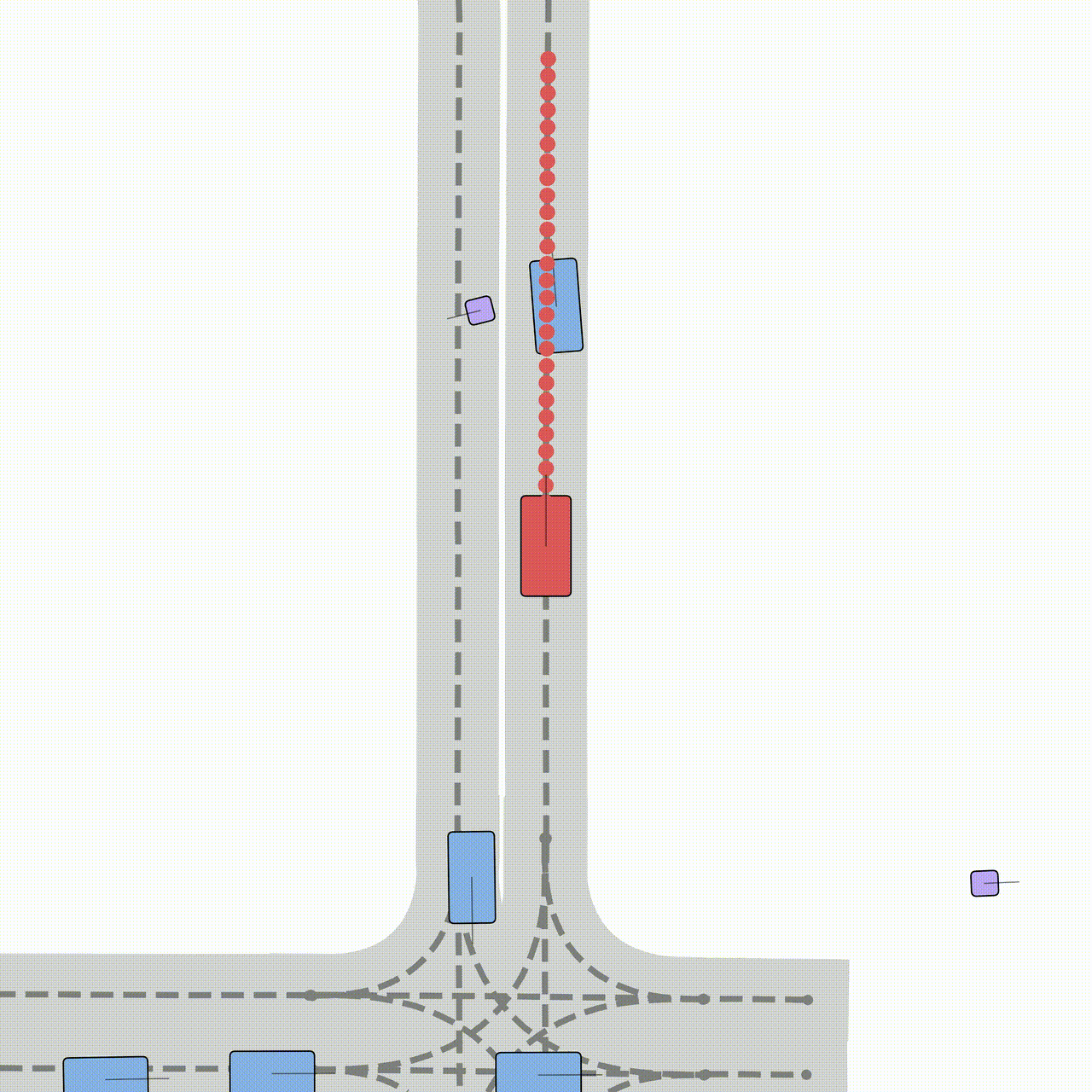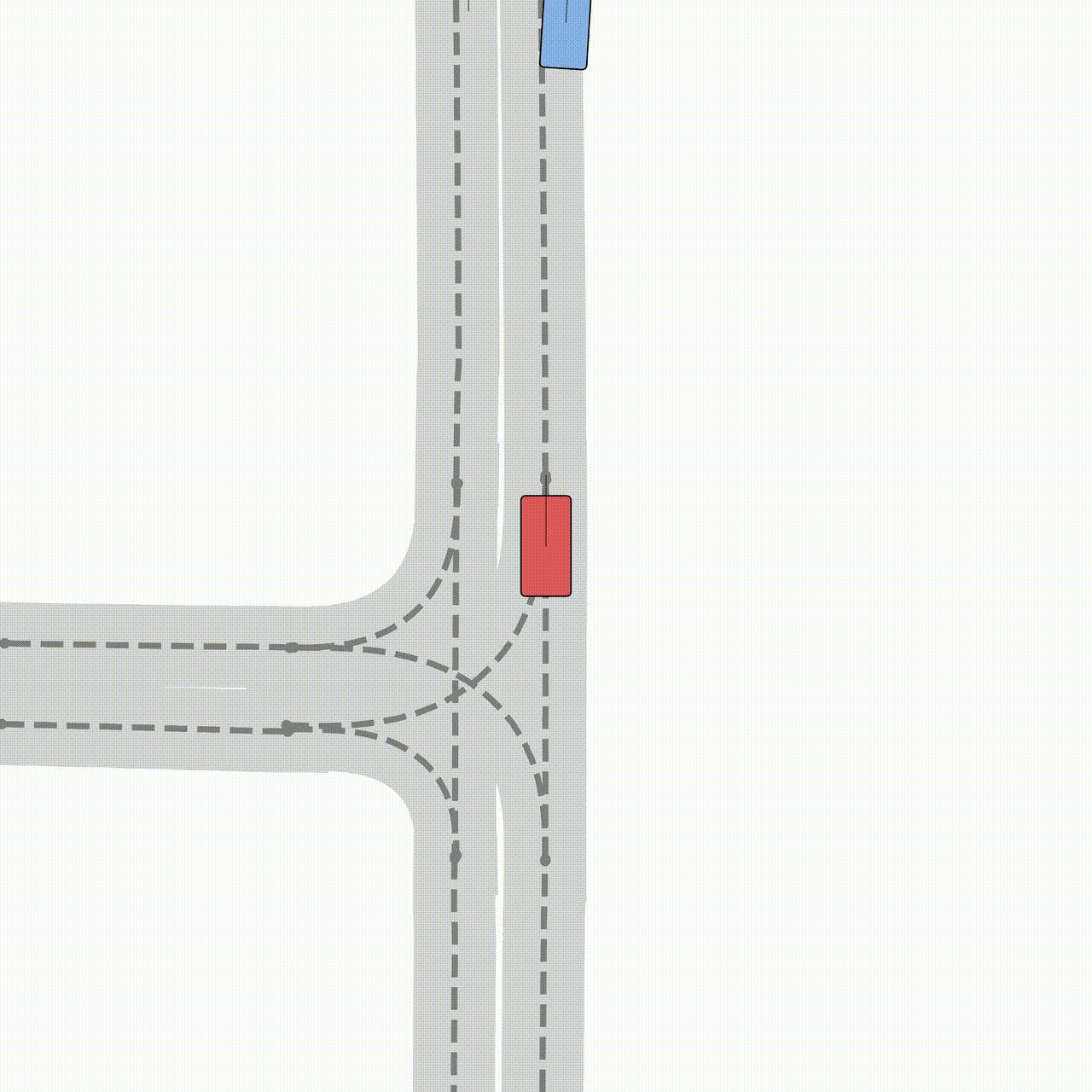
scene initialization
- scene initialization
- 자율주행 시뮬레이션을 돌릴 때, 제일 처음 시작하는 환경 구성
- 도로: 도로 차선 갯수, 모양, 차선 간 연결 관계 등
- agent
- 차량/사람/자전거/정적 장애물 등의 초기 상태
- 여기서 초기상태는, 위치/속도/방향/차 크기/종류 를 의미
scene initialization을 왜 difssuion 으로 풀어야 하는데?
- 기존 시뮬레이터(carla, waymax, metadrive 등)에서는
- 규칙 기반으로, 도로 모양을 만듦(단순하게 직선 차선/원 호 곡률 차선의 랜덤한 조합)
- 규칙 기반으로, agents를 배치함
- scene initialization이 실제 세상과 최대한 유사해야, 시뮬레이션을 돌리는 의미가 더 커짐
- 아래 사진처럼, 도로 모양(좌회전, 횡단보도)과 목표 속도에 따른 미묘한 차량간 위치 배치는 규칙 기반으로 초기화하기 어려움

- 생성 모델(diffusion)은
- 실제 차량 데이터셋의 확률 분포를 학습하면서도,
- 데이터셋에는 없었지만, 실제 세상과 유사한 다양한 결과를 생성해내는 능력
- 즉, 현실적이면서도, 데이터셋보다 훨씬 다양한 시나리오를 만들어낼 수 있게 됩니다.
latent diffusion model을 쓰는 이유?
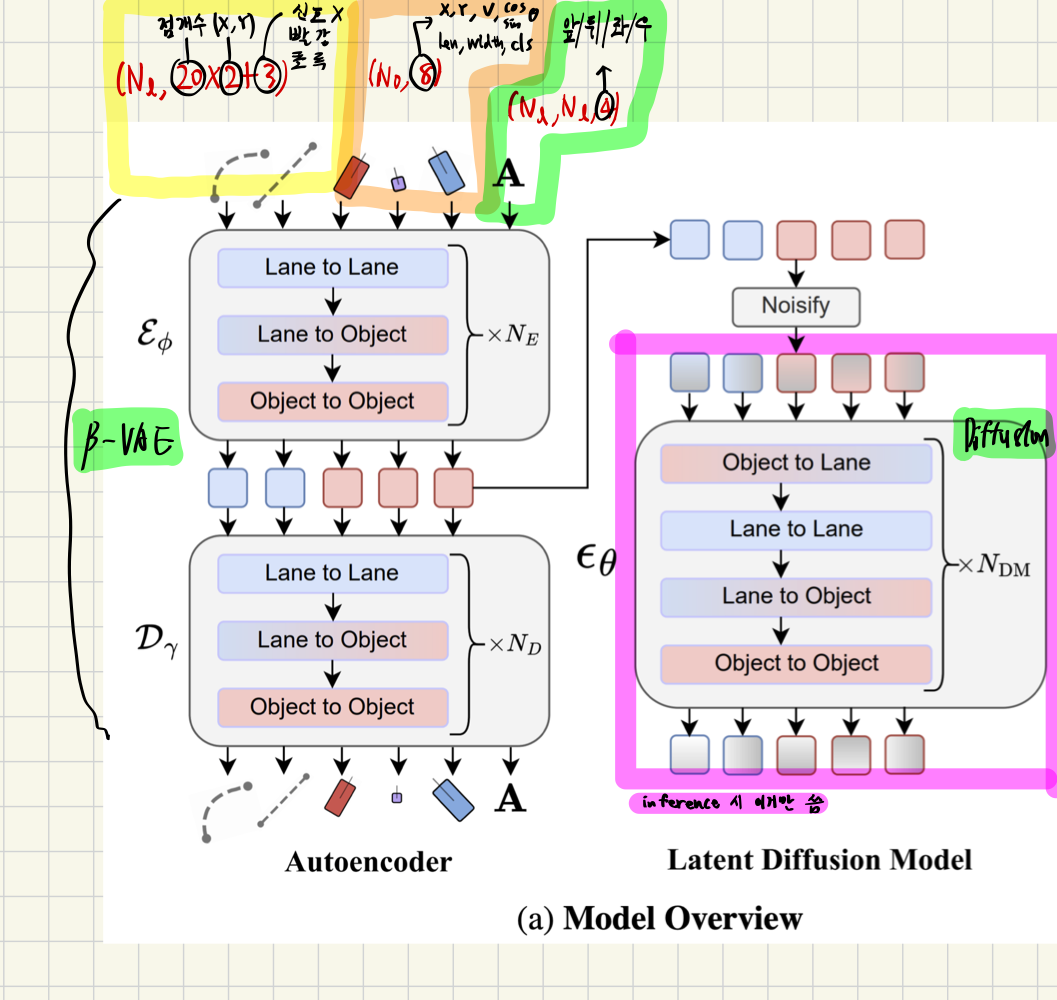
- 그냥 diffusion model을 쓰는 경우와 동일한 성능을 유지하면서도
- 학습시 학습 비용(적은 학습 파라미터 수, 더 빠른 학습) 달성 가능
- inference시 더 경량화되고 더 빠른 추론 속도 달성 가능
그럼 왜 베타-VAE? autoencoder로 충분하지 않아?
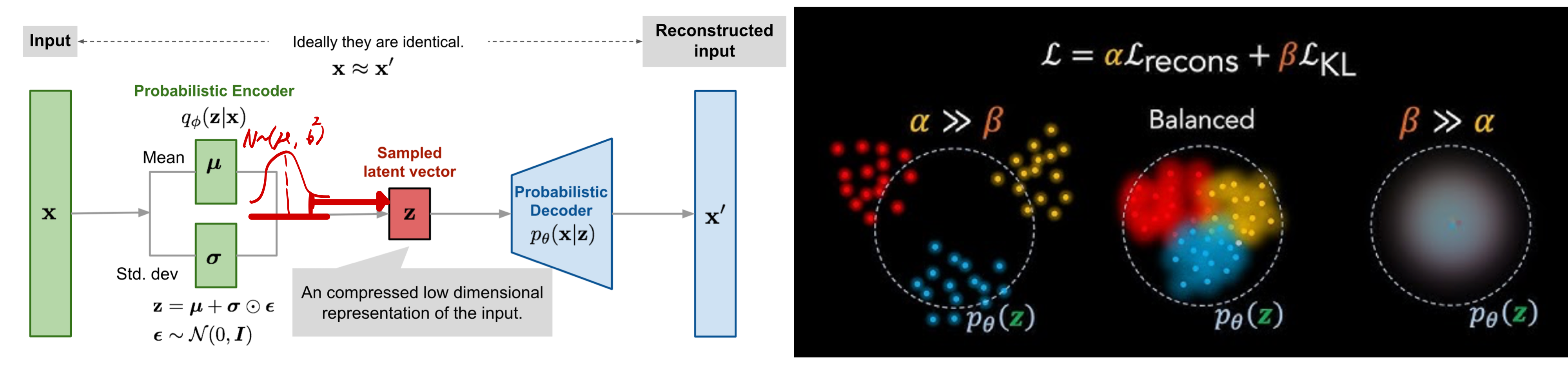
- 왜 VAE?
- autoencoder에 비해서 VAE는, latent space를 guassian distribution에 투영시켜준다.
- diffusion model은 normal guassian dist에서 출발하여 -> 데이터를 복원 하는 테스크
- diffusion은 normal guassian dist에서 출발하여 -> guassian distribution 으로 복원하는게 훨씬 학습하기 쉬움
- 훈련 시간이 단축되고, 더 적은 파라미터로도 같은 높은 성능을 낼 수 있게 됨
- diffusion은 normal guassian dist에서 출발하여 -> guassian distribution 으로 복원하는게 훨씬 학습하기 쉬움
- 왜 베타 VAE?
- 베타를 통해, KL divergence loss 의 weight를 조절 가능
- 베타가 작아질수록
- 복원 화질을 높이면서도
- latent space를 깔끔하게 구획 가능 (속성별로 독립적 조작이 가능)
- 대신, latent space의 공간이 넓어져서, diffusion Model 학습 시 비교적 오래 걸린다.
- 논문에서는 beta를 매우 낮게 설정하였다.
In-painting 맵을 무한히 확장
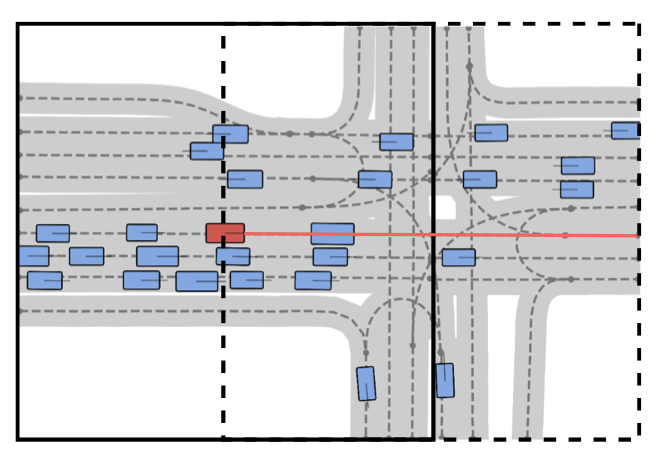
inference시
- 위 그림에서, 먼저 검은색 실선 영역에 대해 차선과 agent를 생성합니다.
- 이 때, 차선의 갯수와 agent의 갯수는 내가 임의로 설정할 수 있습니다.
- 그 후, 검은색 실선 영역의 오른쪽 절반 부분만 다시 활용합니다.
- 오른쪽 절반 부분의 차선과 agent를 latent diffusion model의 입력으로 사용합니다.
- 그리고, 미리 학습해놓은 분류기를 이용하여, 오른쪽 부분에 몇 개의 차선이 있는지를 출력해주는 네트워크를 이용해서,
- 차선에 대한 초기 random noise 벡터의 갯수를 정합니다.
- 차량 댓수는 여기서도 내가 임의로 넣어주는건가 봅니다.
- 미리 학습해놓은 분류기?
- 좌측 장면 상황을 보고 -> 우측에 몇 대의 차량과 차선이 있는지를 맞추도록 학습해 놓은 분류기입니다.
- 이제 오른쪽 절반 부분의 차선과 agent + 초기 random noise 벡터들을 input으로 하는 denoising과정을 여러 번 수행하면 됩니다.
오른쪽 절반 부분의 차선과 agent는 매번 복구해줍니다.
학습 시
- 일반 학습 루프와, in-painting 특화 학습 루프를 돌립니다.
- 왼쪽만 보고, 오른쪽의 차선 갯수를 유추하는 예측 보조 클래스도 학습합니다.
- learnable query가 lane 토큰과 cross attention 하면서 학습한다고 합니다.
behaviour simulation
- ctrl-sim이라는 논문을 기반으로 만들었다고 합니다.
- 안전 모드(천천히, 차간 거리 유지)나 도전 모드(충돌 유도)로 난이도를 바꿔가며 테스트할 수 있습니다.
- 차량이 볼 수 있는 범위(약 반경 80 m) 내에서만 계산해 효율을 높입니다.
scene initialization 정량적 평가
한 단락 요약
Scene Initialization(초기 장면 생성) 평가는 “도로 그래프 품질”과 “초기 객체(차량) 배치 품질”의 두 축으로 나뉩니다. 연구진은 Waymo Open Motion(미국 6개 도시)·nuPlan(4개 도시) 데이터셋에서 50 k개의 실제 장면과 50 k개의 모델이 생성한 장면을 뽑아, ① Lane Graph에 대해 Urban Planning Metric 4종 + Fréchet Distance (FD), ② Agent 배치에 대해 Jensen‑Shannon Divergence(JSD) 6종 + Collision Rate를 계산하였다. 모든 지표는 히스토그램 또는 가우시안 통계량을 기반으로 하며, 값을 읽기 쉽게 10~100배로 스케일링해 Table 1, 2에 정리했다. 비교 대상은 SLEDGE(DiT‑L/XL)·DriveSceneGen(Upper‑bound)으로, Scenario Dreamer가 대부분의 지표에서 오차를 대폭 줄이며 파라미터·속도 면에서도 우위를 보였다.
데이터셋과 샘플링
- Waymo Open Motion: 487 002 훈련·44 097 검증 시나리오에서 64 m × 64 m FOV를 중심·회전 정규화해 50 k 장면을 무작위 추출. 시뮬레이션 호환성(신호등 부재) 플래그도 함께 기록해 후처리에 활용.
- nuPlan: 1 300 h 로그를 30 s/1 s 간격으로 샘플링하여 450 k 훈련·50 k 검증 프레임을 구성, 동일한 FOV로 50 k 장면을 추출.
- 생성 샘플: 두 데이터셋에서 훈련한 Scenario Dreamer Base(B)·Large(L) 모델이 각각 50 k 초기 장면을 생성.
정량 지표 정의
1. Lane Graph – Urban Planning Metrics
Lane Centerline Graph의 degree ≠ 2 노드를 key‑points로 정의한 뒤, 다음 일차원 통계량에 대해 Fréchet Distance(FD)를 계산한다.
- Connectivity : key‑point 차수 분포
- Density : 그래프당 key‑point 수
- Reach : 각 key‑point에서 도달 가능한 경로 수
- Convenience : 모든 key‑point 쌍의 최단 경로 길이
- 가독성을 위해 로 스케일링.
2. Lane Perceptual Quality FD
Autoencoder 마지막 전 층 임베딩(펜얼티 없는 특징)에 대해 FD를 계산하여 “형태적 유사도”를 측정. ([openaccess.thecvf.com][1], [openaccess.thecvf.com][1])
3. 경로 길이·끝점 거리
- Route Length: 원점에서 DFS로 탐색 가능한 최장 경로(m).
- Endpoint Distance: 예측된 successor edge (i, j)마다 평균(m). ([openaccess.thecvf.com][1])
4. Agent JSD Metrics
50 k 실·생성 장면의 히스토그램을 아래 bin 설정으로 만들고 JSD 계산.
- Nearest Dist. (0–50 m, 1 m bin, ×10)
- Lateral Dev. (0–1.5 m, 0.1 m bin, ×10)
- Angular Dev. (−200°–200°, 5° bin, ×100)
- Length (0–25 m, 0.1 m bin, ×100)
- Width (0–5 m, 0.1 m bin, ×100)
- Speed (0–50 m/s, 1 m/s bin, ×100)
5. Collision Rate
동일 샘플에서 두 객체의 bounding‑box overlap 존재 비율 (%) 측정. ([openaccess.thecvf.com][1])
평가 프로토콜 Step‑by‑Step
-
실제·생성 셋 구축
- Waymo·nuPlan에서 50 k 실제 장면, Scenario Dreamer (B/L)에서 50 k 생성 장면 확보.
-
Lane Graph 분석
- 그래프 노드 중 degree≠2 지점만 선별 → key‑points.
- 4개 통계량 벡터 ·를 만들고 FD 계산.
- Autoencoder penultimate feature로 Perceptual FD 추가. ([openaccess.thecvf.com][1])
-
Agent 분석
- 각 차량에 대해 6 특성 히스토그램 → JSD.
- Synchronous AABB overlap 검사로 Collision Rate 산출. ([openaccess.thecvf.com][1])
-
스케일링
- 표준편차가 작은 항목은 10·100배 곱해 테이블을 읽기 쉽게 보정.
-
성능 레코딩
- 각 모델에 대해 Generate Time(s), Param (M), GPUh 병기. ([openaccess.thecvf.com][1])
-
비교
- nuPlan: SLEDGE (DiT‑L/XL) 재학습 결과와 비교.
- Waymo: DriveSceneGen의 GT‑Raster upper bound 사용. ([openaccess.thecvf.com][1])
결과 해석 핵심
- Lane Graph: Scenario Dreamer (L) FD 0.67 ↘ (↓53 %) vs SLEDGE (DiT‑XL) 1.44 (nuPlan). 연결성·Reach 등 모든 항목 동반 개선. ([openaccess.thecvf.com][1])
- Agent 분포: JSD 전 항목 4–8 배 감소, Collision Rate도 5–12 %대로 절반 이하. ([openaccess.thecvf.com][1])
- 연산 효율: Scene 당 0.08–0.16 s, 파라미터 377 M(‑50 %), 트레이닝 GPUh 96–256h(‑10×). ([openaccess.thecvf.com][1])
왜 이 평가가 타당한가
- 추상 시뮬레이터에서 도로 구조 다양성과 객체 상호관계가 RL 학습 난이도를 좌우하므로, 각각을 분리해 통계적 거리(FD, JSD)로 검증.
- 대량 샘플(50 k)·다도시 데이터로 모델 과적합·편향 완화.
- 스케일링 후에도 원본 값은 내부 스크립트로 보존(추가 검증 가능).
- Collision Rate는 시뮬레이션 안정성을 직접 측정해 실용성을 보강.
기억하면 좋은 Tip
- Urban Planning Metric 4종은 Lane Graph 품질 비교의 업계 표준으로 자리 잡은 지표(원형은 SLEDGE 논문).
- FD·JSD 모두 값이 0에 가까울수록 실제 데이터와 유사하므로 테이블에서 “↓”가 더 좋은 성능.
- 실험 코드는 GitHub repo 에 공개 예정이므로(링크 참조) 같은 절차로 자신의 데이터셋을 검증 가능. ([github.com][5])
behavior generation 정량적 평가
아래에는 Scenario Dreamer 논문의 Behaviour Simulation(행동 시뮬레이션) 부분에 대한 정량적 평가 과정을, 데이터 준비부터 지표 계산·결과 해석까지 단계별로 상세히 정리했습니다.
요약
- 1000개의 Waymo 테스트 장면을 대상으로, Ego 차량 기준 80 m × 80 m FOV 내에서 IDM, Trajeglish, CtRL-Sim(+/- Tilting) 모델을 시뮬레이션하고,
- **Jensen-Shannon Divergence (JSD)**로 모션 현실성(선속도·각속도·가속도·최근접 거리)을,
- **충돌률(Agent Collision, Planner Collision)**을 계산하여 비교했습니다.
1. 데이터 및 비교 대상 설정
-
테스트 장면 추출
- Waymo Open Motion Dataset에서 시뮬레이션 호환 조건을 충족하는 1 000개 장면을 무작위로 선택했습니다 .
-
시뮬레이션 영역
- 각 장면은 Ego 차량을 중심으로 80 m × 80 m FOV 안에서만 시뮬레이션을 수행하여 계산량을 절감했습니다 .
-
비교 모델
- IDM (규칙 기반), Trajeglish (데이터 기반), CtRL-Sim (Scenario Dreamer의 다중 에이전트 Transformer) 모델을 평가 대상으로 삼았습니다 .
2. 평가 지표 정의
2.1 모션 현실성 (Motion Realism via JSD)
-
특성 선택:
- 선속도(Linear Speed), 각속도(Angular Speed), 가속도(Acceleration), 최근접 거리(Nearest Distance)
-
히스토그램 세팅:
-
각 특성별로 200개 균등 bin을 사용하여 분포를 근사
-
범위:
- 선속도: [0, 30] m/s
- 각속도: [−50, 50] °/s
- 가속도: [−10, 10] m/s²
- 최근접 거리: [0, 40] m
-
-
JSD 계산:
- 실제 분포 vs. 생성 분포 간 유사도를 측정하며, 논문에서는 ×10⁻² 스케일로 보고했습니다 .
2.2 충돌률 (Collision Rates)
- Agent Collision (%): 시뮬레이션 중 에이전트 간 충돌이 발생한 비율 .
- Planner Collision (%): 에이전트 vs. Ego(IDM 플래너) 간 충돌 비율 .
3. 시뮬레이션 및 측정 절차
- 초기 장면 설정: Scenario Dreamer로 생성된 lane graph 위에 각 모델의 행동 시뮬레이터를 올립니다 .
- 롤아웃: 각 장면에 대해 최대 100 스텝(≈20 s) 동안 에이전트 행동을 순차 실행합니다 .
- 데이터 수집: 모든 에이전트의 위치·속도·가속도·이웃 거리 등을 각 타임스텝별로 기록합니다.
- 분포 생성: 기록된 값들로 히스토그램을 구성해 실제 로그와 비교합니다.
- JSD 산출: 위 2.1 절차에 따라 각 특성별 JSD를 계산합니다.
- 충돌 검사: AABB 충돌 판정으로 Agent와 Planner 충돌률을 집계합니다.
4. 평가 결과 (Supplementary Table 1)
| 모델 | 제어? | 선속도↓ | 각속도↓ | 가속도↓ | 최근접 거리↓ | Agent Coll.(%)↓ | Planner Coll.(%)↓ |
|---|---|---|---|---|---|---|---|
| IDM | ✗ | 9.2 | 0.4 | 19.8 | 1.6 | 7.2 | 5.8 |
| Trajeglish† | ✗ | 19.5 | 0.3 | 19.7 | 4.0 | 6.4 | 7.0 |
| CtRL-Sim (κ=+10) | ✓ | 4.1 | 0.1 | 20.1 | 1.3 | 6.2 | 4.9 |
| CtRL-Sim (κ=−50) | ✓ | 4.2 | 0.2 | 26.1 | 1.5 | 10.9 | 11.9 |
- Positive Tilting(κ=+10) 버전은 선속도·각속도·최근접 거리 JSD에서 최저를 기록하며, Planner 충돌률은 **4.9%**로 가장 낮았습니다 .
- Negative Tilting(κ=−50) 버전은 계획자 충돌률이 **11.9%**로 상승했으나, 모션 현실성은 비교적 유지되었습니다 .
5. 해석 및 시사점
- **데이터 기반 행동 모델(CtRL-Sim)**은 규칙 기반(IDM)·단순 토큰 모델(Trajeglish) 대비 모션 유사도와 충돌 회피 성능에서 전반적으로 우수합니다.
- κ 조절을 통해 **난이도(공격성/온순성)**를 직관적으로 제어할 수 있어, 강화학습 플래너의 스트레스 테스트에 활용 가능합니다.
- 실험 환경을 일관된 FOV와 동일 lane graph 표현으로 고정함으로써, 행동 모델 간 공정한 비교가 이뤄졌습니다.
더 궁금하신 세부 구현이나 추가 분석(예: JSD 계산 스크립트, 충돌률 정의 세부 조건 등)이 필요하시면 알려 주세요!
