
주소 바인딩
프로세스는 실행을 위해 메모리에 적재되면 프로세스를 위한 독자적인 주소공간이 생긴다. 이 주소를 논리적 주소라고 한다. 논리적 주소는 각 프로세스마다 독립적으로 할당된다.
왜 프로세스는 논리적 주소를 사용할까?
CPU가 프로세스의 작업을 수행하기 위해서 프로세스의 논리적 주소를 참조하게 된다. 논리적 주소만으로는 실제 메모리의 주소를 알 수 없기 때문에 논리 주소를 물리적 메모리로 열결시키는 작업이 필요하다. 이 작업을 주소 바인딩이라고 한다.
주소 바인딩에는
- 컴파일 타임 바인딩
- 로드 타임 바인딩
- 실행 시간 바인딩
이렇게 세가지 바인딩 방식이 있다. 세 바인딩의 기준은 물리적 주소가 언제 결정되느냐에 따라서 결정된다.
컴파일 타임 바인딩
말 그대로 컴파일 할 때 물리적 메모리 주소가 결정되는 주소 바인딩이다.
프로그램의 물리적 주소를 변경하고 싶으면 다시 컴파일해야 한다.
로드 타임 바인딩
프로그램의 실행이 시작될 때 물리적 주소가 결정된다.
이 바인딩에서는 로더가 메모리 주소를 부여하고 프로그램이 종료될 때 까지 물리주소가 고정된다.
실행 시간 바인딩(run time binding)
프로그램이 실행한 후에도 물리적 주소가 변경될 수 있는 바인딩 방식이다.
런타임 바인딩에서는 CPU가 주소를 참조할 때마다 해당 데이터가 물리적 메모리의 어느 위치에 존재하는지 주소 매핑 테이블을 이용해 주소 바인딩을 점검한다.
그리고 주소 매핑 테이블 뿐 만 아니라 기준 레지스터, 한계 레지스터, MMU(Memeoty Management Unit이 필요하다.
런타임 바인딩은 메모리에 프로세스의 주소공간이 연속적으로 적재되어 있음을 가정한다.
- 기준 레지스터: 프로세스의 물리적 메모리의 시작 주소를 가지고 있다.
- 한계 레지스터: 현재 CPU에서 수행중인 프로세스의 논리적 주소의 최대값, 프로세스의 크기를 가지고 있다.
- MMU: 논리적 주소를 물리적 주소로 메핑해주는 하드웨어
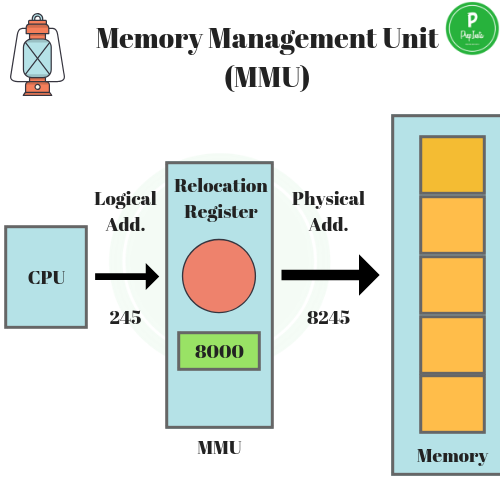
MMU 동작 방식
재배치 레지스터에는 현재 CPU에서 수행중인 프로세스의 물리적 메모리 시작 주소가 저장되어 있다. CPU가 논리적 주소 245에 있는 데이터를 요청하게 되면 재배치 레지스터에 저장된 물리적 시작 주소와 해당 논리적 주소를 더한다. 그렇게해서 실제 메모리의 8245에 있는 데이터를 꺼내오면 된다.
그렇다면 한번 생각해보자🤔
프로세는 고유한 주소공간을 가지고 있다. 그리고 논리적 주소값은 프로세스마다 독립적으로 할당된다고 하였다. 프로세스A에도 100번 논리 주소가, 프로세스B에도 100번 논리주소가 있다는 말이다. 그렇지만 프로세스A의 100번 논리주소에 매핑되는 실제 물리적 주소와 프로세스B에 매핑되는 실제 물리적 주소는 다를 것이다.
따라서 MMU기법에서는 문맥교환이 일어날 때 마다 재배치 레지스터의 값을 바뀌는 프로세스에 해당되는 값으로 재설정을 해주어야 한다.
한계 레지스터가 필요한 이유
MMU 방식에서는 기준레지스터값 + 논리적 주소값을 통해서 주소 바인딩을 한다.
만약 해당 값이 해당 프로세스의 주소범위를 넘어가는 값이 된다면 어떻게 될까? 프로세스가 접근해서는 안되는 영역을 접근할 가능성이 생긴다.
이런 문제점을 방지하기 위해서 한계레지스터를 사용하는 것이다.
한계 레지스터에 최대 논리적 주소값을 저장하고 CPU가 논리적 주소를 요청할 때 마다 한계 레지스터 값보다 작은 값인지를 검사하게 된다.
