목차
1. 정확도(Accuracy)
2. 오차행렬(Confusion matrix)
3. 정밀도(precision)와 재현율(recall)
서두
머신러닝 모델을 적용한 뒤 최종적으로 평가를 해야 한다.
평가는 모델이 분류냐 회귀냐에 따라 종류가 나뉜다.
분류 : 혼동 행렬(confusion matrix), 정확도(accuracy), 정밀도(precision), 재현율(recall), F값(F1-score), 곡선아래면적(AUC)
회귀 : 평균제곱오차(MSE), 결정계수(coefficientg of determination)
먼저 분류 모형에 따른 평가지표를 하나씩 살펴보자
1. 정확도(Accuracy)
정확도는 실제 데이터에서 예측 데이터가 얼마나 같은지를 판단하는 지표다.
정확도(Accuracy) =
하지만 정확도만으로 평가할 경우 ML모델의 성능을 왜곡할 가능성이 크다.
예를 들어 캐글에서 가장 유명하며 입문단계로 꼽히는 타이타닉 예제의 수행결과를 봤을 때, ML 알고리즘을 적용한 후 보통 예측 정확도 결과가 80%였지만 남성보다 여성의 생존확률이 높았으므로 알고리즘 적용없이 여성을 생존으로, 남성을 사망으로 예측결과를 예측해도 비슷한 결과가 나온다.
즉, 단순 성별 조건만으로 결정하는 것과 별 차이가 없는 평가지표로 나타날 가능성이 크다.
다음 예제를 통해 살펴보자
BaseEstimator 클래스를 상속받아 성별에 따라 생존자를 예측하는 단순 Classifier를 생성했다.
생성한 MyDummyClassifier()는 단순히 성별 피처가 1이면 0, 아니면 1로 예측하는 단순한 Classifier이다.
사이킷런은 BaseEstimator를 상속받으면 Customized 형태의 Estimator를 생성할 수 있다.
Estimator : 분류, 회귀 즉, 지도학습의 모든 알고리즘을 구현한 클래스
Estimator 클래스는 fit()과 predict()를 내부에서 구현한다.
from sklearn.base import BaseEstimator
class MyDummyClassifier(BaseEstimator):
# fit() 아무것도 학습X
def fit(self, X, y=None):
pass
# predict() 메서드
def predict(self, X):
pred = np.zeros((X.shape[0], 1))
for i in range(X.shape[0]):
if X['Sex'].iloc[i] == 1:
pred[i] = 0
else:
pred[i] = 1
return pred이제 생성된 Classifier를 통해 타이타닉 생존자 예측을 수행해보자
## 데이터 전처리 함수
from sklearn import preprocessing
import numpy as np
# Null 처리 함수
def fillna(df):
df['Age'].fillna(df['Age'].mean(),inplace=True)
df['Cabin'].fillna('N',inplace=True)
df['Embarked'].fillna('N',inplace=True)
df['Fare'].fillna(0,inplace=True)
return df
# 불필요한 속성 제거 함수
def drop_features(df):
df.drop(['PassengerId','Name','Ticket'],axis=1,inplace=True)
return df
# 레이블 인코딩 함수
def format_features(df):
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin','Sex','Embarked']
for feature in features:
le = preprocessing.LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# 생성한 Data Preprocessing 함수 호출
def transform_features(df):
df = fillna(df)
df = drop_features(df)
df = format_features(df)
return df
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 타이타닉 데이터 불러오기, 데이터 가공
titanic_df = pd.read_csv('dataset/titanic_train.csv')
y_titanic_df = titanic_df['Survived'] # 타겟 변수
X_titanic_df = titanic_df.drop('Survived', axis=1) # 피처
X_titanic_df = transform_features(X_titanic_df)
# 학습/테스트 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df,
test_size = 0.2, random_state = 0)
# DummyClassifier를 통해 학습/예측/평가 수행
myclf = MyDummyClassifier()
myclf.fit(X_train, y_train)
mypredicitions = myclf.predict(X_test)
print('DummyClassifier 정확도 : {0:.4f}'.format(accuracy_score(y_test, mypredicitions)))DummyClassifier 정확도 : 0.7877이와 같이 단순한 알고리즘 예측결과도 정확도 결과가 약 78%로 높은 수치가 나올 수 있으므로 모델학습에 대한 정확도를 평가지표를 활용할 경우 항상 신중해야 한다.
2. 오차행렬(Confusion matrix, 혼동행렬)
오차행렬(Confusion matrix, 혼동행렬)은 학습된 분류모델이 예측을 수행하면서 얼마나 헷갈리는지에 대해서 보여주는 지표이다.
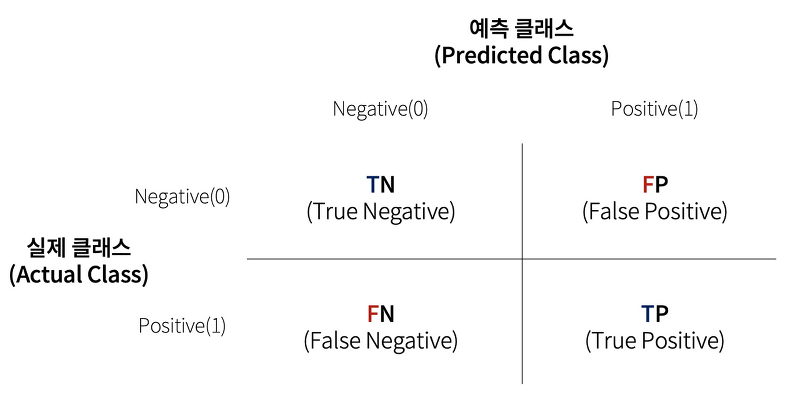

- TN : 예측값을 0(부정)으로 예측했고, 실제 값도 0인 경우
- FP : 예측값을 1(긍정)으로 예측했고, 실제 값은 1인 경우
- FN : 예측값을 0으로 예측했고, 실제 값은 1인 경우
- TP : 예측값을 1로 예측했고, 실제값도 1인 경우
TN, FP, FN, TP 값을 조합하여 Classifier의 성능을 측정할 수 있는 주요 지표인 정확도(Accuracy), 정밀도(Precision), 재현율(Recall)값을 알 수 있다.
앞서 설명한 정확도(Accuracy)의 경우 아래와 같이 계산될 수 있다.
정확도(Accuracy) =
정확도는 분류 모델의 성능을 측정할 수 있는 한 가지의 요소일 뿐이다.
불균형데이터에서는 정확도보다 정밀도(Precision)와 재현율(Recall)이 더 선호되는 평가지표이다.
3. 정밀도(Precision)와 재현율(Recall)
정밀도와 재현율은 Positive 예측 성능에 좀 더 초점을 맞춘 평가지표이다.
정밀도와 재현율은 다음과 같은 공식으로 계산된다.
정밀도(Precision) =
재현율(Recall) =
정밀도는 예측을 Positive로 한 대상 중 예측과 실제값이 "Positive"로 일치한 데이터의 비율을 의미한다.
Positive 예측 성능을 정밀하게 측정하기 위한 평가지표로 양성 예측도라고도 한다.
재현율은 실제 값이 Positive인 대상 중 예측과 실제 값이 Positive로 일치한 데이터의 비율을 뜻한다.
민감도(Sensitivity) 또는 TPR(True Positive Rate)라고도 한다.
재현율의 경우 실제 Positive 양성 데이터를 Negative로 잘못 판단할 경우 큰 위험을 초래할 수 있다.
암 환자를 예를 들 경우, 환자를 Positive 양성이 아닌 Negative 음성으로 잘못 판단할 경우 암 환자의 치료시기를 놓쳐 사망에 이르게 할 수 있다.
반면 정밀도가 중요한 지표가 되는 경우도 있다.
예를 들어 스팸메일 여부 판단 모델의 경우, 실제 Negative(일반메일)을 Positive(스팸메일) 분류할 경우 업무에 차질이 생길 수 있다.
타이타닉 예제를 통해 오차행렬, 정밀도, 재현율을 구해서 예측 성능을 평가해보자
예측 성능을 평가하기 앞서 평가를 간편하게 적용하기 위해
confusion matrix, accuracy, precision, recall 등의 평가를 한 번에 호출하는 함수를 만들어보자
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
def get_clf_eval(y_test, pred):
confusion = confusion_matrix(y_test, pred)
accuracy = accuracy_score(y_test, pred)
precision = precision_score(y_test, pred)
recall = recall_score(y_test, pred)
print('오차행렬')
print(confusion)
print('정확도:{0:.4f}, 정밀도:{1:.4f}, 재현율:{2:.4f}'.format(accuracy, precision, recall))이제 로지스틱 회귀 기반으로 타이타닉 생존자를 예측하고 평가지표를 수행해보자
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
# 타이타닉 데이터 불러오기, 데이터 가공, 학습/테스트 데이터 분할
titanic_df = pd.read_csv('dataset/titanic_train.csv')
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df,
test_size=0.20, random_state=11)
lr_clf = LogisticRegression()
lr_clf.fit(X_train, y_train)
pred = lr_clf.predict(X_test)
get_clf_eval(y_test, pred)오차행렬
[[104 14]
[ 13 48]]
정확도:0.8492, 정밀도:0.7742, 재현율:0.7869참고자료 : 파이썬 머신러닝 완벽가이드 - 권철민
