Chapter
1. 기초수학 문제풀이
2. 자료구조
(1) 리스트(List)
1. 기초수학 문제풀이
역시 수업들으면서 다 알아들은 것 같아도 혼자 풀면 얼렁뚱땅이다. 몇 문제 풀고는 몇 문제 남았나 순서 확인하느라고 힘들었다ㅠㅠ... 아쉬운 세 문제 복습하고 마무리하려 한다...
Q1. 100~1000사이의 난수만들어서 약수,소수, 소인수 출력하기
→ 풀이
# 약수
for n in range(1, randInt+1):
if randInt % n == 0:
print(f'{n}은 {randInt}의 약수')
print('=' * 50)
############################
# 소인수
n = 2
while n <= randInt:
if randInt % n == 0:
print('소인수:{}'.format(n))
randInt /= n
else:
n += 1
print('='*50)
약수와 소인수는 어떻게 구했지만, 소수는 결국 실패했다. 계속 무한대로 코드가 돌아가거나, 범위 내의 소수만 출력될 뿐이었다.
→ 강사님 코드
rNum = random.randint(100,1000)
print(f'rNum: {rNum}')
for num in range(1, rNum+1):
soinsuFlag = 0
# 약수
if rNum % num == 0:
print(f'[약수]: {num}')
soinsuFlag += 1
# 소수
if num != 1: #소수는 1이 될 수 없음.
flag = True
for n in range(2, num):
if num % n == 0: #약수가 있음!
flag = False #약수가 있으므로 더이상 반복문 진행X
break
if(flag): #flag = true라는 건 약수가 없다는 뜻
print(f'[소수]: {num}')
soinsuFlag += 1
# 소인수
if soinsuFlag >= 2:
print(f'[소인수]: {num}')소인수가 약수이면서 소수인점을 이용해서 코드를 깔끔하게 짠 게 너무 대단하다는 말밖에는....ㅠㅠ 나는 따로따로 짜려고 하니까 너무 코드도 길어지고 복잡해져서 제발에 걸려 넘어지게 되던데.. 소수를 구할 때 2이상의 범위에서 약수가 있으면 소수가 될 수 없다는 것을 이용한 것을 보면 역시 기본베이스를 더 다져야 한다는 생각이 든다.
Q2. 100~1000사이의 난수를 소인수분해하고, 이에 대한 지수 찾기
→ 강사님 코드
import random
randInt = random.randint(100,1000)
print(f'randInt: {randInt}')
soinsuList = []
n = 2
while n <= randInt:
if randInt % n == 0:
print(f'소인수: {n}')
soinsuList.append(n) #!!
randInt /= n
else:
n += 1
print(f'soinsuList: {soinsuList}')
tempNum = 0
for s in soinsuList:
if tempNum != s:
print(f'{s}\'s count: {soinsuList.count(s)}')
tempNum = s소인수분해는 했는데, 소인수를 카운트하는 걸 할 수가 없었다. 소인수들을 리스트에 나열해서 그 수를 세는 게 핵심이었다.
Q3. 군수열의 합이 최초 100을 초과하는 항의 값 찾기
수열: {1/1, 1/2, 2/1, 1/3, 2/2, 3/1, 1/4, 2/3, 3/2, 4/1, 1/5, 2/4}
flag = True
n = 1 # 군
nCnt = 1 # 군 안의 항
searchNC = 0 # 분자
searchNP = 0 # 분모
sumN = 0
while flag:
for i in range(1, (n+1)):
print(f'{i}/{(n-i+1)} ', end= '')
sumN += i / (n-i+1)
nCnt += 1
if sumN > 100:
searchNC = i
searchNP = n-i+1
flag = False
break
print()
n += 1
print(f'수열의 합이 최초 100을 초과하는 항의 값: {nCnt}, {searchNC }/{searchNP }, {sumN}')분명 혼자 못 풀 때에는 손도 못 대겠는데, 강사님이랑 같이 풀 때는 이해가 다 된다. 분수형태의 군수열을 지난시간에 예제로 풀어서 자신있다 싶었는데 고작 합계 구하는 걸 못 해서 헤맸다. 조바심내지 말아야지
2. 자료구조
여러 개의 데이터가 묶여있는 자료형을 컨테이너 자료형이라고 하는데, 이러한 컨테이너 자료형의 데이터 구조를 '자료구조'라고 한다.
컨테이너 자료형에는 리스트(list), 튜플(tuple), 딕셔너리(dic), 세트(set)와 같은 종류가 있다.
- 리스트(list): []안에 데이터를 나열
- 튜플(tuple): ()안에 데이터를 나열. 저장한 정보는 변경 불가능
- 딕셔너리(dic): {}안에 key와 value를 한 쌍으로 나열
- 세트(set): {}안에 데이터 나열. 중복 데이터는 한 번만 출력함.
# 리스트(List)
students = ['철수', '짱구', '훈이', '유리', '맹구']
print(students)
print(type(students))
#튜플(tuple)
jobs = ('의사', '속기사', '전기기사', '감정평가사','회계사')
print(jobs)
print(type(jobs))
#딕셔너리(dic)
scores = {'kor':95, 'eng':80, 'math':100}
print(scores)
print(type(scores))
#세트(set)
allsales = {100, 200, 500, 200}
print(allsales)
print(type(allsales))
(1) 리스트(List)
1) 리스트란?
리스트는 []을 통해서 선언할 수 있는데, 안에 나열한 데이터는 ','를 통해서 구분짓는다.
데이터는 숫자, 문자(형), 논리형 등 모든 종류의 데이터가 가능하며, 심지어 또다른 컨테이너 자료형 데이터를 담을 수도 있다. 리스트안에 나열된 데이터들은 아이템(item)이라고도 부를 수 있다.
students = ['짱구', '철수', '유리', '훈이', '맹구']
print(f'students: {students}')
print(type(students))
print('-'*50)
numbers = [10, 20, 30, 40, 50, 60, 70]
print(f'numbers: {numbers}')
print(type(numbers))
print('-'*50)
strs = [3.14, '십', 20, 'one','3.141592', [1,2,3]]
print(f'strs: {strs}')
print(type(strs))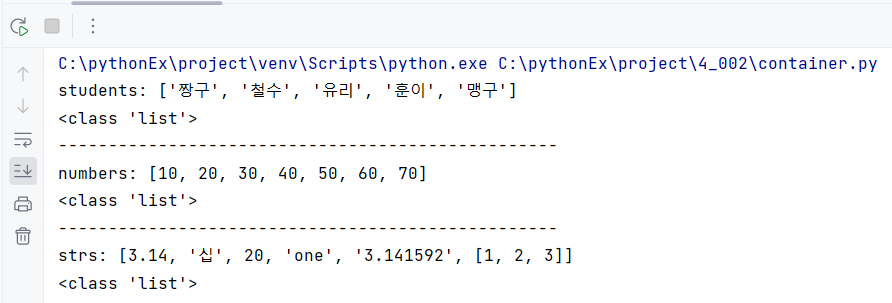
2) 리스트 조회
리스트의 아이템들은 한꺼번에 []안에 나열해서 출력할 수도 있지만, 하나의 아이템들을 따로 출력할 수도 있다.
리스트의 번호표인 인덱스(index)를 이용하는 것인데, 이 때 0부터 순서가 시작한다는 것을 주의해야 한다.
students =['짱구', '철수', '유리', '훈이', '맹구']
print(f'students: {students}')
print(f'students[0]: {students[0]}')
print(f'students[1]: {students[1]}')
print(f'students[2]: {students[2]}')
print(f'students[3]: {students[3]}')
print(f'students[4]: {students[4]}')
print(type(students))
print(type(students[0]))
3) 리스트 길이
리스트의 길이는 아이템의 개수를 의미하는데, len()함수를 이용해서 구할 수 있다. len()은 리스트같은 컨테이너 자료형 데이터들의 길이 뿐만 아니라, 단일의 문자형 데이터의 길이 등을 구할 때에도 사용할 수 있다.
# 리스트의 길이: 리스트에 저장된 아이템 개수
students =['짱구', '철수', '유리', '훈이', '맹구']
print(f'students: {students}')
sLength = len(students)
print('length of students: {}'.format(sLength))
print('-'*50)
# 문자열의 길이도 알 수 있음.
str = 'Hello python!!'
print(f'\'Hello python!!\'의 문자열의 길이: {len(str)}')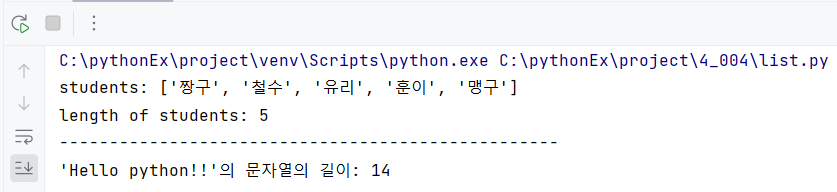
4) 리스트와 for문
for문을 이용해서 리스트의 아이템을 조회하거나, 아이템을 이용해서 추가 데이터를 출력할 수 있다.
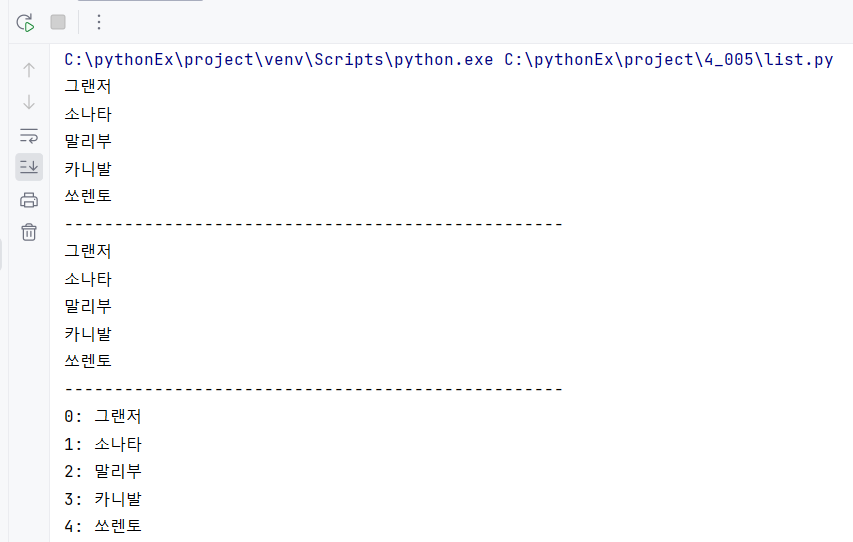
cars = ['그랜저','소나타','말리부','카니발','쏘렌토']
for i in range(len(cars)):
print(cars[i])
print('-'*50)
for car in cars:
print(car)
print('-'*50)
for idx, value in enumerate(cars):
print(f'{idx}: {value}')
리스트 cars의 아이템을 출력하려고 할 때, 앞서 배운 방법대로 for문의 range안에 리스트 갯수를 넣어서 데이터를 출력할 수도 있지만, range()함수를 사용하지 않더라도 리스트 자체를 넣어서 레퍼런스 변수(car)가 리스트를 출력할 수 있게 할 수 있다.
더해서, enumerate()함수를 이용한다면 자동적으로 리스트 안의 아이템들에게 인덱스를 자동적으로 부여해서 나열할 수 있다.
str = 'Hello python!!'
for idx, value in enumerate(str):
print(f'{idx}: {value}')
참고로 enumberate()함수는 컨테이너 자료형 뿐만 아니라 len()과 마찬가지로 문자형 등과 같은 단일 데이터들에게도 인덱스를 부여해서 사용할 수 있다.
studentCnts = [[1, 19], [2,20], [3,22], [4,18], [5,21]]
for i in range(len(studentCnts)):
print(f'{studentCnts[i][0]}학급 학생수: {studentCnts[i][1]}')
print('-'*50)
for classNo, cnt in studentCnts:
print(f'{classNo}학급 학생수: {cnt}')
print('='*50)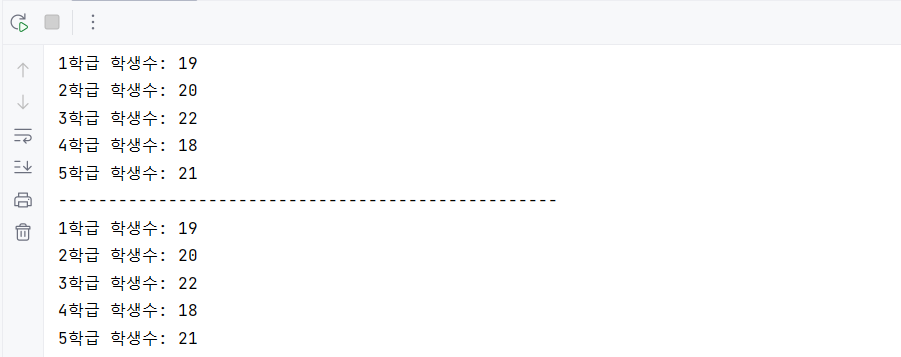
뿐만 아니라, 리스트 안에 리스트 형식의 데이터가 나열되어 있을 때에도 for문을 이용하거나, 레퍼런스 변수를 두 개를 나열해서 각각의 인덱스를 자동으로 불러올 수 있는 좀 더 간단한 코드를 이용할 수 있다.
5) 리스트와 while문
for문만 아니라 while문을 이용해서도 리스트를 조회할 수 있다.
cars = ['그랜저','소나타','말리부','카니발','쏘렌토']
#1
n = 0
while n < len(cars):
print(cars[n])
n += 1
print('-' * 50)
#2
n = 0
flag = True
while flag:
print(cars[n])
n += 1
if n == len(cars):
flag = False
print('-'*50)
#3
n = 0
while True:
print(cars[n])
n += 1
if n == len(cars):
break
리스트 길이를 이용한 조건식이나, 조건식에 다다를 때까지 조건문 계속 시행하는 while문 등을 사용할 수 있다.
