Chapter
1. BeauifulSoup library
(1) 예제1. html파일 만들어서 크롤링하기
(2) 예제2. 네이버 금융
(3) 예제3. 위키백과 문서정보 가져오기
2. '시카고 샌드위치 맛집' 웹데이터 분석
(1) 메인 페이지 웹데이터 분석
(2) 하위 페이지 웹데이터 분석
(3) 번외: 지도 시각화
지도 시각화가 끝나고, 웹 크롤링에 대해서 배웠다.
웹 크롤링이란 웹, URL을 통해서 원하는 데이터를 추출해내는 것을 말한다. 단어도 처음 들어본데다가 html 문법 또한 다루게 될줄 몰라서 혼자서 수업을 듣는 게 많이 더뎠다. 몇 번을 일시정지한 다음 익히고 넘어간 줄 모르겠다.
웹 크롤링은 BeautifulSoup 라이브러리를 이용하는데, 우선 몇 가지 예제를 통해서 사용방법을 익히고, <Chicago Magazine>에서 2012년에 발표한 'The 50 Best Sandwiches in Chicago' 데이터를 통해 웹데이터 분석을 해보자!
1.BeauifulSoup library
우선 예제에 들어가기에 앞서 라이브러리를 설치한다음 불러온다.
conda install -c anaconda beautifulsoup4
from bs4 import BeautifulSoup(1) 예제1. html파일 만들어서 크롤링하기
예제학습을 하기 위해서 새로운 html파일을 만들었다.(zerobase_0904.html)

이제부터 각종 html 태그들을 통해서 데이터를 추출해보자. 먼저 파일을 VScode에 불러와 출력하면, html코드를 출력할 수 있다.
page = open("../data/03. zerobase_0904.html", "r").read()
print(page)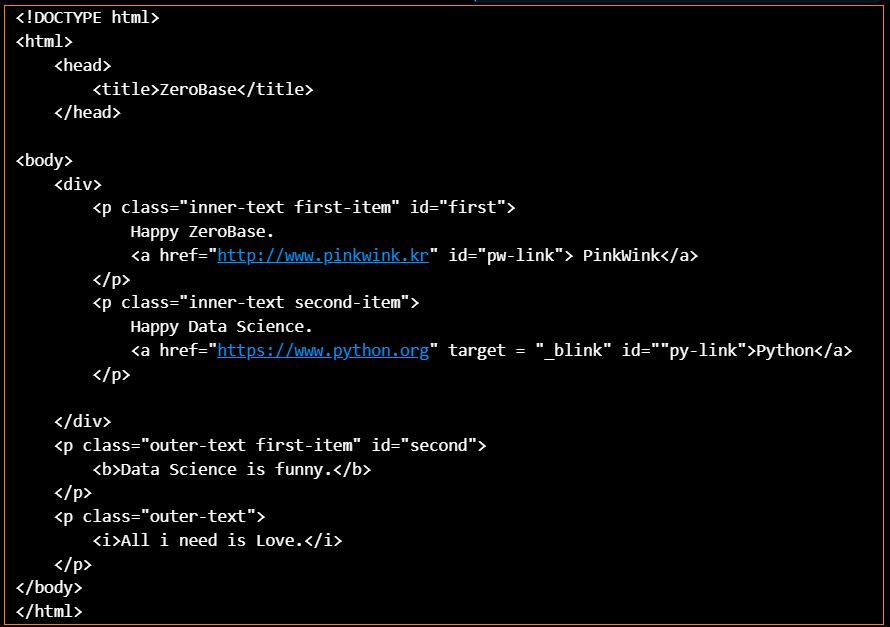
혹은 BeatifulSoup 매서드를 사용해도, 코드를 불러올 수 있다.
soup = BeautifulSoup(page, "html.parser")
print(soup.prettify())이제 불러온 웹페이지의 html 코드를 soup 변수에 지정했으면 태그를 불러오면 그 태그안에 든 내용을 확인할 수 있다. body태그와 p태그를 확인해보자.
soup.body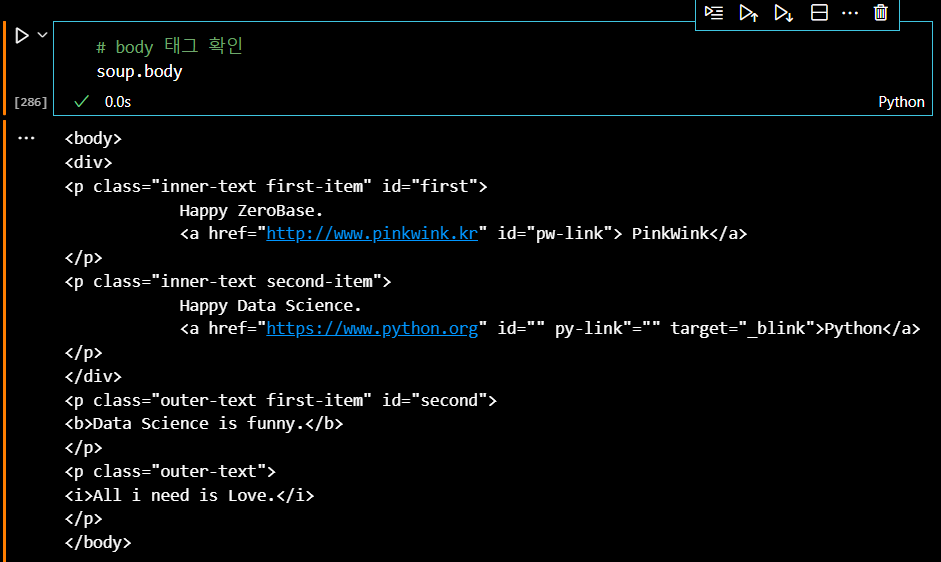
soup.p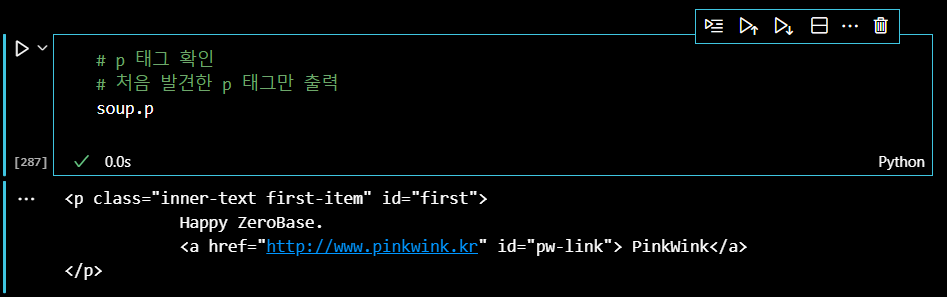
그런데 웹페이지의 p태그가 여러 개 있는데도 불구하고, 첫 번째 발견한 태그밖에 출력하지 못한다. 이럴때, find_all() 매서드를 사용하면 모든 태그를 찾을 수 있다. (단순 find() 매서드를 사용하면 태그 하나만 출력한다.) P태그를 모두 찾아보자.
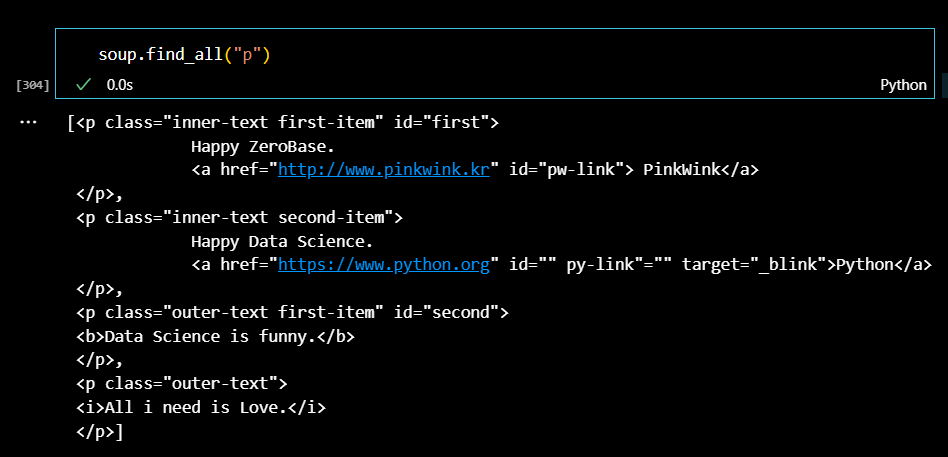
soup.find_all("p")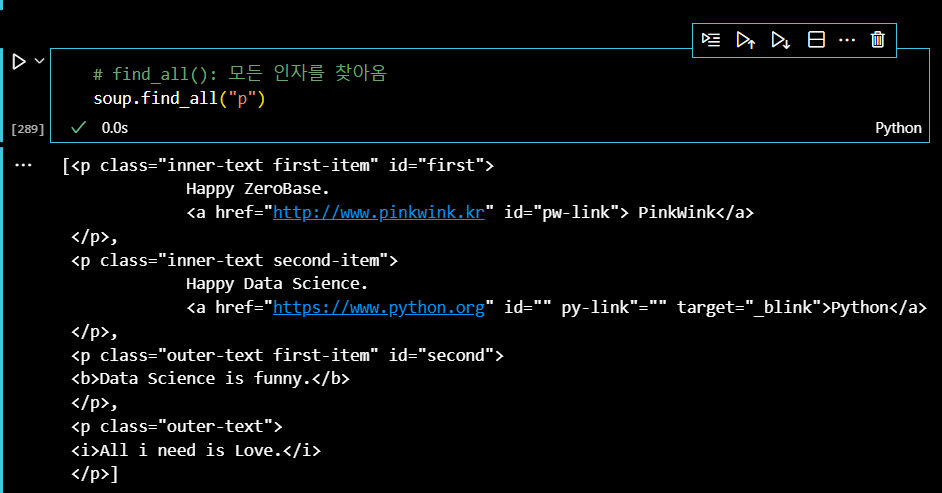
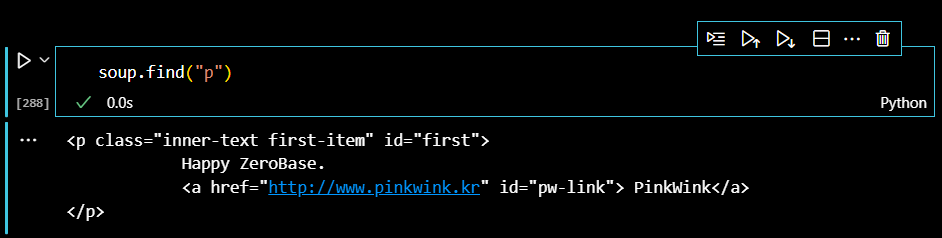
find()매서드 안에 태그뿐만 아니라, 태그 하위의 class나 id같은 속성값을 서술하여, 데이터를 추출할 수 있다. 먼저, find()로 첫 번째 p태그를 추출하면 다음과 같다.
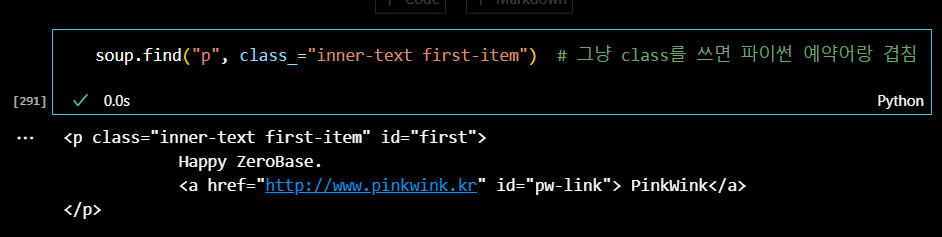
이때, class나 id속성 조건을 주어서 p태그를 찾아보자. 그런데 class는 python 예약어와 겹치기 때문에 조건을 줄 때에는 'class_='와 같은 형태로 적어야 한다.
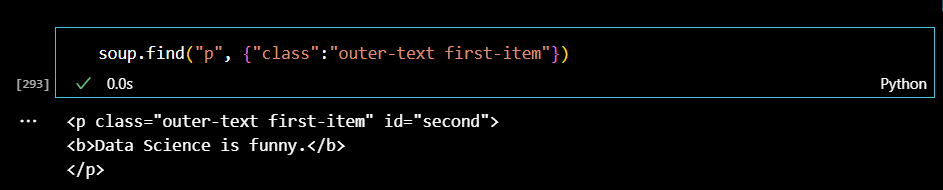
class와 그 value를 딕셔너리 형태로 쓸 수도 있다.
여기서 태그를 제외하고 text만 추출할 수 있다.

그래도 남아 있는 html문법은 strip()매서드를 이용해서 제거해보자.

id 속성값으로도 데이터를 찾아보자. 혹시 여러 개를 찾을 수 있으니 find_all()매서드를 통해서 검색해보자. 이때 데이터 출력값은 리스트 형식으로 출력된다.

여기서도 텍스트만 깔끔하게 출력할 수 있는데, 출력된 데이터가 리스트 형식임을 주의해야 한다.
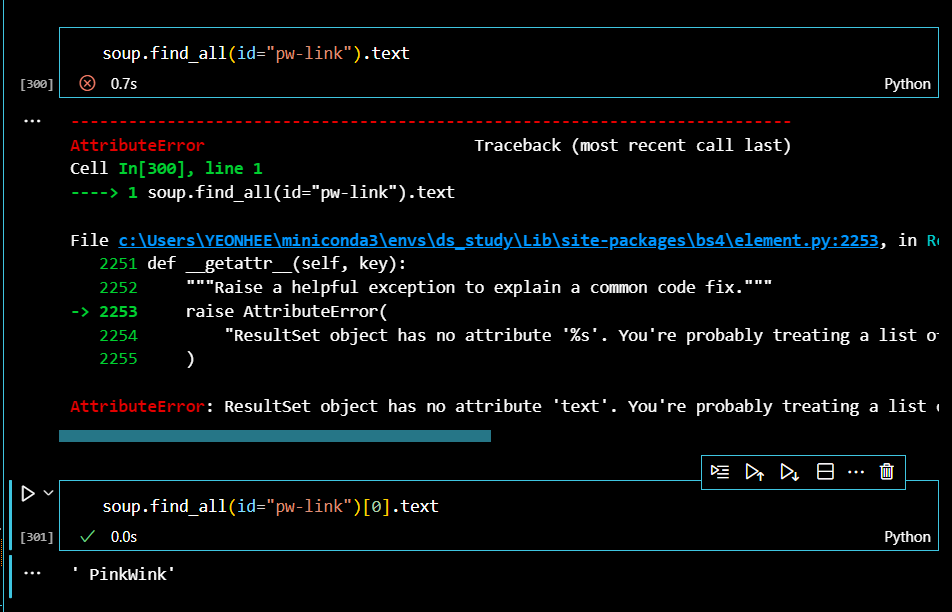
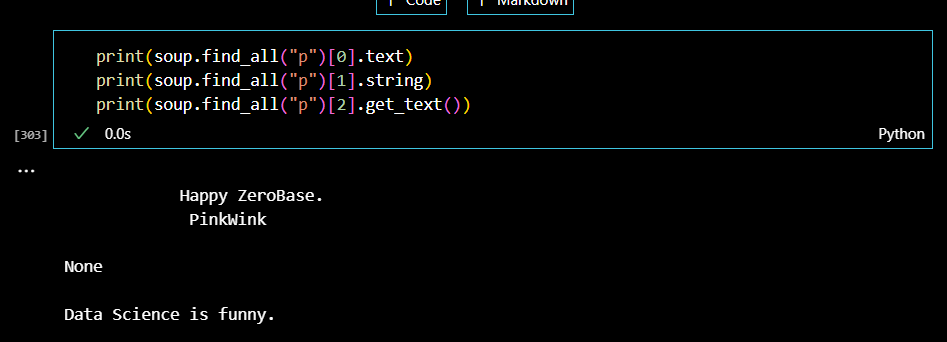
text 메서드 뿐만 아니라 다양한 메서드를 통해서 태그를 제외한 텍스트만을 추출할 수 있다. p태그를 찾아서 다양한 메서드로 인덱스 0,1,2의 데이터를 추출해보자.
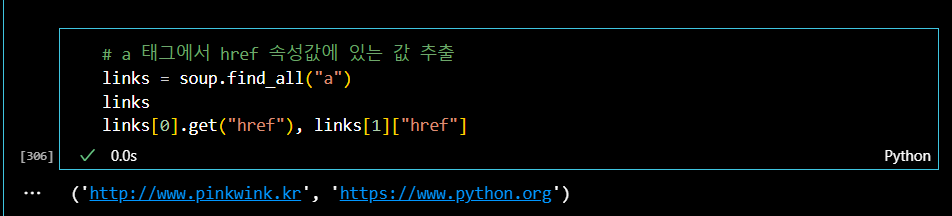
마지막으로 zerobase 웹페이지에 있는 링크들을 찾아보자. 링크는 <a href>를 통해서 생성되기 때문에, 먼저 a태그를 찾은 다음, href속성값을 검색한다.
이제부터는 실제 웹페이지를 통해서 데이터 파싱을 해보자!
.
.
(2) 예제2. 네이버 증권
먼저 사용할 라이브러리들을 불러보자.
import requests
from bs4 import BeautifulSoup지금부터 파싱할 웹페이지는 '네이버 증권'으로 그 중에서도 '시장지표' 페이지를 분석하려고 한다.
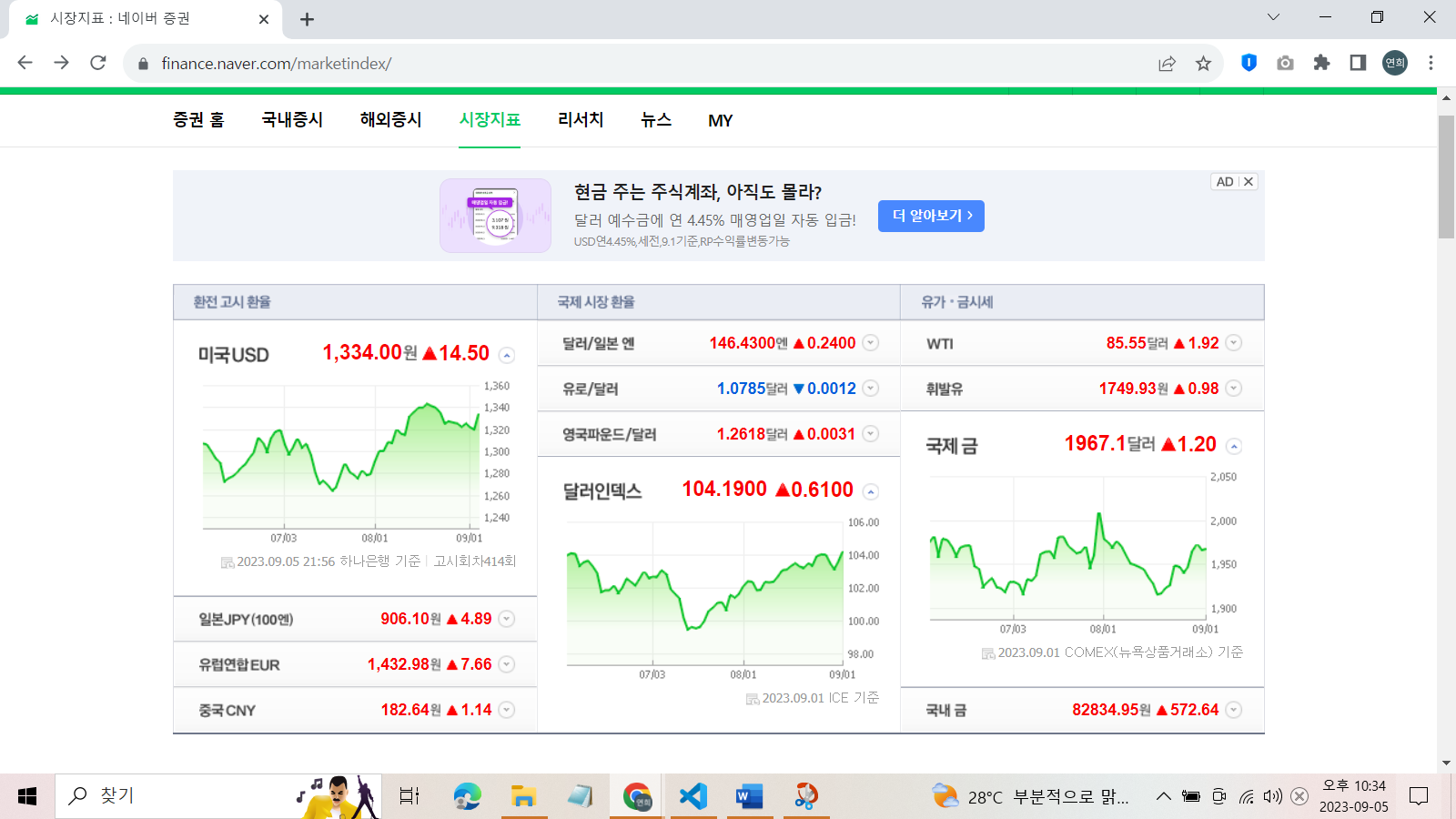
다음에는 '시장지표' 페이지의 url주소를 변수에 지정해서 html코드를 불러온다.
url = "https://finance.naver.com/marketindex"
response = requests.get(url)
soup = BeautifulSoup(response, "html.parser")
print(soup.prettify())prettify() 메서드로 전체 웹페이지 코드를 불러와서 확인할 수도 있지만, 코드가 너무 길어질 수도 있으므로
response.status코드를 이용해서 http 상태코드로 간단하게 정상출력되는지 확인해보자.
100번대부터 500번대까지 다양한 상태를 보여주는 상태코드가 있는데, 이때, 200이 출력된다면 url이 정상적으로 불러온 것이다.
그런데, 예제 1번처럼 간단한 웹페이지가 아니라 지금처럼 아주 복잡한 html코드로 출력되는 웹페이지라면 크롤링하기가 매우 힘들다. 따라서 웹페이지 안에서 개발자 도구를 연 다음, 'ctrl+shift+c'를 누르고, 원하는 element를 클릭하면 해당 html코드 부분을 확인할 수 있다.
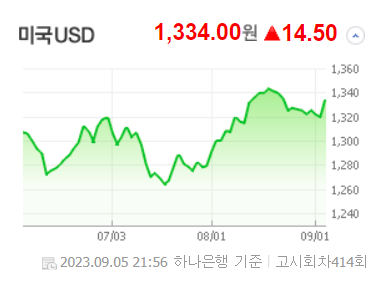
나는 금액 데이터를 파싱하고 싶기 때문에, 이 부분 html코드를 확인했다.
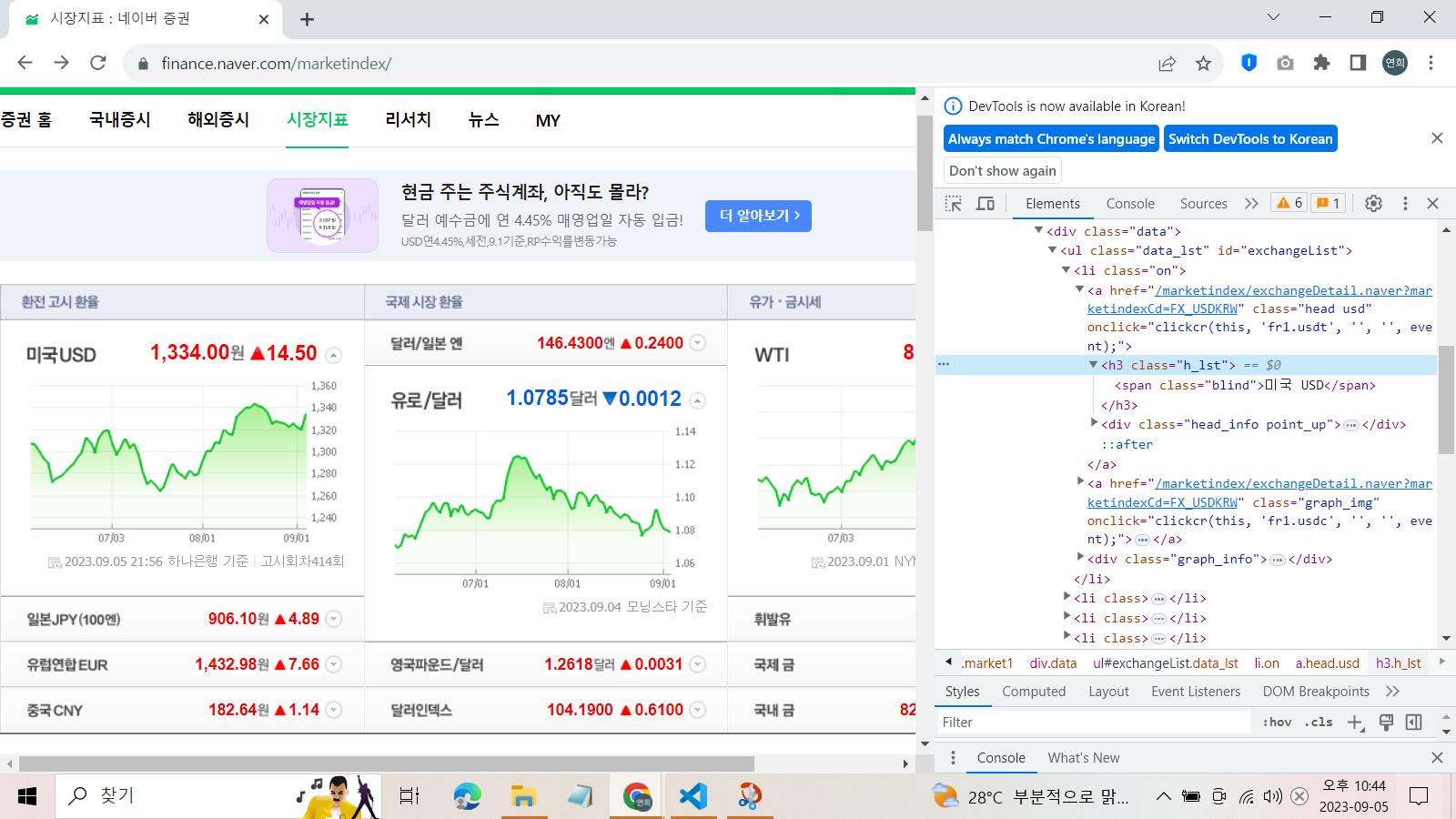
이때 태그가 span임을 확인했으므로, 모든 금액 데이터를 출력해보자.
하지만 span태그는 class 속성값을 하위에 여러개 두고 있으므로, 다중조건으로 금액만을 출력해야 한다.
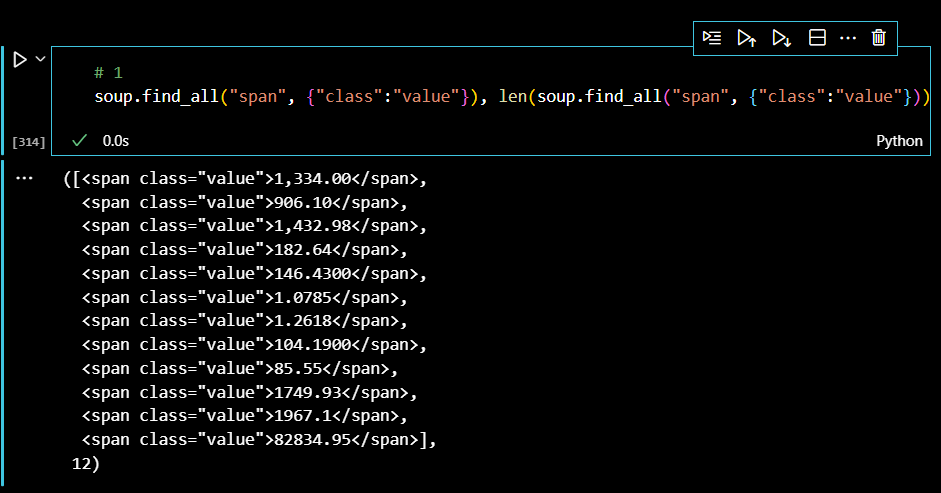
웹페이지에서 출력되는 금액과 그 개수가 모두 일치한다.
미국 환율 금액을 찾아보자. 미국 환율 금액은 웹페이지에서 가장 첫 번째, html 코드에서도 인덱스 0번을 차지한다.
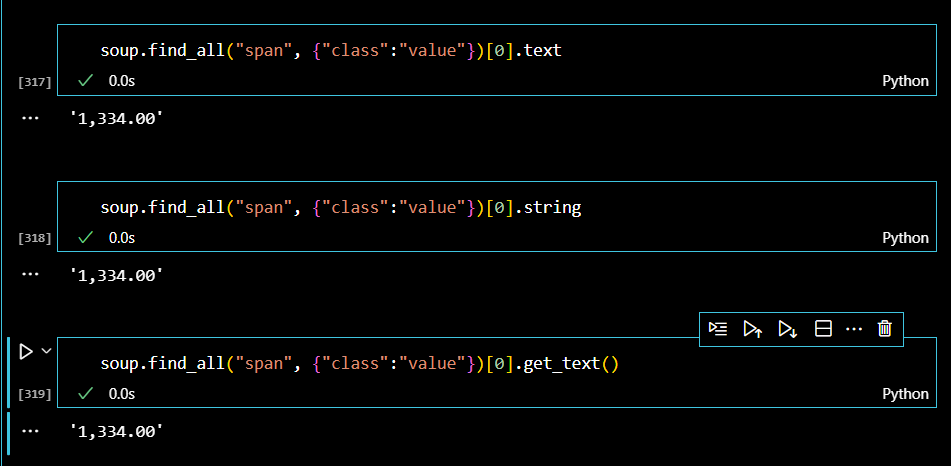
이런식으로 파싱해서 미국 환전 환율의 상단의 '미국USD'와 환율 금액, 상승 기호, 변동금액까지 출력해보자.
참고로 이번에는 select(),select_one() 메서드를 이용해서 파싱하는데, find()와 마찬가지로 태그를 인자로 집어넣으면 태그 안에 든 데이터를 출력한다. 하지만 select()의 경우에는 select()로 검색하면 모든 태그를 전부 찾고, select_one()을 이용해야 첫 번째 발견한 하나의 태그만을 찾을 수 있다. 이제 메서드를 이용해서 데이터를 찾아보자.
위 사진과 같은 환율 정보는 'li'태그에서 모두 찾을 수 있다.
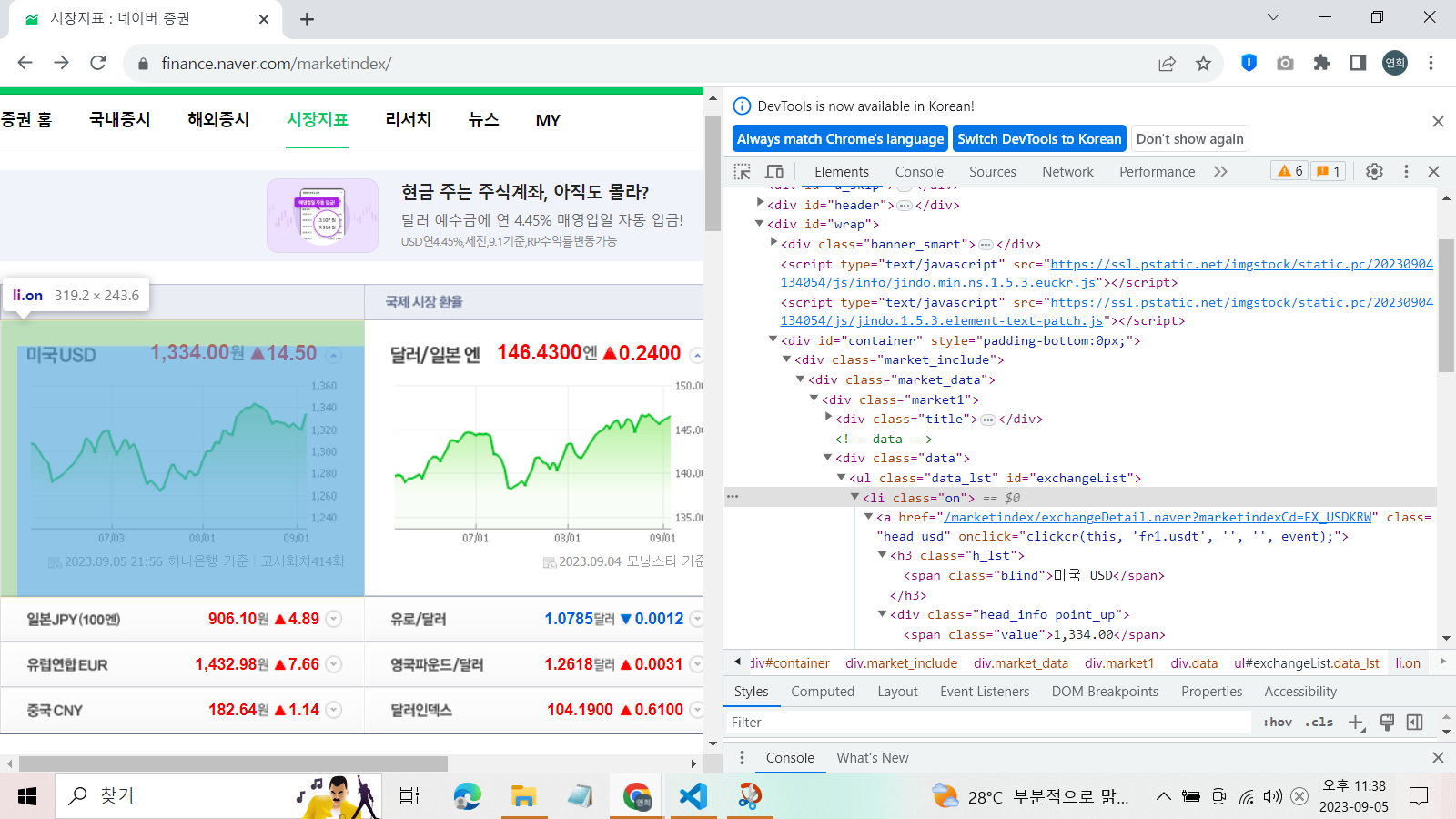
따라서 'li'태그를 모두 찾은 리스트를 exchangeList 변수에 지정해주었다. 리스트는 미국부터 중국까지의 환율 정보가 담긴 것이다.
exchangeList = soup.select("li")
exchangeList따라서 인덱스 0의 value가 미국 환율 정보가 된다. 먼저, 이를 이용해서 국가명, 환율 금액, 변동 금액을 출력해보자. 각각의 class 속성값을 이용한다. slect() 메서드를 사용할때 class나 id를 기호로 간단하게 표현할 수 있는데, class의 경우에는 아래 코드와 같이 '.'으로, id의 경우에는 '#'으로 간단하게 사용할 수 있다.
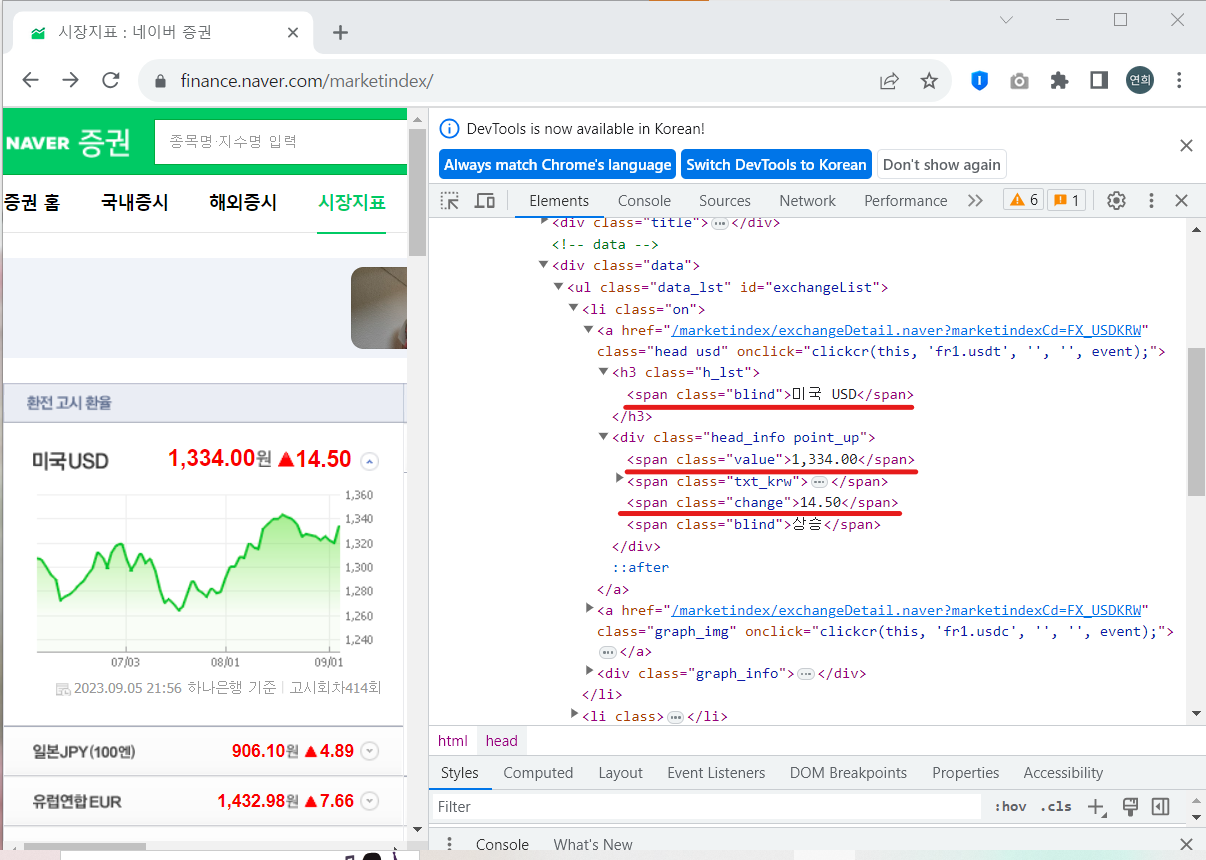
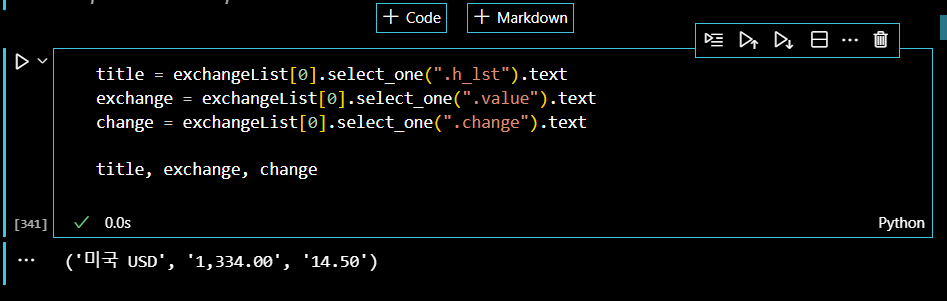
이제 환율 상승/하락 정보를 가져오자. 그런데 사진에서 보이는 것과 같이 속성값이 같은 것이 있다. 그래서 이럴 때에는 '>' 기호를 사용해서 그 밑의 태그를 출력한다는 표시를 해줘야 한다. 또한, 상위 클래스 속성이 'head_info point_up'으로 띄어쓰기로 되어있는데, 이는 띄어쓰기를 기준으로 두 개의 클래스가 붙어 있다고 보면 된다.
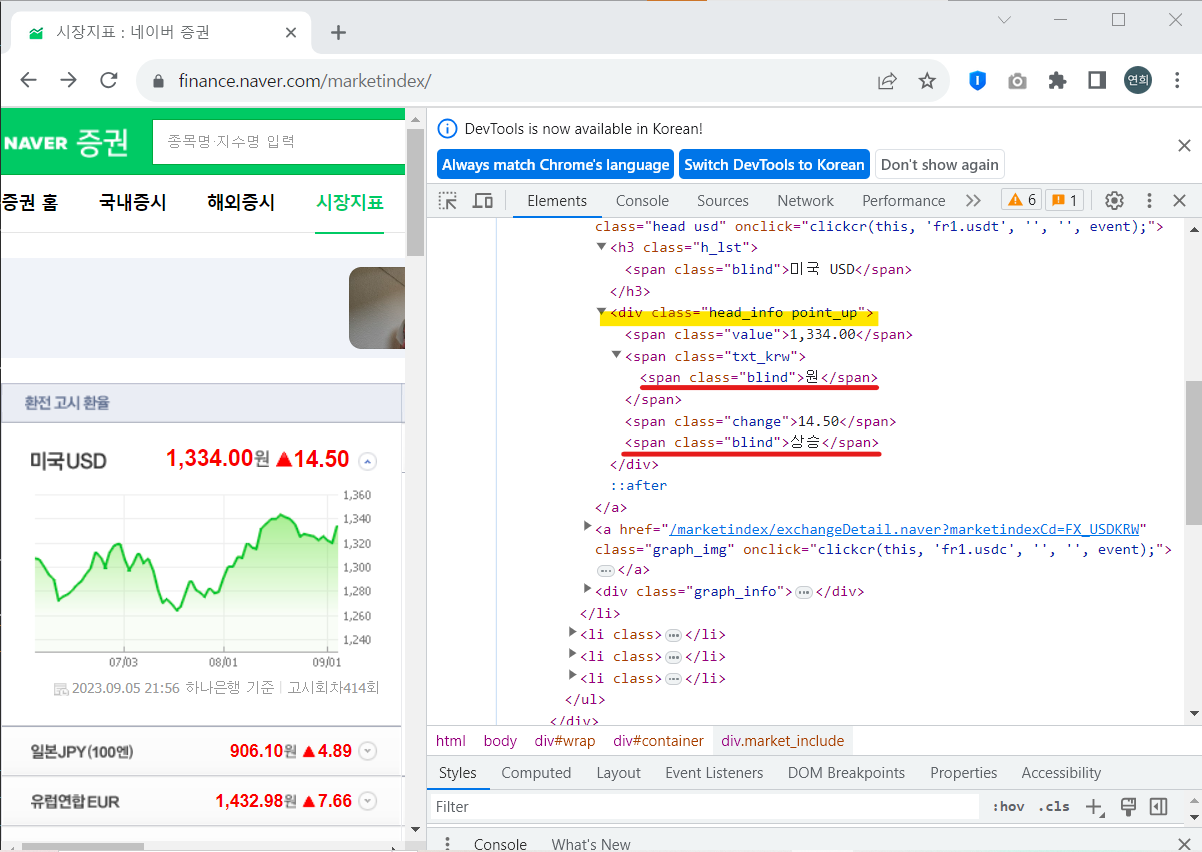
따라서 다음과 같이 상승 데이터를 가져올 수 있다.
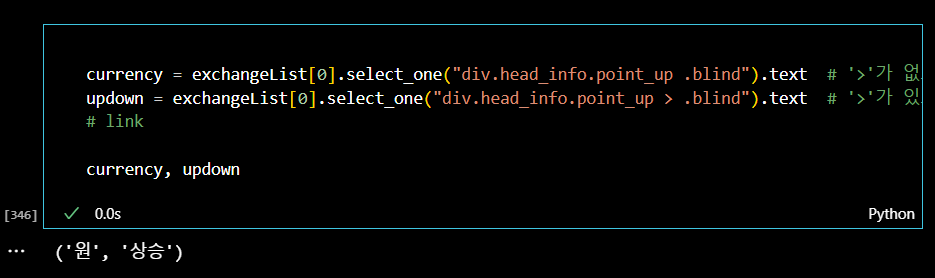
마지막으로 미국 환율 정보를 눌렀을 때 하위페이지로 넘어가는 url 링크주소를 출력해보자.
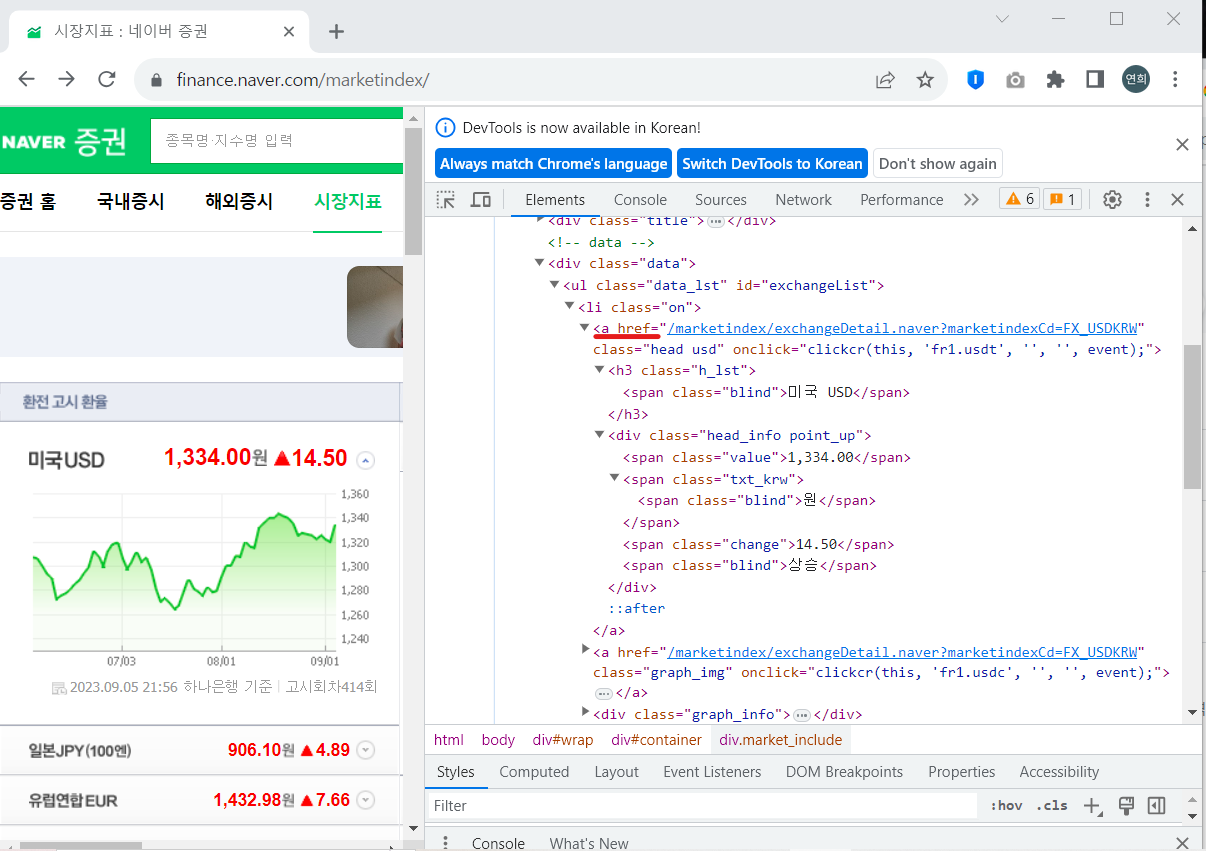
그런데 위의 'a'태그를 확인하면 메인 url은 스킵하고 있다. 따라서 '네이버 증권' 메인 url주소를 따로 변수에 지정해서 연산기능으로 링크주소를 합쳐준다.

미국 환율정보를 불러오는 방법으로 for문을 사용해서 4개 국가의 모든 정보를 불러오자. 각 국가별 데이터는 리스트 안에 담고, 리스트를 딕셔너리 형태로 묶어서 변수에 지정해주었다.
# 4개 데이터 수집
exchange_datas = []
baseUrl = "https://finance.naver.com"
for item in exchangeList:
data = {
"title" : item.select_one(".h_lst").text,
"exchange": item.select_one(".value").text,
"change": item.select_one(".change").text,
"updown": item.select_one(".head_info.point_up > .blind").text,
"link" : baseUrl + item.select_one("a").get("href")
}
exchange_datas.append(data)
exchange_datas # 리스트 안의 딕셔너리 형태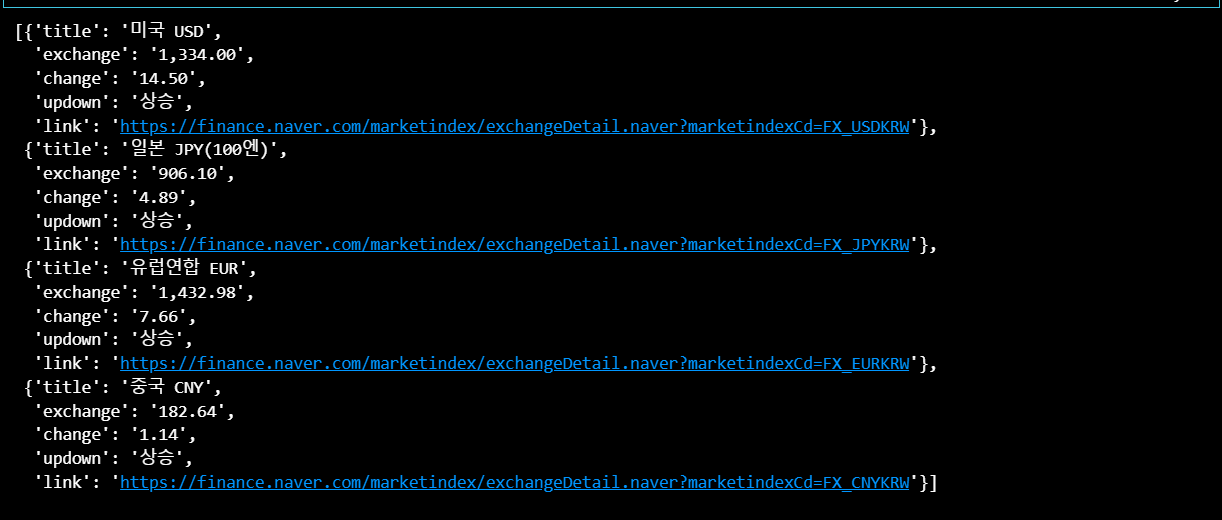
깔끔한 데이터 식별을 위해서 하나의 데이터프레임 안에 넣어주었다.
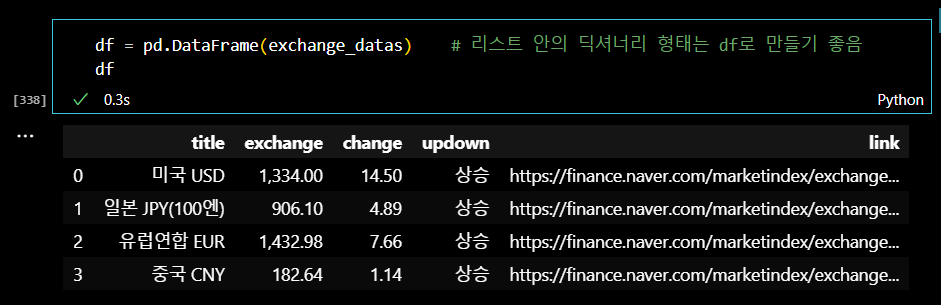
.
.
(3) 예제3. 위키백과 문서정보 가져오기
다음으로 위키백과에 '여명의 눈동자'를 검색해서 주요인물 정보를 가져오자. 먼저, url 정보를 불러와야 하는데, 주소가 한글이 섞여있기 때문에, 코드창에 붙여 넣으면 한글이 깨지게 된다.
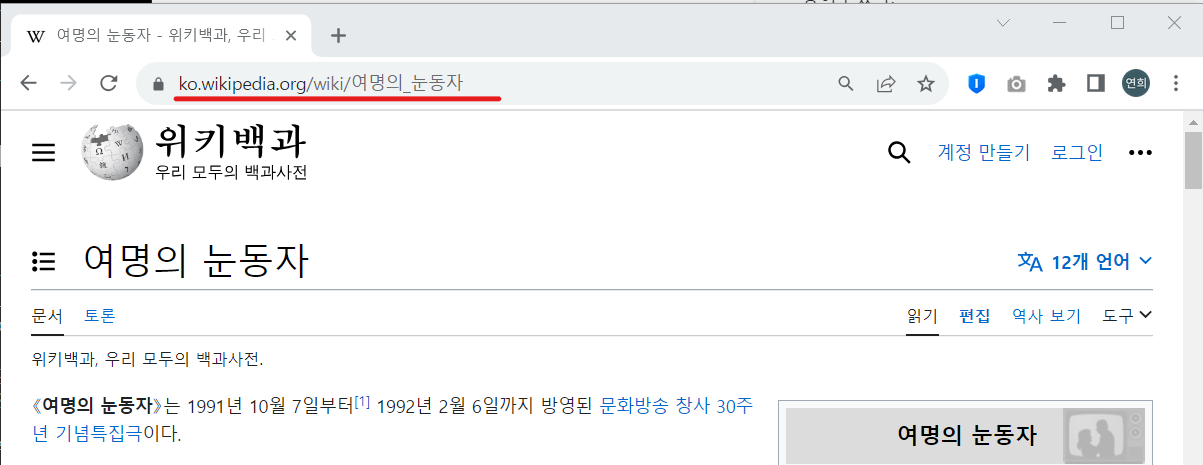
따라서 다음과 같이 인코딩해주는 과정이 필요하다.
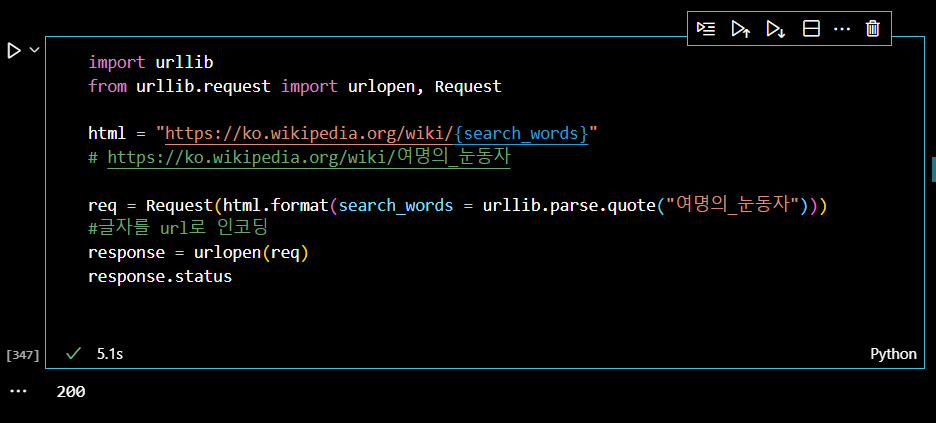
이제 주요인물 정보를 가져와보자. 데이터는 "ul"태그 안에 있다는 것을 개발자 도구를 통해 확인했다.
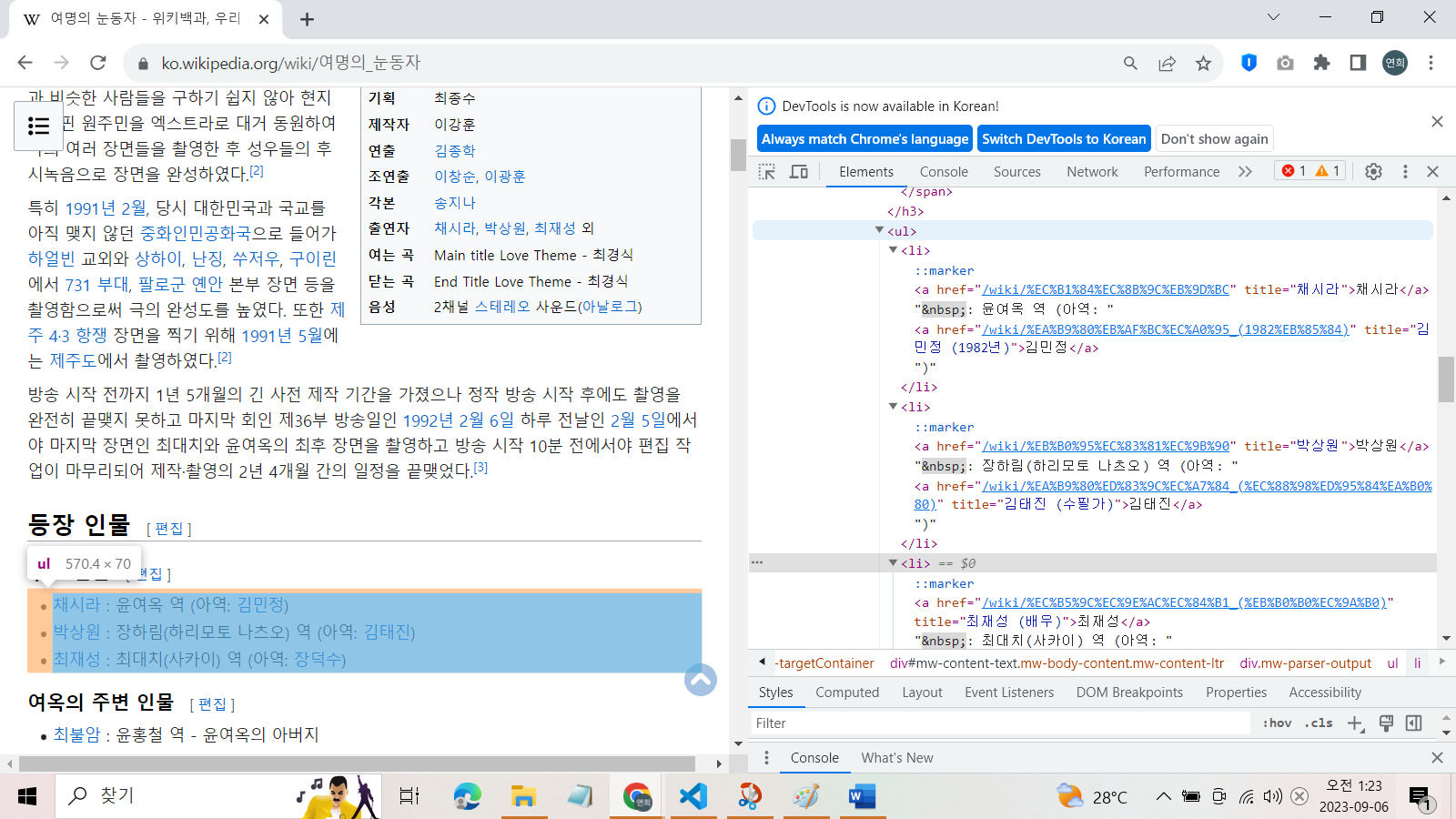
그런데 "ul" 태그만 280개나 있고, 그 안에 있는 데이터 양도 방대하다.

따라서 for문을 이용해서 텍스트 정보만 출력해서 텍스트별로 번호를 매겨서 데이터를 좀 더 쉽게 추출해보자.
n = 0
for each in soup.find_all("ul"):
print("=>" + str(n) + "====================")
print(each.get_text())
n += 1
이마저도 결과가 너무 많아서 새창으로 출력물을 확인해야 했다.
이런 식으로 출력물을 사용할 수 있었으며, 주요인물의 경우, 인덱스 32번에서 확인할 수 있었다.
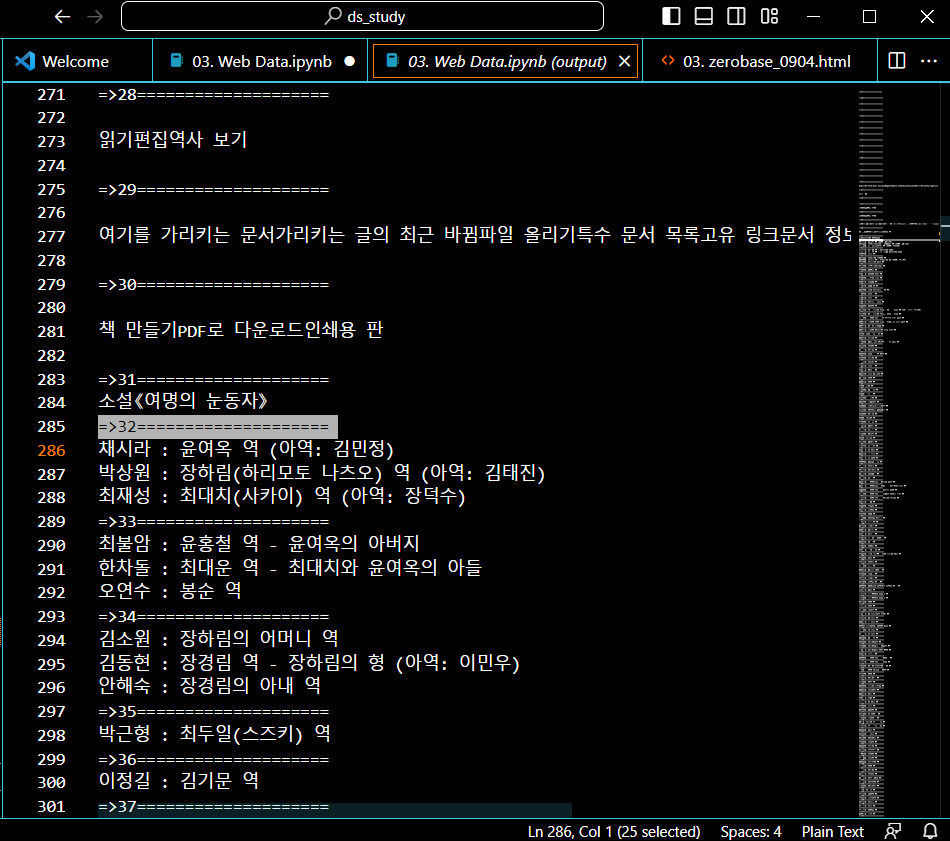
이제 인덱스 번호를 이용해서 데이터를 추출해보자. 같이 딸려오는 html코드는 strip()과 replace()를 이용해서 없애주었다.

이렇게 주요인물 정보를 파싱할 수 있다.
.
.
.
.
2. '시카고 샌드위치 맛집' 웹데이터 분석
이제 <Chicago Magazine> 홈페이지에서 샌드위치 맛집 선정 포스팅을 분석해보자.
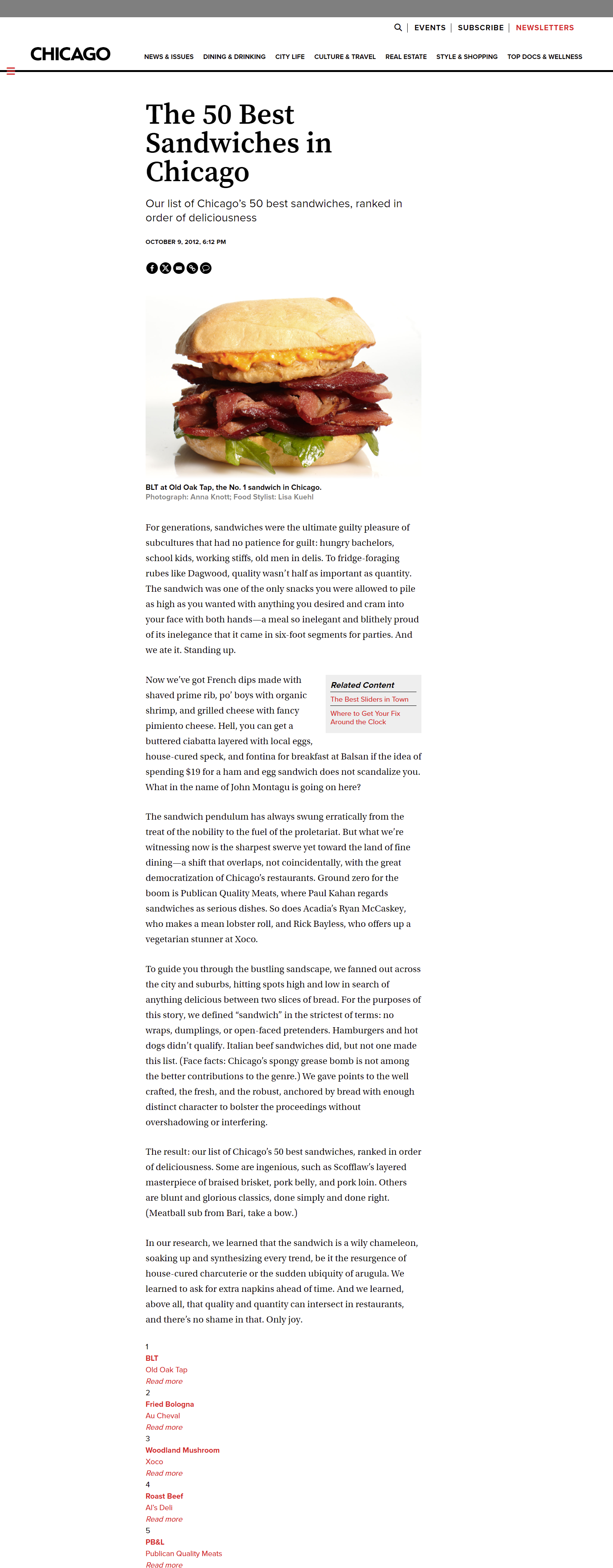
사이트는 다음과 같이 하단에 50개의 맛집 정보를 담고 있는데, 각각 순위, 메뉴, 카페 이름, 주소, 하위 링크를 담고 있다.
(1) 메인 페이지 웹데이터 분석
먼저, 메인 페이지를 통해서 50개 맛집의 순위, 메뉴, 카페 이름, 링크주소를 찾아내자. 분석에 사용할 라이브러리를 불러오고, url 주소를 변수에 지정한다.
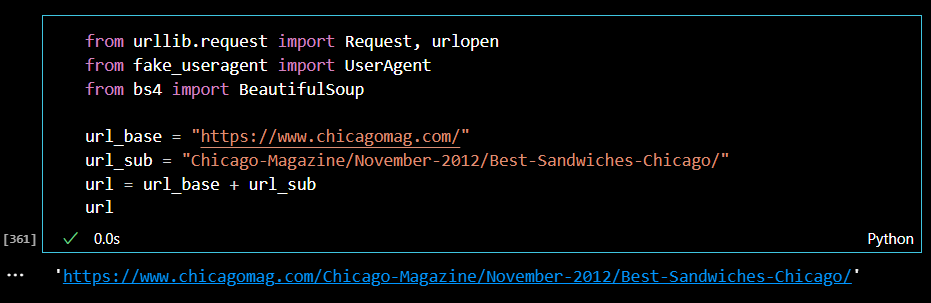
url링크가 잘 열리는지 상태번호를 통해서 확인해본다. 그런데 상태 번호가 403으로 접근이 허용되지 않았다.
response = urlopen(url)
response.status
이때, request() 메서드에, URL주소와 함께, headers로 정상적인 이용자인지 소프트웨어 식별 정보를 확인해 줘야 한다. 간단하게 "Chrome"을 통해서 사용하고 있음을 적어줘도 되고, UserAgent() 메서드로 정보를 확인해줄 수도 있다.
# 방법1
req = Request(url, headers={"User-Agent":"Chrome"}) # 입장 조건
response = urlopen(req)
response.status
# 방법2
ua = UserAgent()
ua.ie
req = Request(url, headers={"User-Agent":ua.ie}) # 입장 조건
response = urlopen(req)
response.status soup 변수에 웹페이지의 html코드도 담아주었다.
soup = BeautifulSoup(response, "html.parser")이제 파싱을 시작해보자.
각 순위들의 정보는 div 태그 안의 class 속성값 'sammy'에 담겨있다.
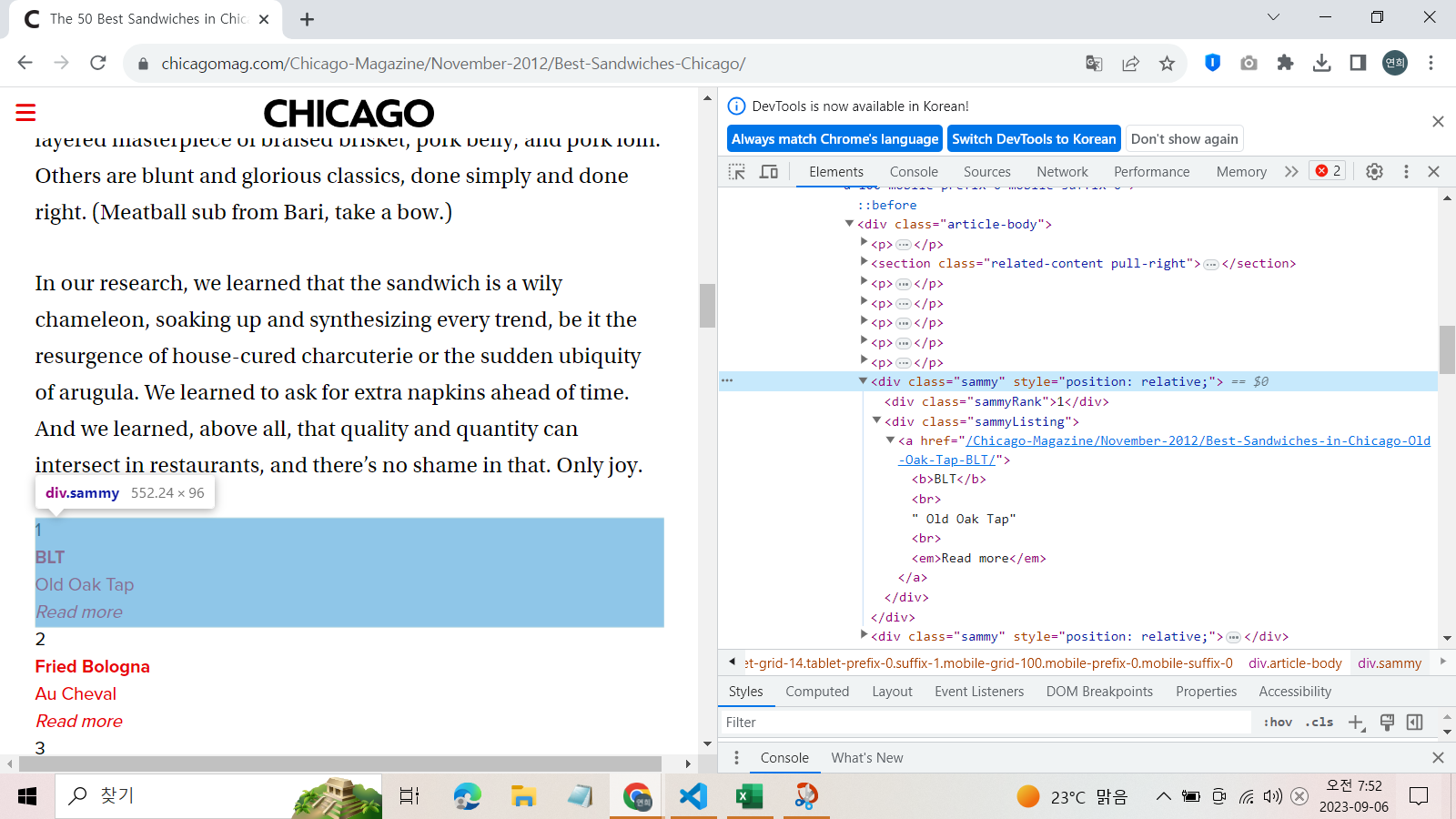
메서드로 태그 정보를 찾았을 때, 리스트 길이가 50개가 맞는지 확인해보자.

인덱스 0번에 저장되어 있는 1순위 맛집의 정보들을 파싱해보았다. 우선, 따로 tmp_one 변수에 지정해주었다.
하위 태그 값을 통해서 파싱할 정보들도 확인했다.
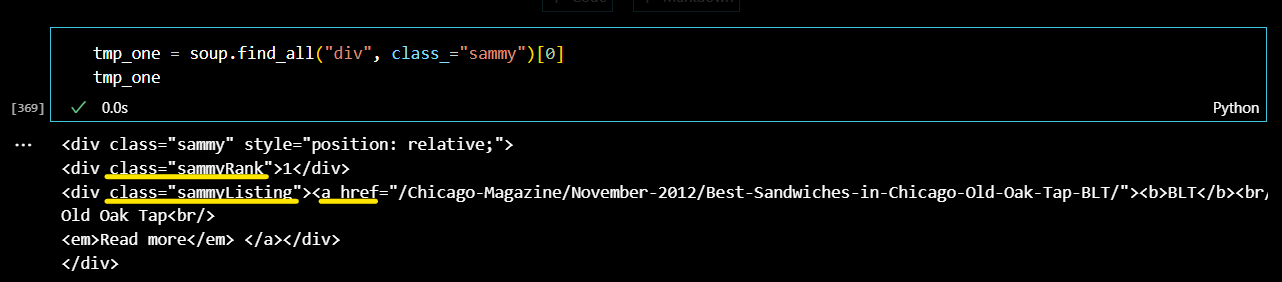
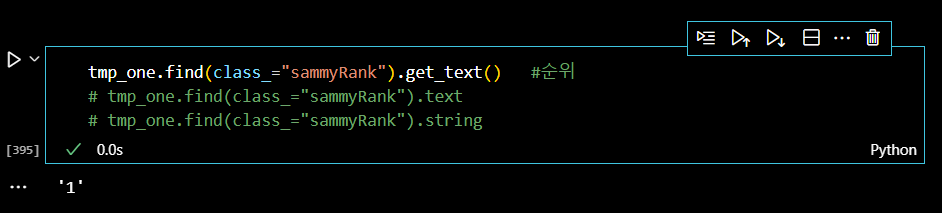
이제 value를 출력해보자! 먼저 순위를 출력한다.
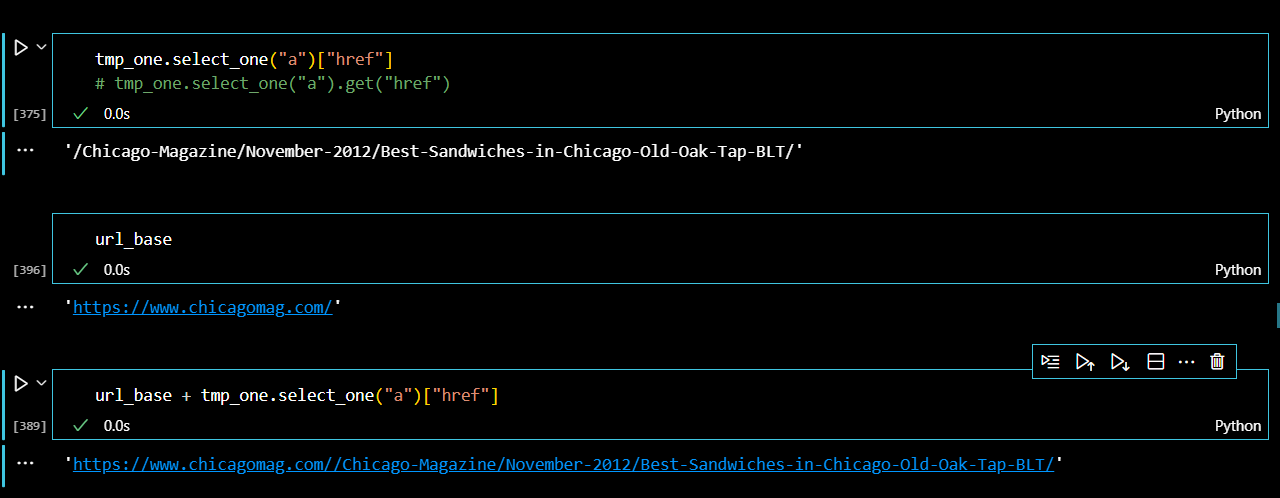
다음으로 링크를 찾아보자. 그런데 보이는 봐야 같이 서브 url주소만 저장되어있기 때문에 맨 처음에 저장했던 메인 url주소를 불러와 연사자로 합쳐주었다.
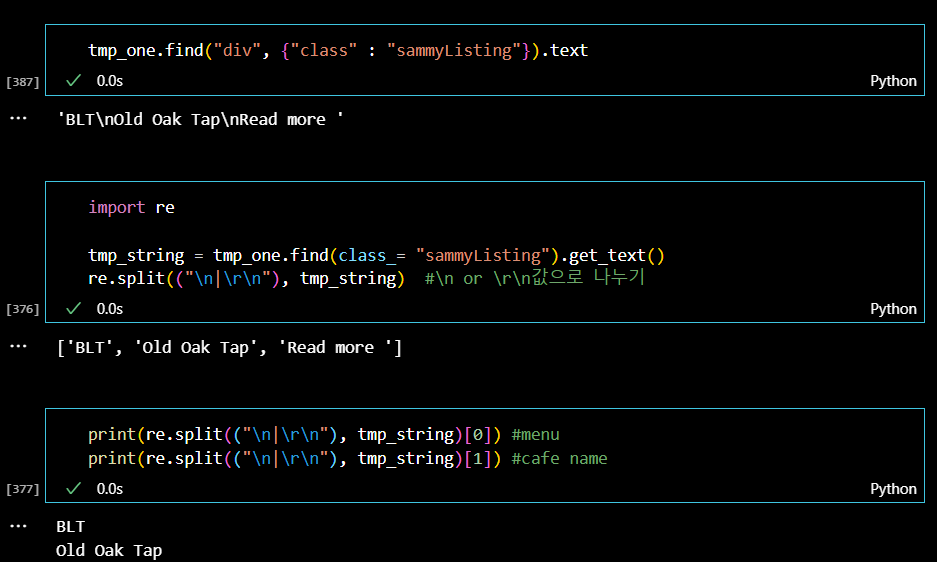
다음으로 메뉴 이름과 가게이름 정보이다. 두 정보는 하나의 클래스 속성값에 같이 저장되어 있으므로 인덱스 번호를 이용해서 값을 찾아주었다. 또한, 텍스트 메서드로 데이터를 찾았음에도 아직 붙어있는 html 코드는 벗겨주었다.
이런 식으로 50개의 맛집 정보를 모두 찾아보자.
반복문을 사용해서 빈 리스트에 각각 담아주었다.
url_base = "https://www.chicagomag.com/"
# 필요한 내용을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu = []
cafe_name = []
url_add = []
list_soup = soup.find_all("div", "sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split(("\n|\r\n"), tmp_string)[0])
cafe_name.append(re.split(("\n|\r\n"), tmp_string)[1])
url_add.append(urljoin(url_base, item.find("a")["href"]))모두 50개의 데이터를 찾았는지 리스트 길이를 확인한다.

이제 리스트를 딕셔너리 형태로 만들어서 다시 dataframe으로 만들어주었다.
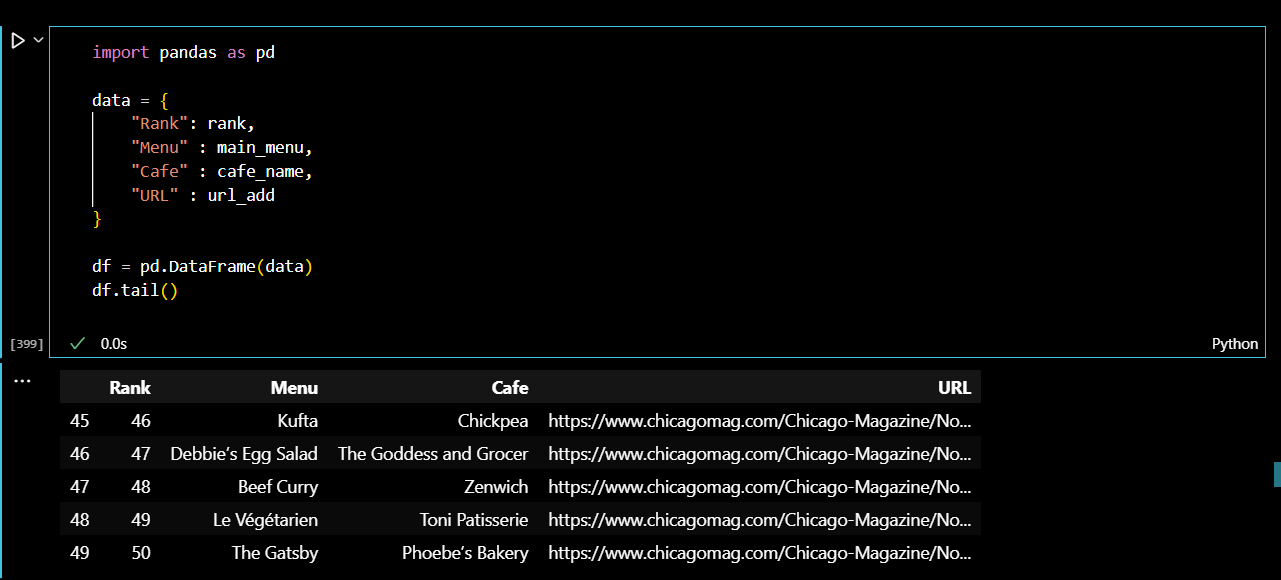
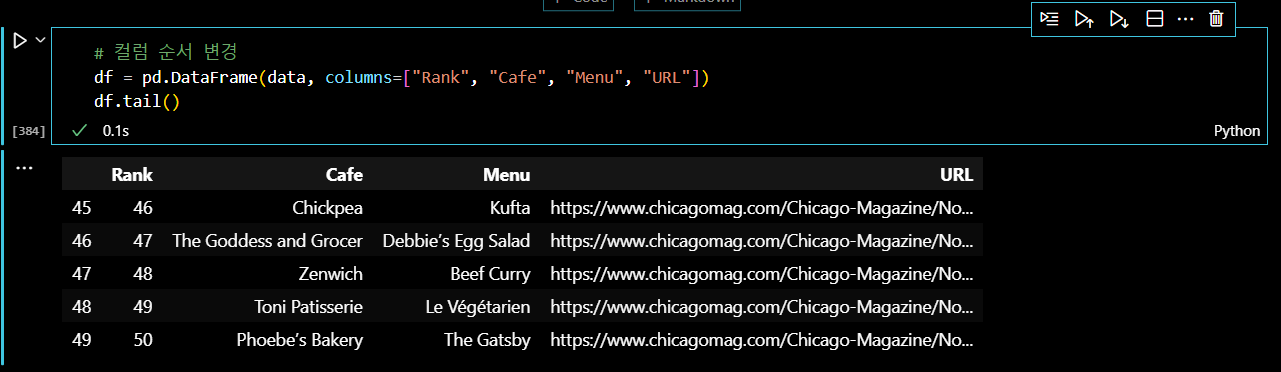
.
.
(2) 하위 페이지 웹데이터 분석
다음으로 각각의 순위를 클릭했을 때 넘어가는 하위 페이지에서 데이터를 크롤링해보자. 하위페이지는 다음과 같으며, 금액과 가게 주소를 확인할 수 있다.
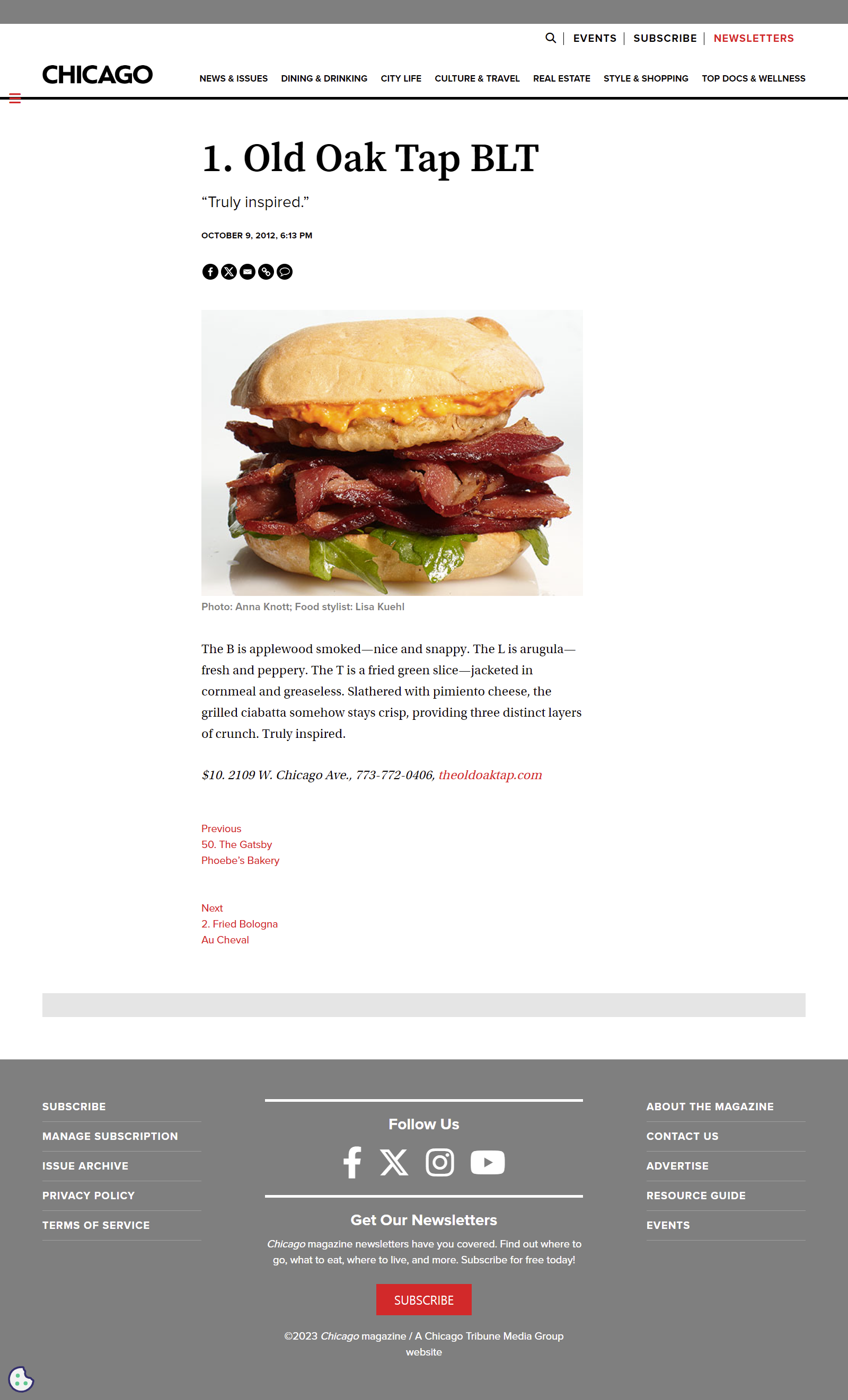
"p"태그의 class 속성값 "addy"에서 정보를 찾을 수 있었다.
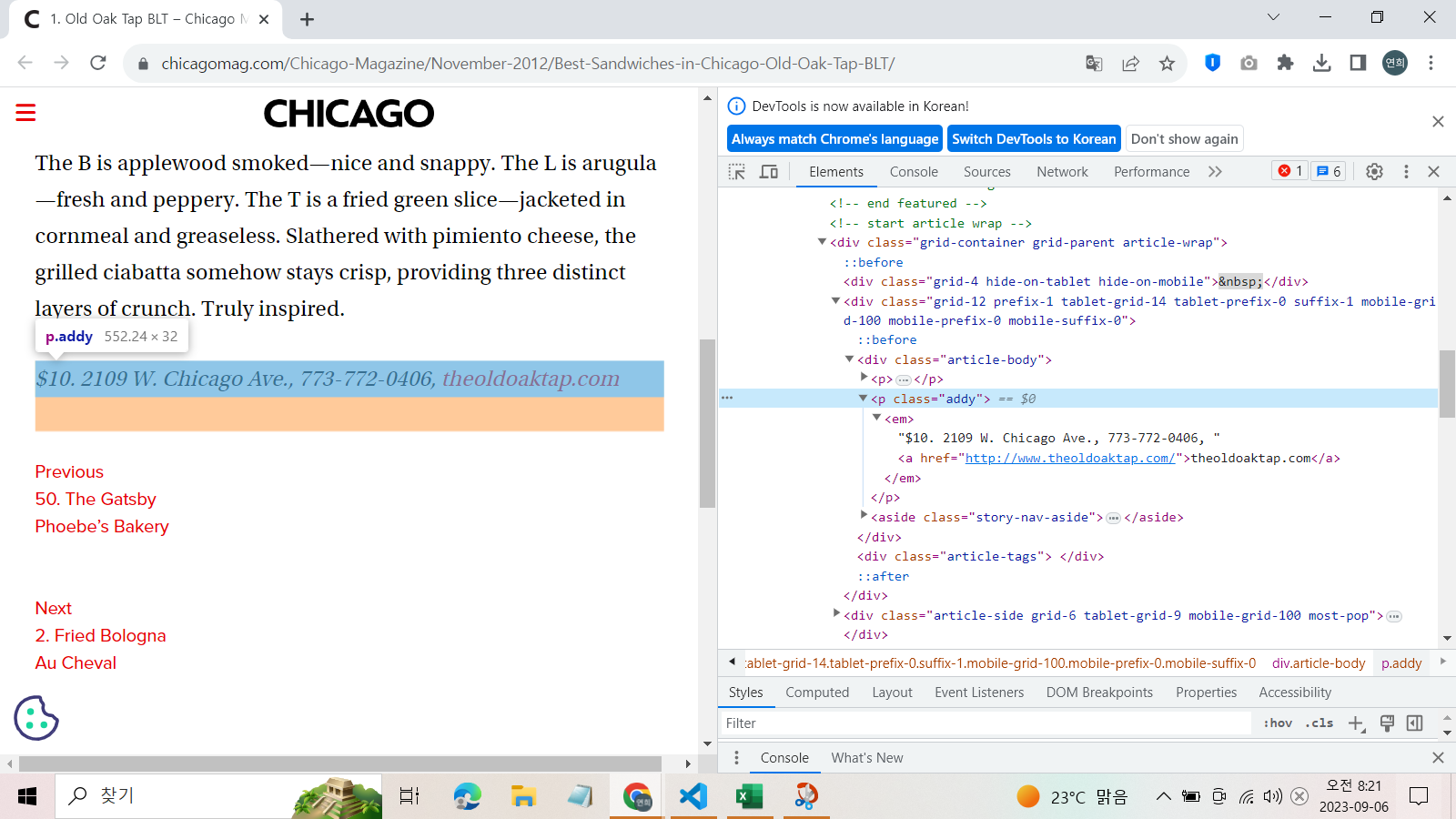
우선 1위 맛집의 메뉴 가격과 주소를 크롤링해보자.
데이터프레임을 사용해서 하위 페이지 URL주소를 변수에 지정한다.
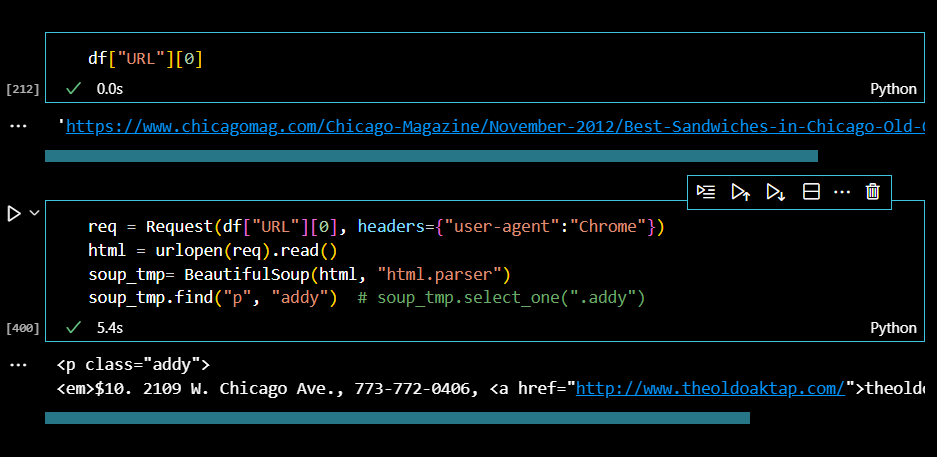
텍스트만 불러와보자.
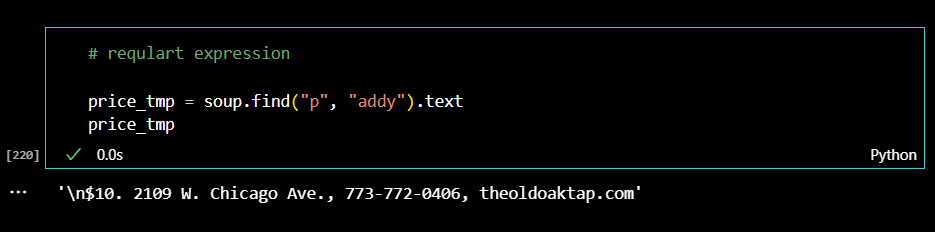
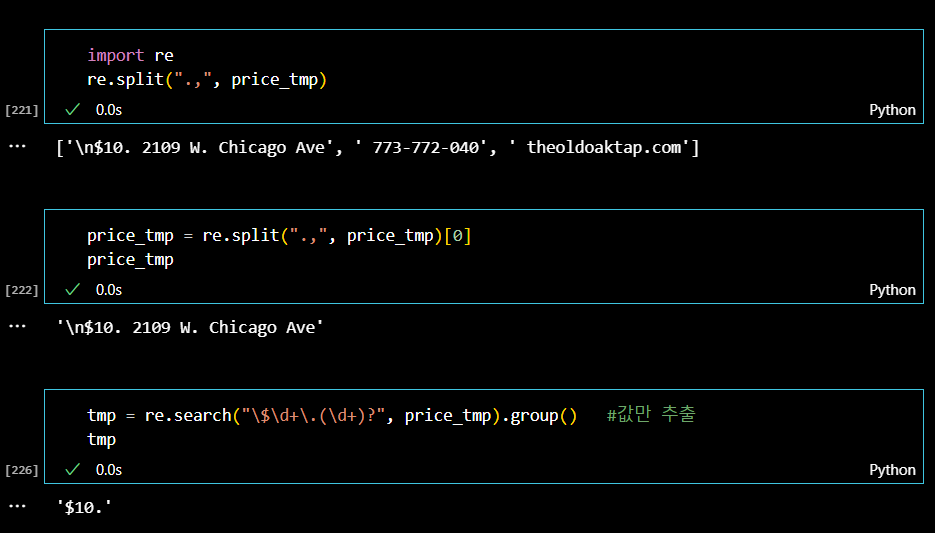
가격과 주소정보가 한꺼번에 있음을 확인했으므로, 리스트 형식으로 데이터를 구분해준다음 regular expression을 활용해서 원하는 정보만 출력해낸다.
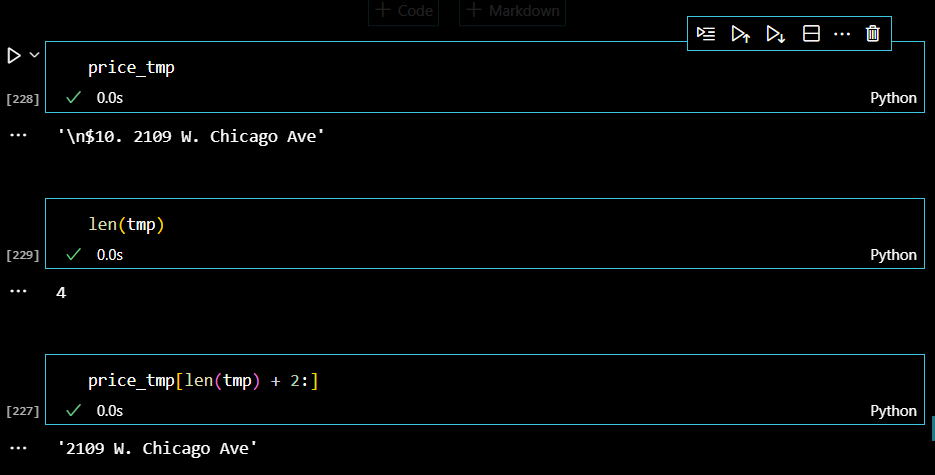
주소정보는 price_tmp변수를 통해서 문자열의 길이를 활용하여 원하는 정보를 출력한다.
이런 식으로 for문을 활용해서 50개 맛집 정보를 모두 찾아보자. 메인페이지와 비슷한 방식으로 모두 리스트에 저장하되, 이번에는 tqdm패키지를 설치한다음 이를 이용했다.
from tqdm import tqdm
price = []
address = []
for index, row in tqdm(df.iterrows()):
req = Request(row["URL"], headers={"user-agent":"Chrome"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
gettings = soup_tmp.find("p", "addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2 :])
print(index)리스트 길이도 확인해보자.

이제 기존의 데이터프레임에 새로운 칼럼을 만들어서 가격과 주소정보를 추가해준다.
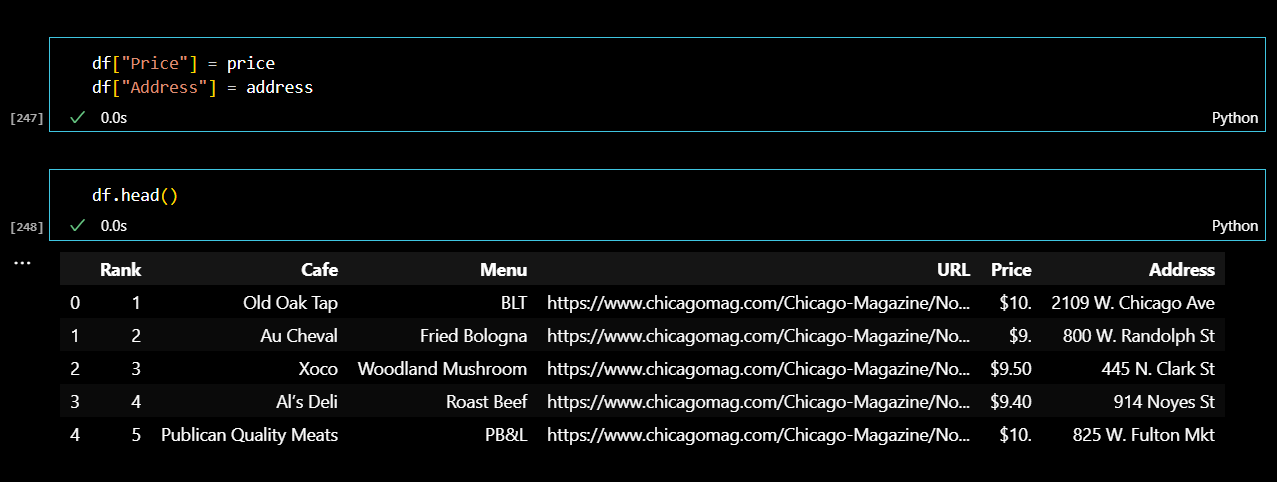
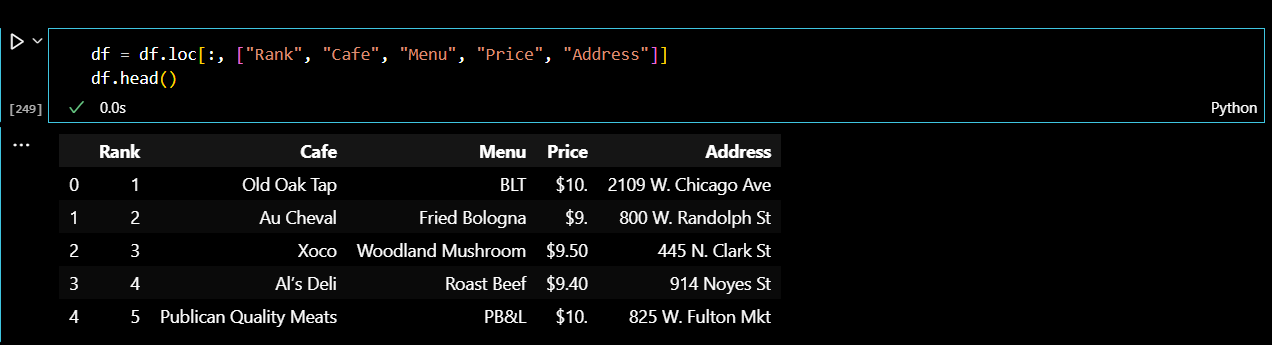
데이터프레임을 조금 수정해주었다. 링크를 주소를 제거한 다음 하위 페이지로 확인할 수 있는 새로운 데이터프레임을 만들어 준다.
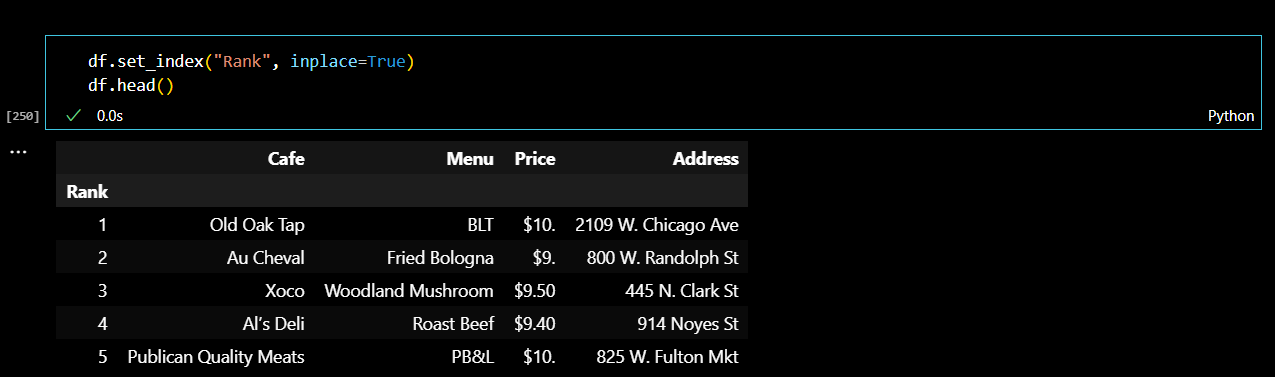
이렇게 하위 페이지까지 웹페이분석을 모두 마쳤다!!
하위페이지를 통해서 각 가게들의 주소까지 확인했으니, 지난 시간에 배운 지도 시각화까지 진행해본다.
.
.
(3) 번외: 지도 시각화
필요한 라이브러리들을 불러와주자.
# requirements
import folium
import pandas as pd
import numpy as np
import googlemaps
from tqdm import tqdm위도와 경도 확인을 위해서 구글 맵스 키값까지 설정해준다.
gmaps_key="(생략)"
gmaps = googlemaps.Client(key=gmaps_key)50개 가게들의 위도와 경도 정보를 for문을 이용해서 리스트에 저장한다.
lat = []
lng = []
for idx, row in tqdm(df.iterrows()):
if not row["Address"] == "Multiple location":
target_name = row["Address"] + ", " + "Chicago"
# print(target_name)
gmaps_output = gmaps.geocode(target_name)
location_output = (gmaps_output[0].get("geometry"))
lat.append(location_output["location"]["lat"])
lng.append(location_output["location"]["lng"])
else:
lat.append(np.nan)
lng.append(np.nan)리스트 길이가 50이 맞는지 확인해주자.

데이터프레임에 위도와 경도 컬럼을 추가해주었다.
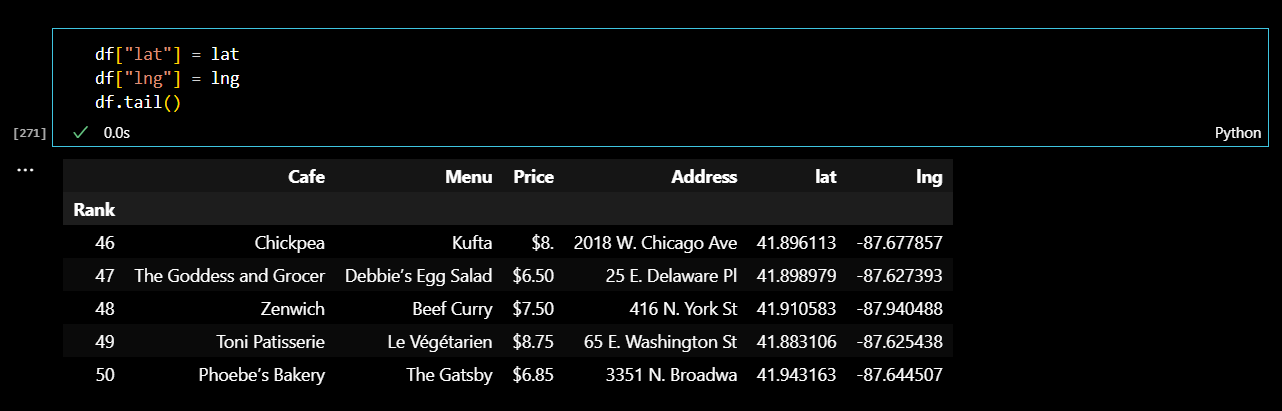
먼저, 시카고 지도를 그려보자.
mapping = folium.Map(location=[41.8781136, -87.6297982], zoon_start=11)
mapping
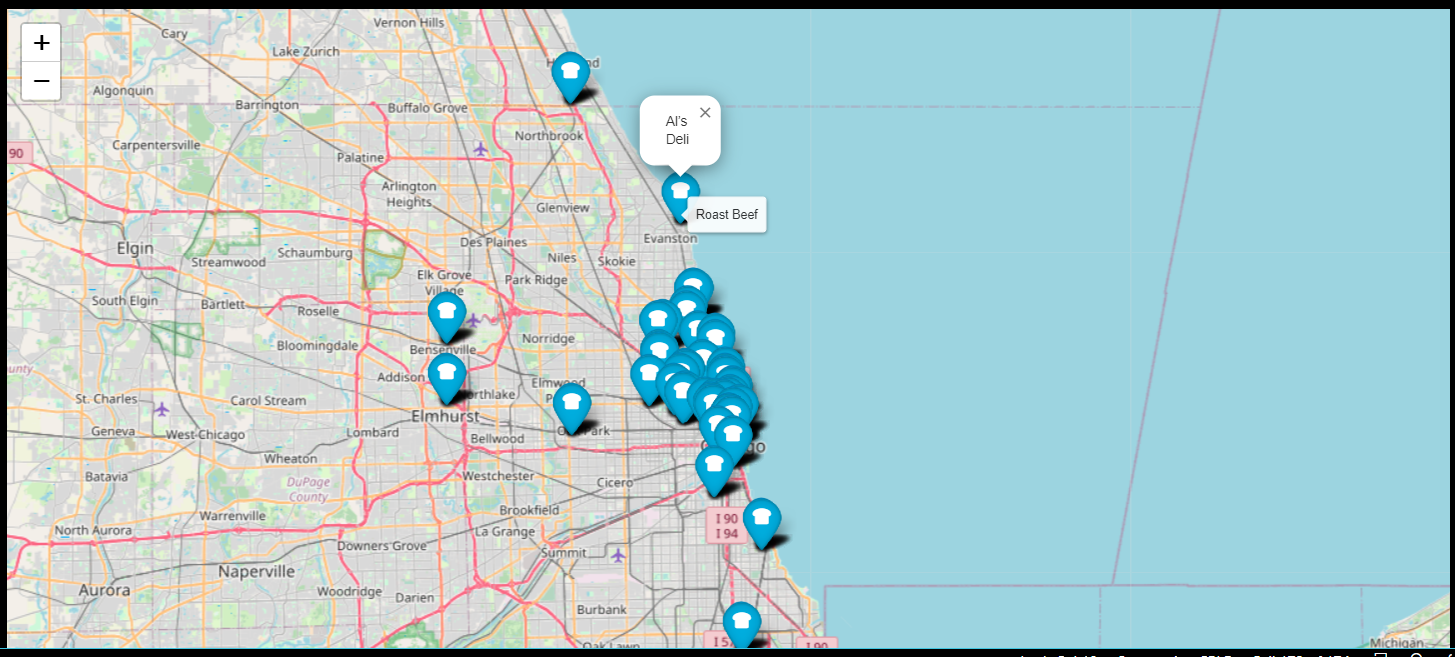
지도 위에 마커를 찍고, 팝업과 툴팁기능으로 각각 카페이름과 메뉴를 확인할 수 있게 해주었다. 마지막으로 마커 아이콘까지 커스텀해주었다.
for idx, row in df.iterrows():
if not row["Address"] == "Multiple location":
folium.Marker(
location=[row["lat"], row["lng"]],
popup = row["Cafe"],
tooltip = row["Menu"],
icon = folium.Icon(
icon="bread-slice",
prefix = "fa"
)
).add_to(mapping)
mapping