Chapter
1. Naver API
(1) 등록
(2) 사용하기
(3) 실습 예제: '몰스킨' 데이터 정리하고 시각화하기
1. Naver API
(1) 등록
우선 '네이버 개발자센터(Naver Developers)'로 들어간다. 그 뒤 하단에 '서비스 API'선택한 후, '오픈 API 이용 신청'으로 들어간다.(https://developers.naver.com/apps/#/wizard/register)
계정등록까지 마치면 '애플리케이션 등록'으로 사용할 이름과 사용API까지 선택해주면 Client ID, Client Secret을 받을 수 있다.
이번 강의에서는 '검색 API'을 이용해서 데이터를 추출해오는 작업을 했다.
.
.
(2) 사용하기
jupyter notebook으로 코드 사용하기 위해서 네이버 개발자센터에서 제공해주는 코드를 가져왔다.
(naver developers > Documents > 서비스 API > 검색 > 검색 API 블로그 검색 구현 예제 >Python)
블로그에서 '파이썬'을 검색해보자.

다음과 같이 제공받은 코드를 통해 제공받은 client_id, client_secret을 입력하고, quot()안에 검색어를 입력해주면 된다.
이때, 네이버 블로그에서 검색되는 것이므로 url주소를 blog로 작성해주면 검색결과를 얻을 수 있다.
만약 네이버 책, 네이버 쇼핑 등에서 검색을 하고 싶다면 url주소를 바꿔서 입력해준다.


.
.
.
(3) 실습 예제: '몰스킨' 검색결과 데이터 정리하고 시각화하기
'네이버 쇼핑'에서 '몰스킨'을 검색한 결과물을 정리하여 시각화해보자.
1) url 주소 생성 함수 만들기
함수를 직접 만들어서 검색출력 시작위치와 출력 갯수를 설정한 후, url주소 만들기
앞에서 만든 url주소 형식을 만들기 위해, 변수로 구조적으로 분해해서 함수를 만든다.
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp만약
gen_search_url("shop","TEST", 10, 3)다음과 같은 함수를 입력하면 네이버쇼핑에서 'TEST'라는 값을 검색해서 10번 부터 3개의 항목을 출력하는 url을 만들게 된다.

2) get_reult_onpage()
앞에서 만든 url주소를 urllib패키지를 통해 페이지 정보를 불러와 분석할 수 있는 환경을 만든다. 이때 불러온 json파일은 한글로 디코딩까지 해준다.
import json
import datetime
def get_result_onpage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Reques Success" % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))참고로 datetime.datetime.now() 매서드는 현재날짜와 시간을 반영해준다.
첫 번째 함수로 만든 url주소로 get_result_onpage()함수값을 가져오면 다음과 같아진다. 검색 결과가 길어서 생략했지만 5개의 판매 품목 데이터가 변수 안에 지정된다.
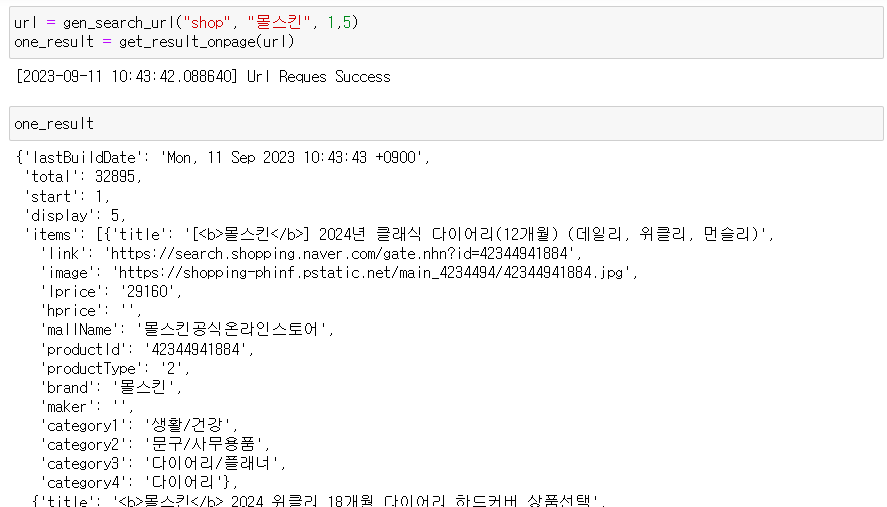
여기서 첫번째 품목 정보를 살펴보면 다음과 같다.

이걸 이용해서 판매 품목 제목(title), 판매 링크(link), 판매가(lprice), 쇼핑몰 이름(mallName)을 가져올 수 있다.

3) 검색 데이터를 이용해 데이터프레임 생성 함수 만들기
이제 방금 확인한 품목 결과별 데이터(title, link, lprice, mallName)를 이용해서 데이터 프레임을 만든다.
import pandas as pd
def get_fields(json_data):
title = [each["title"] for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mallName = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title" : title,
"link" : link,
"lprice" :lprice,
"mall" : mallName
}, columns=["title", "lprice", "link", "mall"])
return result_pd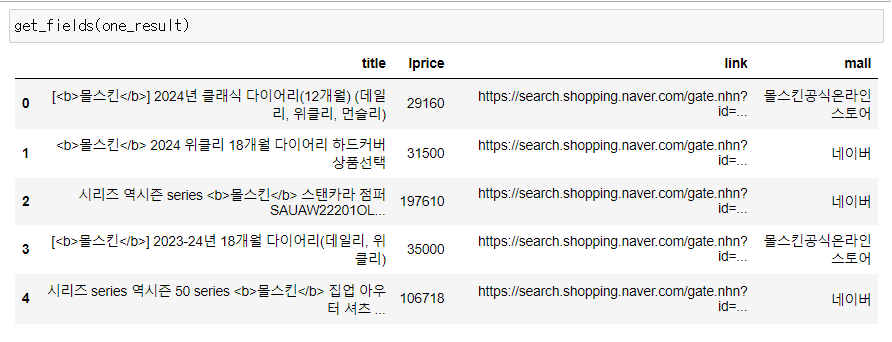
4) title에 남아있는 html코드 제거하는 함수 만들기
그런데 만들어진 함수의 'title'컬럼을 확인하면 아직 html코드가 남아있는 것을 확인할 수 있다.
이를 제거하는 함수를 만들어서 깔끔하게 정리한다.
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>","")
return input_str이렇게 만든 함수를 다시 앞에서 만든 get_fields() 함수의 title 변수 할당 코드에 넣어준다.
import pandas as pd
def get_fields(json_data):
title = [delete_tag(each["title"]) for each in json_data["items"]]
link = [each["link"] for each in json_data["items"]]
lprice = [each["lprice"] for each in json_data["items"]]
mallName = [each["mallName"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title" : title,
"link" : link,
"lprice" :lprice,
"mall" : mallName
}, columns=["title", "lprice", "link", "mall"])
return result_pd데이터프레임이 깔끔해진 것을 확인할 수 있다.
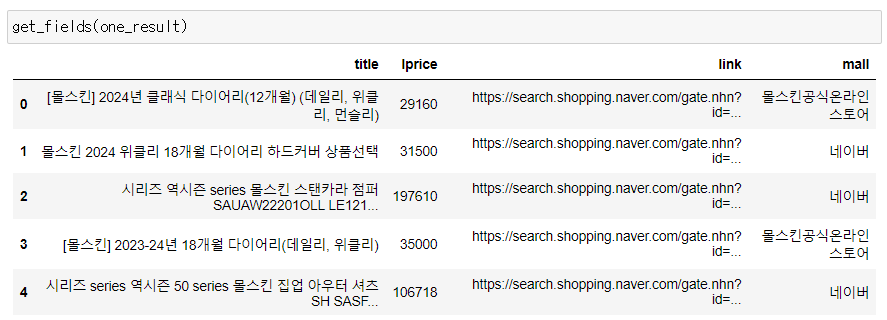
5) 1000개의 검색 결과 데이터프레임으로 저장한 후 다듬기
이제 1000개의 '몰스킨'검색 결과물을 데이터프레임으로 저장해보자. 이때 주의할 점은 검색결과를 출력할 수 있는 수의 한계가 있기 때문에 100개씩 나눠서 출력해야 한다는 것이다.
그런데 맨처음 만든 get_search_url()함수를 사용할때 start_num을 1, disp_num을 100으로 10번 반복하면 계속 첫번째 검색 결과부터 100개만 10번 출력되는 결과를 낳게 된다.
따라서 start_num을 1,101,201,...으로 바꿔서 10번 실행할 필요가 있다. 반복문(for문)을 사용해서 코드를 간단하게 해결해보자.
result_mol = []
for n in range(1,1000,100):
url = gen_search_url("shop", "몰스킨", n, 100)
json_result = get_result_onpage(url)
pd_result = get_fields(json_result)
result_mol.append(pd_result)
result_mol=pd.concat(result_mol)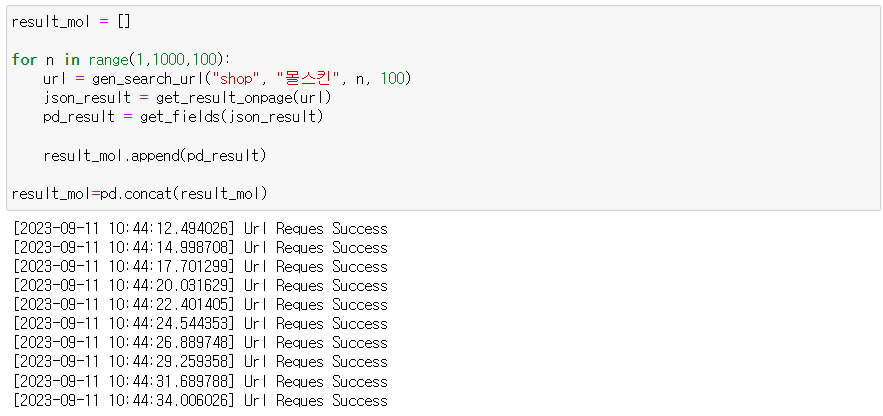
정상적으로 완료되었다.
그런데 저장된 데이터프레임의 개요를 확인했더니, 10번 출력된 데이터프레임을 단지 이어붙이기 해서 index가 0-99개를 계속 반복한 결과를 낳았으며, lprice또한 object형으로 저장되어 있다.
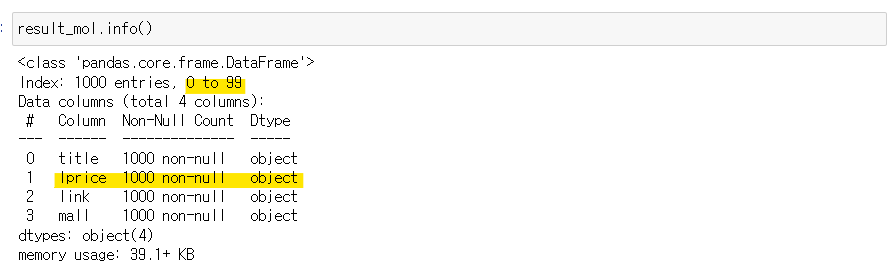
인덱스로 재설정해주고, 'lprice'컬럼의 type도 변경해준다.
result_mol.reset_index(drop=True, inplace=True)
result_mol["lprice"] = result_mol["lprice"].astype("float")6) 엑셀 파일로 저장하기
이제 검색 데이터를 모두 정리했다!
데이터를 엑셀 파일로도 정리해보자.
먼저 사용할 xlswriter패키지를 설치해준다.
pip install xlsxwriter그런 다음 원하는 엑셀 시트로 커스텀 해준다음 파일을 저장해주었다.
writer = pd.ExcelWriter("..\\data\\06. molskin_diary_in_naver_shop.xlsx", engine="xlsxwriter")
result_mol.to_excel(writer, sheet_name="Sheet1")
workbook = writer.book
worksheet = writer.sheets["Sheet1"]
worksheet.set_column("A:A", 4) # 4:간격
worksheet.set_column("B:B", 60)
worksheet.set_column("C:C", 10)
worksheet.set_column("D:D", 10)
worksheet.set_column("E:E", 50)
worksheet.set_column("F:F", 10)
worksheet.conditional_format("C2:C1001", {"type":"3_color_scale"}) # C컬럼의 크기에 따라 색 변경
writer.close()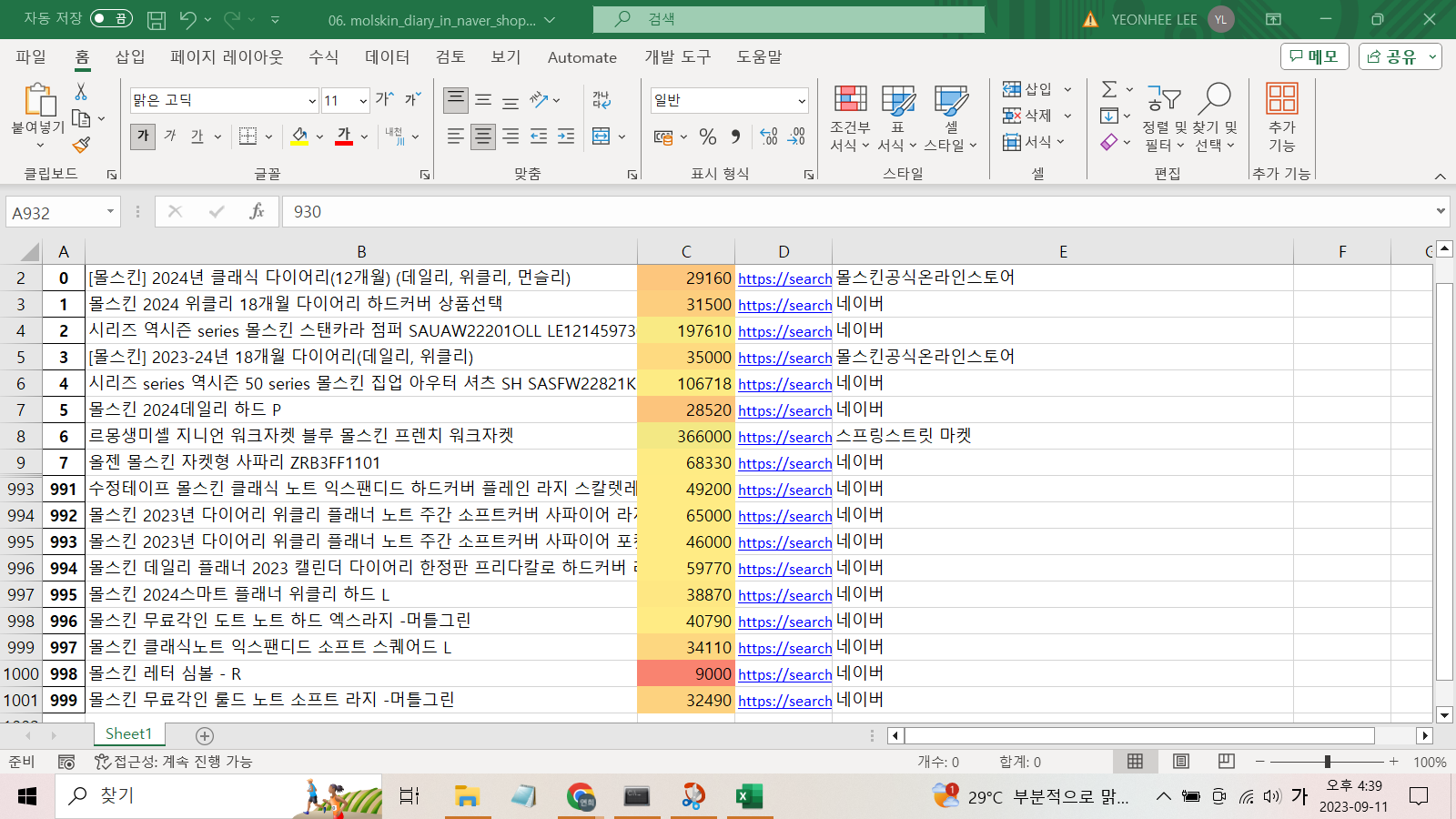
다음과 같은 엑셀 파일을 만들 수 있다. 이때 'lprice'가 저장된 C컬럼은 가격 크기에 따라 셀의 색깔이 달리하는 함수를 사용했다. (중간 데이터는 생략된 상태)
7) 시각화
마지막으로 그래프로 시각화를 해본다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15,6))
sns.countplot(
data=result_mol,
x = result_mol["mall"],
palette="RdYlGn",
order = result_mol["mall"].value_counts().index
)
plt.xticks(rotation=90) #xlabel을 90도 회전함
plt.show()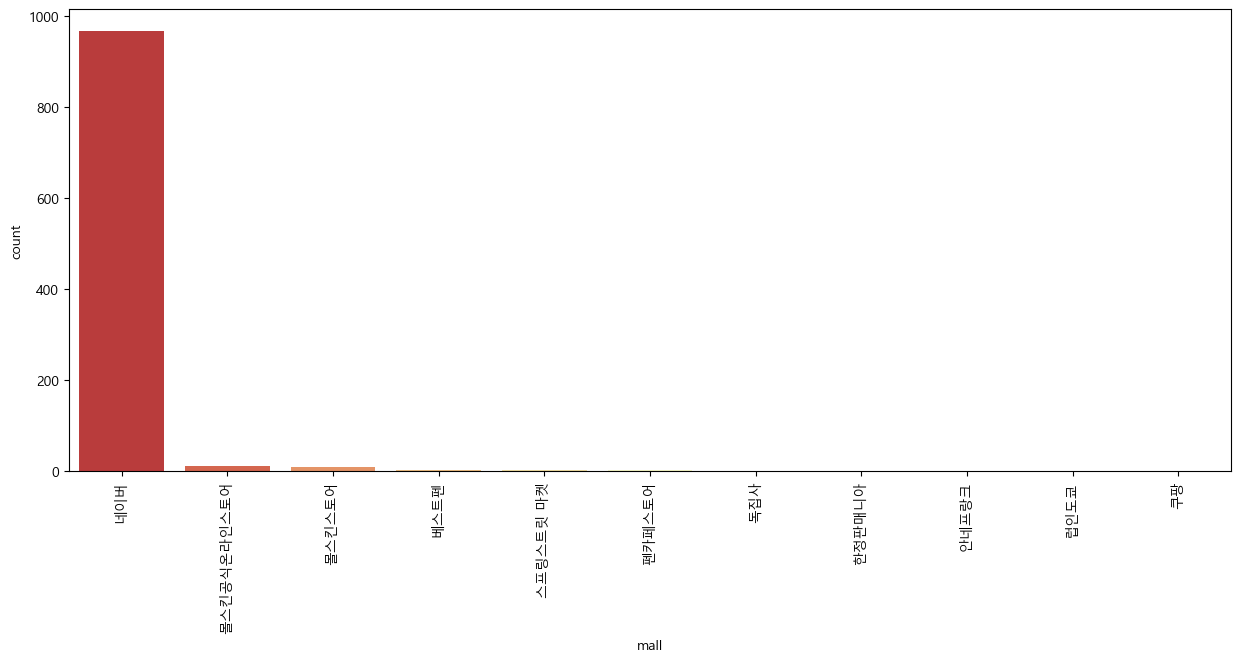
판매처의 개수가 '네이버'가 압도적으로 우위를 점하고, 다음으로는 '몰스킨공식온라인스토어', '몰스킨스토어' 등의 사이트가 몰스킨을 많이 판다는 것을 확인할 수 있다.
