[030] 테이블 병합·결합(UNION, JOIN)과 기타 데이터 조회(CONCAT, ALIAS, DISTINCT, LIMIT) / SQL 기초 -④
CHAPTER
1. 데이터 병합 및 결합
(1) UNION
(2) JOIN
2. 기타 데이터 조회 방법
(1) CONCAT
(2) ALIAS
(3) DISTINCT
(4) LIMIT
1. 데이터 병합 및 결합
(1) UNION
UNION은 여러 개의 SQL문을 합쳐서 하나의 SQL문으로 만들어주는 방법이다.
이때 주의해야할 점은 컬럼의 개수가 같아야 한다는 것이다.
UNION 문법에도 두 가지 종류가 있는데, 중복값의 출력 여부에 따라 다음과 같이 나뉜다.
- UNION: 중복된 값을 제거하여 알려준다.
- UNION ALL: 중복된 값도 모두 보여준다.
SELECT column1, column2, ... FROM tableA
UNION | UNION ALL
SELECT column1, column2, ... FROM tableB;두 개의 테스트용 테이블 생성해서 두 가지 문법의 차이 점을 확인해 보자.
# 테이블 생성
CREATE TABLE test1
(
no int
);
CREATE TABLE test2
(
no int
);
# 데이터 삽입
INSERT INTO test1 VALUES (1);
INSERT INTO test1 VALUES (2);
INSERT INTO test1 VALUES (3);
INSERT INTO test2 VALUES (5);
INSERT INTO test2 VALUES (6);
INSERT INTO test2 VALUES (3);
# 확인
SELECT * FROM test1;
SELECT * FROM test2;
- test1의 모든 데이터와 test2의 모든 데이터를 중복된 값을 포함하여 검색
SELECT * FROM test1
UNION ALL
SELECT * FROM test2;
- test1의 모든 데이터와 test2의 모든 데이터를 중복된 값을 제거하여 검색
SELECT * FROM test1
UNION
SELECT * FROM test2;
이번에는 지난 시간에 만든 'celeb' 테이블을 사용해서 몇 가지 예제를 확인해본다.

- 성별이 여자인 데이터를 검색하는 쿼리와 소속사가 YG엔터테인먼트인 데이터를 검색하는 쿼리를 UNION ALL로 실행
SELECT name, sex, agency FROM celeb WHERE sex='F'
UNION ALL
SELECT name, sex, agency FROM celeb WHERE agency='YG엔터테인먼트';'UNION ALL'을 사용했기 때문에 두 쿼리에 공통되는 '이수현'데이터가 중복되었다.

- 성별이 여자인 데이터를 검색하는 쿼리와 소속사가 YG엔터테인먼트인 데이터를 검색하는 쿼리를 UNION으로 실행
SELECT name, sex, agency FROM celeb WHERE sex='F'
UNION
SELECT name, sex, agency FROM celeb WHERE agency='YG엔터테인먼트';
- 가수가 직업인 연예인의 이름,직업을 검색하는 쿼리와, 1980년대에 태어난 연예인의 이름,생년월일, 나이를 검색하는 쿼리를 UNION으로 실행
SELECT name, job_title FROM celeb WHERE job_title LIKE '%가수%'
UNION
SELECT name, birthday, age FROM celeb WHERE birthday BETWEEN '1980-01-01' AND '1980-12-31';그런데 두 쿼리의 컬럼의 개수가 다르기 때문에 에러가 발생했다.

그래서 두 번째 쿼리의 'age'컬럼을 제거해서 두 쿼리의 개수를 맞춰주었다.
SELECT name, job_title FROM celeb WHERE job_title LIKE '%가수%'
UNION
SELECT name, birthday FROM celeb WHERE birthday BETWEEN '1980-01-01' AND '1980-12-31';
.
.
.
.
(2). JOIN
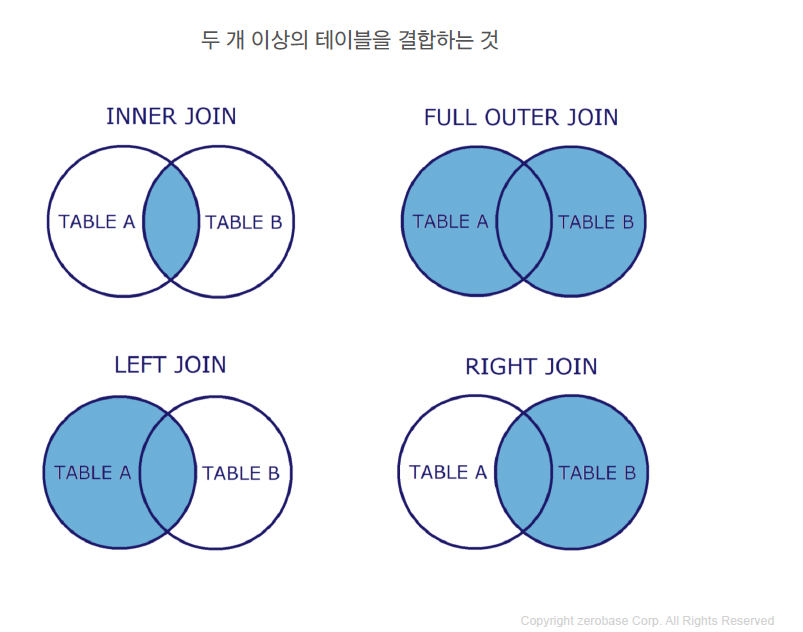
join은 두 테이블을 결합하는 것을 말한다. 합치는 방법에 따라 5가지가 있다.
그 전에 'celeb'테이블과 함께 실습한 'snl_show'테이블을 만들어 주었다. 테이블은 방송출연자와 그 정보를 담았다.
# 테이블 생성
CREATE TABLE snl_show
(
ID int NOT NULL AUTO_INCREMENT PRIMAEY KEY,
SEASON int NOT NULL,
EPISODE int NOT NULL,
BROADCAST_DATE date,
HOST varchar(32) NOT NULL
);
# 확인
DESC snl_show;
# 데이터 삽입
INSERT INTO snl_show VALUES (1, 8, 7, '2020-09-05', '강동원');
INSERT INTO snl_show VALUES (2, 8, 8, '2020-09-12', '유재석');
INSERT INTO snl_show VALUES (3, 8, 9, '2020-09-19', '차승원');
INSERT INTO snl_show VALUES (4, 8, 10, '2020-09-26', '이수현');
INSERT INTO snl_show VALUES (5, 9, 1, '2021-09-04', '이병현');
INSERT INTO snl_show VALUES (6, 9, 2, '2021-09-11', '하지원');
INSERT INTO snl_show VALUES (7, 9, 3, '2021-09-18', '제시');
INSERT INTO snl_show VALUES (8, 9, 4, '2021-09-25', '조정석');
INSERT INTO snl_show VALUES (9, 9, 5, '2021-10-02', '조여정');
INSERT INTO snl_show VALUES (10, 9, 6, '2021-10-09', '옥주현');
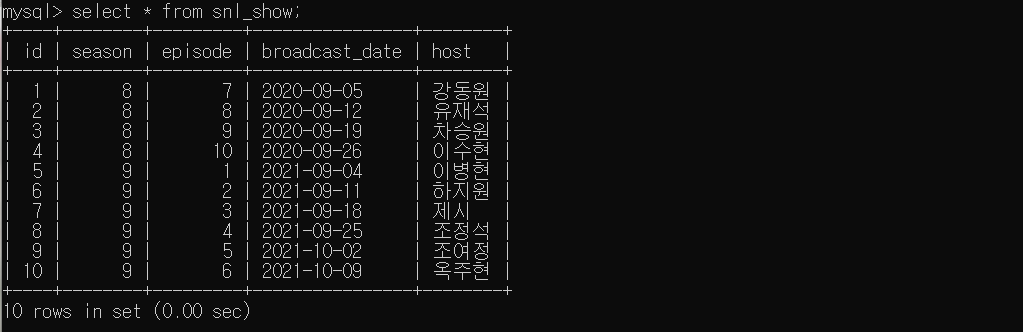
# 확인
SELECT * FROM snl_show;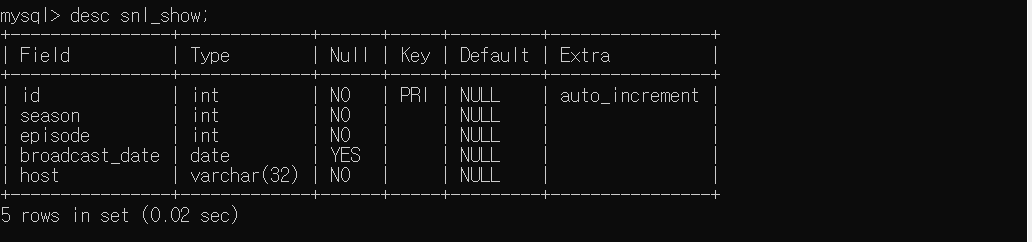
이제 join의 종류를 'celeb'테이블과 함께 예시를 확인해 보면서 익혀보자.

1) INNER JOIN
INNER JOIN은 두 개의 테이블에서 공통된 요소들을 통해 결합하는 조인방식이다. 기본 문법을 살펴본 다음, 예제를 확인해보자.
SELECT col1, col2, ...
FROM tableA
INNER JOIN tableB
ON tableA.column = tableB.column
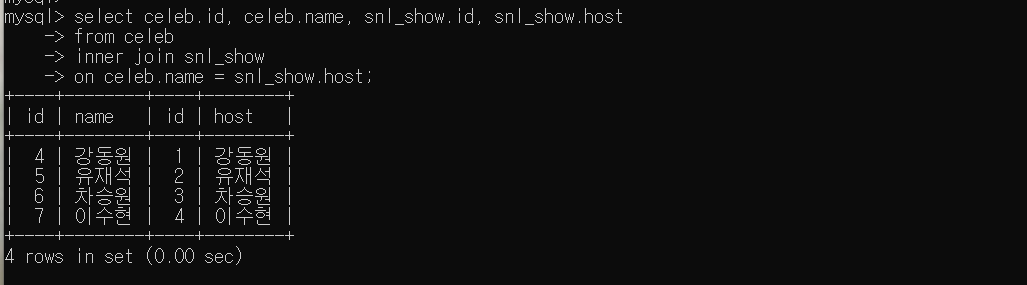
WHERE condition;- snl_show에 호스트로 출현한 celeb을 기준으로 celeb테이블과 snl_show를 INNER JOIN
SELECT celeb.id, celeb.name, snl_show.id, snl_show.host
FROM celeb
INNER JOIN snl_show
ON celeb.name = snl_show.host;컬럼명을 조회할 때 겹치지 않는 컬럼의 경우에는 테이블명을 명시하지 않을 수 있지만, 겹치는 컬럼의 경우는 반드시 컬럼명을 명시해야 한다.
.
.
2) LEFT JOIN
두 개의 테이블에서 공통영역을 포함해 왼쪽 테이블의 다른 데이터를 포함하는 조인방식이다.
SELECT col1, col2, ...
FROM tableA # left table
LEFT JOIN tableB # right table
ON tableA.column = tableB.column
WHERE condition;- snl_show에 호스트로 출현한 celeb을 기준으로 celeb테이블과 snl_show를 LEFT JOIN
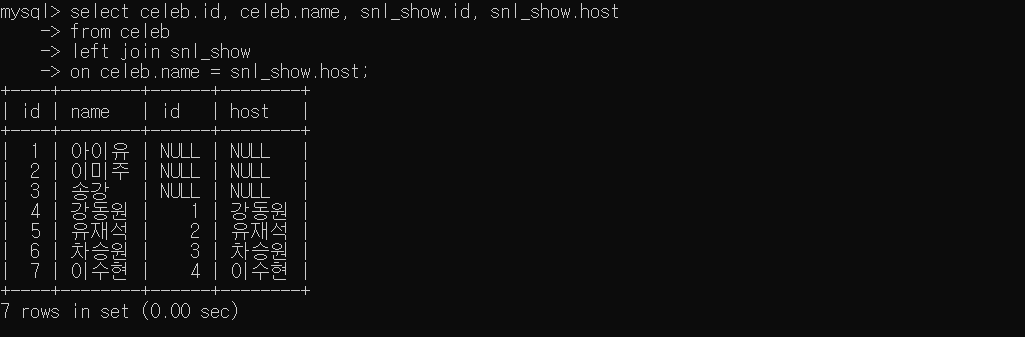
SELECT celeb.id, celeb.name, snl_show.id, snl_show.host
FROM celeb
LEFT JOIN snl_show
ON celeb.name = snl_show.host;left table인 'celeb'테이블의 모든 데이터는 출력되지만 right table인 'snl_show'의 데이터는 'celeb'과 공통된 데이터만 출력할 수 있게 된다.
.
.
3) RIGHT JOIN
두 개의 테이블에서 공통영역을 포함해 오른쪽 테이블의 다른 데이터를 포함하는 조인방식이다.
SELECT col1, col2, ...
FROM tableA # left table
RIGHT JOIN tableB # right table
ON tableA.column = tableB.column
WHERE condition;- snl_show에 호스트로 출현한 celeb을 기준으로 celeb테이블과 snl_show를 RIGHT JOIN
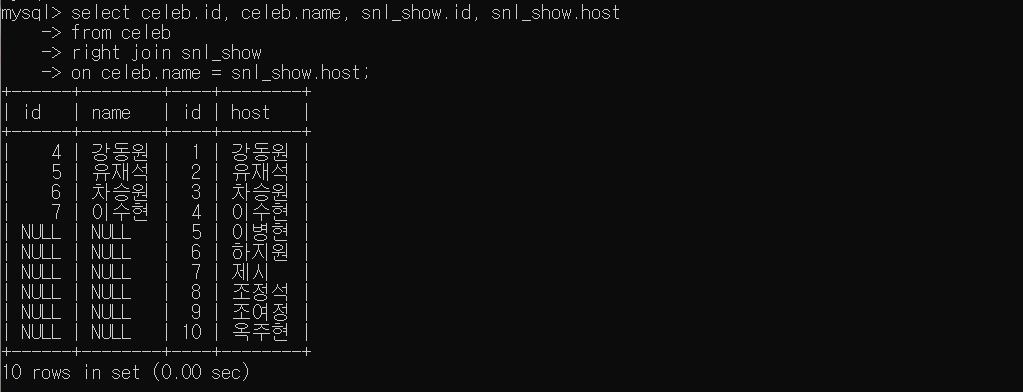
SELECT celeb.id, celeb.name, snl_show.id, snl_show.host
FROM celeb
RIGHT JOIN snl_show
ON celeb.name = snl_show.host;right table인 'snl_show'테이블의 모든 데이터는 출력되지만 left table인 'celeb'의 데이터는 'snl_show'와 공통된 데이터만 출력할 수 있게 된다.
.
.
4) FULL OUTER JOIN
두 개의 테이블에서 공통영역을 포함해 양쪽 테이블의 모든 데이터를 포함하는 조인방식이다.
SELECT col1, col2, ...
FROM tableA # left table
FULL OUTER JOIN tableB # right table
ON tableA.column = tableB.column
WHERE condition;하지만 이러한 문법은 아쉽게도 MYSQL에서는 지원하지 않는다...
그래서 다음과 같은 문법 형식을 통해서 대체할 수 있다.
이와 같이 쓸 수 있는 이유는 UNION이 중복된 데이터를 제거하기 때문에 FULL OUTER JOIN을 할 수 있게 되는 것이다.
SELECT col1, col2, ...
FROM tableA
LEFT JOIN tableB ON tableA.column = tableB.column
UNION
SELECT col1, col2,...
FROM tableA
RIGHT JOIN tableB ON tableA.column = tableB.column
WHERE condition;- snl_show에 호스트로 출현한 celeb을 기준으로 celeb테이블과 snl_show를 FULL OUTER JOIN
SELECT celeb.id, celeb.name, snl_show.id, snl_show.host
FROM celeb
LEFT JOIN snl_show
ON celeb.name = snl_show.host
UNION
SELECT celeb.id, celeb.name, snl_show.id, snl_show.host
FROM celeb
RIGHT JOIN snl_show
ON celeb.name = snl_show.host;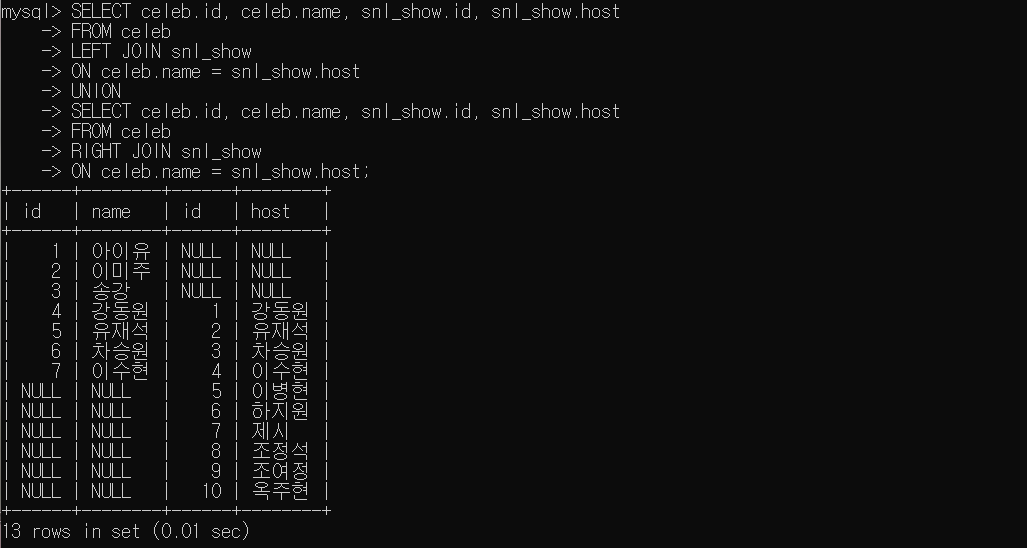
.
.
5) SELF JOIN
SELF JOIN은 INNER JOIN과 같이 공통된 부분만 출력하는 조인 방식이지만, 그 기준을 WHERE절에 명시하는 차이점이 있다.
SELCT col1, col2,...
FROM tableA, tableB, ...
WHERE condition;- snl_show에 호스트로 출현한 celeb을 기준으로 celeb테이블과 snl_show를 SELF JOIN
SELECT celeb.id, celeb.name, snl_show.id, snl_show.host
FROM celeb, snl_show
WHERE celeb.name = snl_show.host;
- celeb의 연예인 중, snl_show에 host로 출연했고 소속사가 안테나인 사람의 이름과 직업을 조회
SELECT celeb.name, celeb.agency, celeb.job_title
FROM celeb, snl_show
WHERE celeb.name = snl_show.host AND celeb.agency='안테나';
- celeb 연예인 중, snl_show에 host로 출연했고, 영화배우는 아니면서 YG소속이거나, 40세 이상이면서 YG소속이 아닌 연예인의 이름과 나이, 직업, 소속사, 시즌, 에피소드를 조회
SELECT celeb.name, celeb.age, celeb.job_title, celeb.agency, snl_show.season, snl_show.episode
FROM celeb, snl_show
WHERE celeb.name = celeb.host
AND (( NOT celeb.job_title LIKE '%영화배우% AND celeb.agency='YG엔터테인먼트)
OR (celeb.age>=40 AND celeb.agency != 'YG엔터테인먼트'));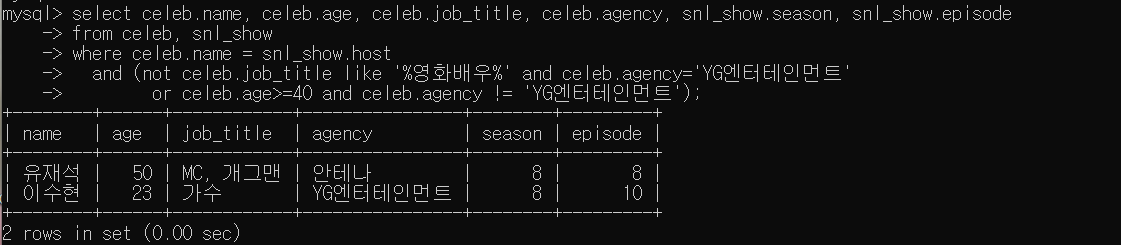
- snl_show에 출연한 celeb중, 에피소드 7,9,10중에 출연했거나, 소속사가 YG로 시작하고 뒤에 6자로 끝나는 사람 중 2020년 9월 15일 이후에 출연했던 사람
SELECT celeb.name, snl_show.season, snl_show.episode, snl_show.broadcast_date, celeb.agency
FROM celeb, snl_show
WHERE celeb.name = snl_show.host
AND (snl_show.episode IN (7,9,10) OR agency='YG____' )
AND broadcast_date > 20200915;
- snl_show에 출연한 연예인 중 직업이 영화배우나 탤런트가 아닌 사람의 아이디, 이름, 직업, 시즌, 에피소드 정보를 검색
SELECT celeb.id, celeb.name, celeb.job_title, snl_show.season, snl_show.episode
FROM celeb, snl_show
WHERE celeb.name = snl_show.host
AND NOT (celeb.job_title LIKE '%영화배우%' OR celeb.job_title LIKE '%탤런트%'); 
- snl_show에 출연한 연예인 중 2020년 09월 15일 이후에 출연했거나 소속사가 '엔터테인먼트'로 끝나지 않으면서 직업이 영화배우나 개그맨이 아닌 사람의 celeb 아이디, 이름, 직업, 소속사 검색
SELECT celeb.id, celeb.name, celeb.job_title, celeb.agency
FROM celeb, snl_show
WHERE celeb.name= snl_show.host
AND (snl_show.broadcast_date >= 20200915 OR NOT celeb.agency LIKE '%엔터테인먼트')
AND NOT (celeb.job_title LIKE '%영화배우%' OR celeb.job_title LIKE '%개그맨%'); 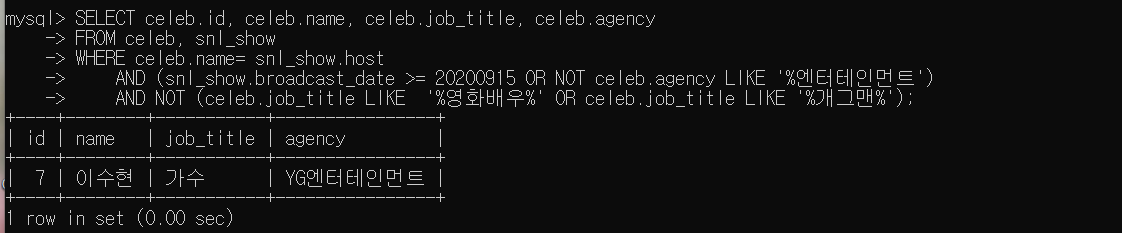
.
.
.
.
3. 기타 데이터 조회 방법
(1) CONCAT
여러 문자열을 하나로 합치거나 연결한다. 다음과 같은 문법으로 사용할 수 있다.
SELECT CONCAT('str1', 'str2', ...)- 'concat'과 'test'문자열 합치기
SELEECT CONCAT('concat', ' ', 'test');
- 문자열 '이름: '과 celeb테이블의 name컬럼을 합쳐서 새로운 데이터를 생성
SELECT CONCAT('이름: ', name) FROM celeb;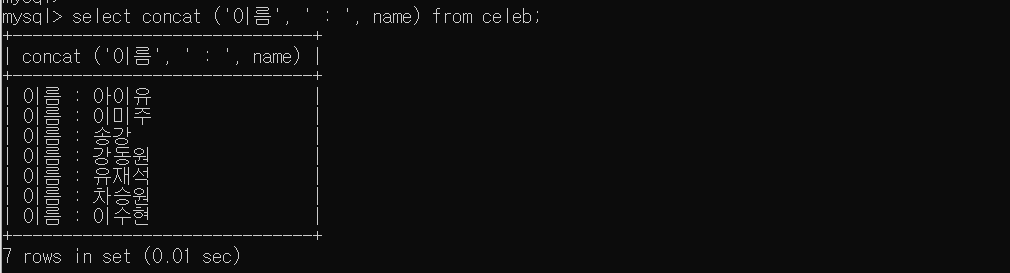
.
.
(2) ALIAS
ALIAS는 칼럼이나 테이블 이름에 별칭 생성하는 코드이다.
이런 식으로 칼럼의 별칭을을 생성할 수도 있고,
SELECT column as alias
FROM tablename;혹은 테이블의 별칭을 이와같이 생성할 수도 있다.
SELECT column1, column2
FROM tablename as alisa;예제를 몇 가지 살펴보자.
- name을 이름으로 별칭을 만들어 검색
SELECT name as '이름' FROM celeb;
- name은 이름으로, agency는 소속사로 만들어 검색
SELECT name as '이름', agency as '소속사'
FROM celeb;
- name과 job_title을 합쳐서 profile이라는 별칭을 만들어 검색
SELECT CONCAT (name, ' : ', job_title) as profile
FROM celeb;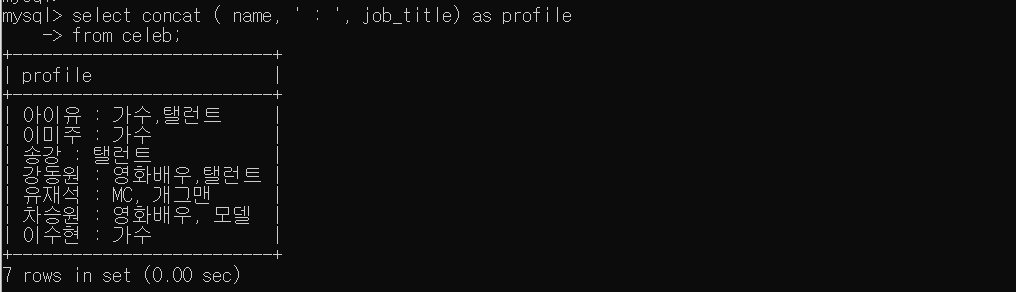
- snl_show에 출연한 celeb을 기준으로 두 테이블을 조회하여, celeb테이블은 c, snl_show는 s라는 별칭을 만들어 출연한 시즌,에피소드,이름,직업 검색
SELECT s.season, s.episode, c.name, c.job_title
FROM celeb AS c, snl_show AS s
WHERE c.name = s.host;
이때 AS는 생략도 가능하다.
SELECT s.season, s.episode, c.name, c.job_title
FROM celeb c, snl_show s
WHERE c.name = s.host;
- snl_show에 출연한 celeb을 기준으로 두 테이블을 조인하여 다음과 같이 각 데이터의 별칭을 사용하여 검색
① 시즌, 에피소드, 방송일을 합쳐서 '방송정보'
② 이름, 직업을 합쳐서 '출연자정보'
SELECT CONCAT(s.season, '-', s.episode, '(', s.broadcast_date, ')' ) AS '방송정보,
CONCAT(c.name, '(', c.job_title, ')' ) AS '출연자정보'
FROM celeb AS c, snl_show AS s
WHERE c.name = s.host;
- 이름이 세글자인 연예인 정보
SELECT CONCAT('이름: ', name, ', 소속사 : ', agency) as '연예인 정보'
FROM celeb
WHERE name LIKE '___';
- 앞글자가 2글자이고, '엔터테인먼트'로 끝나는 소속사 연예인 중 snl_show에 출연한 celeb의 신상정보(나이,성별)와 출연정보(시즌-에피소드, 방송날짜), 소속사 정보를 방송날짜 최신순으로 정렬하여 검색
SELECT c.agency as '소속사 정보',
CONCAT ('나이: ', c.age, ' (', c.sex, ')' ) as '신상정보',
CONCAT ( s.season, '-', s.episode, ' , 방송날짜: ', s.broadcast_date) as '출연정보'
FROM celeb AS c, snl_show AS s
WHERE c.name = s.host
AND c.agency LIKE '__엔터테인먼트'
ORDER BY s.broadcast_date DESC;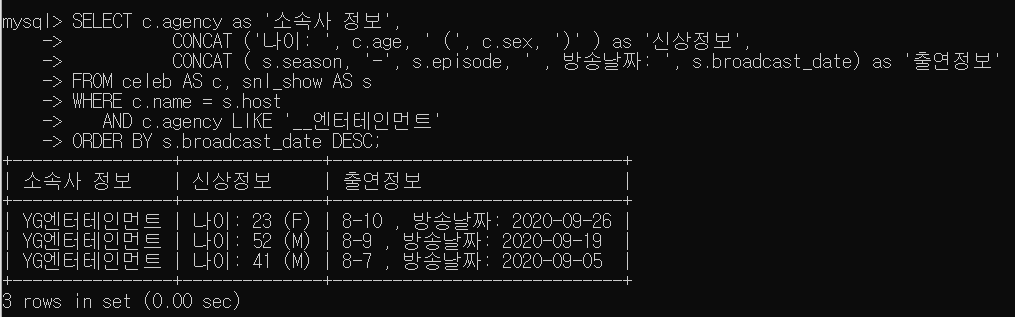
.
.
(3) DISTINCT
DISTINCT는 검색한 결과의 중복 제거해 주는 기능을 갖고 있다.
SELECT 조회문에 붙여서 사용할 수 있다.
SELECT DISTINCT column1, column2, ...
FROM tablename;- 연예인 소속사 종류 검색
먼저 중복을 포함하여 데이터를 검색해보자.
SELECT agency
FROM celeb;
중복 제거하면 다음과 같다.
SELECT DISTINCT agency
FROM celeb;
- 가수 중에서 성별과 직업별 종류 검색 -중복 제거
SELECT DISTINCT sex, job_title
FROM celeb;
WHERE job_title LIKE '%가수%';
.
.
(4) LIMIT
LIMIT은 검색결과를 정렬된 순으로 주어진 숫자만큼만 조회하는 기능을 가진다.
코드의 마지막 줄에서 제한 숫자를 넣어주면 된다.
SELECT col1, col2, ...
FROM tablename
WHERE condition
LIMIT number;- celeb 데이터 3개만 가져오기
SELECT *
FROM celeb
LIMIT 3;
- 나이가 가장 적은 연예인 4명 검색
SELECT *
FROM celeb
ORDER BY age
LIMIT 4;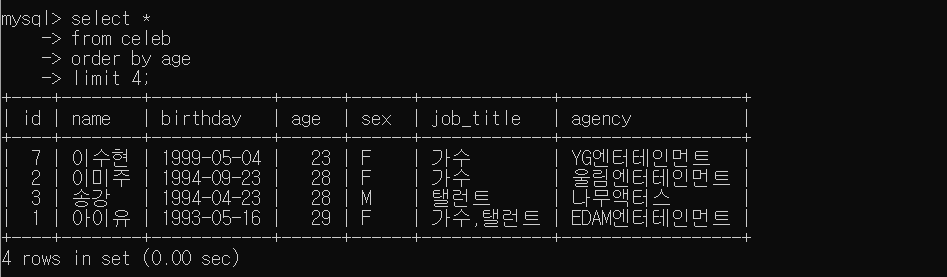
- 남자 연예인 중 나이가 가장 많은 2명 조회
SELECT *
FROM celeb
WHERE sex='M'
ORDER BY age DESC
LIMIT 2;
- snl_show에 출연한 연예인의 정보를 나이가 많은 순으로 2개만 검색
SELECT CONCAT ('SNL 시즌 ', s.season, ' 에피소드 ', s.episode, ' 호스트 ', c.name) as 'SNL 방송정보', c.age
FROM celeb as c, snl_show as s
WHERE c.name = s.host
ORDER BY c.age DESC
LIMIT 2;
