Chapter
1. Python with MYSQL
(1) Python으로 MYSQL 접속하기
(2) Python으로 SQL 쿼리 실행하기
(3) Python으로 CSV데이터를 INSERT하기
2. Primary key, Foreign key
(1) Primary key
(2) Foreign key
1. Python with MYSQL
이번에시간에는 Python과 MYSQL을 연동해서 사용해보자.
python으로 mysql에 접속해 쿼리를 작성하는 것이다.
(1) Python으로 MYSQL 접속하기
VSCode를 사용해 이전에 사용하던 작업환경을 통해 MYSQL을 연동했다. 먼저 MYSQL driver를 설치해준다.
# 설치
pip insall mysql-connector-python
# 설치 확인
import mysql.connector설치 확인까지 마쳤다면 코드를 통해 접속하려는 MYSQL 환경의 정보를 입력하면 된다.
mydb = mysql.connector.connect(
host = "<hostname>",
user = "<username>",
password = "<password>"
)연결을 통해 작업을 다 마쳤다면 연결을 종료해줘야 한다.
mydb.close()예를 들어 Local환경의 zerobase Database에 연결하려면 다음과 같이 코드를 작성하면 되고,
# 연결
local = mysql.connector.connect(
host = "localhost",
user = "root",
password = "******"
database = "zerobase"
)
# 종료
local.close()외부 서버의(ex. AWS RDS) zerobase 데이터베이스를 연결하면 된다.
# 연결
remote = mysql.connector.connect(
host="database-1.cg5yaxkdzdyu.us-east-2.rds.amazonaws.com",
post = 3306,
user = "admin",
password = "**********",
database = "zerobase"
)
# 해제
remote.close().
.
(2) Python으로 SQL 쿼리 실행하기
1) 테이블 생성 및 삭제
먼저 쿼리를 실행하기 위해 쿼리문에 의해 반환되는 결과값을 제공하는 cursor를 지정해줘야 한다.
그 다음에 execute()메서드에 SQL 쿼리를 작성해준다.
AWS RDS의 zerobase 데이터베이스를 연결한 결과를 remote 변수에 지정해준 다음, sql_file 테이블을 생성해주었다.
cur = remote.cursor()
cur.execute("CREATE TABLE sql_file (id int, file_name varchar(16))")
remote.close()만들어진 sql_file 테이블을 확인해보자.
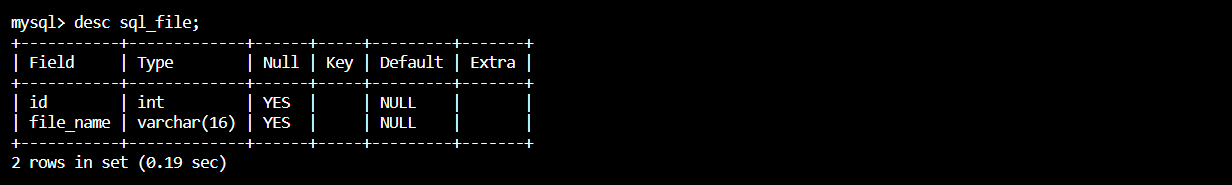
반대로 파이썬으로 sql쿼리문을 실행해 테이블을 삭제해보자. 마찬가지로 execute메서드에 쿼리를 작성해주었다.
cur = remote.cursor()
cur.execute("DROP TABLE sql_file")
remote.close()결과를 확인해보자.

2) SQL File 실행하기
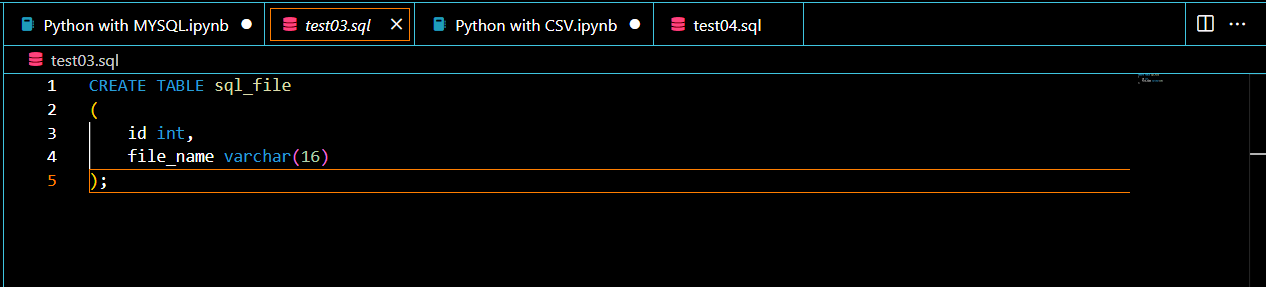
이번에는 SQL File을 실행하여 데이터를 다뤄보는 작업을 해본다. 먼저 실행할 SQL File을 생성해주었다.(test03.sql) 해당 파일에는 sql_file 테이블을 생성하는 코드가 담겨있다.
마찬가지로 AWS RDS의 zerobase 데이터베이스의 연결 결과가 담긴 remote변수를 이용해주었다.
SQL File를 열기위해서 open()메서드로 파일을 읽을 수 있도록 했다.
cur = remote.cursor()
sql = open("test03.sql").read()
cur.execute(sql)
remote.close()sql_file 테이블이 정상적으로 만들어졌는지 확인해보자.

쿼리문이 여러 개일 때에는 어떻게 작동시켜야 될까?
먼저 실행할 SQL File(test04.sql)을 만들었다. 해당 파일에는 sql_file 테이블에 들어갈 데이터의 insert문이 작성되어 있다.

다수 쿼리를 실행하기 위해서는 execute()메서드의 옵션을 'multi=True'로 넣어준다.
cur = remote.cursor()
sql = open("test04.sql").read()
for result_iterator in cur.execute(sql, multi=True):
if result_iterator.with_rows:
print(result_iterator.fetchall())
else:
print(result_iterator.statement)
remote.commit()
remote.close()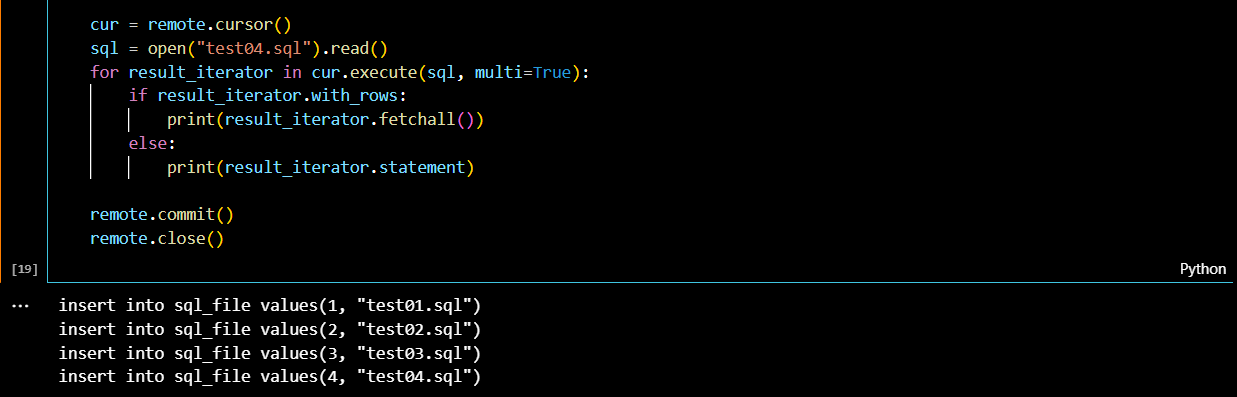

참고로 commit()은 코드가 하나씩 작성할 때마다 데이터베이스에 저장하게 하는 역할을 한다. 따라서 for문이 실행되다가 중간에 에러가 발생해도 그 이전까지는 데이터베이스에 저장하게 할 수 있다.
3) 데이터 조회하기
이번에는 테이블 데이터를 불러와서 조회해보자. fetchall()을 사용하여 출력 결과를 불러올 수 있다.
참고로 cursor()를 만들 때 불러온 데이터 양이 많다면 'buffered=TRUE'를 넣어준다.
cur = remote.cursor(buffered=True)
cur.execute("SELECT * FROM sql_file")
result = cur.fetchall()
result
.
.
(3) Python으로 CSV데이터를 INSERT하기
이번에는 CSV파일의 데이터를 불러와서 SQL 테이블에 insert해보자.
먼저 파일을 Pandas로 불러 읽는다.
import pandas as pd
df = pd.read_csv("police_station.csv")
df.tail()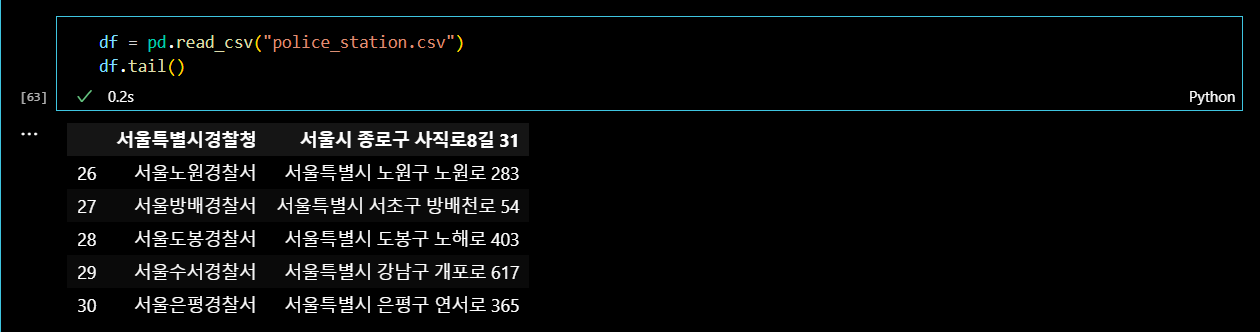
마찬가지로 AWS RDS의 zerobase데이터에 연결한다. 이번에는 결과를 conn변수에 지정해주었다. 그 다음 cursor를 만들어 insert 코드까지 만들어 주었다.
cursor = conn.cursor(buffered=True)
sql = "INSERT INTO police_station values (%s, %s)"데이터를 입력해준다.
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()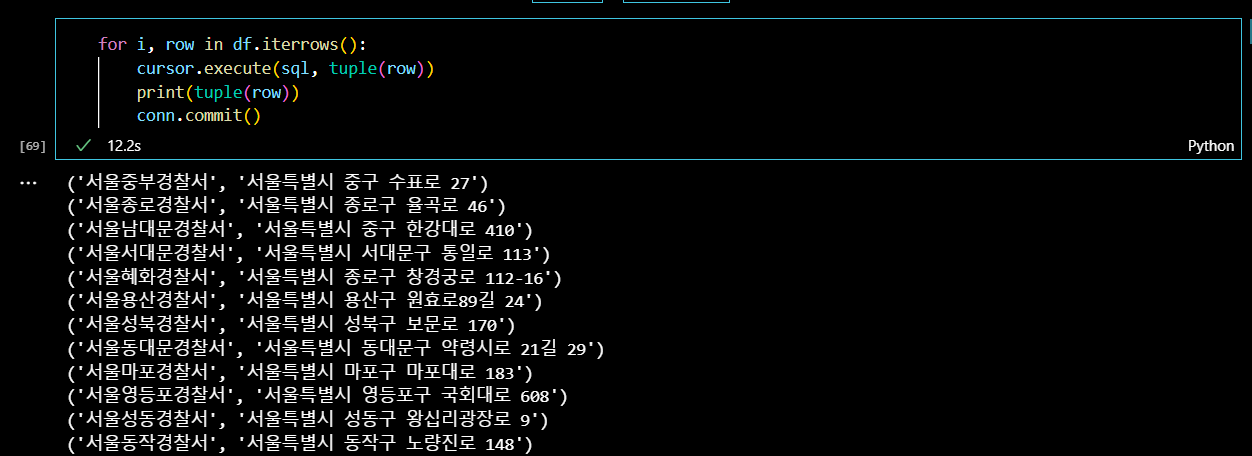
결과를 확인해준다.
cursor.execute("SELECT * FROM police_station")
result = cursor.fetchall()
result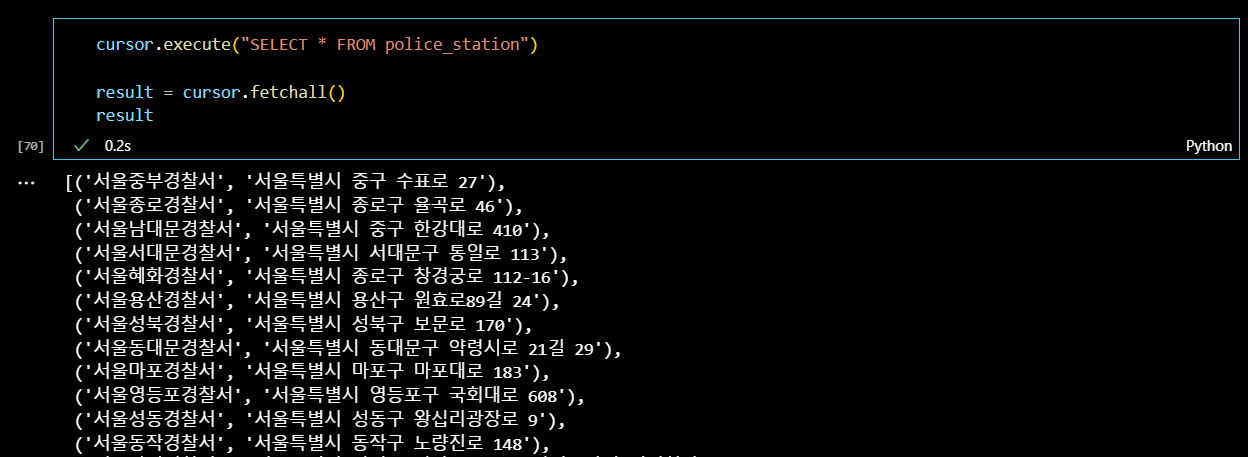
결과물을 데이터프레임으로 읽어서 마무리해준다.
result_df = pd.DataFrame(result)
result_df.tail()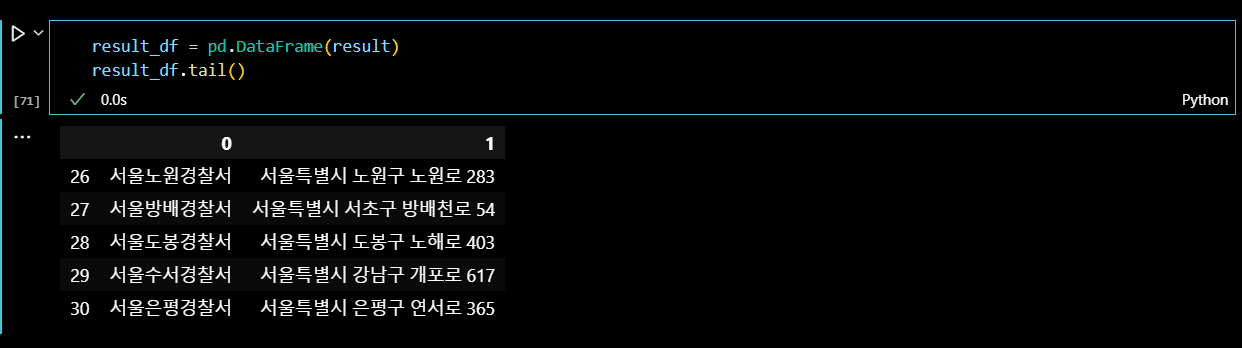
.
.
.
.
2. Primary key, Foreign key
(1) Primary key
테이블의 각 레코드를 식별하는 값으로 primary key(기본키)라고 한다. 중복되지 않은 고유값을 포함하며, Null값은 포함할 수 없다. 마지막으로 테이블 당 하나의 기본키를 가질 수 있다.
생성문법은 다음과 같은데, CONSTRAINT 제약문은 없어도 가능하다.
CREATE TABLE tablename
(
column1 datatype NOT NULL,
column2 datatype NOT NULL,
....
CONSTRAINT constraint_name
PRIMARY KEY (column1, column2, ...)
);1) 하나의 칼럼을 기본키로 설정하는 경우
CREATE TABLE person
(
pid int NOT NUL,
name varchar(16),
age int,
sex char,
PRIMARY KEY (pid)
);
# 확인
DESC person;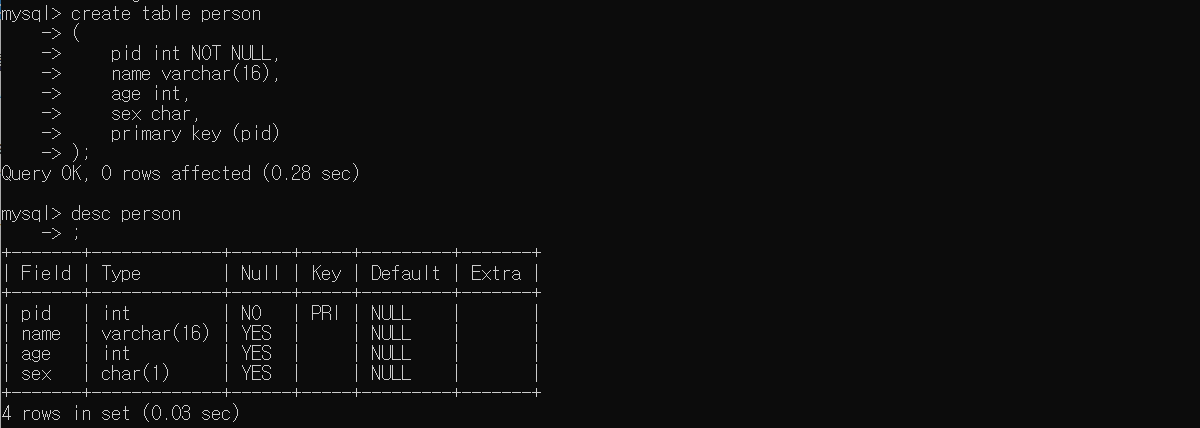
2) 여러 개의 칼럼을 기본키로 설정하는 경우
이때는 기본키가 두 개가 생성되는 것이 아니라, 두 개의 컬럼이 하나의 기본키로 설정되는 것이라고 이해해야 한다.
CREATE TABLE animal
(
name varchar(16) NOT NULL,
type varchar(16) NOT NULL,
age int,
PRIMARY KEY (name, type) # 두 개가 하나의 기본키
);
# 확인
DESC animal;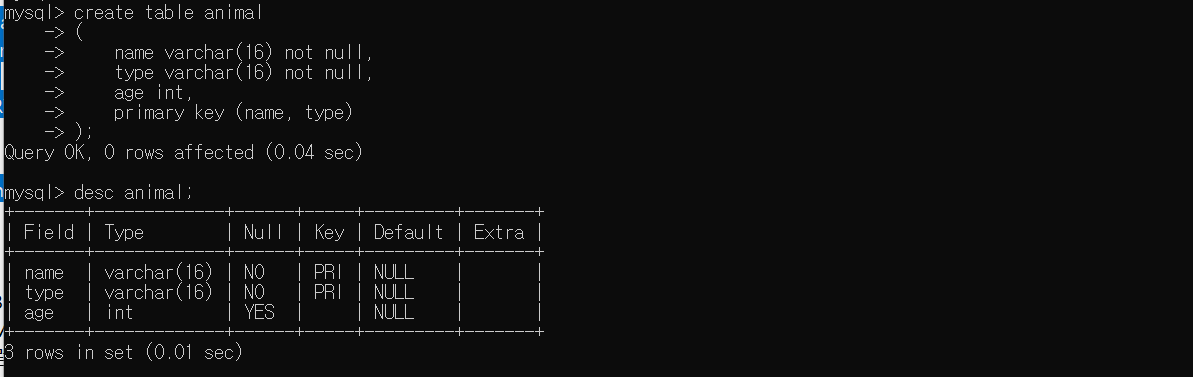
3) 기본키 삭제하기
primary key를 삭제할 때에는 'ALTER TALBE'문을 이용해서 삭제한다. 이때, 한 개의 칼럼이 기본키로 설정되든, 두 개의 컬럼이 기본키로 설정되든 삭제방법은 동일하다.
# 하나의 칼럼이 기본키로 설정된 경우
ALTER TABLE person
DROP PRIMARY KEY;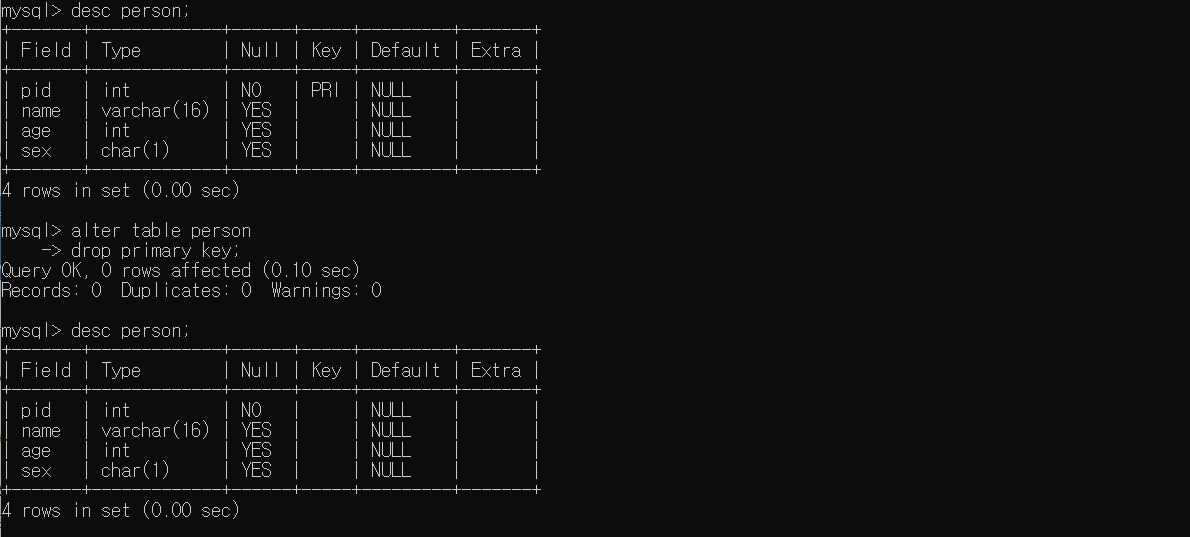
# 여러 개의 칼럼이 기본키로 설정된 경우(삭제방법 동일)
ALTER TABLE animal
DROP PRIMARY KEY;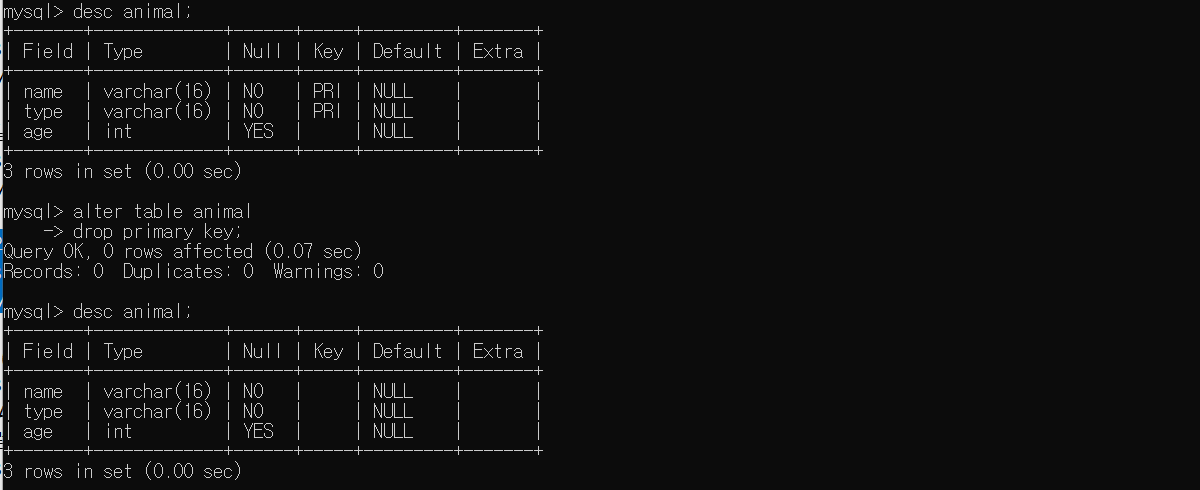
4) 기본키 추가하기
기존의 테이블에서 기본키를 추가해보자.
삭제된 person과 animal테이블에 다시 기본키를 설정해주었다.
# 하나의 칼럼을 기본키로 지정
ALTER TABLE person
ADD PRIMARY KEY (pid);
# 여러 개의 칼럼을 기본키로 지정하는 경우
ALTER TABLE animal
ADD CONSTRAINT PK_animal PRIMARY KEY (name, type);
.
.
.
(2) Foreign key
1) 외래키 생성하기
Foreign key(외래키)는 한 테이블을 다른 테이블과 연결해주는 역할을 한다. 이때 참조되는 테이블의 항목은 그 테이블의 기본키, 혹은 단일값이 되어야 한다.
person 테이블의 기본키(pid)를 참조해서 Foreign key를 생성해주었다. 이때 마찬가지로 제약문 'CONSTRAINT'는 생략할 수 있다.
CREATE TABLE orders
(
oid int not null,
order_no varchar(16),
pid int,
PRIMARY KEY (oid),
CONSTRAINT FK_person FOREIGN KEY (pid) REFERENCES person(pid)
);
# 확인
DESC orders;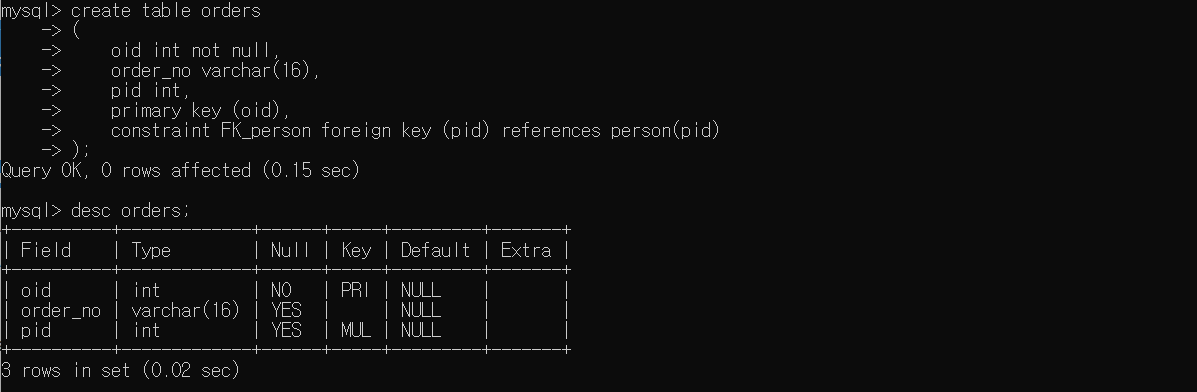
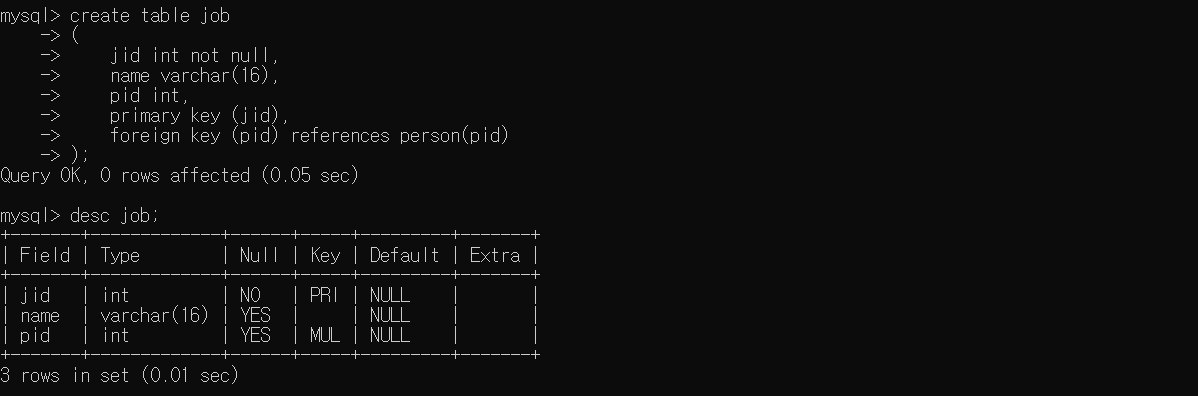
이번에는 제약문을 생략해서 만들어보았다.
CREATE TABLE job
(
jid int not null,
name varchar(16),
pid int,
PRIMARY KEY (jid),
FOREIGN KEY (pid) REFERENCES person(pid)
);
관계 설정으로 자동 생성되는 제약문을 확인할 수도 있다.
SHOW CREATE TABLE job;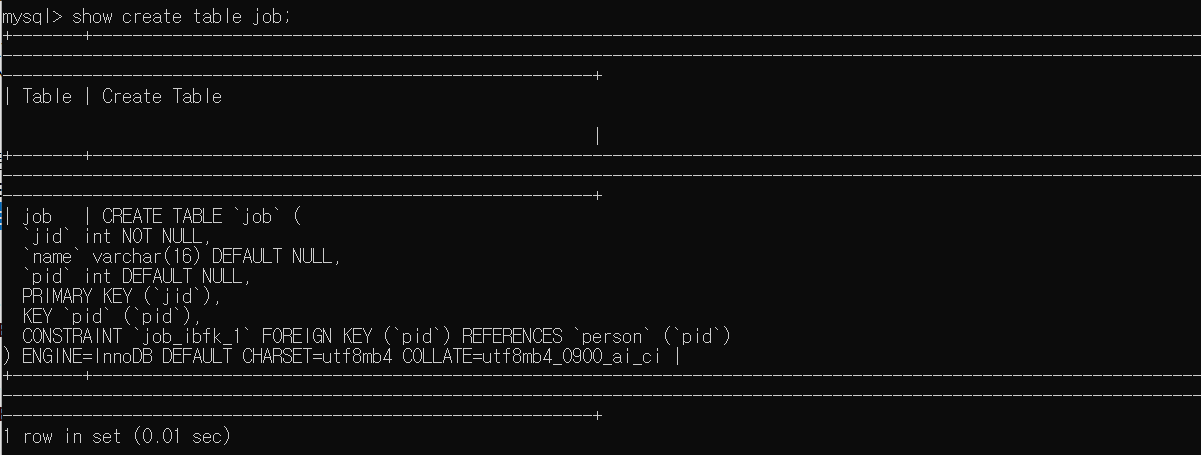
2) 삭제하기
ALTER TABLE문을 이용해서 외래키를 삭제해보자. 외래키는 여러 개 만들 수 있기 때문에 삭제할 대상을 명시해줘야 한다.
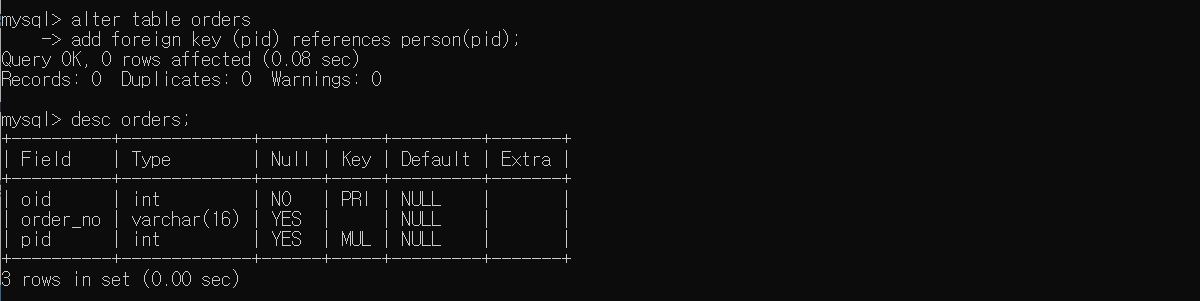
ALTER TABLE orders
DROP FOREIGN KEY FK_person;
# 확인
DESC orders;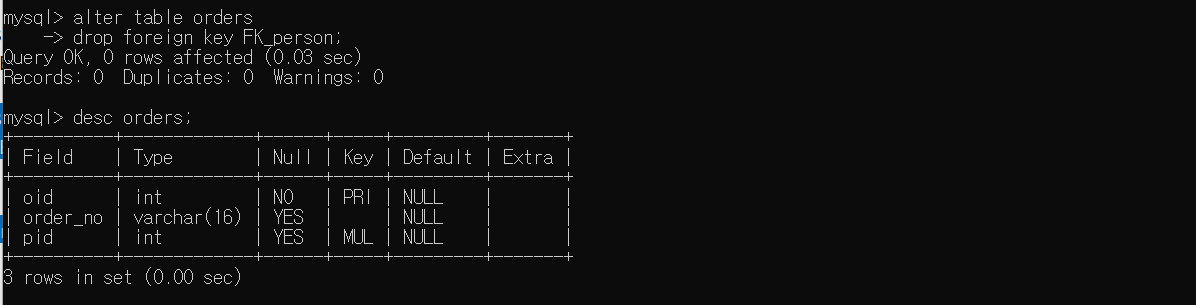
얼핏 테이블 정보를 확인했을 때 삭제가 안된 것처럼 보이지만 제약문을 살펴보면 관계가 끊어진 것을 확인할 수 있다.
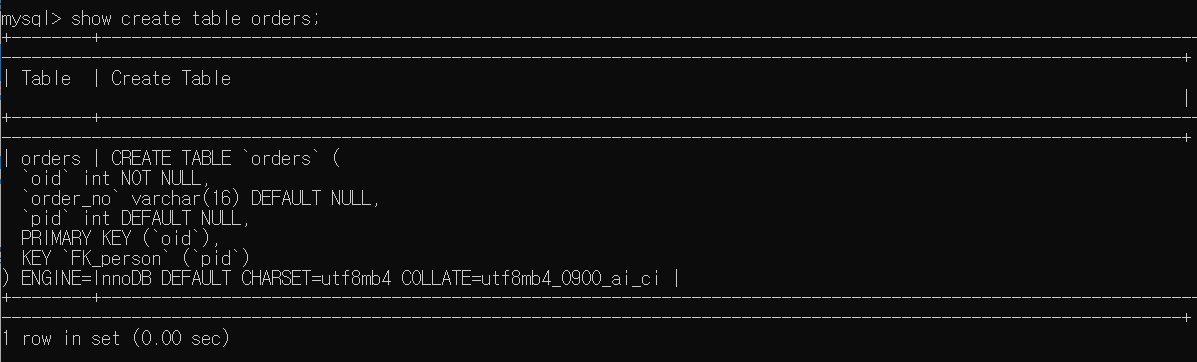
3) 만들어진 테이블에 외래키 생성하기
이미 만들어진 테이블에 외래키를 지정해보자. 마찬가지로 ALTER TABLE문을 이용한다.
ALTER TABLE orders
ADD FOREIGN KEY (pid) REFERENCES person (pid);