System Architecture란
System Architecture는 시스템의 구조(structure), 행위(behavior), 뷰(views)를 정의하는 개념 모델입니다. 시스템의 목적을 달성하기 위해 각 컴포넌트가 상호작용 하는 것으로, 정보가 교환 되는 것을 설명합니다.
다양한 System Architecture가 있지만 목적은 하나로 생각할 수 있습니다.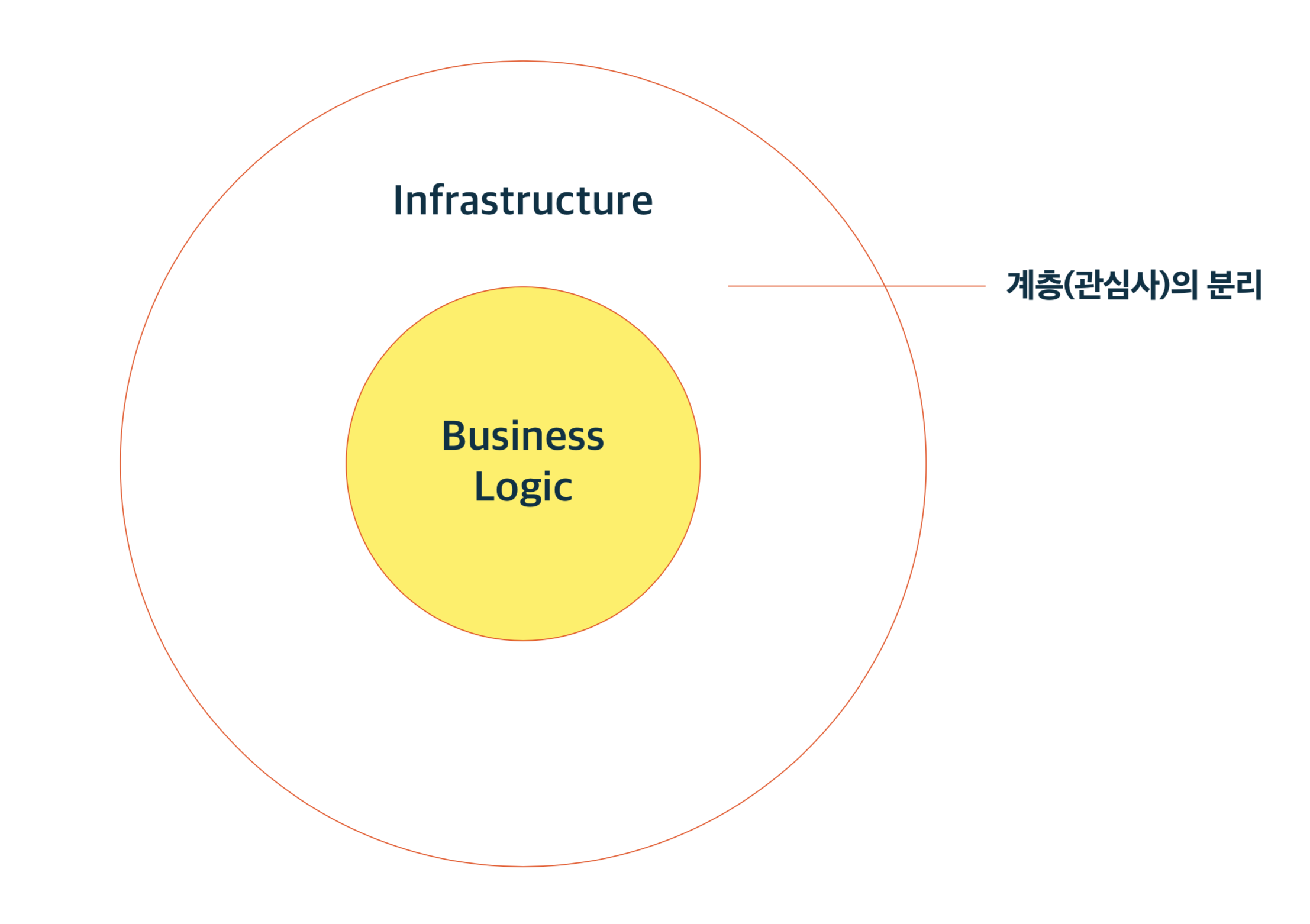
관심사의 분리입니다.
소프트웨어를 계층으로 나누면 관심사를 분리할 수 있습니다. 관심사의 분리는 계층을 물리적으로 분리해서 이루어집니다. 이때, 의존성 규칙 계층사이에서 서로 의존과 간섭이 없을때 clean architecture라고 합니다.
이러한 클린 아키텍쳐가 동작하기 위해서는 의존성 규칙을 지켜야합니다.
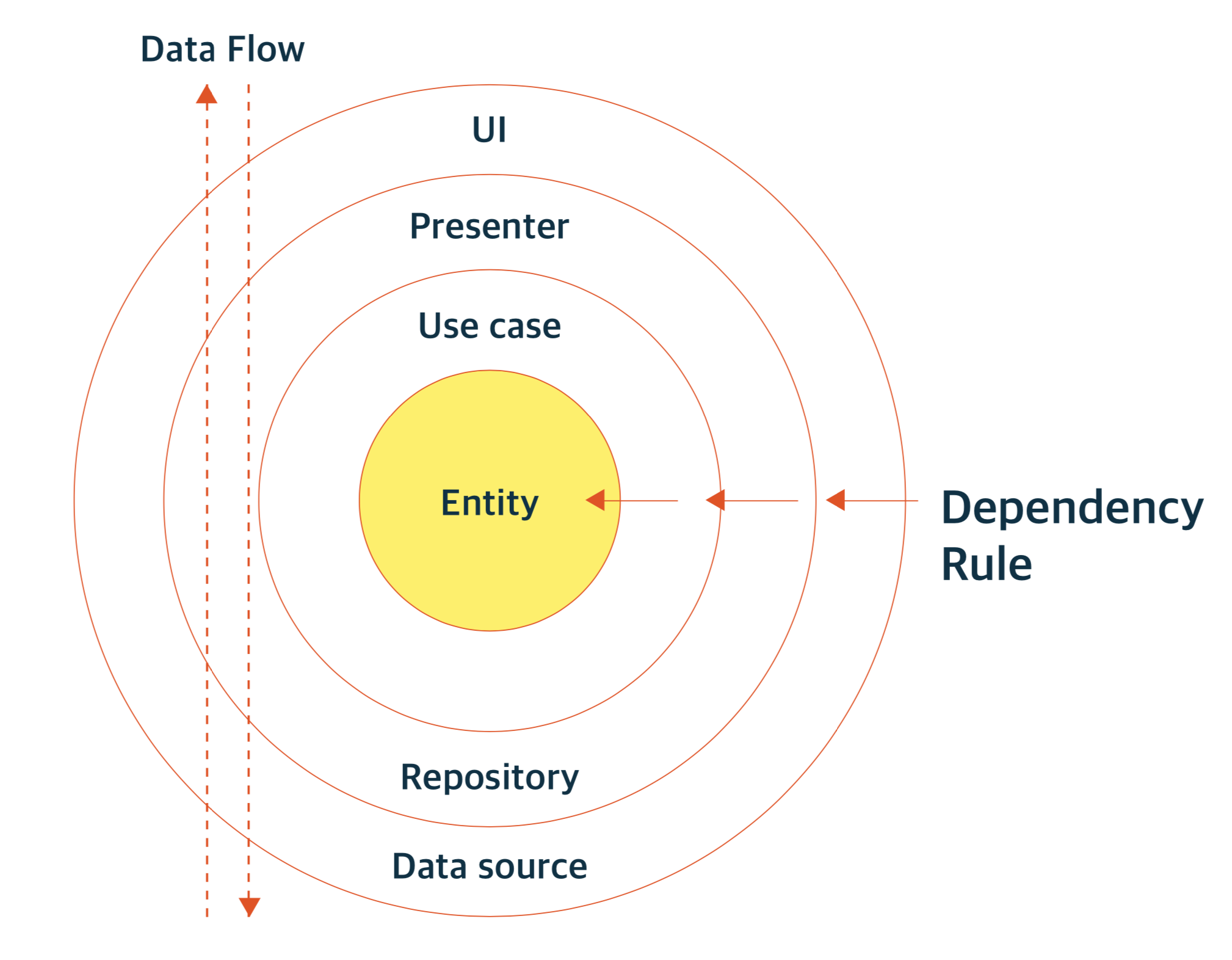
Dependency Rule (의존성 규칙)
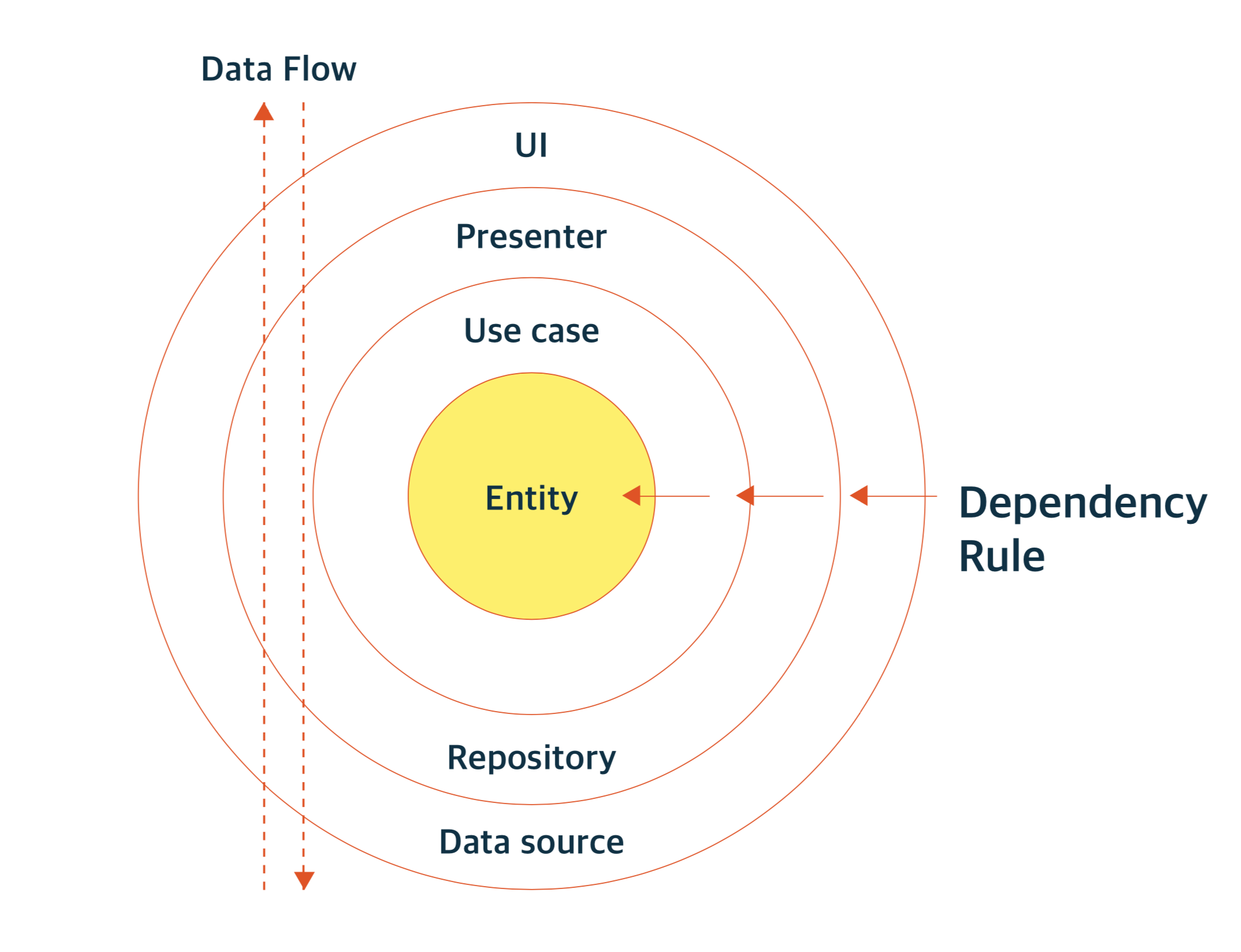
의존성 규칙은 Business Logic을 담당하는 코드가 DB 또는 Web과 같이 구체적인 세부사항에 의존하지 않고 독립적으로 실행되야 한다는 규칙입니다.
inner circle에 해당하는 Domain은 outer circle에 해당하는 Infrastructure에 대해서는 알지 못합니다.
이 뜻은 UI, DB는 Business Logic에 의존하지만 Business Logic은 바깥쪽 레이어가 어떻게 변경되든 영향을 받지 않는다는 뜻입니다.
이 의존성 규칙에서는 반드시 모든 소스코드 의존성이 외부에서 내부로, 저수준에서 고수준으로 향해야합니다.
고수준과 저수준은 추상화의 정도에 따라 분류될 수 있습니다. 추상화가 많이 되어 있을수록 고수준이라고 할 수 있습니다.
추상화란?
추상화란, 대상에서 특징을 뽑아낸 것으로 프로그래밍에서는 인터페이스 안에 함수를 쓰는 것이 추상화를 하는 방법입니다. 코드를 썼을 때 어떤 내용을 수행하는지가 한눈에 파악되지 않을때 추상적이라고 말할 수 있습니다.
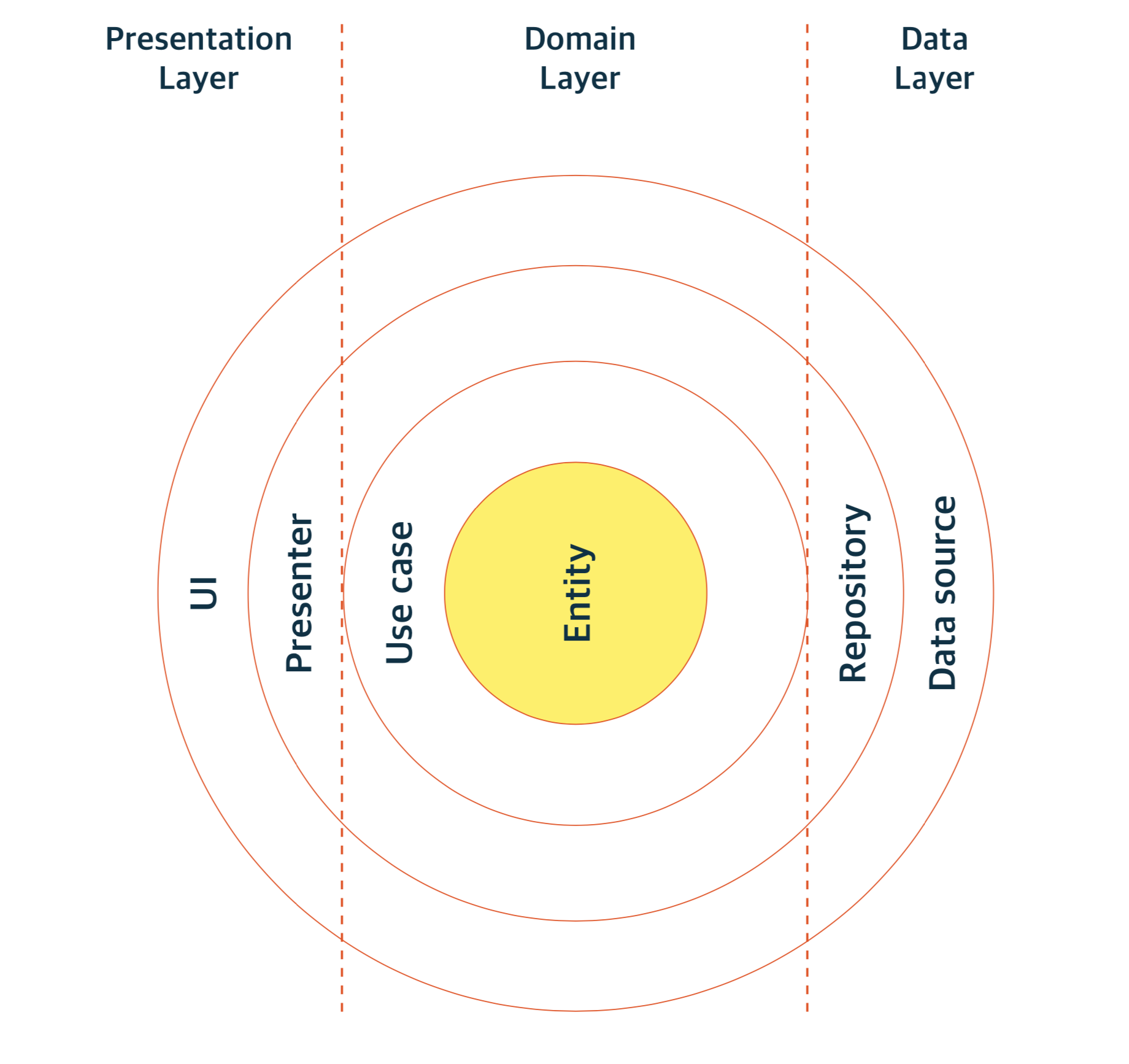
2개로 나눠져 있던 Layer를 더 세분화 하면 4개의 Layer로 나눌 수 있는데, Domain이 Entities, Use Cases로 세분화 되고 Adapter가 Domain과 Infrastructure 사이의 경계를 관리합니다.
가장 안쪽에 있는 비즈니스 로직은 바깥쪽 계층 중 무엇이 변경되더라도 바뀌지 않아야합니다.
이 비즈니스로직을 담당하는 Domain 계층은 이 비즈니스 로직을 담당하는 Domain 계층은 entity와 usecase로 구성되어있는데, entity란 비즈니스 로직을 캡슐화한 것으로 가장 일반적이면서도 고수준의 규칙을 캡슐화한 모듈입니다.
usecase는 entity에서 데이터를 가져오거나 Application의 동작을 결정합니다.
이 계층또한 entity에 영향을 주지 않으며 데이터베이스, UI, 혹은 공통의 프레임워크 변경으로부터 영향을 받지 않습니다.
Adapter와 infrastructure
Adapter는 domain과 infrastructure 사이에서 번역을 하는 역할을 담당합니다.
이 계층에서는 데이터는 entity와 usecase에 용이한 형태에서 사용하고 있는 프레임워크에 용이한 형태로 변환됩니다.
infrastructure는 가장 바깥쪽 계층으로 데이터베이스나 웹 프레임워크 등 일반적으로 프레임워크나 도구로 구성되게되며, 변화할 가능성이 매우 높기 때문에 가능한 한 도메인 계층으로부터 멀리 유지됩니다. 도메인 계층과 분리되어있으므로 비교적 쉽게 변경하거나 하나의 구성요소를 다른 구성요소와 변환할 수 있습니다.
영향을 주는 쪽 즉, interface를 구현한 구현체가 저수준의 정책을 직접 참조하게된다면 의존성 규칙을 위반하게 됩니다. 이 해결책은 의존성 역전의 원칙을 적용해 저수준의 정책이 변경되어도 고수준의 도메인에서는 변경에 대한 영향이 없도록 만들어 줄 수 있습니다.
Clean architecture를 구현해야하는 이유
클린 아키텍쳐를 구현해야하는 이유는 반대의 경우를 상상해보면 알기 쉽습니다.
대표적인 예로 스파게티코드를 예시로 들어보겠습니다.
스파게티 코드를 작성하게 되면 작동 자체는 하지만, 추후 코드의 유지보수가 매우 어려워집니다.
스파게티 코드로 작성된 코드는, 코드의 작동방식을 변경하거나 버그를 찾거나 개선하는 등 코드를 수정하는 모든 작업에 방해가 되기 때문입니다.
스파게티코드가 발생하는 원인은 알고리즘 구현정도가 지나치게 떨어질 때 발생하는데,
즉 한 함수에서 지나치게 많은 일을 하거나, 여러 함수/메소드들이 지나치게 서로를 의존할때 등등 코드의 동작방식이 얽혀있을때 발생하게 됩니다.
이를 방지하기 위해서 코드가 물리적으로 분리되어있고, 그 코드가 정해진 연관성을 가지는게 좋습니다.
클린 아키텍쳐는 관심사를 분리하는 것이 목적입니다. 관심사를 분리하게되면 계층이 분리되고, 이렇게 계층화가 되면 각 계층의 의존과 간섭이 없어지게 되므로, 자동적으로 코드들이 정해진 연관성을 가지고 물리적으로 분리되게 됩니다. 클린 아키텍쳐를 구현하면 얻게 되는 장점에 대해 설명드리겠습니다.
- 프레임워크와 독립적으로 사용이 가능
System architecture는 라이브러리 존재 여부나 프레임워크에 한정적이지않아 개발도구로써 사용하는 것이 가능합니다. - 테스트에 용이
Business logic은 UI,DB,Web server등 기타 외부 요인과 관계없이 테스트가 가능합니다. - 독립적인 UI
시스템의 다른 부분을 고려하지않고 UI를 변경할 수 있습니다. - 독립적인 DB
DB또한 독립적으로 변경할 수 있고 Business rule에 얽매이지 않습니다.
이처럼 Business 로직은 외부상황(DB,UI)에 대해 아무것도 모르고 서로 독립적인 상태를 유지합니다. 그렇다면 비즈니스 로직은 어떻게 쓰여지는게 올바를까요?
다음 시리즈로 넘어가겠습니다.

ogm...