- learning rate를 조절하는 방법
- data preprocessing 선처리 하는 방법
- overfitting 방지하는 방법
cost function을 정의하고 최소화 하는 값을 찾기위해서 찾은 것
: Gradient descent 알고리즘.
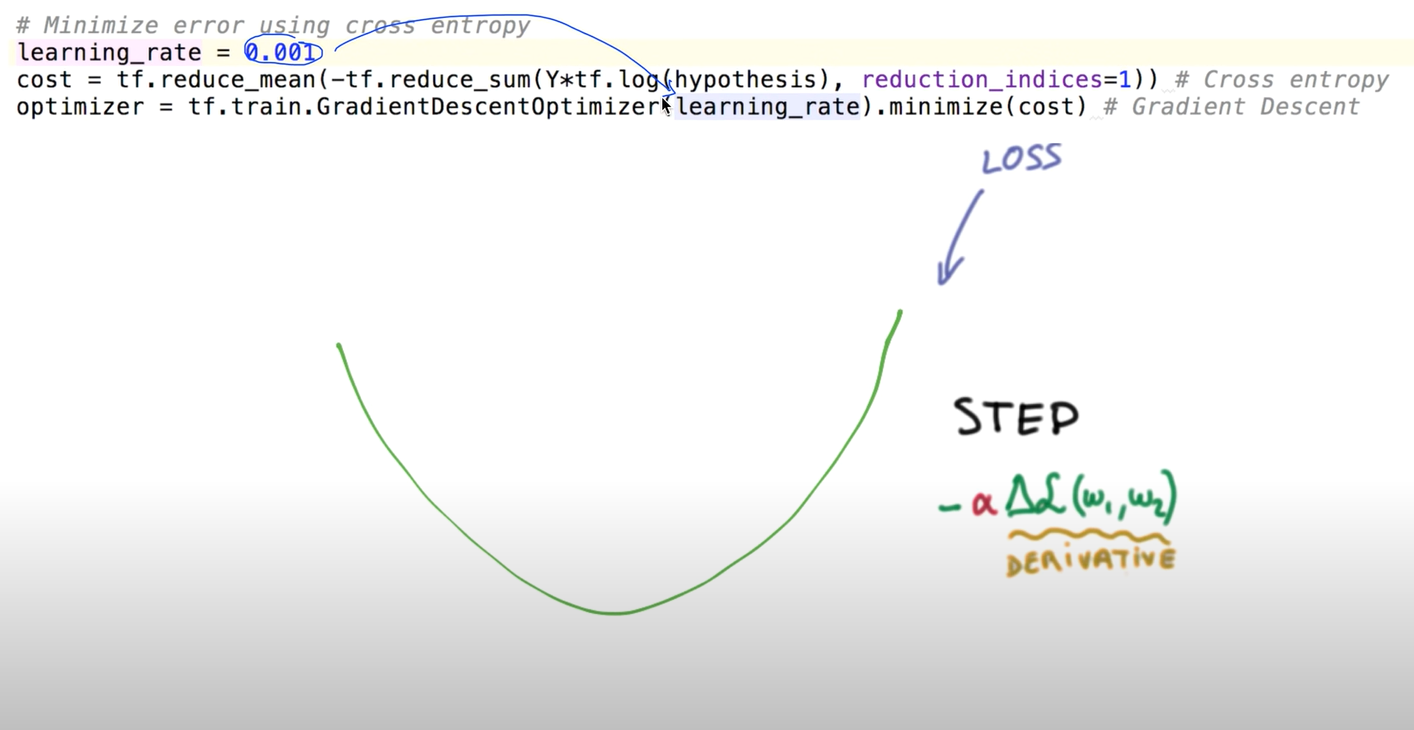
이 learning rate을 잘 정하는게 중요한데
1) 만약에, 큰 값을 정한다면? = 경사면 내려가는 한발작 스텝이 큰 것.
스텝이 커서 울퉁불퉁 될 것이고, 왔다갔다 해짐. 밖으로 튕길수도. 그러면 학습이 이뤄지지 않을 뿐 아니라 cost 함수를 출력하면 숫자아닌 값이 출력됨.
이것을 overshooting 이라고 함.
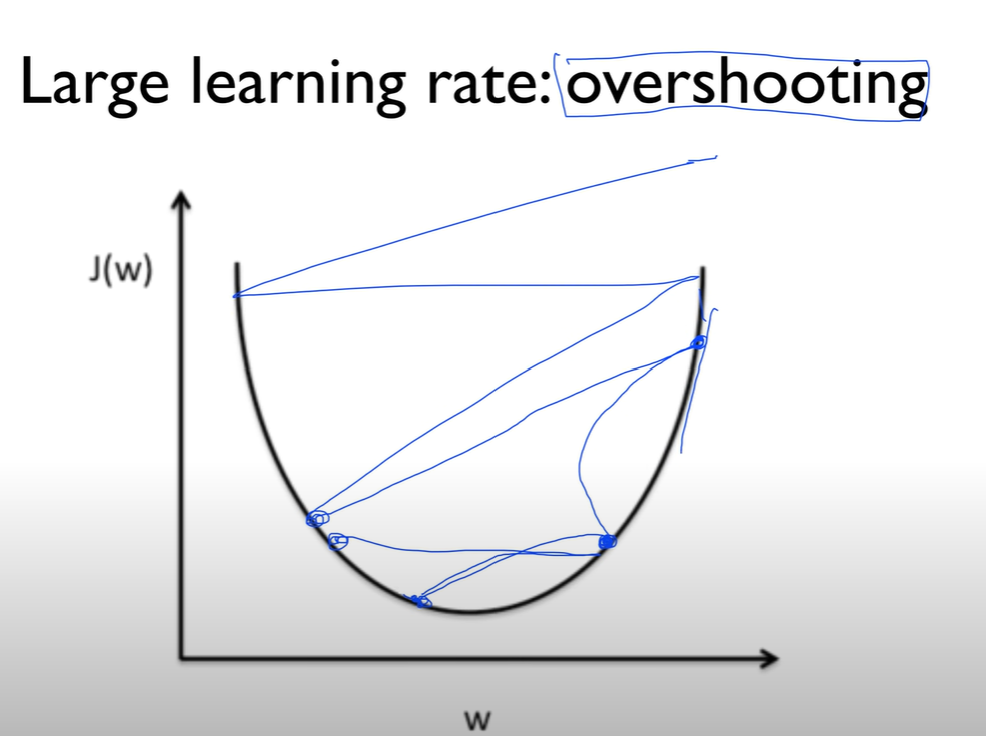
2) 너무 작은 learning rate을 설정한다면?
해져도 해산못함. 어느시점에서 stop 하게 됨. 최저점이 아님에도. 그런경향이 있어. 이것을 피하기 위해 cost 함수를 출력해보고 변하긴 하는데 너무 작다 하면 learning rate 조금 올려서 해보기.
learning rate을 정하는 답은 특별한 답은 없음
보통 0.01로 작해보고 ~ 좀 크고 작게 계속 관찰하기.
data preprocessing 선처리 하는 방법
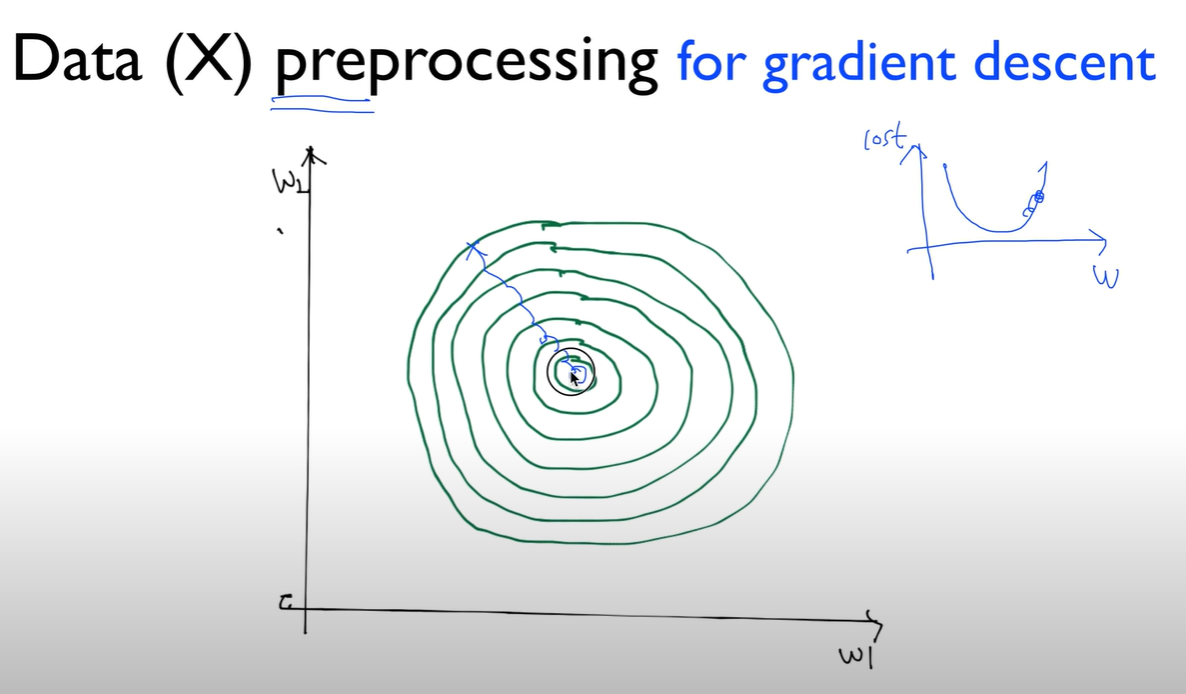
가끔 선처리 할 이유가 있다.
원하는 것은 어떤 점에서 시작하면 우리가 어떤 스텝식 경사면 따라 내려가서 최고로 낮은 지점에 도착하는 것이 목표.
예시)

우리가 가진 데이터의 값중 x의 값과 x2의 값 차이가 크게 난다면?
이전과 같은 선을 그려본다면 ?
어떤 알파값을 잡았을때, 저기가 너무 좁아서 알파값이 너무 좋은 값임에도 불구하고 밖으로 가면 튀어남. 이것을 주의해야 한다.
이렇게 데이터 값에 큰 차이가 있을 경우에, nomalized 할 필요가 있다.
여러가지 방법이 있는데, 오리지날이 2차원 형태로 저런 형태로 흝어져있다면 보통 많이 쓰는게 zero-centered data. data의 중심이 0되게 취하기.
가장 많이 쓰는것. 어떤 이 값이 이 값 전체의 범위가 어떤 형태의 범위 안에 항상 들어가도록 nomalized 하는 것.
learning rate도 잘 잡은 거같은데 이상하면, 데이터 중에 차이가 크게 나는것이 있는지, 이 전처리를 했는지 하면 됩니다.

하는 방법 매우 간단.
x의 값들이 있으면 x의 값을 여러분이 계산한 평균과 분산의 값을 가지고 나누기. \
이런 형태의 nomalization은 Standardization 이라고 하는데 여러가지 nomalization이 있는데 선택해서 x 데이터를 처리해보는 것도 머신러닝의 좋은 성능을 발휘하기 위한 한 방법일 수 있다.
Overfitting
머신러닝의 가장 큰 문제.
머신러닝이 학습을 통해서 모델을 만드는데 이 학습 데이터에 너무 딱 잘 맞는 모델을 만들어 낼 수 있다. 그렇게 되면 이게 학습데이터를 다시 가지고 물어보면 답을 잘하겠지만 test 데이터나 실제 데이터 잘 안맞는 경우가 있다.
Overfitting 줄이는 법
- Training data 더 많이
- features 수 줄이기
- Regularzation (일반화 시키기) - 기술적인 방법
Regularzation
일반화 시키기.
- weight 너무 큰 값을 가지지 말자.

decision boundary를 구부리는 거 자체를 overfitting 이라고 하는데 이것을 좀 피자. 라는 것.
편다는 의미는 값이 좀 wight 이 좀 적은 값을 가진다는 의미
구부린다는 것의 의미는 어떤 특정한 wight이 굉장히 큰 값을 가질경우 구부러 지게 된다.

이것을 하기 위해서는
cost 함수 설명할때 최적화 최소화 하는게 목표였는데 이 cost 함수에 이 틈을 추가 시켜 준다.
여러가지 형태로 regularization 할수 있는데
하나의 상수를 둘수 있다. 이것을 regularization strength 라고 함.
이것을 tensorlfow로 구현시 굉장히 쉽게 구할수 있다.
Jinwoo Park
5년 전
좋은 강의 공유해주셔서 감사합니다. 강의 내용중 Regularization에 대해 질문 드리고 싶은 것이 있습니다.
-
충분히 많은 개수의 training set이 있다고 가정할때, Regularization을 하는 것은 오히려 모델의 정확도를 떨어뜨리지 않을까요? 이미 잘 만들어진 모델을 변형시키는 것과도 같을 것 같아서요.
-
만약 모델이 w_3 x3 + w_2x2 + w_1*x1 + c 와 같은 형태를 띄고 있으며, x1, x2, x3 중 유독 Overfitting을 유발하는 feature가 x3라고 할때 - 즉, x3가 유독 특이점(outlier)을 많이 갖고 있는 경우- 제시된 Regularization 방식처럼 모든 w_1, w_2, w_3에 대해 같은 효과를 적용시키는 것은 불합리한 부분이 있어보입니다. 이런 상황을 방비한 대책같은게 있을까요?
-
적당한 Lambda 값을 선택하는 방법은 무엇일까요? 떠오르는 가장 단순한 방법으로는 Lambda 값을 다르게 하여 각각 학습을 진행한 이후, 각 결과 모델의 Train Accuracy를 계산해 비교하는 방법이 있을것 같습니다만, 이런 방법은 training data set이 방대할수록 비효율 적일 것 같다는 생각이 듭니다. 이에 대한 고견을 여쭤보고 싶습니다.
읽어주셔서 감사합니다.
답변 :
https://stackoverflow.com/questions/41032889/better-use-of-regularization#
