이 글은 Geoffrey Huntley의 How to Ralph Wiggum을 읽고 풀어쓴 해설입니다.
들어가며
2025년 중반, 호주의 오픈소스 개발자 Geoffrey Huntley가 염소 농장에서 루프 하나를 고안했습니다.
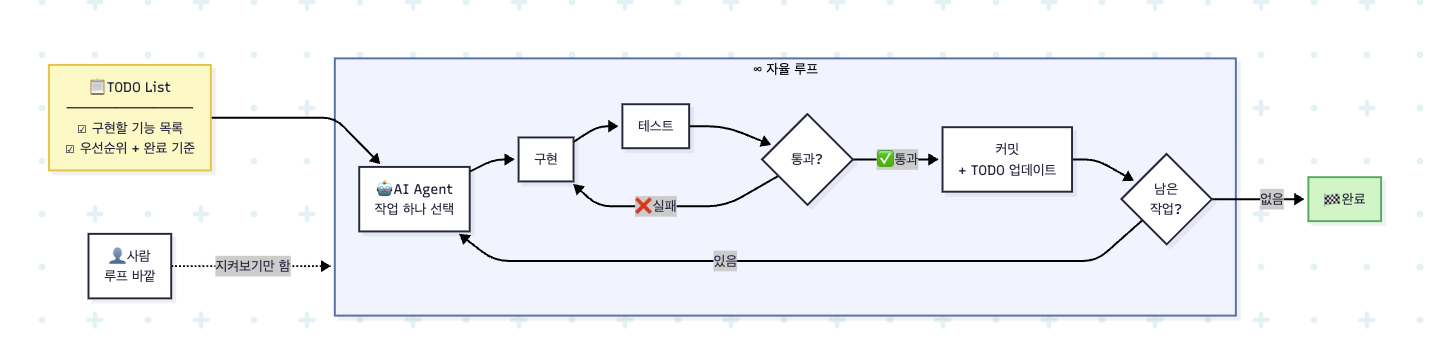
AI에게 작업을 시키는 게 아니라, AI가 스스로 돌 수 있도록 환경을 설계하는 방식입니다. 이름은 심슨의 캐릭터 Ralph Wiggum에서 따왔습니다. 멍청하지만 절대 포기하지 않는 Ralph처럼, 실패해도 루프를 계속 돌린다는 데서요.
The Ralph Wiggum Technique은 2025년 말 개발자 커뮤니티를 강타했습니다. Matt Pocock 같은 유명 개발자들이 트위터에서 바이럴시켰고, 유튜브 튜토리얼이 쏟아졌고, 커뮤니티 fork만 수백 개가 생겼습니다. "하룻밤 자고 일어나면 기능이 구현돼 있다"는 후기가 밈처럼 돌았고, Huntley 본인은 이 방법으로 LLVM 컴파일러를 탑재한 프로그래밍 언어를 AI 혼자 만들어냈습니다. "코딩(typing)은 죽었다."는 선언이 커뮤니티를 달궜습니다.
급기야 Anthropic이 공식 Claude Code 플러그인(/plugin ralph)으로 채택했습니다. 커뮤니티는 환호했습니다.
그리고 Huntley의 트윗이 올라왔습니다.

플러그인은 랄프 루프의 루프만 흉내냈다는 평가였습니다. 스펙 기반 개발, 독립적 context window, 완료 게이트 등의 Ralph를 Ralph답게 만드는 원칙들은 빠져 있었기 때문입니다.
루프라는 형태만 가져갔고, 그 형태가 나온 이유는 없었습니다.
이 글은 그 이유들을 하나씩 풀어쓴 해설입니다. Ralph가 왜 그렇게 설계됐는지, 각 원칙이 어떤 LLM의 한계를 막는지를 중심으로 작성하였습니다.
Ralph가 만들어진 배경
Huntley가 AI에게 작업을 맡겼을 때 왜 결과가 들쭉날쭉한지, 왜 어떤 날은 되고 어떤 날은 안 되는지, 원인을 추적했더니 LLM의 작동 방식에서 반복적으로 나타나는 패턴 네 가지가 있었습니다.
AI의 골든 타임은 생각보다 짧다. Anthropic은 200K 토큰 컨텍스트 윈도우를 제공한다고 하지만, 윈도우 끝에 가까워질수록 AI는 앞에서 읽은 스펙을 사실상 무시하기 시작합니다. 한 세션에 작업을 몰아넣을수록 AI는 점점 멍청해집니다.
세션이 끊기면 모든 걸 잊는다. 그렇다고 세션을 길게 유지하는 것도 답이 아닙니다. 컨텍스트 압축이 일어나기 시작하면 디테일이 무너지고, AI는 처음에 잡았던 방향을 서서히 놓칩니다. 짧게 끊으면 맥락이 사라지고, 길게 늘이면 품질이 붕괴됩니다.
AI는 완료를 선언하기 쉽다. LLM은 RLHF 훈련 과정에서 사람이 만족스러워하는 응답에 보상을 받습니다. "구현했습니다"는 개발자를 기쁘게 합니다. 그 결과 LLM은 실제로 완료됐는지와 무관하게, 완료처럼 들리는 시점에서 멈추려는 경향이 생깁니다. 테스트를 돌리지 않았어도, 엣지 케이스를 빠뜨렸어도, 외부에서 거절당하지 않는 한 스스로 멈춥니다.
프로젝트 규칙을 모른다. 매 세션마다 AI는 이 프로젝트의 컨벤션, 팀의 결정 사항, 금지된 패턴을 처음 보는 상태로 시작합니다. 알려주지 않으면 인터넷에서 가장 흔한 패턴으로 코드를 씁니다.
Huntley는 이 네 가지를 각각 설계 결정으로 막았습니다. 한 번에 작업 하나로 컨텍스트를 통제하고, 디스크에 상태를 기록해서 세션 간 기억을 대체하고, 테스트 통과를 커밋 조건으로 걸어서 완료 선언을 막고, AGENTS.md에 프로젝트 규칙을 적어두어 매 세션 시작 시 결정론적으로 AI에게 읽힙니다. Ralph의 각 구성 요소를 보면 이 네 가지 대응 방식이 하나씩 녹아 있습니다.
Ralph의 구조: 3단계, 2개 프롬프트, 1개 루프
복잡한 오케스트레이션 프레임워크가 없습니다. 파일 몇 개와 루프 하나입니다.
Phase 1: 요구사항 정의 (specs/)
Phase 2: Planning 루프 → IMPLEMENTATION_PLAN.md 생성
Phase 3: Building 루프 → 구현 + 테스트 + 커밋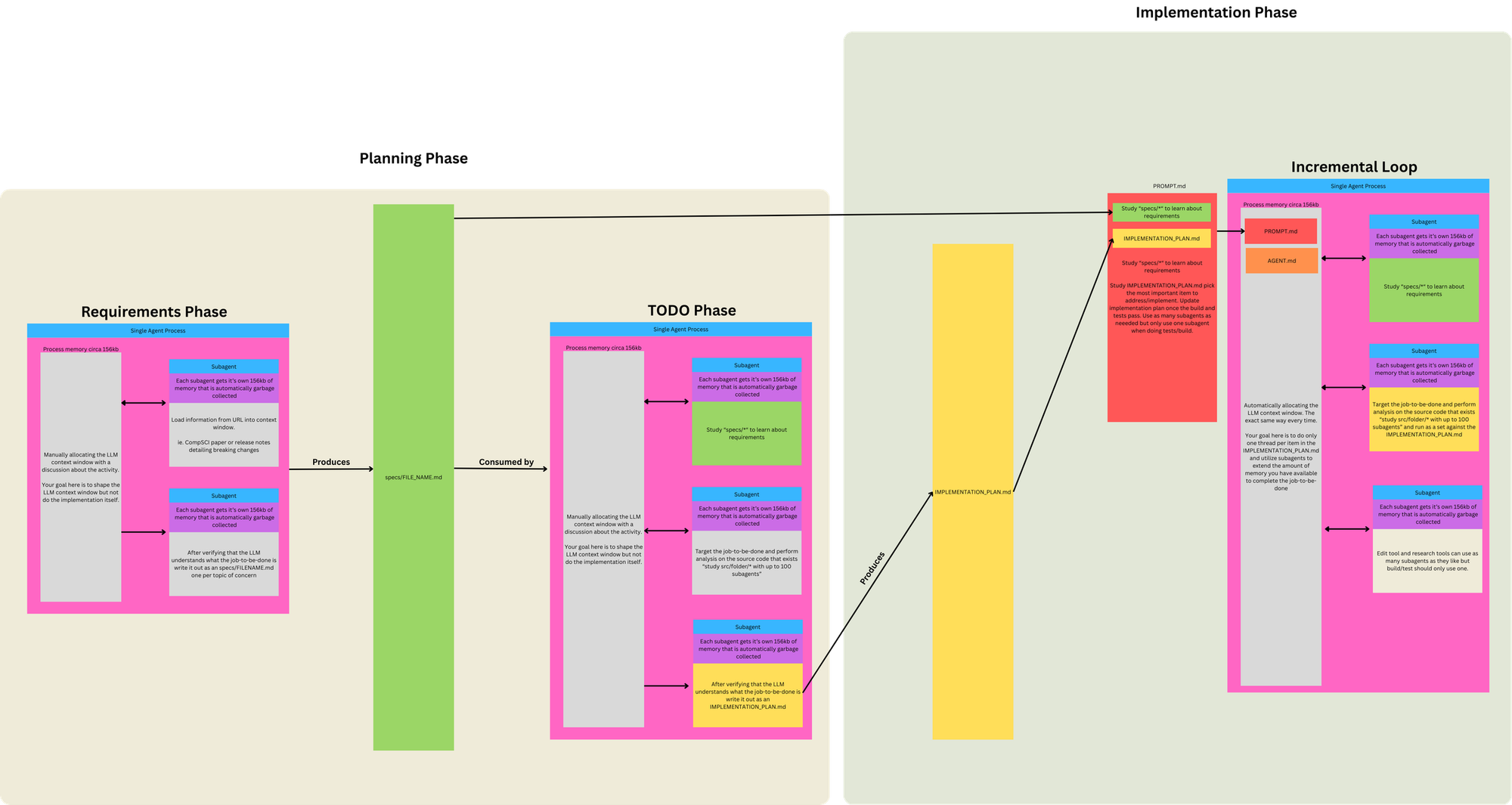
루프 자체는 한 줄짜리 bash입니다.
while :; do cat PROMPT.md | claude; done이 루프가 한 번 돌 때마다 AI는 새로운 컨텍스트 윈도우에서 시작합니다. 직전 세션이 무엇을 했는지는 디스크에 기록된 파일로만 알 수 있습니다.
| 파일 | 역할 |
|---|---|
specs/*.md | 무엇을 만들어야 하는지. 요구사항 명세 |
AGENTS.md | 이 프로젝트에서 AI가 알아야 할 규칙. 빌드/실행 명령, 금지 패턴 등 |
PROMPT_plan.md | Planning 루프 지시문. 스펙과 코드 간 갭 분석 후 작업 목록 생성 |
PROMPT_build.md | Building 루프 지시문. 작업 하나 선택, 구현, 테스트, 커밋 |
IMPLEMENTATION_PLAN.md | 루프 간 공유 상태. 남은 작업 목록 |
Planning 루프가 스펙과 현재 코드를 비교해 IMPLEMENTATION_PLAN.md를 뽑아내면, Building 루프는 거기서 작업 하나를 골라 구현하고, 테스트가 통과되면 커밋과 목록 갱신까지 처리합니다. 루프가 재시작되면 다음 AI 인스턴스는 이 파일들을 읽고 상태를 복원합니다. 세션이 끊겼어도 프로젝트는 멈추지 않습니다.
원칙 1: 컨텍스트는 한 번에 하나
PROMPT_build.md는 AI가 작업 목록에서 항목을 하나 골라 구현하고, 테스트를 통과시킨 뒤 커밋하는 흐름을 따르도록 구성되어 있습니다. 커밋이 끝나면 루프가 다시 시작됩니다.
Huntley가 실험으로 도출한 수치를 보면, Anthropic이 200K 토큰이라고 광고하는 컨텍스트 윈도우에서 실제 추론에 활용되는 범위는 40~60%에 그친다고 합니다. 이 구간을 '스마트 존'이라 부릅니다. 작업 하나에 전체 컨텍스트를 집중하면 AI는 스마트 존 안에서 계속 작동합니다.
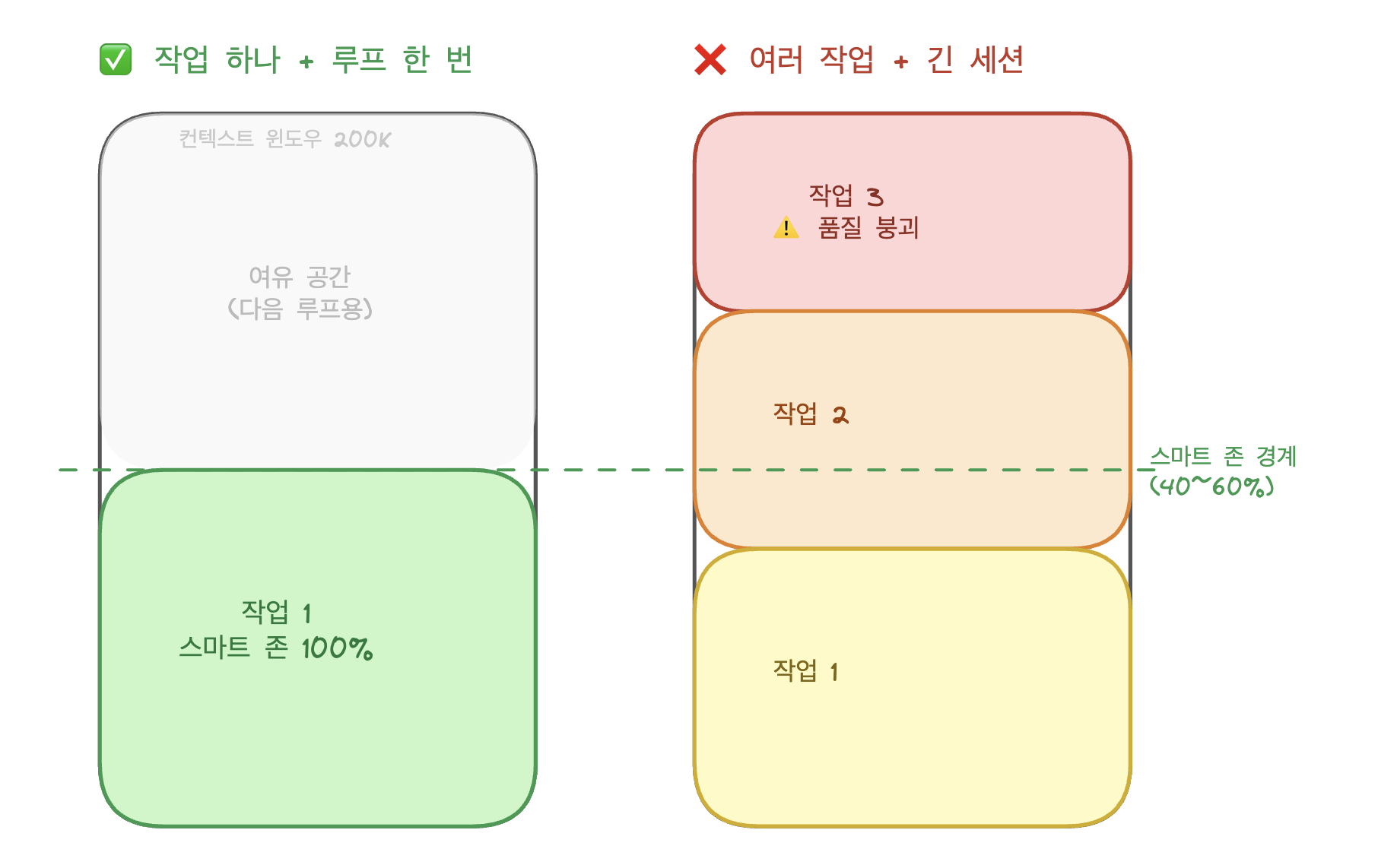
여러 작업을 한 세션에 넣으면 컨텍스트가 분산되고, 세션 중반을 넘어서면 앞서 읽었던 스펙이 사실상 반영되지 않습니다.
부하(context window에)가 큰 작업은 서브에이전트에 맡깁니다. URL 조회, 외부 문서 검토, 대용량 파일 분석처럼 무거운 처리는 별도 에이전트에 위임하고, 각 서브에이전트는 약 156KB의 컨텍스트를 사용한 뒤 작업이 끝나면 메모리가 회수됩니다. 메인 컨텍스트는 구현 판단에만 활용합니다.
작업 하나가 마무리되면 루프가 처음부터 다시 시작되고, 새로 실행된 AI 인스턴스에게는 이전 맥락이 남아 있지 않습니다. 비효율적으로 보이지만, 여러 작업을 한 세션에서 처리하면 나중 작업이 앞서 내린 판단을 슬그머니 뒤엎어 버리고, 이미 끝난 줄 알았던 작업이 다음 루프에서 되살아납니다. 루프를 짧게 끊는 쪽이 전체를 빠르게 완주한다는 게 Huntley가 실험 끝에 내린 결론인 것 같습니다.
원칙 2: 디스크가 기억한다
Ralph에는 데이터베이스도, 벡터 스토어도, 메모리 모듈도 없습니다. 상태는 전부 디스크에 있는 파일입니다.
루프가 한 번 돌 때마다 AI 인스턴스는 새 컨텍스트 윈도우에서 시작하지만, 이전 세션이 무엇을 했는지, 어떤 결정을 내렸는지, 어디서 막혔는지는 모두 디스크에 남습니다. 기억을 파일에 위임했으니 AI 자신이 직접 기억할 것은 없습니다.
그 기억 장치가 IMPLEMENTATION_PLAN.md입니다. 매 루프 시작 시 AI는 이 파일을 읽어서 현재 상태를 파악하고, 작업을 마치면 완료 표시와 함께 발견한 것들을 기록하고 커밋합니다. 다음 인스턴스가 같은 파일을 읽으면 어디서부터 이어갈지 압니다.
할일 목록뿐 아니라 버그, 미결 문제, 아키텍처 결정 배경, 테스트 실패 경위까지 모두 쌓아두면 다음 인스턴스가 흐름을 끊기지 않고 이어갈 수 있습니다. PROMPT_build.md가 "발견한 문제는 즉시 IMPLEMENTATION_PLAN.md에 기록하라"고 명시한 것도 같은 이유입니다.
계획이 틀렸다면 Planning 루프를 한 번 더 돌리면 됩니다. AI가 스펙과 코드를 비교해 계획을 다시 씁니다. 사람이 맥락을 직접 정리해서 AI에게 다시 설명하는 것보다 빠르고, 틀린 계획을 붙들고 고민할 필요도 없습니다.
AGENTS.md는 용도 자체가 다른 파일입니다. 빌드 명령, 테스트 실행 방법, 코드 패턴처럼 세션이 바뀌어도 달라지지 않는 운영 정보가 여기 모입니다. 루프를 돌리며 발견한 패턴이나 반복된 실수도 마찬가지입니다.
다만 AGENTS.md는 간결하게 유지해야 합니다. 매 루프마다 전체를 읽기 때문에 파일이 비대해질수록 컨텍스트 윈도우를 낭비합니다. PROMPT_build.md가 "AGENTS.md는 운영 정보만 담아라. 진행 상황 업데이트나 작업 메모는 IMPLEMENTATION_PLAN.md에 적어라"고 명시하는 이유도 같습니다.
이 구조의 핵심은 가변과 불변을 나누는 데 있습니다. IMPLEMENTATION_PLAN.md에는 루프마다 바뀌는 프로젝트의 현재 상태가 담기고, AGENTS.md에는 루프와 무관하게 유지되는 운영 원칙이 쌓입니다. 세션 간 기억과 프로젝트 규칙, 이 두 가지를 파일 두 개로 감당하는 구조입니다.
원칙 3: 테스트가 백프레셔다
LLM을 RLHF로 훈련하면 사람이 만족스러워하는 응답에 보상이 주어집니다. "구현했습니다"는 응답은 언제나 개발자를 기쁘게 하죠. 때문에 실제로 완료됐는지와 무관하게, 완료처럼 들리는 시점에 멈추려는 경향이 생깁니다. 엣지 케이스를 빠뜨렸어도, 테스트를 돌리지 않았어도, 외부에서 거절당하지 않는 한 스스로 멈춥니다(혹은 Provider 업체들의 토큰 절약을 위한 학습일수도..).
Ralph에서 이 문제를 막는 장치가 테스트입니다. 품질을 나중에 확인하는 수단이 아니라, 커밋을 막는 게이트입니다. PROMPT_build.md에는 이렇게 적혀 있습니다.
When the tests pass, update @IMPLEMENTATION_PLAN.md,
then git add -A then git commit테스트를 통과하기 전에는 커밋 자체가 일어나지 않고, AI가 완료를 선언해도 게이트가 통과를 거부합니다.
이 흐름을 Huntley는 "acceptance-driven backpressure"라고 불렀습니다. 수용 조건은 사람이 쓰고, 통과 방법은 AI가 찾습니다. 스펙은 무엇을 검증할지만 정할 뿐, 구현 방식에는 손대지 않습니다.
빌드와 테스트의 비대칭 배분도 여기서 나옵니다. PROMPT_build.md에는 다음과 같이 적혀 있습니다.
You may use up to 500 parallel Sonnet subagents for searches/reads
and only 1 Sonnet subagent for build/tests.읽기·검색은 500개까지 병렬로 풀되, 빌드·테스트는 반드시 1개로 좁힙니다. 병목을 의도적으로 만들어 검증을 건너뛰지 못하도록 구조로 막습니다.
주관적인 기준도 게이트로 만들 수 있습니다. 코드 품질, 문서 톤, UX처럼 통과/실패를 프로그램으로 판정하기 어려운 영역은 LLM-as-judge 패턴으로 테스트를 구성합니다. AI가 기존 테스트 예시를 보고 언제 이 방식이 필요한지 스스로 파악합니다. 수용 기준이 주관적이어도 게이트를 빠져나가는 경로는 동일합니다.
Huntley가 PROMPT_build.md에 별도로 박아둔 지시도 있습니다.
DO NOT IMPLEMENT PLACEHOLDER OR SIMPLE IMPLEMENTATIONS.
WE WANT FULL IMPLEMENTATIONS.플레이스홀더를 넣으면 컴파일은 되고, 테스트를 얕게 작성하면 통과도 됩니다. 게이트가 제대로 작동하려면 기준 자체가 충분히 깐깐해야 합니다. 게이트의 강도는 결국 스펙을 쓰는 사람에게 달려 있다고 봅니다.
원칙 4: 사람은 루프 바깥에 있다
Huntley는 사람의 위치를 두 가지로 구분합니다. 루프 안(in the loop)과 루프 위(on the loop)입니다.
루프 안에 있다는 건 매 결정에 개입한다는 뜻입니다. AI가 작업을 선택할 때, 구현 방식을 고를 때, 테스트 결과를 해석할 때 사람이 참여합니다. 기존의 AI 코딩 어시스턴트 활용 방식이 대부분 이렇습니다. 겉보기엔 빠른 것 같아도, 루프가 돌 때마다 사람의 판단을 기다려야 하니 결국 사람이 병목이 되고 AI는 혼자 달릴 수 없습니다.
Ralph에서 사람은 루프 위에 있습니다. 루프가 돌아가는 걸 지켜보다가, 반복적으로 실패하는 패턴이 보이면 환경을 손봅니다. AGENTS.md에 운영 규칙을 추가하거나, PROMPT에 가드레일을 넣습니다. Huntley는 이걸 "signs(표지판)"라고 불렀습니다. AI가 같은 곳에서 반복해서 길을 잃을 때, 표지판을 세워두면 다음 루프부터는 그 실수가 사라집니다.
사람이 개입하는 형태는 네 가지로 좁혀집니다.
- 루프를 시작하거나 멈추는 것
- 실패 패턴에 맞게
PROMPT를 수정하는 것 - 궤도를 벗어났을 때 Planning 루프를 다시 돌려 계획을 새로 만드는 것
- 테스트를 보강해서 게이트를 더 깐깐하게 만드는 것
이 네 가지 밖에서 개입하면 루프 위가 아니라 루프 안으로 들어가는 것입니다.
Huntley는 처음부터 완벽한 PROMPT를 만들려 하지 말라고 강조합니다.
처음부터 완벽한
PROMPT를 만들려 하면 대부분 쓸모없는 짓이 됩니다. Ralph가 어디서 막히는지 보기 전에는, 무엇을 막아야 할지 알 수 없습니다. 실패 패턴이 실제로 반복된다는 걸 확인한 다음에만 손을 씁니다. 한 번 실패한 건 Ralph가 다음 루프에서 스스로 고칠 수도 있습니다.
AGENTS.md를 키우는 방식도 같습니다. 처음부터 세세하게 채워두는 게 아니라, 루프를 돌면서 발견한 것들만 쌓습니다. 파일이 비대해지면 매 루프마다 읽는 컨텍스트 윈도우를 그만큼 잡아먹습니다. 원칙 1에서 컨텍스트를 한 작업에 집중하는 이유와 같습니다.
사람 몫으로 남는 건 뭘 만들지 정하고, 어떤 기준으로 검증할지 결정하고, 루프가 반복해서 틀리는 부분에 표지판을 세우는 것입니다. 작업 선택이든, 구현 판단이든, 테스트 통과 여부든 그건 Ralph 몫입니다. 사람이 루프 안으로 들어가는 순간, Ralph는 자율 루프가 아니라 비싼 자동완성에 가까워집니다.
마치며
Huntley가 선언한 "코딩(typing)은 죽었다. 소프트웨어 엔지니어링은 살아있다"는 말은 과격하게 들리지만, 제가 보기엔 틀린 말이 아닙니다. Ralph가 제안하는 건 AI에게 타이핑을 맡기는 것이고, 사람 몫으로 남는 건 뭘 만들지 정하고, 어떤 기준으로 검증할지 판단하고, 어디서 무너지는지 포착하는 것입니다.
"코딩은 죽었다"는 말이 불편하게 들리는 건, 코딩을 타이핑과 동일시하기 때문인 것 같습니다. Huntley가 말하는 건 키보드 입력의 종말이 아니라 역할의 이동입니다. 무엇을 만들지, 어떤 제약 조건이 있는지, 어디까지가 완료인지를 판단하는 일은 여전히 사람 몫입니다. 그 판단을 구조로 표현하는 것이 소프트웨어 엔지니어링이고, Ralph는 그 구조를 LLM이 돌아갈 수 있는 환경으로 옮겨놓는 방식입니다.
저는 이 방법론을 PoC 프로젝트에 직접 적용해서 쓰고 있습니다. Huntley가 Ralph로 직접 만든 프로젝트인 loom 레포를 보면서 실제 구조가 어떻게 생겼는지 따라가며 specs/를 만들고, AGENTS.md에 프로젝트 규칙을 정리하고, 루프를 돌렸습니다. 문서나 글로만 읽을 때와 달리, 실제 코드베이스를 보면서 느낀 점들이 따로 있었습니다. 이 부분은 다음 포스팅에서 다룰 예정입니다.
한 가지 확신이 생긴 건, 아키텍처는 사람이 먼저 잡아야 한다는 점입니다. 어떤 컴포넌트가 어떤 책임을 가질 것인지, 어떤 흐름으로 어떤 컴포넌트와 소통할 것인지. 이 역할과 경계를 먼저 정의해두지 않으면 AI는 매 세션마다 다른 방식으로 구현합니다. 스타일이 달라지는 게 아니라 구조가 흔들립니다. "소프트웨어 엔지니어링은 살아있다"는 말이 와닿는 지점이 여기였습니다.
또 아쉬운 점은, 이미 규모가 커진 코드베이스에 Ralph를 적용하기는 쉽지 않다는 것입니다. 처음부터 Ralph 방식으로 짠 프로젝트라면 specs/와 코드가 함께 자라지만, 기존 코드베이스에 뒤늦게 적용하려면 LLM이 맥락을 파악할 수 있도록 스펙과 문서를 따로 정리하고 인덱싱하는 작업이 먼저 필요합니다. 그 자체가 적지 않은 공수입니다.
그럼에도 이 방법론의 매력은 빠른 개발 속도에만 있지 않습니다. AI로 코딩할 때 가장 지치는 순간이 있습니다. 안 되면 더 자세하게 설명하고, 그래도 안 되면 다시 설명하고, 컨텍스트가 쌓일수록 오히려 더 엉켜서 처음보다 못한 상태가 되는 그 루프입니다. Ralph는 바로 그걸 구조적으로 끊어줍니다. LLM에게 맥락을 어떻게 효율적으로 전달할 것인가는 AI와 함께 개발하는 한 계속 따라다닐 문제인데, 적어도 코딩에 있어서는 Ralph가 그 답의 방향을 잡아주는 것 같습니다. 앞으로도 적극적으로 써볼 생각입니다.
