광고 클릭 이벤트 집계 아키텍처를 공부하는 중에 Kappa 아키텍처를 처음 알게 되었습니다. 그래서 이에 대해 심도있게 알아가보겠습니다.
Kappa 아키텍처는 일괄 및 스트리밍 처리 경로를 동시에 지원하는 lambda 아키텍처의 단점을 보완하기 위해 등장한 아키텍처인데요. 먼저 데이터를 처리하는 두 방식에 대해 정리하고 넘어가겠습니다.
✏️ 스트림 처리 (stream processing)
- 데이터를 지속적이고 즉각적으로 처리하는 방식입니다.
- usecase : 실시간 스트리밍 방송, 실시간 추천 시스템
🙋 그럼 실시간 처리 (real-time processing)랑 같은거 아닌가요??
- 실시간 처리는 데이터 포인트 하나하나를 즉시 처리하는 것이고, 스트림 처리는 한 스트림 내의 데이터들을 지속적으로 처리하는 '근사적' 실시간 처리를 하는 것입니다.
- 스트림 내에는 여러 개의 데이터 포인트가 있는 것!
✏️ 일괄 처리 (batch processing)
- 일정량의 데이터를 모아서 한꺼번에 처리하는 방식입니다.
- usecase : 이미지 프로세싱, 머신러닝 모델 학습, 웹 로그 분석 및 리포트 생성
✏️ Lambda 아키텍처 간단 설명
lambda 아키텍처는 일괄 처리와 스트리밍 처리를 동시에 지원하는 아키텍처로 아래와 같은 구조를 가집니다.
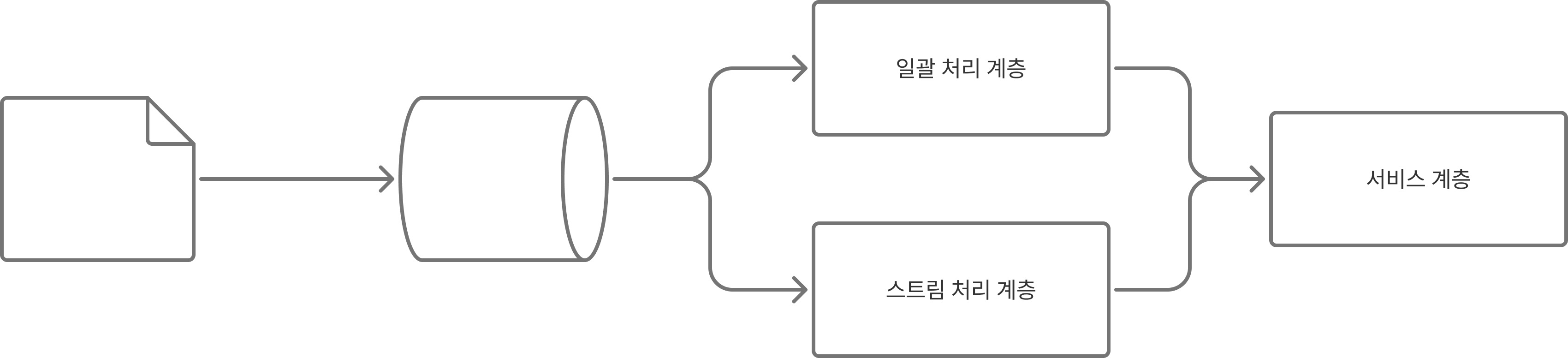
🔥 단점
1. 로직이 중복됨
- 구조도에서 볼 수 있듯이 '일괄 처리 계층' 과 '스트림 처리 계층' 이 분리되어 있으므로 각 계층에 맞는 코드 베이스를 분리해야 합니다. 따라서 디버깅이 복잡해지고 유지보수에도 비용이 많이 듭니다.
2. 일괄 처리에 비효율적
- 일부 usecase에서는 매 배치 사이클마다 데이터를 다시 처리해야하는 것이 매우 비효율적이라고 합니다.
- 아직 저에게는 잘 안와닿네요.... ㅎ
3. 복잡함
- 다양한 구성 요소가 각각의 소프트웨어에 따라 다르게 동작하기 때문에 운영과 유지보수가 매우 복잡합니다.
지금부터는 Kappa 아키텍처가 어떻게 'lambda' 아키텍처의 단점을 보완하고 어떤 특징을 가지는지 알아보겠습니다. 🏃♀️
✨ Kappa 아키텍처 소개
⬇️ 간략한 아키텍처 구조도

- 단일 스트림 처리 엔진을 사용하여 실시간 데이터 처리 및 일괄 처리를 모두 수행하는 방식입니다.
아키텍처 구조도만 보고도 lambda 아키텍처와의 차이점을 한 눈에 확인할 수 있습니다. 또한 이러한 아키텍처를 가지기 때문에 lambda 아키텍처의 단점이었던 1. 로직이 중복되는 문제가 바로 해결되는 것을 확인할 수 있습니다.
그럼 단일 스트림 처리 계층에서 일괄 처리까지 어떻게 수행할 수 있는 것일까요?
생각보다 정말 간단했습니다. 메시징 엔진으로부터 저장된 스트리밍 데이터를 불러와서 일괄 처리 방식으로 데이터를 처리하면 됩니다.
이것이 가능한 이유는 Kafka와 같은 메시지 큐에 data retention (데이터 보존) 기능을 지원하기 때문입니다.
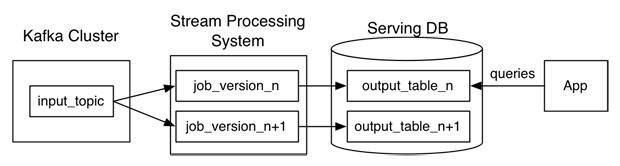
- 각각의 처리한 스트림들을 offset으로 테이블을 나누어 따로 저장해둡니다. 일괄 처리를 할 때는 필요한 offset 의 데이터를 가져오면 됩니다.
✅ Upstream Replay
- 이와 같은 처리 방법을
Upstream Replay라고 합니다.- 데이터가 처음 생성되거나 수집되는 시점에서 다시 데이터를 처리하는 방법입니다.
🤩 장점
1. 실시간 처리가 가능함
- 스트림 처리를 지원하므로 당연한 내용입니다.
2. 비용 효율적임
- 일괄 (batch) 처리 계층이 따로 필요하지 않으므로
Lambda아키텍처보다 비용 효율적입니다.
3. 간단함
- 이 또한 일괄 (batch) 처리 계층이 없기 때문입니다.
🔥 단점
1. 스트리밍 처리에 비해 일괄 처리는 성능이 떨어짐
- 스트리밍 데이터를 백트래킹하여 처리하는 것은 배치 데이터를 백트리킹하여 처리하는 것보다 성능이 떨어지기 때문입니다.
2. 데이터 히스토리가 제한적임
- 하나의 데이터 파이프라인 (스트림) 만 사용하기 때문에 과거 데이터는 Kafka 같은 로그 시스템에 의존하게 됩니다. 그러나 Kafka는 데이터를 무한으로 보존하지 않고, 지정해준 보존 시간이나 용량을 초과하면 삭제하기 때문에 데이터 히스토리가 제한적일 수밖에 없게 되는 것입니다.
📒 참고 문헌
- Introduction to Unified Batch and Stream Processing of Apache Flink : https://www.alibabacloud.com/blog/introduction-to-unified-batch-and-stream-processing-of-apache-flink_601407
- Kappa Architecture: Stream Processing in Big Data Analytics : https://medium.com/data-and-beyond/kappa-architecture-stream-processing-in-big-data-analytics-e539f4bf63cd
- What Is the Kappa Architecture?: https://hazelcast.com/foundations/software-architecture/kappa-architecture/
- Lambda Architecture : https://www.snowflake.com/guides/lambda-architecture/
