이런 분들께 이 글을 추천합니다.
- 이미 브라우저의 렌더링 동작에 대해 "기초적인" 지식이 있으신 분
- 브라우저 렌더링 과정 중 Parsing에 집중 해보고 싶은 분
이 글의 순서는 다음과 같습니다.
- 서문
HTML Parsing방법CSS Parsing방법DOMandCSSOM
혹시나 빠르게 훑어보고만 싶다면, 실제로 parsing의 예제를 담은
Tokenization Example만 보셔도 좋습니다! (우측의 목차로 이동해주세요!)
1. 서문
면접관 : 주소창에 www.google.com을 입력했을때 일어나는 과정에 대해서 설명해보세요.
다음과 같은 질문을 얼마나 많이 들어보셨나요?
정말 많은 글에서도 강조되고 언급되는 만큼 웹개발자에게 중요한 질문으로 자리잡고 있습니다.
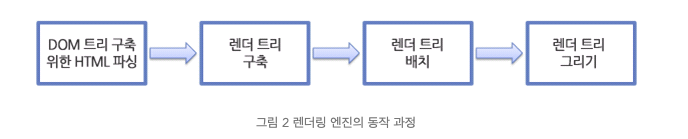
Rendering Engine이 동작하여 화면에
저도 마찬가지로 웹 개발자로서 정말 여러번 마주하는 개념이었는데요.
한번 공부하는김에 제대로 공부를 진행해보고 싶어. 이번 기회에 오로지 Parsing만 담아서 학습을 진행해보려 합니다.
부스트캠프 기간중에서도 Parsing에 대해 공부했던 기억을 더듬어 가면 좋겠다 싶었습니다!

깊이 있는 학습을 진행하기 위해서 이번 글은 오로지 Parsing 만을 담습니다.
제가 찾을 수 있는 범위 내에서 브라우저가 Parsing을 하는 내용을 최대한 담아보았으니 잘 봐주시길 바랍니다!
2. HTML Parsing

HTML은 HyperText Markup Language의 약자로, 웹의 기반을 이루며 웹 페이지에 구조와 의미를 제공합니다. HTML 파싱의 내부 작동 원리를 이해하는 것은 웹 콘텐츠를 프로그래밍적으로 생성, 분석, 또는 수정하고자 하는 개발자와 디자이너에게 필수적입니다.
HTML Parsing 과정은 웹 개발에 있어서 당연히 필수적인 부분입니다. 이 과정을 통해서 웹 페이지를 읽어내어 내가 원하는 정보를 추출하고 그 내용을 활용하곤 합니다. 혹은 검색엔진에게 노출되도록 하는 과정에서도 유용하게 사용됩니다.
하지만, 이 글에서 다루는 과정은 오히려 반대입니다.
브라우저는 HTML Parser를 통해서 HTML을 읽어내고 그 구조와 의미를 분석하도록 합니다. 기본적으로 HTML 파싱은 HTML 문서를 구성 요소로 분해하고 Document Object Model (DOM) 을 구성하는 과정을 포함합니다.
해당 단락에서는, HTML의 파싱과정을 자세히 살펴볼 예정입니다.
아래의 과정은 대표적으로 다음과 같습니다.
HTML의 기본적인 구조에 대해서 이해하기HTML Parsing과정에 대해서 이해합니다. (tokenization,tree construction)
1. basic HTML document
HTML Parsing 과정을 이해하기 전에 기초적인 HTML을 먼저 이해합니다.
HTML은 웹 페이지를 생성하기 위한 표준 마크업 언어입니다. HTML은 웹 페이지의 구조를 정의하고, 텍스트, 이미지, 링크, 폼, 버튼 등 웹 페이지에 표시되는 다양한 요소를 배치하고 스타일링할 수 있습니다.
HTML은 '태그'라고 불리는 꺾쇠 괄호(<>)로 둘러싸인 명령어를 사용하여 웹 페이지의 구조를 만듭니다. 이러한 태그는 대게 시작 태그와 종료 태그로 구성되며, 그 사이에 웹 페이지의 실제 내용이 들어갑니다. 예를 들어, <p>는 단락(paragraph)을 시작하는 태그이고, </p>는 단락을 끝내는 태그입니다.
HTML 문서는 브라우저에 의해 해석되어 사용자에게 웹 페이지의 형태로 표시됩니다.
<!DOCTYPE html> <!-- 문서 타입 선언 (DOCTYPE): HTML5를 의미 -->
<html> <!-- HTML: 루트 요소 -->
<head> <!-- Head: 메타데이터 부분 -->
<meta charset="UTF-8"> <!-- 문자 인코딩 -->
<title>페이지 제목</title> <!-- 페이지 제목 -->
<link rel="stylesheet" type="text/css" href="styles.css"> <!-- 연결된 스타일시트 -->
<script src="script.js"></script> <!-- 자바스크립트 파일 -->
</head>
<body> <!-- Body: 실제 보이는 내용 -->
<h1>제목</h1> <!-- 제목 -->
<p>단락입니다.</p> <!-- 단락 -->
<img src="image.jpg" alt="이미지 설명"> <!-- 이미지 -->
<a href="https://www.example.com">링크</a> <!-- 링크 -->
<!-- 기타 요소 -->
</body>
</html>-
<!DOCTYPE html>: HTML5 문서를 나타내는 DOCTYPE 선언입니다. -
<html>: HTML 문서의 루트 요소입니다. 모든 다른 HTML 요소는 이 태그 내부에 위치해야 합니다. -
<head>: 이 부분에는 페이지의 메타데이터가 들어갑니다. 예로는 페이지 제목, 문자 인코딩, 외부 스타일시트와 자바스크립트 파일 등이 있습니다. -
<body>: 이 부분에는 웹 페이지의 실제로 보이는 내용이 들어갑니다. 예로는 텍스트, 이미지, 링크, 제목, 단락 등이 있습니다.
이제는 본격적으로 HTML Parsing Process에 대해서 학습하겠습니다.
HTML Parsing Process
HTML Parsing은 HTML document를 분석하고 그 구조적인 구성 요소인 tag, attrivutes, content를 추출하여 의미있는 model을 만들어냅니다.
즉 DOM(Document Object Model) 를 생성해냅니다.
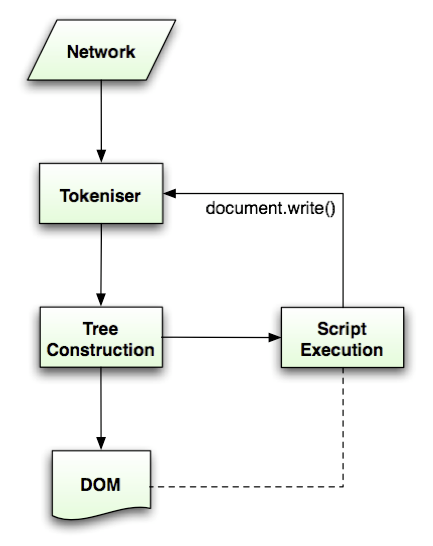
HTML Parsing Process의 일련의 과정을 담은 도식도 입니다
1. HTML Token
Tokenization 은 HTML 파싱 과정에서 가장 기본적인 단계입니다. raw HTML을 token이라고 불리는 더 작은 단위로 분해하는 역할을 담당합니다. 토큰은 HTML 문서를 구성하는 개별적인 요소를 의미합니다. 즉 token은 documnet 의 최소한의 가치를 가지고 있습니다.
원시(또는 raw) HTML 코드란?
웹 브라우저에 의해 아직 처리되지 않은, 원본 상태의 HTML 코드를 의미합니다. 이는 HTML 문서를 구성하는 태그, 속성, 텍스트 등이 포함되어 있는 초기 형태의 코드입니다. 원시 HTML 코드는 일반적으로 텍스트 에디터나 코드 에디터에서 볼 수 있으며, 웹 브라우저의 "페이지 소스 보기" 옵션을 통해서도 확인할 수 있습니다. 원시 HTML 코드는 파싱 과정을 통해 브라우저에 의해 해석되고, 이후에 사용자에게 보여지는 웹 페이지의 구조와 내용을 형성합니다. 이 코드는 직접 작성될 수도 있고, 서버에서 동적으로 생성되어 클라이언트에 전송될 수도 있습니다.
HTML Tokenization은 다음과 같은 과정을 수행합니다.
HTML 코드를 토큰으로 분해하기
토큰화 과정 중 HTML 코드를 문자단위로 스캔하여 패턴을 식별하고 다양한 유형의 토큰을 인식할 수 있습니다. 이 때 Parsing Algorithm은 코드를 분석하며 token idetification 을 통해서 특정 문자와 순서를 찾아 냅니다. 예를 들어서 <를 만나면 태그의 시작을 표시하고 이는 토큰의 존재를 의미합니다. 이 과정에서 HTML 코드는 순차적으로 분석되며 파서가 토큰을 동적으로 식별하는 순간 코드에서 분리합니다. 이 과정은 전체 HTML 코드가 토큰화 될때 까지 진행됩니다.
토큰의 종류
-
<tag>: 시작 태그는 HTML 요소의 시작을 나타내며<tag>문법으로 표시됩니다. 예를 들어,<p>는 단락의 시작 태그를 나타냅니다. 시작 태그는 요소 유형에 대한 정보를 제공하고 속성을 포함할 수 있습니다. -
</tag>: 종료 태그는 HTML 요소의 종료를 나타내며</tag>문법으로 표시됩니다. 예를 들어,</p>는 단락 요소의 종료 태그를 나타냅니다. 종료 태그는 시작 태그에 의해 정의된 구조를 반영하며 문서의 계층적 구조에 기여합니다. -
<tag />: 일부 HTML 요소는 자체적으로 종료될 수 있으며 별도의 종료 태그가 필요하지 않습니다. 자체 종료 태그는 '' 문법으로 표시됩니다. 예를 들어, '
'는 줄 바꿈 태그를 나타냅니다. 자체 종료 태그는 일반적으로 내용이 없거나 특별한 처리가 필요한 요소에 사용됩니다. -
Text: 텍스트 토큰은 HTML 요소 내의 문자 내용을 나타냅니다. 이들은 일반 텍스트, 문자열 또는 태그나 다른 특별한 토큰의 일부가 아닌 문자 순서를 포함합니다. 텍스트 토큰은 HTML 문서의 보이는 내용에 기여합니다. -
주석: HTML 주석은 코드 내에 노트나 주석을 추가하는 데 사용되는 토큰입니다. 이들은 '' 문법으로 표시됩니다. 주석은 개발자에게 추가 정보나 지침을 제공하는 방법으로, 보이는 내용으로 렌더링되지 않습니다. -
DOCTYPE: DOCTYPE 토큰은 문서 유형 선언을 나타내며 사용되는 HTML 버전에 대한 정보를 제공합니다. 이것은 HTML 문서의 시작 부분에서 특정 문법으로 표시됩니다. 예를 들어 ''. DOCTYPE 토큰은 문서가 브라우저나 파서에 의해 올바르게 해석되도록 합니다.
여기까지 Tokenization 과 Token의 종류에 대해서 학습을 진행했습니다.
다음은 Tokenzation Algorithm에 대해서 학습을 진행합니다.
2. Tokenization Algorithm
Tokenization Algorithm 은 HTML 파싱 과정 중에서 가장 중요한 단계 입니다. 이 과정중에서 파싱 도중 다양한 유형의 토큰을 식별하고 처리하기 위한 논리를 정의합니다.
1. 변수와 데이터 초기화
이 단계에서 파서는 토큰화 도중 생성된 토큰을 저장하기 위해 필요한 변수와 데이터 구조를 설정합니다. 이는 배열, 연결 리스트 또는 다른 적절한 데이터 구조를 초기화하는 것을 포함할 수 있습니다.
또한 알고리즘은 파싱 과정을 추적하기 위해 필요한 플래그나 상태 변수를 초기화합니다. 이러한 플래그는 특정 조건을 나타내거나 알고리즘의 흐름을 제어하는 데 사용될 수 있습니다.
Tokenization Algorithm은 상태상태 기계(State Machine)를 바탕으로 설명할 수 있습니다. HTML 문서를 읽으면서 Data state,Tag open state라는 두가지 상태를 가지게 됩니다.
초기상태는 Data state로 초기화 되어 있습니다.
2. HTML 코드 스캔 시작:
HTML 코드는 첫 번째 문자부터 스캔을 시작하여 토큰화 과정을 시작합니다. 파서는 코드의 각 문자를 검사하여 HTML 구조에서의 역할을 분석합니다.
3. 토큰 경계 식별:
이 단계에서 토큰화 알고리즘은 특정 문자 패턴과 시퀀스를 기반으로 다양한 유형의 토큰을 인식하고 구분합니다. 알고리즘은 토큰의 경계를 식별하고 생성될 토큰의 유형을 결정합니다.
<를 만나게 되면, Tag open state 상태로 변경됩니다. 그리고 여러 문자열을 지나치게 되지만 >문자를 만날때 까지 상태를 변화하지 않다가 >문자를 만나고 나서 state를 다시 Data state로 변경하고, 기존의 <``>를 통해서 만들어지게 된 영역은 Tokenization이 진행됩니다.
4. 시작 태그 처리:
알고리즘이 < 문자를 감지하면 이어지는 문자가 시작 태그를 나타내는지 확인하기 위해 검사합니다. 태그 이름과 관련된 어트리뷰트는 HTML 코드에서 추출됩니다.
시작 태그 토큰이 생성되어 태그 이름과 어트리뷰트를 포함하며, 토큰 데이터 구조에 저장됩니다.
5. 종료 태그 처리:
</ 시퀀스를 만나면 알고리즘은 이어지는 문자를 종료 태그로 해석합니다. 태그 이름은 코드에서 추출됩니다.
종료 태그 토큰이 생성되어 태그 이름을 포함하며, 토큰 데이터 구조에 추가됩니다.
6. 자체 종료 태그 처리:
알고리즘이 자체 종료 태그, 예를 들어
을 만나면, 자체 종료 태그 토큰을 생성합니다. 자체 종료 태그와 관련된 모든 어트리뷰트가 토큰에 포함됩니다.
자체 종료 태그 토큰이 토큰 데이터 구조에 추가됩니다.
7. 텍스트 내용 처리:
태그나 특별한 시퀀스의 일부가 아닌 문자는 텍스트 내용으로 간주됩니다. 알고리즘은 연속된 문자를 텍스트 토큰으로 수집하고 토큰 데이터 구조에 저장합니다.
알고리즘은 필요에 따라 텍스트 내용 내의 공백, 줄 바꿈, 및 기타 텍스트 서식을 처리합니다.
8. 주석 처리:
알고리즘이 <!-- 시퀀스를 감지하면 이어지는 문자를 주석으로 인식합니다. 주석의 내용은 추출됩니다.
주석 토큰이 생성되어 주석 내용을 포함하며, 토큰 데이터 구조에 추가됩니다.
9. DOCTYPE 선언 처리:
알고리즘은 HTML 문서의 시작 부분에서 DOCTYPE 선언을 식별하고 추출합니다. DOCTYPE 토큰은 사용되는 HTML 버전에 대한 정보를 제공합니다.
DOCTYPE 토큰이 생성되어 관련 정보를 포함하며, 토큰 데이터 구조에 저장됩니다.
10. HTML 코드 계속 스캔:
각 토큰을 처리한 후에 알고리즘은 HTML 코드를 계속 스캔하며, 다음 문자로 이동하고 토큰화 규칙을 기반으로 평가합니다.
이 과정은 전체 HTML 코드가 스캔되고 토큰화될 때까지 반복됩니다.
Tokenization Example
간단한 예시로 Tokenization에 대해서 학습을 마무리 지어 보겠습니다.
<html>
<head>
<title>My Web Page</title>
</head>
<body>
<p>Welcome to my web page.</p>
</body>
</html>처음 문서를 읽기 시작하며, 초기 상태는 Data state였지만, <를 만나 Tag open state 상태로 변경됩니다. 그 이후 >를 만날때 까지 Tag open state 상태를 유지하다가 >를 만나 다시 Data state로 변경됩니다.
또한 Tag open state과정에서 parsing된 <html> 이라는 문자열은 Tokenization 이 진행됩니다.
아래는 위의 과정을 거쳐서 생성된 Token 들 입니다.
- 시작 태그 토큰:
<html> - 시작 태그 토큰:
<head> - 시작 태그 토큰:
<title> - 텍스트 토큰:
"My Web Page" - 종료 태그 토큰:
</title> - 종료 태그 토큰:
</head> - 시작 태그 토큰:
<body> - 시작 태그 토큰:
<p> - 텍스트 토큰:
"Welcome to my web page." - 종료 태그 토큰:
</p> - 종료 태그 토큰:
</body> - 종료 태그 토큰:
</html>
지금까지 HTML document를 Tokenization Algorithm에 대해서 학습을 진행했습니다. 해당 토큰들은 결국 DOM(Document Object Model)을 생성하는 발판이 되어 줍니다.
이제 지금까지 생성한 Token들을 통해 Tree를 만들어 봅시다.
3. Tree Construction (1)
Tree Construction은 HTML 파싱과정 중에서 가장 중요한 단계입니다.
HTML 코드가 토큰화 되고 트큰들이 모두 준비가 되었다면, 트리를 구성하는 알고리즘은 이러한 토큰들을 가져와서 Tree Construction 을 진행합니다. 이 과정에서 만들어진 것을 DOM(Document Object Model) 이라고 합니다. DOM tree 는 HTML 문서를 Pasing 하고 이를 의미있는 단위의 집합 (Token)으로 변화시킨 뒤 , 이를 통해 계층적인 구조로 만들어 냅니다!
이제부터 구체적으로 Dom tree를 만들어 내는 과정에 대해서 학습을 진행합니다.
DOM tree의 root를 생성
트리 구성 과정의 시작에서 알고리즘은 DOM 트리의 루트 노드를 생성합니다. 이 루트 노드는 전체 HTML 문서를 대표합니다. 이것은 DOM 트리의 계층적 구조를 구성하기 위한 시작점으로 작용합니다.
child Node 생성
알고리즘이 토큰화 과정에서 생성된 토큰들을 순회하면서, HTML 요소를 대표하는 시작 태그를 만납니다. 각 시작 태그에 대해 알고리즘은 DOM 트리에 요소 노드를 생성합니다.
요소 노드들은 HTML 요소에 대한 정보를 담고 있으며, 요소의 태그 이름, 속성, 그리고 중첩된 내용을 포함합니다. 이러한 요소 노드들은 DOM 트리의 구성 요소가 되어, HTML 문서의 구조를 형성합니다.
parent-child relation 생성
HTML 문서의 계층적 구조를 반영하기 위해 알고리즘은 요소 노드들 사이에 부모-자식 관계를 설정합니다. 시작 태그가 발견되면, 해당 요소 노드는 이전에 열린 요소의 자식이 됩니다. 이렇게 해서 중첩된 구조가 생성되며, 요소들은 그들이 포함되는 기준에 따라 계층적으로 조직됩니다.
예를 들어, HTML 코드 <div><p>Hello, World!</p></div>를 고려해보면, 알고리즘은 <div> 요소에 대한 요소 노드와 <p> 요소에 대한 노드를 생성합니다. <p> 요소 노드는 <div> 요소 노드의 자식이 되어, 부모-자식 관계를 형성합니다.
Node간 형제 관계 처리:
부모-자식 관계 외에도 알고리즘은 요소들 사이의 형제 관계도 처리합니다. 새로운 시작 태그가 이전에 열린 요소와 같은 부모를 공유할 때, 그것은 기존 요소의 형제가 됩니다.
예를 들어, HTML 코드 <div><p>Paragraph 1</p><p>Paragraph 2</p></div>에서는 알고리즘이 두 개의 <p> 요소 노드를 생성합니다. 두 <p> 요소는 동일한 부모 <div>를 가지고 서로의 형제입니다.
이러한 부모-자식 및 형제 관계를 정확하게 설정함으로써 알고리즘은 DOM의 트리 구조를 구성합니다. 결과로 나온 DOM 트리는 HTML 요소의 중첩된 조직을 반영하여 HTML 문서의 계층적 표현을 제공합니다.
4. 중첩된 HTML 요소일때의 문제 해결
HTML 요소의 중첩된 구조(nested structure)란, 한 요소가 다른 요소 내부에 위치하는 것을 의미합니다. 이는 트리 구조로 표현되며, 이러한 구조를 통해 웹 페이지의 레이아웃과 내용이 정의됩니다.
<div>
<p>안녕하세요.</p>
<ul>
<li>항목 1</li>
<li>항목 2</li>
</ul>
</div>이 예시에서 <div> 요소는 <p> 요소와 <ul> 요소를 내부에 포함하고 있습니다. 또한, <ul> 요소는 <li> 요소를 내부에 포함하고 있습니다. 이런 식으로 하나의 요소가 다른 요소를 포함하는 구조를 "중첩된 구조"라고 합니다.
이 중첩된 구조는 Document Object Model (DOM) 트리로 표현될 때, 부모-자식 관계를 형성하게 됩니다. 예를 들어, 위의 HTML 코드에서 <div> 요소는 <p>와 <ul>의 부모가 되며, <ul>은 <li>의 부모가 됩니다. 이렇게 중첩된 구조를 통해 웹 페이지의 계층적 구조가 형성되고, 이를 쉽게 조작하거나 스타일을 적용할 수 있습니다.
open element stack의 활용
알고리즘은 중첩된 요소를 처리하기 위해 "open element stack" 또는 "element stack"이라는 스택을 유지합니다.
이 스택은 토큰화된 HTML 코드를 통해 알고리즘이 진행되면서 현재 열려 있는 요소를 추적합니다.
아직 닫히지 않은 각 요소 노드는 스택에 푸시됩니다.
시작 태그를 통한 노드 생성
알고리즘이 시작 태그 토큰을 만나면 해당 HTML 요소에 대한 새로운 요소 노드를 생성합니다.
새로 생성된 요소 노드는 그 다음 DOM 트리에 추가됩니다.
요소 노드를 추가하기 전에, 알고리즘은 현재 요소의 적절한 부모를 결정하기 위해 오픈 요소 스택을 확인합니다.
부모 요소는 스택에서 가장 최근에 열린 요소입니다.
부모-자식 관계 문제 해결
알고리즘은 HTML 코드에서의 중첩을 기반으로 요소 간의 부모-자식 관계를 설정합니다.
부모-자식 관계는 DOM 트리에서 반영되며, 부모 요소가 자식 요소의 직접적인 조상 역할을 합니다.
알고리즘은 각 자식 요소 노드가 그것의 부모 요소 노드 내에 올바르게 중첩되도록 합니다.
종료태그를 통한 스택 제거
알고리즘이 종료 태그 토큰을 만나면, 해당 요소가 닫혔다는 것을 나타냅니다.
알고리즘은 일치하는 태그 이름을 가진 가장 최근에 열린 요소를 찾기 위해 오픈 요소 스택을 확인합니다.
알고리즘은 일치하는 태그 이름을 가진 요소를 찾고 닫을 때까지 스택에서 요소를 제거합니다.
요소를 닫는 것은 그것이 완전하고, 그것의 부모 요소 내에 올바르게 중첩되었다고 간주됩니다.
요소가 닫히면, 그들은 스택에서 제거되어 완전히 처리되었다고 표시됩니다.
Tree Construction Example
간단한 예시로 Tree Construction에 대해서 학습을 마무리 지어 보겠습니다.
<html>
<head>
<title>My Web Page</title>
</head>
<body>
<p>Welcome to my web page.</p>
</body>
</html>DOM 트리를 구축할 차례입니다. 처음에는 루트 노드만 있는 상태입니다. 'html' 시작 태그 토큰을 만나면, 'html' 노드가 루트 노드의 자식으로 추가됩니다. 이후 'head', 'title', 'body', 'p' 등의 노드도 동일한 방식으로 트리에 추가됩니다.
'p' 노드를 예로 들면, 이 노드는 'body' 노드의 자식으로 들어갑니다. 그리고 그 안의 텍스트 "Welcome to my web page."는 'p' 노드의 자식으로 들어가게 됩니다.
아래는 예시로 작성된 tree 구조 입니다.
html
├── head
│ └── title
│ └── "My Web Page"
└── body
└── p
└── "Welcome to my web page."Graceful Degradation (우아한 저하)
HTML 파싱 알고리즘은 종종 에러로 인해 프로세스를 종료하기보다는 콘텐츠의 복구와 렌더링을 우선시합니다.
우아한 저하 기술을 사용함으로써 알고리즘은 에러가 있더라도 가능한 많은 유효한 콘텐츠를 파싱하고 렌더링하려고 노력합니다.
이 접근 방식은 사용자가 HTML 문서의 일부가 문제가 있더라도 사용 가능한 콘텐츠에 계속 접근하고 상호 작용할 수 있도록 합니다.
<!--잘못된 코드-->
<!DOCTYPE html>
<html>
<head>
<title>Test Page</title>
</head>
<body>
<h1>Welcome to My Website
<p>This is a paragraph.</p>
<p>This is another paragraph
<ul>
<li>List Item 1
<li>List Item 2
</ul>
</body>
</html>다음의 코드를 통해서 확인한 결과

위의 HTML 코드는 많은 문법 오류를 포함하고 있습니다.
<h1> 태그가 닫히지 않았습니다.
두 번째 <p> 태그가 닫히지 않았습니다.
<li> 태그들이 닫히지 않았습니다.
그럼에도 불구하고 대부분의 웹 브라우저는 이를 적절히 렌더링하여 사용자에게 의미 있는 콘텐츠를 보여줍니다. 이것이 바로 "우아한 저하"의 한 예시라고 할 수 있습니다. 코드가 완벽하지 않더라도 브라우저가 이해할 수 있도록 최대한 노력합니다.
3. CSS Parsing

Cascading Style Sheets (CSS)는 웹 서비스에서 시각적 외관을 형성하는 역할을 수행합니다. 사용자에게 매력적이고 편리한 인터페이스를 만들려고 노력하고 있습니다. 당연하게도 브라우저는 CSS document를 parsing하여, 우리가 만든 dom tree에 연결하는 기능(이 과정에서 CSSOM이 생성됩니다)을 수행합니다.
1. CSS Parsing 이유
CSS Parsing을 하는 가장 주요한 이유는 CSS 코드를 통해서 스타일 을 분리하고 추출하는 것입니다. 이러한 추출된 스타일 중에서는 HTML 요소의 시각적 모양(색, 크기, 모양, 위치 등등)을 결정하는 정보를 모두 포함합니다. 브라우저는 Parsing을 통해서 style을 추출하고 저장하여 차후 렌더링 과정에서 활용합니다.
CSS Parsingdms 다음과 같은 이유를 가지고 있습니다.
1.구문 유효성 검사:
CSS Parsing은 CSS 코드가 정의된 구문 규칙 및 구조를 준수하는지 확인합니다. 선택기, 속성, 값 및 구두점의 올바른 사용을 포함하여 코드가 올바르게 작성되었는지 확인합니다. 구문 유효성 검사는 CSS 코드의 오류나 불일치를 식별하고 표시하는 데 도움이 되므로 개발자는 이를 수정하고 스타일이 적절하게 렌더링되도록 할 수 있습니다.
2. CSS 개체 모델(CSSOM) 구축:
CSS Parsing은 CSS 개체 모델(CSSOM)을 구성하는 데 중요한 역할을 합니다. CSSOM은 CSS 코드의 구조화된 표현을 나타내므로 개발자는 프로그래밍 방식으로 CSS 속성 및 값에 액세스하고 조작할 수 있습니다. 이는 스타일시트와 상호 작용하고 웹 요소 표시에 동적 변경 사항을 적용하는 방법을 제공합니다.
3. 스타일 결정:
구문 분석 중에 CSS 규칙은 선택기를 기반으로 해당 HTML 요소와 일치됩니다. 브라우저의 렌더링 엔진은 구문 분석된 CSS를 활용하여 각 요소에 어떤 스타일을 적용해야 하는지 결정합니다. 스타일을 정확하게 구문 분석하고 해결함으로써 CSS 구문 분석은 웹 페이지의 시각적 표현이 의도한 디자인과 일치하는지 확인합니다.
2. CSS Parsing Process
1. Toknization
Toknization는 CSS 구문 분석 프로세스의 첫 단계입니다. 여기에는 CSS 코드를 CSS OM의 구성 요소인 개별 토큰으로 나누는 작업이 포함됩니다. 토큰은 선택자(Selector), 속성(Property), 값(Value), 기호 및 키워드와 같은 고유한 단위를 나타냅니다. CSS 코드를 토큰화함으로써 브라우저의 구문 분석 엔진은 CSS 규칙의 각 요소를 식별하고 처리할 수 있습니다.
다음은 css가 Toknization 되는 Token type 들을 명시합니다.
- 선택자(Selector) : p , h1 등등
- 식별자(Identifier) : id, class 등등
- 여는 중괄호 (LeftCurlyBracket) :
{ - 닫는 중괄호 (RightCurlyBracket) :
} - 속성 (Property) :
display,border등등 - 콜론 (Colon) :
: - 값 (Value) : flex , 1px solid black 등등
- 세미콜론 (Semicolon) :
;
간단한 예시로 css Toknization을 마무리 해보겠습니다.
#main-header {
font-size: 24px;
color: blue;
}- 식별자(Identifier):
#main-header - 여는 중괄호(LeftCurlyBracket):
{ - 속성(Property):
font-size - 콜론(Colon):
: - 값(Value):
24px - 세미콜론(Semicolon):
; - 속성(Property):
color - 콜론(Colon):
: - 값(Value):
blue - 세미콜론(Semicolon):
; - 닫는 중괄호(RightCurlyBracket):
}
아직은 각 Token들이 나누어져 있지만 의미는 부여되지 않았습니다.
지금까지 CSS Tokenizaion에 대해서 학습을 짆애했습니다. 글머 다음 단계인 Lexical Analysis 로 이동하겠습니다.
2. Lexical Analysis
Lexical Analysis은 CSS parsing의 Token화 이후의 단계 입니다. 이 과정에서 Token 화 된 결과물을 바탕으로 의미 있는 단위로 분해하고 연결하는 작업을 처맇바니다.
Lexical Analysis 과정 중에는 생성된 Token을 의미 있는 단위로 합치는 기능을 수행합니다. 예를 들어 선택자, 속성, 값 등등의 토큰은 CSS 문서 내부에서 해당 기능을 수행하여 인식되고 분류됩니다. 이때 토큰을 의미 있는 단위로 분해하는것은 차후 CSS를 구조화된 표현을 진행할때 필수적입니다.
body {
background-color: #f2f2f2;
color: #333;
}토큰화 결과물
body,{,background-color,:,#f2f2f2,;,color,:,#333,;,}
Lexical Analysis 과정 이후 결과
body=> 선택자
{=> 여는 중괄호
background-color=> 속성
:=> 콜론
#f2f2f2=> 값
;=> 세미콜론
color=> 속성
:=> 콜론
#333=> 값
;=> 세미콜론
}=> 닫는 중괄호
Token 화 한 결과물을 바탕으로 의미를 부여하는 Lexical Analysis 까지 수행했습니다. 다음은 Syntax Analysis 입니다.
3. Syntax Analysis(구문 분석)
Syntax Analysis은 CSS Parsing의 3번째 단계 입니다. CSS 코드의 구조와 문법을 분석하여 정의된 구문 규칙을 준수하는지 확인하는 작업이 포함됩니다. 구문 분석은 CSS 코드의 계층 구조를 나타내는 parse tree을 구축하기 위해 토큰의 배열과 관계를 확인합니다.
Syntax Analysis은 Tokenization 중에 생성된 토큰을 CSS 구문 규칙에 따라 의미 있는 순서로 정렬합니다. 이 단계에서는 Token의 순서와 배치를 고려하여 CSS 규칙, 속성, 값 및 기타 요소의 구조를 결정합니다.그리고 그 이후 parse tree를 구축합니다.
구문 분석 트리는 CSS 코드의 계층 구조를 나타냅니다. 구문 분석은 토큰을 노드로 구성하고 노드 간의 관계를 정의하여 구문 분석 트리를 구성합니다. 예를 들어 구문 분석 트리에는 CSS 코드의 계층 구조를 반영하는 상위-하위 관계와 함께 선택기, 속성, 값 및 선언에 대한 노드가 있을 수 있습니다.
예를 들어 아래와 같은 css 문서가 존재할때
/* CSS Comment */
h1 {
color: #333;
font-size: 24px;
text-align: center;
}
p {
font-family: Arial, sans-serif;
font-size: 16px;
line-height: 1.5;
}다음과 같은 parse tree를 가지게 됩니다.
StyleSheet
├─ Comment: " CSS Comment "
├─ Rule
│ ├─ Selector: "h1"
│ └─ DeclarationBlock
│ ├─ Declaration
│ │ ├─ Property: "color"
│ │ └─ Value: "#333"
│ ├─ Declaration
│ │ ├─ Property: "font-size"
│ │ └─ Value: "24px"
│ └─ Declaration
│ ├─ Property: "text-align"
│ └─ Value: "center"
├─ Rule
│ ├─ Selector: "p"
│ └─ DeclarationBlock
│ ├─ Declaration
│ │ ├─ Property: "font-family"
│ │ └─ Value: "Arial, sans-serif"
│ ├─ Declaration
│ │ ├─ Property: "font-size"
│ │ └─ Value: "16px"
│ └─ Declaration
│ ├─ Property: "line-height"
│ └─ Value: "1.5"또한 이 단계 에서 잘못된 규칙이 잇는지 확인하는데,
body {
color red;
}이 때 Syntax Analysis는 오류를 감지하고 오류 메세지를 반환하거나 복구하는 기능을 수행합니다.
4. CSS Parsing Algorithm
CSS Parsing Algorithm은 CSS 규칙이 파싱되고 평가되어 웹 페이지 내의 HTML 요소에 적용되는 체계적인 과정을 정의합니다. 이는 CSS 코드를 해석하고 각 요소에 적용해야 할 최종 스타일을 결정하는 주요 단계를 개요화합니다.
1. 규칙 선택 및 일치:
CSS Parsing Algorithm의 첫 번째 단계는 규칙 선택 및 일치입니다. 이 과정은 CSS 규칙을 선택하고 문서 트리의 해당 HTML 요소와 일치하는지 결정하는 것을 포함합니다.
- 선택자 평가: 알고리즘은 각 CSS 규칙 내의 선택자를 평가하여 대상 요소를 식별합니다.
- 선택자 일치: 선택자가 평가되면 알고리즘은 문서 트리의 HTML 요소와 일치시킵니다.
- 규칙 순서: 알고리즘은 여러 규칙이 동일한 요소와 일치할 때 CSS 규칙의 순서를 고려합니다.
2. 스타일 상속 및 연속:
CSS 파싱 알고리즘의 두 번째 단계는 스타일 상속 및 연속입니다.
- 스타일 상속: CSS에서 일부 속성은 기본적으로 부모 요소에서 자식 요소로 상속됩니다.
- 연속 순서: CSS 연속은 여러 규칙이 동일한 요소를 대상으로 할 때 충돌을 해결하는 프로세스입니다.
3. 최종 속성 값 계산:
CSS 파싱 알고리즘의 세 번째 및 마지막 단계는 각 CSS 속성에 대한 최종 속성 값을 계산하는 것입니다.
- 상대 단위 해결: 알고리즘은 상대 단위를 처리하여 해당 절대 값으로 변환합니다.
- 상속 처리: 계산 과정에서 알고리즘은 부모 요소에서 상속된 값을 고려합니다.
CSS 파싱 알고리즘은 CSS 코드의 복잡성을 처리하기 위한 체계적인 방법을 제공하며,
각 요소에 대한 최종 계산 스타일을 결정하는 규칙 기반 평가 및 연속 메커니즘을 따릅니다.
CSSOM tree Example
지금까지 학습한 CSS parser 방식을 통해 CSS문서로 CSSOM 문서를 생성하는 예시를 진행해 보겠습니다.
body {
background-color: #f5f5f5;
}
h1 {
font-size: 24px;
color: #333;
}
p {
font-size: 16px;
color: #666;
}예시로 사용할 css 구문입니다.
1. 토큰화
토큰화 결과물은 다음과 같ㅅ브니다.
body,{,background-color,:,#f5f5f5,;,}h1,{,font-size,:,24px,;,color,:,#333,;,}p,{,font-size,:,16px,;,color,:,#666,;,}
2. 구문분석을 통한 parse tree 생성
- STYLESHEET
- RULESET1
- SELECTOR: body
- DECLARATION BLOCK
- PROPERTY: background-color
- VALUE: #f5f5f5
- RULESET2
- SELECTOR: h1
- DECLARATION BLOCK
- PROPERTY: font-size
- VALUE: 24px
- PROPERTY: color
- VALUE: #333
- RULESET3
- SELECTOR: p
- DECLARATION BLOCK
- PROPERTY: font-size
- VALUE: 16px
- PROPERTY: color
- VALUE: #6663. CSSOM Tree
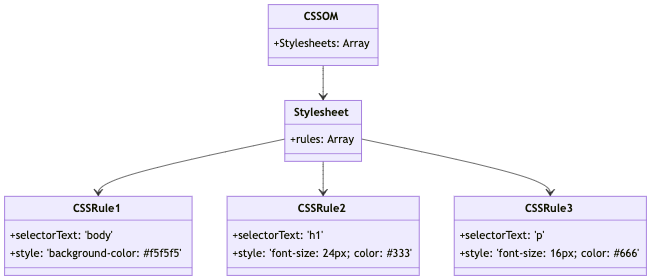
최종적으로 생성한 CSSOM Tree 입니다!
4. DOM and CSSOM
마지막으로 DOM 과 CSSOM 을 정리하고 마무리 하겠습니다
긴 글 읽어주셔서 정말 감사합니다.
about DOM
- 구조화된 객체 모델:
DOM은HTML문서의 구조와 내용을 트리 형태로 나타냅니다.- API와 인터페이스:
HTML문서의 요소와 내용을 접근, 수정, 탐색할 수 있는 API와 인터페이스를 제공합니다.- 동적 수정 가능:
DOM을 통해 개발자는 구조, 내용, 속성 등을 동적으로 수정할 수 있으며, 이를 통해 동적이고 반응적인 웹 경험을 제공합니다.- 객체로의 표현:
HTML요소, 텍스트 노드, 속성, 그리고 다른 문서 구성 요소들을 객체로 나타냅니다.CSSOM과의 상호작용:DOM은 각 요소에 대한 연관된CSS스타일에 접근할 수 있도록CSSOM을 통해 제공합니다.CSSOM을 통한 스타일 업데이트: DOM에 변경이 생기면, 예를 들어 요소의 구조나 내용을 수정하는 경우, 이러한 변경은CSSOM을 통해 연관된CSS스타일에 업데이트를 유발할 수 있습니다.- 렌더링 엔진과의 협력:
CSSOM은 렌더링 엔진에 필요한 스타일 정보를 제공하며, 이 정보는DOM구조를 기반으로 요소의 시각적 렌더링에 적용됩니다.
about CSSOM
- 구조화된 객체 모델:
CSSOM은 웹 페이지의CSS스타일시트를 구조화된 객체 모델로 나타냅니다.- API와 인터페이스: 프로그래밍적으로
CSS스타일을 접근, 조작, 적용할 수 있는 API와 인터페이스를 제공합니다.- 동적 수정 가능: 개발자는
CSSOM을 통해CSS스타일을 동적으로 수정, 추가, 제거할 수 있으며, 이를 통해 웹 페이지의 시각적 표현과 동작에 대한 강력한 제어가 가능합니다.- 객체로의 표현:
CSS규칙, 선택자, 선언, 그리고 다른 스타일링 속성들을 객체로 나타냅니다.DOM과의 상호작용:CSSOM은 특정 DOM 요소와 연결된CSS규칙을 관리합니다.- 렌더 트리에 반영:
CSSOM에 변경이 생기면, 예를 들어CSS규칙을 수정하거나 추가하는 경우, 이러한 변경은 렌더 트리에 반영되어 영향을 받는 요소의 시각적 렌더링이 업데이트됩니다.- 렌더링 과정에서의 역할:
CSSOM과DOM은 렌더링 과정에서 협력하여 웹 페이지의 요소들의 크기, 위치, 외관, 동작을 결정합니다.

유익한 글 잘 보고 갑니다 : )