[DE kit] 2. SQL for Data Engineers
summary table (=ELT)
summary table은 밑단 테이블(콜센터 솔루션 등)이 바뀌더라도 그 내부를 알아야 할 필요가 없기 때문에 유용하다.
- 써머리 테이블만 대시보드, 데이터 분석 등에 사용 (Looker)
- Being consistent is more important than being correct
- summary table을 만드는 방식 : dbt라는 기술을 많이 사용하는 추세
@sql : create table as select (cts구문)
elt 툴로 dbt가 많이 쓰인다는 점 -> analytics engineer 업무
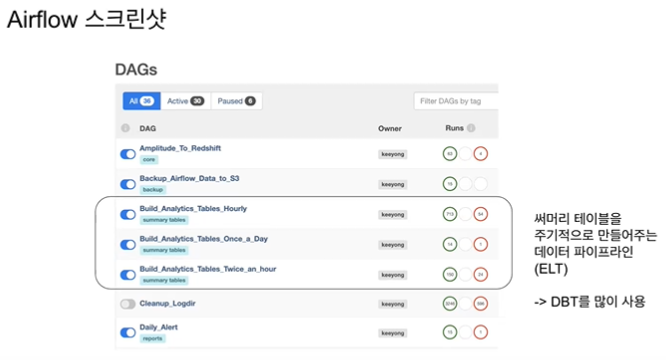
summary table을 시간마다 일마다 등
MAU 계산 (redshift, postgresql 버전)


alias 지정 시 AS 생략 가능
- 데이터 엔지니어가 달라지는 데이터에 어떤 태도를 취해야 할까?
데이터 엔지니어는 모든 에러 명확히, 백엔드가 변경사항을 알려주고 이후 작업하는게 이상적이지만, 데엔이 만드는 코드의 에러는 alert을 걸어야 한다. 구체적으로 뭐가 잘못되었고 무엇을 해라 라고 알리기
try, excetp로 에러처리 하지 않고 에러가 나도록 놔두어야 한다. 보통 슬랙으로 데이터 파이프라인 에러 메시지 본다. 큰 규모의 기업은 매주 온콜 엔지니어를 뽑아서 에러를 관리하기도 한다.
 7, 6, 4
7, 6, 4
COUNT 함수는 인자의 값이 NULL이 아니면 1씩 센다.
SELECT COUNT(1) FROM count_test --7
SELECT COUNT(value) FROM count_test --6 null 제외COUNT(*) = COUNT(1) = COUNT(100) -> NULL 포함
count() 괄호 안에 NULL만 아니면 다 값을 1씩 세는 기능이다.
SQL은 빅데이터가 구조화된 데이터일 때 강력하다.
SQL은 다른 분야의 사람도 읽을 수 있기에 유용하다.
pandas는 데이터 로딩, 조인, 그룹핑, 카운팅 모든 과정을 순차적, 개별적으로 진행해야 한다. 끝까지 가야 최종 결과를 알 수 있다.
sql은 내가 원하는 것과 그것을 어떻게 계산할 지가 명확하게 한 문단으로 끝난다.
-> sql이 컴파일 언어보다 수준이 낮다고 생각하면 안된다. (내가 간과했던 부분...)
하이브 프레스토가 aws에서 아테나
비구조화된 데이터 처리에는 적절하지 않다. -> spark를 주로 사용
구조화된 spark sql
real time streaming 으로 실시간 처리가 필요한 데이터는 spark streaming
-> 빅데이터 프로세싱은 다 spark로 간다. 중요한 점은 spark내에서도 구조화된 데이터는 sql 을 사용한다는 점. 그 누구도 step by step으로 컴파일 언어를 사용하지 않는다.

데이터 품질에 대한 테스팅은 온고잉으로 이루어져야 한다.
etl, elt의 앞 단, 마지막 단은 테스트가 들어가는 것이 좋다.
데이터 엔지니어에게 중요한 점 : 디버깅해서 코드를 계속 돌리려고 노력하기 보다 깔끔하게 에러를 내는 것이 올바른 자세이다.
데이터 품질 체크 방법
- 중복된 레코드 체크
- 최근 데이터 존재 여부 체크하기
- 기본키 지켜지는지 체크하기, dbms에서 보장해주지 않는다. 엔지니어와 분석가의 역량이다.
- 값이 비어있는 컬럼들이 있는지 체크하기
- 위의 체크사항들은 코딩의 unit test 형태로 만들어 쉽게 체크한다. 코드는 정해진 로직이라 상황이 바뀌어도 코드의 행동이 바뀌지 않음. 데이터는 내가 만들어내는 것이 아니기 때문에 로직이 바뀔 때마다 테스트를 해주어야 한다. -> dbt등의 툴로

규모가 커지면 데이터 분석가는 보려는 데이터가 어디있는지 찾는데에 시간을 많이 소모하게 된다. = data discovery 문제
그러나, 이를 완벽히 관리하기란 불가능하므로 중요한 테이블에 대해서는 적어도 품질을 보장하는 형태로 가야 한다.
이외의 데이터들은 검색 엔진을 만들어서 원하는 데이터들을 검색해서 사용할 수 있도록 플랫폼화 = data catalog


ctas : create table as select 를 더 강력하게 만들어주는 것이 dbt 툴

테이블 이름이 없는 경우 에러가 발생하는 것을 방지해준다.
delete from은 where절을 통해 조건에 맞는 절만 삭제할 수 있다.




LIKE : 대소문자 구분 O
ILIKE : 대소문자 구분 X
insert into 라인 바이 라인이라 느리다.

DB마다 NULL 정렬이 다르기 때문에 기억이 어렵다. null 값 위치 옵션을 주면 편함

데이터 타입 변환
- cast 함수 사용 cast(category as int)
- :: 오퍼레이터 사용 category::int

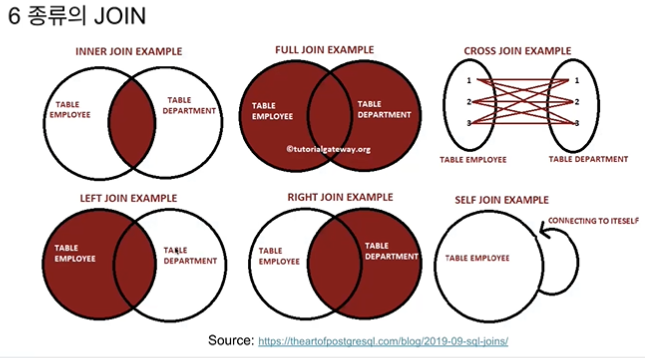
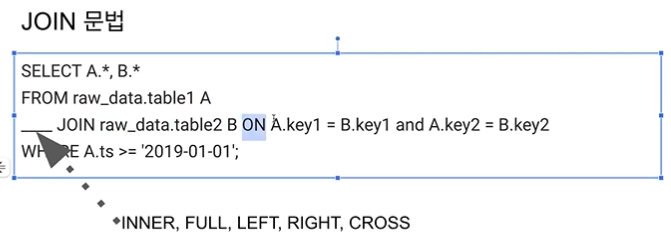

조인 시 사용되는 키가 primary key 인 경우가 많기 때문에 uniqueness 가 보장되는지 항상 확인해야 한다.
JOIN 예제
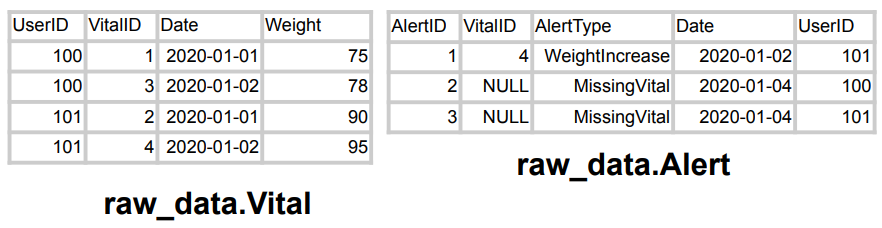
raw_data.Vital : 몸무게 정보
raw_data.Alert : 체중 5kg 증가 or 체중 정보가 2일 이상 들어오지 않을 경우 경고 정보
경고 정보의 후자 경우에는 VitalID가 존재하지 않는다. So, VitalID로 JOIN했을 때 어떤 결과가 나올까?


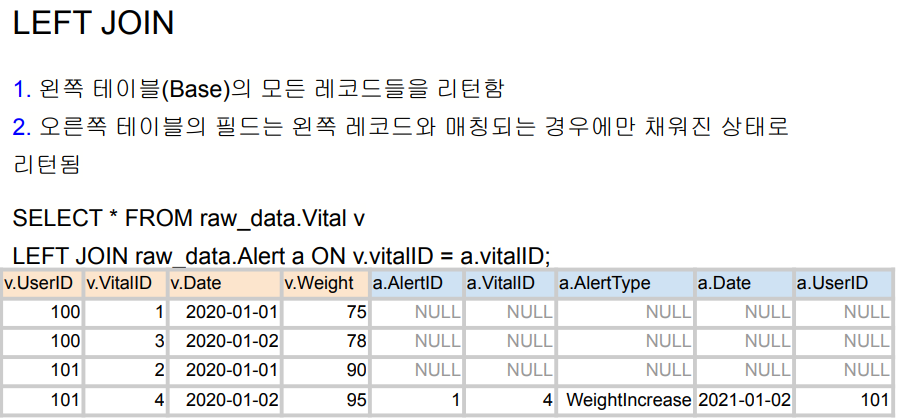

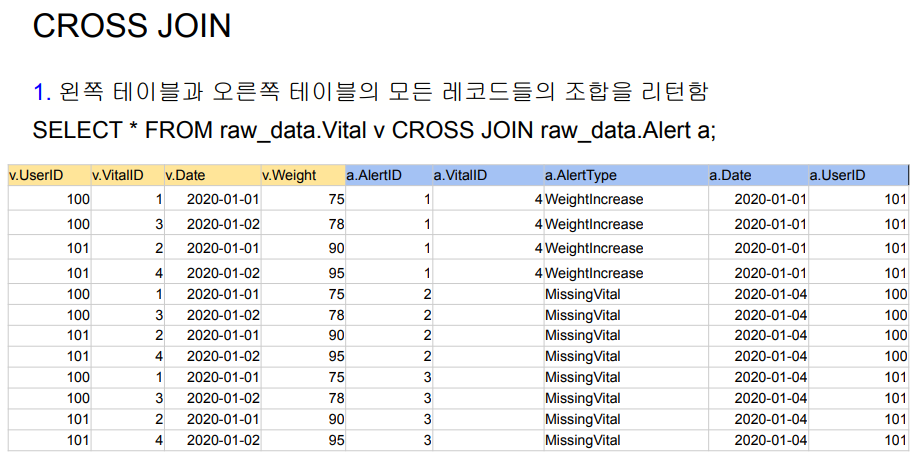
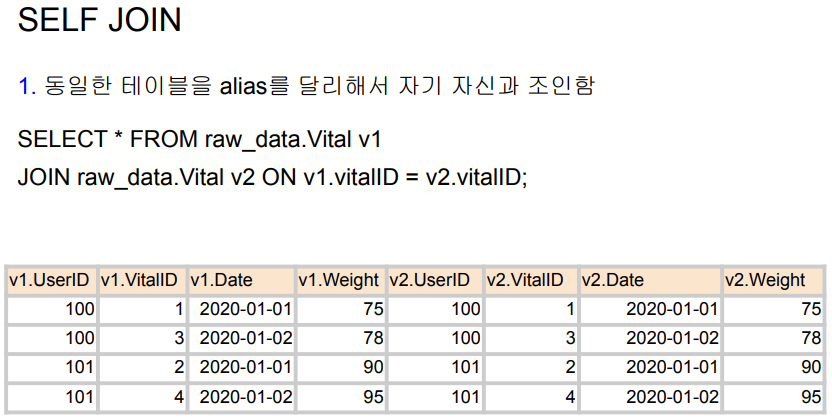
실무에서는 95% 이상 inner join, left join 을 이용한다.





숙제1 : sql 실습 따라하기
숙제2 : 세션 테이블에서 모든 사용자에 대해 userid, first_channel, last_channel 구하기 (윈도우 함수)
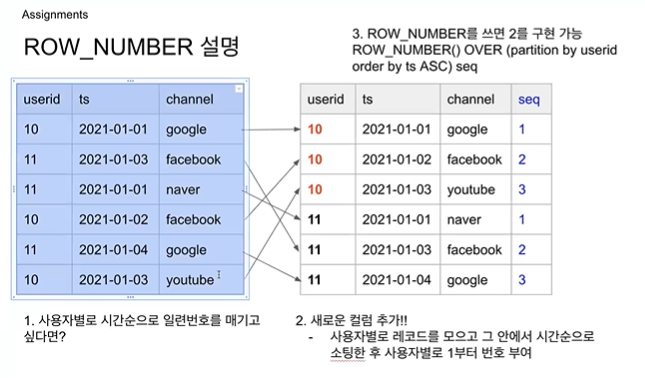
같은 userid끼리 그룹핑->timestamp 필드인 ts 순으로 오름차순 정렬->각 userid 내에서 일련번호 붙이기->일련번호가 1인 것만 읽으면 모든 사용자의 first channel이 된다.->정렬순서를 내림차순으로 바꾸고 1번이 last channel이 된다.
= 이렇게 해주는 문법이 row_number 함수
partition by 그룹핑할 필드명
order by 그룹 내에서 정렬할 기준값
or first_value/last value 함수 써도 되나 문법이 좋지 않다.

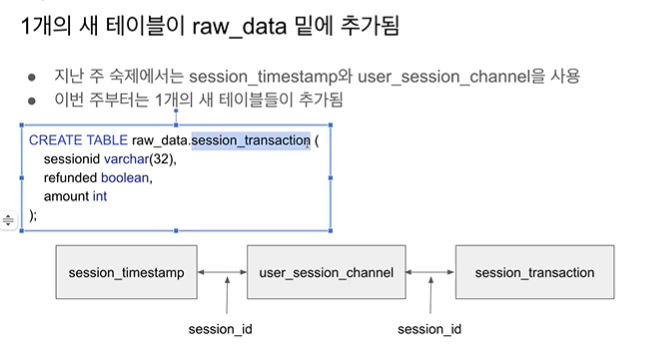
세션 중 트랜잭션이 있는 세션을 session_transaction으로
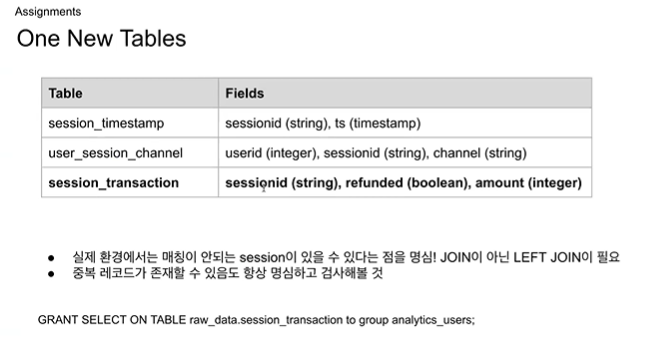
숙제3 :

숙제4 :

Q&A
MySQL을 데이터 웨어하우스를 사용하는 경우에도 Redshift나 빅쿼리처럼 PK를 보장하지 않도록 설정해줄 수 있나요? 아니면 PK가 보장되는 상황에 맞춰 ETL을 설정해줘야 하나요?
-> 불가능, mysql을 쓴다는 것은 데이터가 크지 않다는 것이므로 pk가 보장되어도 성능에 무리가 없다.
self join은 좀 생소한데 어떤 경우에 사용되나요?
-> users 테이블에서 하나의 칼럼에 게스트/호스트 속성값이 있고, 호스트 게스트 분류가 필요할 때 self join 을 사용했던 경험이 있습니다.
쿼리를 하다보니 비용 관련 궁금한점이 생겼습니다. 데이터 웨어하우스에서 클러스터링을 많이 얘기하더라구요, 이 열 정렬 이 된 테이블이라는데 비용이 어떻게 감소되는건지 궁금합니다.
-> 고정비용, 가변비용이냐에 따라 다르다. 레드시프트는 고정비용, 고정비용에서는 걱정할 필요가 없다. 스노우플레이크나 빅쿼리 등에서는 어떻게 최적화된 쿼리를 쓰느냐가 중요. 특정 컬럼을 기준으로 미리 정렬을 해 둘 경우 계산이 더 빨라질 수 있다. 어떤 오퍼레이션을 자주 하느냐, 그 오퍼레이션의 비용은 무엇인가에 따라 다르다.
CTAS 가 ELT 로 이해했는데 CTE도 ELT인가요 차이가 있다면 무엇인가요
elt는 피지컬한 테이블로 만드는 것, cta는 temporary table
빅쿼리, 스노우플레이크처럼 쿼리별로 차징이 되는 경우, 쿼리 실수를 안 하는 것이 중요할 것 같습니다. 직접 쿼리를 날리기 전에 테스트를 해볼 수 있는 수단이 있나요?
-> EXPLAIN SELECT (내가 실행하고 싶은 쿼리) 대략 어떻게 돌아가는지 알 수 있다. 매일 아침에 전날 가장 비싼 쿼리 돌려보기, 제약을 할 수는 있으나 완전히 막을 수 없고 실수로 성장. scalable한 db를 쓸수록 쿼리를 잘 짜야한다. 그런 의미에서 고정비용이 메리트 있다.
당부
데이터 파이프라인은 데이터 웨어하우스에 테이블을 만드는 것이므로 SQL이 중요하다. 현업에서도 SQL 매우매우 중요
실습 : https://colab.research.google.com/drive/1utTJoDhkTnrq169yK1cM8BiBS2xWXyYU?usp=sharing
