[Text Mining] Bag of Words, DTM, TF-IDF 개념과 실습
1. 개념
- 단어 (word) : 의미를 내포하는 가장 기본적인 단위
- 단어집 (vocabulary) : 분석에서 고려하는 서로 다른 단어의 집합
- 문서 (document) : 단어를 비롯한 텍스트들로 이루어진 기본 자료
ex) 블로그, 뉴스 기사, 트위터의 트윗, 논문 등 - 코퍼스 (corpus, 말뭉치) : 문서들의 집합
ex) 블로그 글들, 뉴스기사들, 트윗들, 논문들 등
기호 표현
- 코퍼스 C에 D개의 문서 d=1,2,...,D가 존재한다.
- 단어집에는 V개의 서로 다른 단어 v=1,2,...,V가 존재한다.
- 문서 d에는 개 단어의 시퀀스인 로 이루어져 있다. 각 단어는 단어집의 원소이다.
2. 텍스트 데이터의 수치화 방법
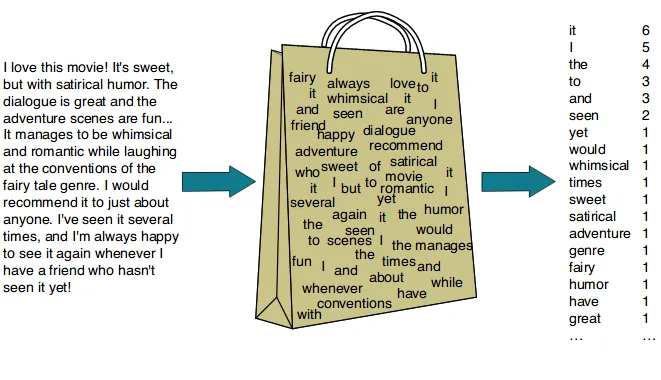
2-1. Bag of Words (BoW)
- 정의 : 단어들의 순서는 고려하지 않고, 단어들의 출현 빈도에만 집중하는 텍스트 데이터의 수치화 방법
2-2. 문서 단어 행렬 (document-term matrix; DTM)
-
정의 : 여러 개의 문서에 나타나는 단어들의 빈도를 "문서 X 단어" 행렬로 표현한 것
-
문서 에 단어 가 출현한 횟수에 대한 행렬을 라 하자.
-
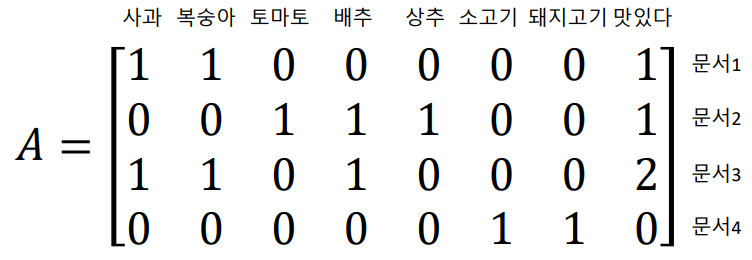
예시 코퍼스에 대한 행렬 A의 형태는 다음과 같다.
ex) 예시 코퍼스
문서 1 () : 복숭아 사과 맛있다
문서 2 () : 토마토 배추 상추 맛있다
문서 3 () : 복숭아 배추 맛있다 사과 맛있다
문서 4 () : 소고기 돼지고기
-
한계점
- 희소(sparse) 표현 : 대부분의 행렬값이 0으로 표현된다.
- 불용어(영어에서 the, and, is 등) 이 자주 등장 : 높은 빈도를 갖는 불용어에 가려져 중요한 단어를 찾지 못할 수 있다.
2-3. TF-IDF (term frequency-inverse document frequency)
-
정의 : 단어에 가중치를 주는 방법
-
구성 요소
: 문서 에서의 특정 단어 v의 수
: 특정 단어 가 등장한 코퍼스의 문서의 수
: 문서의 수 가 반비례하는 수. 즉, 특정 단어 의 중요도 (는 전체 문서의 수)
: 문서 에서 특정 단어 의 중요도 = 특정 단어 v의 등장 횟수 중요도
TF-IDF 행렬이란,
각 문서에서 단어 v의 TF-IDF 가중치인 를 "문서 X 단어" 행렬 로 표현한 것이다.

- idf(배추)를 예로 들면, "배추"라는 단어가 4개 문서 중에서 2개 문서에서 등장했다. 이를 계산하면 1이며, 이는 "배추" 단어의 중요도를 의미한다.
- 배추의 중요도는 1, 상추의 중요도는 2로 "상추는 배추보다 2배 더 중요하다."라는 결론을 도출할 수 있다.
3. 실습
모듈 불러오기
import gensim
from gensim import corpora, models, matutils
import pprint
import numpy as np
from pprint import pprint예시 코퍼스 정의
doc_list = [
"복숭아 사과 맛있다",
"토마토 배추 상추 맛있다",
"복숭아 배추 맛있다 사과 맛있다",
"소고기 돼지고기"
]
print("코퍼스:")
pprint(doc_list)
전처리 (토큰화)
# doc_list의 요소들을 doc에 담아 하나씩 불러오며, 불러온 doc에 대해 split()함수를 적용하여 토큰화합니다.
doc_tokenized =[doc.split() for doc in doc_list]
print("토큰화 결과:")
pprint(doc_tokenized)
BoW 표현
# 각 단어에 대한 고유 인덱스를 생성하고, 단어의 빈도수를 저장합니다.
dictionary = corpora.Dictionary(doc_tokenized)
print("단어 -> 단어인덱스:")
print(dictionary.token2id)
# dictionary.token2id.items()을 사용하여 단어 인덱스 매핑을 반전합니다. 즉, 각 인덱스에 해당하는 단어를 찾을 수 있도록 만듭니다.
id2token = {idx: token for token, idx in dictionary.token2id.items()}
print("단어인덱스 -> 단어:")
print(id2token)
# 사전(dictionary)에서 doc2bow 메소드를 사용하여 각 문서의 Bag-of-Words 표현을 생성합니다.
# Bag-of-Words 표현은 (단어 인덱스, 단어 빈도수) 쌍의 리스트로, 각 문서를 나타냅니다.
BoW_corpus = [dictionary.doc2bow(doc) for doc in doc_tokenized]
print("코퍼스의 BoW 표현:")
pprint(BoW_corpus)
# 각 (단어 인덱스, 빈도수) 쌍을 (단어, 빈도수) 쌍으로 바꾸어 줍니다.
# 이를 위해 사전(dictionary)의 id를 단어로 매핑하여 인덱스 대신 단어를 사용합니다.
id_words = [[(dictionary[id], count) for id, count in line] for line in BoW_corpus]
print("단어 인덱스를 단어로 바꾸어 표현:")
pprint(id_words)
문서 단어 행렬 생성
# models.TfidfModel은 TF-IDF 모델을 생성합니다.
# n: tf 변형 안함, n: idf 사용 안함, n: 문서 정규화 안함 즉, 원래의 Bag-of-Words 빈도수를 그대로 사용합니다.
dtm_model = models.TfidfModel(BoW_corpus, smartirs='nnn')
# 생성된 TF-IDF 모델을 사용하여 BoW_corpus를 변환합니다.
# 각 문서의 각 단어에 대해 TF-IDF 가중치가 계산됩니다.
dtm_corpus = dtm_model[BoW_corpus]
# matutils.corpus2dense 함수를 사용하여 변환된 코퍼스를 밀집 행렬(dense matrix) 형태로 변환합니다.
# num_terms 파라미터는 행렬의 열 크기를 정의하며, 여기서는 사전의 크기(단어의 개수)입니다.
# transpose() 메소드는 행과 열을 바꾸어 문서가 행으로, 단어가 열로 오도록 조정합니다.
dtm_matrix = matutils.corpus2dense(dtm_corpus, num_terms=len(dictionary)).transpose()
print("코퍼스의 문서단어행렬:")
pprint(dtm_matrix)
TF-IDF 행렬 생성
# models.TfidfModel은 TF-IDF 모델을 생성합니다. 여기서 smartirs 매개변수 'nfn'은
# Term Frequency 변형을 하지 않으며(frequency),
# Inverse Document Frequency를 사용하고(natural),
# 문서 정규화는 하지 않는다는 것을 나타냅니다.
tfidf_model = models.TfidfModel(BoW_corpus, smartirs='nfn')
# 생성된 TF-IDF 모델을 사용하여 BoW_corpus를 변환합니다.
# 이 과정에서 각 문서의 각 단어에 대해 TF-IDF 가중치가 계산됩니다.
tfidf_corpus = tfidf_model[BoW_corpus]
# matutils.corpus2dense 함수를 사용하여 변환된 코퍼스를 밀집 행렬(dense matrix) 형태로 변환합니다.
# num_terms 파라미터는 행렬의 열 크기를 정의하며, 여기서는 사전의 크기(단어의 개수)입니다.
# transpose() 메소드는 행과 열을 바꾸어 문서가 행으로, 단어가 열로 오도록 조정합니다.
tfidf_matrix = matutils.corpus2dense(tfidf_corpus, num_terms=len(dictionary)).transpose()
print("코퍼스의 TF-IDF 행렬:")
# np.round 함수를 사용하여 행렬의 각 요소를 소수점 셋째 자리까지 반올림합니다.
pprint(np.round(tfidf_matrix, 3))
💡 질문과 피드백은 댓글에 남겨주시기 바랍니다.
❤️ 도움이 되셨다면 공감 부탁드립니다.

Data Analyst / Engineer