데이터 관점의 멱등성 / 트랜잭션 실습

1. 멱등성(Idempotent)
'멱등하다.' : 한 번 수행한 것과 여러 번 수행한 결과가 같다.
- 어떤 수에 1을 곱하는 연산은 여러 번 수행한 결과가 처음 수행한 결과와 같으므로 멱등하다.
- 절대값 함수는 같은 값에 대해 여러 번 수행한 결과가 처음 수행한 결과와 같으므로 멱등 함수이다.
1-1. 멱등성 적용
1) 데이터 관점의 멱등성
- 데이터 파이프라인이 연속 실행되었을 때 Source에 있는 데이터가 그대로 Data Warehouse에 저장되어야 한다.
- Source Data = Data Warehouse Data
- No duplicates, no missing data
Full Refresh를 하는 데이터 파이프라인이라면?
- Data Warehouse의 관련 테이블에서 모든 레코드를 삭제한다.
- Data Source에서 읽어온 데이터를 Data Warehouse 테이블로 적재한다.
-> 이 과정을 SQL의 Transaction으로 묶어준다. (all or nothing)
Transaction으로 묶어준다면, 1번 과정이 성공하고 2번 과정이 실패하는 경우, 1번 과정이 실행된 결과 테이블을 누군가 사용하는 상황을 방지할 수 있다.
2) HTTP Method 관점의 멱등성
- GET : 리소스를 조회하는 메서드로 여러 번 호출해도 같은 결과가 돌아오며, 리소스에 변화를 주지 않는다.
- PUT : 여러 번 호출해도 매번 같은 리소스로 업데이트되므로 결과가 동일하다.
- DELETE : 여러 번 호출해도 삭제된 리소스에 대한 결과가 달라지지 않는다.
안전성이란 리소스를 변경하지 않는 것을 의미한다.
안전성이 보장되면 멱등성도 보장된다. 멱등성이 보장되어도 항상 안전성을 보장하지 않는다. PUT, DELETE 메서드는 멱등성이 보장되지만, 리소스를 변경하므로 안전성이 보장되지 않는다.
cf)
POST, PATCH : 서버 데이터를 변경하므로 호출할 때마다 응답이 달라지는 멱등하지 않은 메서드이다. 멱등하지 않은 메서드는 서버에서 멱등성을 구현해 멱등성을 확보할 수 있다.
3) API 관점의 멱등성
멱등한 API는 여러 번 요청한 결과와 처음 요청한 결과가 동일하다. 또한, DB(서버 상태)에도 영향을 주지 않는다.
ex: 결제 API
- 결제 중 오류가 발생해도 결제 성공 여부를 수동으로 확인하지 않고 API를 재실행하면 된다.
- 결제를 중복으로 요청해도 결제가 되지 않는다.
1-2. 멱등성 보장
1) 멱등키 사용
API 요청 헤더에 멱등키를 포함한다. 1번 요청과 2번 요청의 멱등키가 동일하다면 서버에서 2번 요청을 중복으로 판단하여 1번 요청과 동일한 응답을 전달한다.
API 서버는 멱등키를 위한 DB를 생성해 요청마다 전달되는 멱등키와 DB의 멱등키(요청받았던 응답의 멱등키)와 일치 여부를 검사한다.
멱등성을 검사할 때 멱등키와 함께 API 주소 등과 함께 묶은 시퀀스를 검사 대상으로 삼기도 한다. 따라서, 동일한 멱등키라도 시퀀스의 다른 요소가 다르면 새로운 요청으로 인식한다.
📌 Source
- 토스페이먼츠 기술블로그 : https://velog.io/@tosspayments/%EB%A9%B1%EB%93%B1%EC%84%B1%EC%9D%B4-%EB%AD%94%EA%B0%80%EC%9A%94
- 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트 with Python 강의 자료
2. 트랜잭션 (transaction)
동시에 Atomic하게 실행되어야 하는 SQL을 묶어 하나의 작업처럼 처리하는 방법
- BEGIN과 END 혹은 BEGIN과 COMMIT 사이에 해당 SQL들을 사용한다.
- ROLLBACK : 이전 상태로 되돌아간다. 명시해주는 것이 좋다.
- Transaction Isolation Level : 'Read Committed'가 디폴트 세팅이다. 즉, 다른 사용자가 테이블에 엑세스할 때 내가 트랜잭션을 열고 작업하고 있는 상태가 아니라 트랜잭션 작업 전의 상태를 볼 수 있게 한다. 커밋한 것만 볼 수 있고 작업 중인 것은 볼 수 없다.
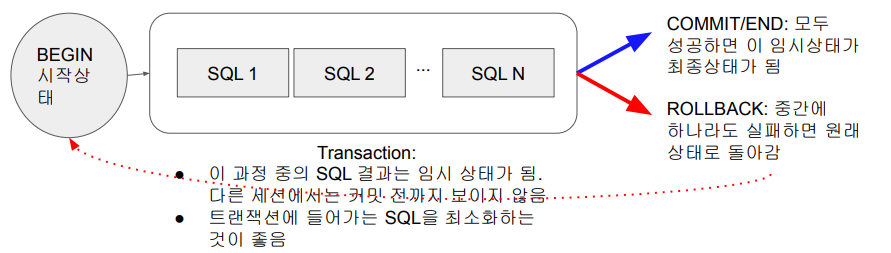 auto commit 이 True인 경우 BEGIN으로 시작해야 한다. auto commit 이 True인 경우 모든 쓰기 작업이 바로 커밋이 된다. 이것을 막으려면 BEGIN으로 시작하고, END 혹은 COMMIT을 명시하면 그때 커밋하게 된다.
auto commit 이 True인 경우 BEGIN으로 시작해야 한다. auto commit 이 True인 경우 모든 쓰기 작업이 바로 커밋이 된다. 이것을 막으려면 BEGIN으로 시작하고, END 혹은 COMMIT을 명시하면 그때 커밋하게 된다.
auto commit이 False인 경우 모든 쓰기 작업이 바로 커밋되지 않는다. BEGIN을 부르면 아무것도 하지 않는다. 생략이 가능하다. 중간에 에러가 발생했을 때 ROLLBACK을 하면 깔끔하게 uncommit되었던 것들이 삭제되고 원래로 돌아간다.
레코드의 변경사항을 바로 반영하는지에 따라 2가지의 트랜잭션으로 구분된다. 이는 autocommit이라는 파라미터로 조절할 수 있다.
- autocommit=True
- 기본적으로 모든 SQL statement가 바로 커밋된다.
- 바로 커밋되는 것을 방지하고 싶다면 BEGIN;END; 혹은 BEGIN;COMMIT을 사용 (혹은 ROLLBACK)
- autocommit=False
- 기본적으로 모든 SQL statement가 커밋되지 않는다.
- 커넥션 객체의 .commit()과 .rollback()함수로 커밋할지 말지 결정한다.
무엇을 사용할지는 개인 취향에 따라 선택한다. Python의 경우 try/catch와 같이 사용하는 것이 일반적이다. try/catch로 에러가 나면 rollback을 명시적으로 실행한다. 에러가 발생하지 않으면 commit을 실행한다.
오류를 파악하기 위해 끝에 raise를 붙여주는 것이 데이터 엔지니어링 관점에서 중요하다.
<실습을 위한 준비>
import psycopg2
# Redshift connection 함수
def get_Redshift_connection(autocommit):
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
user = "aelle_engineer"
password = "*"
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={user} host={host} password={password} port={port}")
conn.set_session(autocommit=autocommit)
return conn실습을 위한 Redshift Connection을 정의한다.
get_Redshift_connection 함수에 인자로 autocommit을 받는다.
2-1. INSERT INTO를 autocommit=False로 실행
# autocommit을 False로 설정
conn = get_Redshift_connection(False)
cur = conn.cursor()get_Redshift_connection 함수에 인자로 False를 전달해 autocommit을 False로 설정한다.
cur.execute("SELECT * FROM aelle_engineer.name_gender LIMIT 10;")
res = cur.fetchall()
for r in res:
print(r)name_gender 테이블의 레코드를 출력한다. 헤더와 레코드가 함께 출력된다.
cur.execute("DELETE FROM aelle_engineer.name_gender;")name_gender 테이블의 레코드를 전부 삭제한다.
cur.execute("SELECT * FROM aelle_engineer.name_gender LIMIT 10;")
res = cur.fetchall()
for r in res:
print(r)레코드가 전부 삭제되어 아무 결과도 출력되지 않는다.
-> 이 과정까지 autocommit이 False였기 때문에 다른 사람에게는 삭제되지 않은 초기의 상태로 보이게 된다.
cur.execute("INSERT INTO aelle_engineer.name_gender VALUES ('Keeyong', 'Male');")이어서 레코드 1개를 삽입한다.
# 추가한 레코드가 보인다.
cur.execute("SELECT * FROM aelle_engineer.name_gender LIMIT 10;")
res = cur.fetchall()
for r in res:
print(r)
''' 결과
('Keeyong', 'Male')
'''이 과정까지도 autocommit false로 반영이 되지 않아 다른 사람에게는 초기의 상태로 보인다.
# 커밋
cur.execute("COMMIT;") # conn.commit()와 동일. cur.execute("ROLLBACK;")와 conn.rollback()도 동일
# 커넥션 종료
conn.close()이 과정까지 반영하기 위해 commit을 진행하면, commit 전 최종 상태인 ('Keeyong', 'Male') 레코드가 보이게 된다.
2-2. INSERT INTO를 autocommit=False로 실행하며 try/except로 컨트롤하기
Try/Except 사용 시 주의사항
try:
cur.execute(create_sql)
cur.execute("COMMIT;")
except Exception as e:
cur.execute("ROLLBACK;")
raiseexcept에서 raise를 호출하면 발생한 원래 exception이 위로 전파된다.
- ETL을 관리하는 입장에서 에러가 감춰지는 것보다는 명확하게 드러나야 한다.
- 따라서, 위의 경우 cur.execute 뒤에 raise를 호출하는 것이 좋다.
raise가 없으면 try에서 에러가 발생해도 except에서 처리를 하기 때문에 Airflow에서는 문제가 없는 것으로 인식하게 된다. 에러가 발생했고 이를 except에서 완벽하게 처리할 수 있는 것이 아니라면 raise를 불러주는 것이 좋다. 에러는 명확하게 식별되어야 하기 때문이다.
실습
conn = get_Redshift_connection(False)
cur = conn.cursor()DB로의 커넥션을 다시 열어준다.
try:
cur.execute("DELETE FROM aelle_engineer.name_gender;") # 레코드 다 삭제 후
cur.execute("INSERT INTO aelle_engineer.name_gender VALUES ('Claire', 'Female');") # 새 레코드 삽입
conn.commit() # cur.execute("COMMIT;")와 동일
except (Exception, psycopg2.DatabaseError) as error:
print(error)
conn.rollback() # cur.execute("ROLLBACK;")와 동일autocommit이 False인 경우는 모든 작업이 transaction이기 때문에 BEGIN을 열지 않아도, 열어도 상관없다.
autocommit이 False인 경우 BEGIN은 어떠한 기능을 하지 않는다.
2-3. INSERT SQL을 autocommit=True로 실행하고 try/except로 컨트롤하기
conn = get_Redshift_connection(True)
cur = conn.cursor()autocommit 인자를 True로 한 DB로의 커넥션을 열어준다.
# 레코드 전부 삭제
cur.execute("DELETE FROM aelle_engineer.name_gender;")레코드를 전부 삭제하는 SQL문을 요청한다. 다른 세션에서 접근해 확인해보면 레코드 삭제가 바로 반영되는 것을 볼 수 있다.
try:
cur.execute("BEGIN;")
cur.execute("DELETE FROM aelle_engineer.name_gender;")
cur.execute("INSERT INTO aelle_engineer.name_gender VALUES ('Claire', 'Female');")
cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
finally :
conn.close()try/except를 적용한 전체 소스코드는 위와 같다.
2-4. INSERT SQL을 autocommit=True로 실행하고 SQL로 컨트롤하기
try/except를 사용하지 않아도 되지만 추천되지 않는다. 그러나 데이터 엔지니어에게는 try/except를 사용하지 않는 것이 깔끔하게 fail하고 끝나기 때문에 어설프게 오류 처리를 해서 오류를 확인하지 못하는 것보다 낫다. 에러가 캐치되지 않는 것은 매우 위험하다. Airflow에서 fail시 호출되는 함수와 슬랙을 연동해서 메세지가 전달되도록 설정할 수도 있다.
conn = get_Redshift_connection(True)
cur = conn.cursor()autocommit을 True로 설정해 Redshift 커넥션을 열어준다.
cur.execute("SELECT * FROM aelle_engineer.name_gender;")
res = cur.fetchall()
for r in res:
print(r)cur.execute("BEGIN;")
cur.execute("DELETE FROM aelle_engineer.name_gender;")
cur.execute("INSERT INTO aelle_engineer.name_gender VALUES ('Benjamin', 'Male');")
cur.execute("END;")2-5. 잘못된 SQL문 실행 시 오류
cur.execute("BEGIN;")
cur.execute("DELETE FROM aelle_engineer.name_gender;")
cur.execute("INSERT INTO aelle_engineer.name_gender3 VALUES ('Andrew', 'Male');")
cur.execute("END;")📍error
UndefinedTable: relation "aelle_engineer.name_gender3" does not exist
📌 Source
- 실리콘밸리에서 날아온 데이터 엔지니어링 스타터 키트 with Python 실습 자료
💡 질문과 피드백은 댓글에 남겨주시기 바랍니다.
❤️ 도움이 되셨다면 공감 부탁드립니다.
