
딥러닝
딥러닝과 머신러닝의 차이는 다음과 같다.
| 머신러닝 | 딥러닝 | |
|---|---|---|
| 활용데이터 형태 | 정형 데이터 | 비정형 데이터 |
| 데이터 의존도 | 데이터가 적어도 적정 수준의 성능 확보 가능 | 데이터가 적으면 성능이 좋지 않음 |
| 하드웨어 의존도 | 저사양 하드웨어에서 실행 가능 | 고사양 하드웨어 GPU 필요 |
| 설명력 | 회귀분석, DT 등 설명력 강점인 방법론 있음 | 모델 내부 연산 논리에 대해 추론 어렵 |
| 문제 해결 방법 | 분석가가 임의로 문제를 여러 단계로 나눠 해결 | End-to-End 방식으로 입력부터 출력까지 분석가의 개입 없이 가능 |
| 특징 추출 | 도메인 지식 또는 분석가의 의견이 반영되어 생성 | 딥러닝 네트워크 내부에서 스스로 학습 |
퍼셉트론
퍼셉트론은 뉴런처럼 데이터를 입력받아 가중치와 입력값을 조합하여 다음 퍼셉트론으로 전달하는 구조. 인공신경망은 퍼셉트론 여러개가 모여 복잡한 업무를 수행하는 네트워크 구조라고 할 수 있으며, 딥러닝은 인공신경망을 더 크고 깊게 확장한 것이다.
퍼셉트론은 선형 회귀 모델의 형태에서 출력값을 1 또는 0밖에 만들지 못하기 때문에 간단한 선형 분류만 다룰 수 있다. 따라서 퍼셉트론 여러개 모인 다층 퍼셉트론을 통해 보다 복잡한 문제 해결 가능하다.
다중 퍼셉트론
다중 퍼셉트론은 입력층과 출력층 사이에 한 개 이상의 히든레이어가 쌓인 구조이다.
- 입력층 : 입력 데이터를 받는 layer
- 은닉층 : 이전 레이어의 출력과 가중치 곱의 합을 입력받음로써 활성 함수가 적용된 layer
- 출력층 : 다층 퍼셉트론에서 최종 결과를 얻는 layer
입력층은 입력 변수 개수만큼 출력층은 예측 변수 개수만큼의 node 을 갖기 때문에 데이터에 의해 정해지지만 히등레이어의 layer 와 node 개수는 네트워크를 설계하면서 직접 설정해야한다. 은닉층의 각 node 에서 퍼셉트론 연산이 적용되기 때문에 다층 퍼셉트론에서 layer 와 node 의 수가 증가할수록 더욱 복잡한 문제 풀 수 있다.
각 layer 사이의 노드는 가중치로 연결되어 있다. 학습 파라미터인 가중치는 어떻게 구할 수 있을까?
다층 퍼셉트론은 feed forward 와 back propagation 을 반복하며 가중치를 추정한다. 처음에는 가중치 값을 랜덤으로 주고 입력층에서 출력층의 방향으로 단순 연산을 한다. (Feed Forwarding) 이때 출력값과 실제값의 오차를 계산한다. 이번에는 출력층에서 입력층의 방향으로 오차를 줄일 수 있게 가중치를 조정한다(Back Propagation)
인공신경망 핵심 알고리즘
다층 퍼셉트론을 포함한 퍼셉트론 구조의 모든 네트워크를 인공신경망이라고 한다.
- 미니 배치
머신러닝보다 비교적 복잡한 인공신경망은 안정적 학습을 위해 대용량의 데이터가 필요하다. 하지만 데이터 클수록 계산량 많아지고 하드웨어의 메모리 한계에 부딪힐 수 있기 때문에 데이터를 작은 단위로 나누어 학습한다.
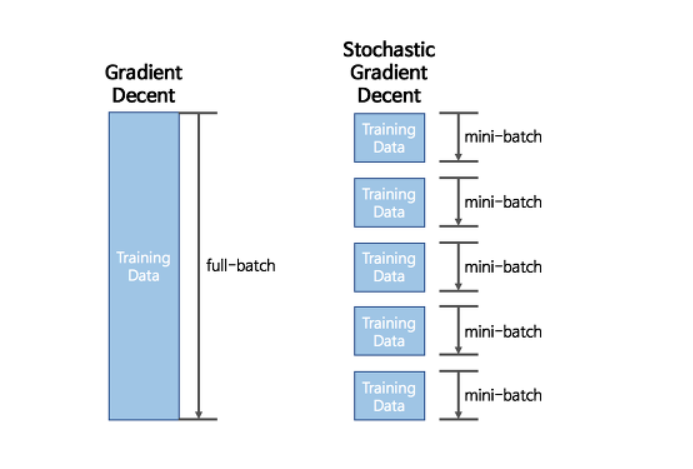
미니배치는 순차적으로 모델에 사용되는데 첫번째 미니배치를 통해 feed forwarding 과 back propagation 을 진행한 후 두번째 미니 배치를 통해 feed forward 와 back propagation 을 반복한다. 모든 미니 배치에서 학습이 수행되면 하나의 주기인 Epoch 이 끝난다. 미니 배치는 단순히 배치라고도 한다.
- 경사하강법
인공신경망의 가중치는 feed forwarding 과 back propagation 을 반복하며 오차를 줄이는 방향으로 학습된다. 선형 회귀 모델의 손실 함수인 MSE 는 다음과 같이 각 회귀 계수에 대한 2차 함수이다. MSE 그래프는 다음과 같은 형태로 나타내는데 우리가 찾는 최적의 회귀 계수는 손실 함수가 가장 작은 부분에서 구합니다(오차가 제일 작은 부분) 수식으로 치면 MSE 를 회귀 계수로 미분하여 기울기가 0이 되는 지점으로 선택한다. 회귀 모델의 손실 함수는 간단하므로 미분으로 다소 쉽게 최적의 회귀 계수를 구할 수 있다.
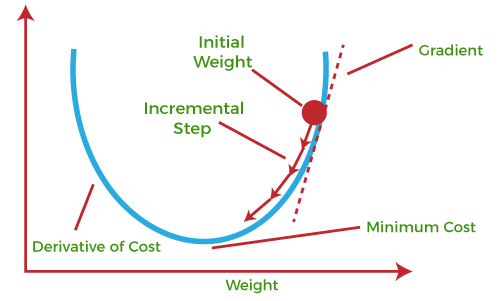
반면, 인공신경망은 활성 함수로 비선형 함수를 사용하며 은닉층이 깊어질 수록 함수가 깊어지기 때문에 미분하여 손실함수의 최소점을 찾기 힘들다. 그래서 Feed Forward 와 back propagation 을 반복하며 최적의 가중치를 탐색한다. 이때 back propagation 과정에서 오차를 줄이는 방향으로 가중치를 업데이트하는 방식을 '경사하강법' 이라고 한다.
경사하강법은 현재 손실함수의 위치에서 가장 기울기가 가파른 방향으로 학습 파라미터를 업데이트하는 것이다. 기울기는 gradient 라고 불리며 미분을 통해 구할 수 있다. 그 다음으로 정할 것은 얼마만큼의 보폭으로 거닐지 학습률을 정해야한다.
Learning rate 은 임의로 정하는 hyperparamater 로서 너무 작게 설정하면 local minimum 에 빠져 최적의 가중치를 얻지 못할 수 있다. 반면, 너무 크게 설정하면 오버슈팅되어 손실함수가 발산하므로 학습이 이루어지지 않는다.
아래의 수식은 경사하강법으로 가중치를 업데이트하는 것을 보여준다.

우리가 원하는 가중치는 global minimum 손실 함수의 가중치이다. 하지만, 손실 함수의 복잡도나 learning rate 에 따라 global minimum 을 찾기 어려울 수 있기 때문에 경사하강법의 심화 방법론인 momentum , Adaptive gradient, Adam 그리고 RMSprop등을 사용한다.
Activation Function
인공신경망이 성능이 좋은 이유는 비선형 활성 함수를 사용하기 때문이다. 활성 함수는 노드의 입력 신호와 가중치 곱을 더한 값을 입력으로 받는 함수이다.
선형 함수가 아닌 비선형 함수를 사용하는 이유는, 선형함수인 f(x)= ax 를 활성함수로 사용하여 3개의 레이어를 쌓는다고 하면, 이 네트워크는 한개의 레이어를 사용한 네트워크와 유사한 상황이 된다 ( f = a(a(a(x))) ) 따라서 여러 은닉층의 효과를 보기 위해서는 비선형 함수의 활성함수를 사용해야한다.
퍼셉트론은 특정 임계치 이상이 되면 신호가 전달되는 Step Function 을 사용했지만, 인공신경망에서는 가중치를 찾는 과정에서 미분이 필요하므로 임계치 부분에서 미분이 불가능한 Step Function 을 사용할 수 없다. 초기에는 대안으로 Sigmoid function 을 사용했지만 gradient vanishing 이라는 기울기 소멸문제가 발생하여, 최근에는 ReLU, ELU 등의 함수를 사용한다.
gradient vanishing : 출력값이 0 또는 1에 가까우면 기울기가 0에 가까운 아주 작은 값이 된디. 가중치를 업데이트하는 과정에서 너무 작은 기울기가 곱해지게되면 값이 0에 가까워지면서 가중치 학습이 잘 되지 않는다 이러한 현상을 gradient vanishing 이라고 한다.
출력함수
출력함수는 마지막 출력층의 결과를 목적에 맞는 적절한 형태로 변형해주는 역할을 한다.
회귀 문제이면 입력값을 그대로 출력하는 Identtity function , 분류 문제면 Softmax Function 을 사용한다.
Identity function
Softmax function : 입력값을 0에서 1 사이로 정규화하여 출력값의 총합을 항상 1로 만듦
Dropout
인공신경망은 layer 와 node 가 많아질수록 모델이 복잡해지기 때문에 오버피팅이 발생할 수 있다. dropout 은 과적합을 방지하는 Regularization 과 모델을 앙상블하는 효과를 준다.
Dropout 은 학습과정에서 일정 비율의 노드만 사용하며 나머지는 사용하지 않는다. 노드를 끄면 연결된 가중치가 사용되지 않으므로 학습할 파라미터 수가 줄면서 일반화된 모델을 생성할 수 있다. 또한, 각 배치를 학습할 때마다 랜덤하게 노드가 선택되기 때문에 특정 조합에 너무 의존적으로 학습되는 것을 방지하며, 인공신경망을 앙상블하여 사용하는 것 같은 효과를 준다.
Batch Normalization
여러 개의 은닉층을 통과하면서 입력 분포가 매번 변화하는 문제를 Internal Covariance Shift 라고 한다. 이 문제는 학습 과정을 불안정하게 하여 가중치가 엉뚱한 방향으로 업데이트되는 원인이 된다.
Batch Normalization 은 각 layer 에서 활성 함수를 통과하기 전 정규화를 통해 활성 함수 이후에도 어느 정도 일정한 분포가 생성되도록 하여 Internal Covariance Shift 를 통해 해결한다.
고급 딥러닝 기술
CNN
Convolutional Neural Network 은 이미지나 영상을 다루는 컴퓨터비전에서 가장 대표적으로 사용되는 인공신경망이다. 컴퓨터 비전은 딥러닝의 발전 영역에서 가장 두각을 나타내는 분야 중 하나다.
CNN 은 1980년대 토론토 대학의 얀 르쿤과 그의 동료들이 우편번호와 수표의 숫자 필기체를 인식하는 LeNet 이라는 모델을 개발하면서 처음 소개되었다. 알고리즘은 성공적으로 동작했지만 10개의 숫자를 학습하는 데 약 3일이 걸렸기 때문에 실제로 사용하는 데 제한이 있었다. 약 30년이 지난 후 오버피팅과 학습 시간의 문제를 해결할 수 있게 되면서 CNN 을 원할히 학습시킬 수 있었다.
현재는 이미지 분류는 기본이고 얼굴 인식과 자율 주행처럼 어려운 과제인 객체 인식 분야에서도 CNN 을 많이 사용하고 있다.
정형 데이터 : 데이터베이스 시스템 테이블 같이 고정된 컬럼과 개체의 관계로 되어 있다.
이미지 : 한 장의 사진처럼 보이지만 컴퓨터가 읽을 때는 픽셀 단위의 숫자 행렬로 되어 있다.
다층 퍼셉트론의 입력층 node 수는 정형 데이터의 입력 변수 개수와 같다. 그렇다면 다층 퍼셉트론에 이미지를 적용하려면 어떻게 할까? 이미지를 정형 데이터로 바꾸려면 행렬을 1차원 벡터로 펼쳐주어야 한다.
하지만 행렬을 이렇게 정형 데이터의 행으로 풀면 이미지가 갖는 고유의 특성인 공간적 정보를 잃어버릴 수 있다. 예를 들어 사진에 임의의 한점을 찍으면 해당 점의 주변은 비슷한 색으로 구성되어 있을 것이다. 컴퓨터가 인식하는 데이터 형태로 생각하면 위치가 근접한 픽셀끼리는 굉장히 유사한 정보를 갖고 있다. 그런데 이를 벡터로 변환하면 공간적 정보가 사라지게 된다. 이러한 정형 데이터를 입력으로 받는 다층 퍼셉트론의 단점을 CNN 은 이미지 그대로 입력을 받음으로써 극복할 수 있다.
CNN 은 크게 Convolutional Layer, Pooling Layer , Fully Connected Layer 세 개의 layer 로 구성되어 있다.
- Convolutional layer : 이미지의 공간적 정보를 학습
- Pooling layer : Convolutional layer 의 차원 형태의 크기를 줄임으로써 학습 파라미터 개수를 감소
- fully connected layer : 최종 출력을 위한 다층 퍼셉트론 구조.
Convolutional layer
Convolutional layer 은 CNN 에서 가장 핵심이 되는 부분으로 이미지의 중요한 지역 정보를 뽑는 역할을 한다. Convolutional layer 에서는 이미지에 필터(또는 커널)을 적용하여 Convolution 을 수행한다. Convolution 은 필터가 입력 이미지를 훑으면서 겹치는 부분의 각 원소를 곱하여 모두 더한 값을 출력하는 연산이다.
Filter 은 CNN 에서 학습할 가중치로써 다층 퍼셉트론과 마찬가지로 초기에는 랜덤으로 주어지며 손실 함수가 줄어드는 방향으로 학습된다. 잘 학습된 필터는 이미지의 특징을 추출한다. 다양한 특징을 뽑기 위해 여러개의 필터를 사용하며 예를 들어 Vertical Filter, Horizontal Filter 두개의 필터를 사용할 수 있다. CNN 내부에는 다양한 필터를 적용한 Feature Map 으로 이미지의 여러 정보를 결합하여 분류를 잘하도록 학습이 진행된다.
Convolutional Layer 에서 정해야할 하이퍼파라미터로는 필터의 크기, Stride (필터를 움직이는 간격)와 padding (Convolution 하면 크기 줄어드는 것 방지하고자 입력 이미지 외각에 임의의 값 부여)사용 여부가 있다.
Stride가 크면 Feature map 은 작아지므로 CNN 구현할 때는 Stride를 주로 1로 설정한다.
Convolution 은 이미지의 크기를 줄이므로 Convolutional Layer 을 여러개 거치면서 이미지의 크기는 계속해서 작아지게 되고, 이미지의 가장자리에 위치한 픽셀은 중앙에 위치한 픽셀에 비해 상대적으로 연산에 잘 활용되지 않으며 점점 정보가 사라지게 된다. 이러한 문제를 방지하고자, Padding 으로 이미지 가장자리에 임의의 값이 설정된 픽셀을 추가함으로써 입력 이미지와 Feature map 의 크기를 갖게 만든다.
Pooling layer
Pooling layer 은 Convolutional layer 로 계산된 feature map 의 크기를 줄여 연산량을 줄이는 역할을 한다. 크기를 압축하는 대표적 방법은 max pooliing 과 average pooling 으로 feature map 에서 지정한 영역에서 대표값으로 최대 또는 평균을 취하는 것이다. poooling layer 은 인접한 픽셀 중 중요한 정보만 남기는 강조 효과를 가져올 수 있으며, Convolutional layer 와 달리 단순 계산만 진행하기 때문에 가중치 따로 없다. pooling layer 은 모든 Convolutional layer 에 적용할 필요는 없으며 선택사항이다.
Fully Connected layer
CNN 은 회귀와 분류 모두에 적용할 수 있으며, 다층 퍼셉트론과 마찬가지로 최종 출력값은 분류 문제이면 각 클래스에 대한 예측 확률 벡터, 회귀 문제면 예측값 벡터이다. 이미지의 입력 데이터는 Convolutional layer 와 pooling layer 을 통과하면서 주요 특징만 추출된 여러 개의 feature map 의 형태이다. 고차원의 feature map 이 출력값의 형태인 1차원 벡터로 변환되기 위해 flatten layer 을 거치게 된다. 예를 들면 데이터 하나당 feature map 이 32개라면, 3288 = 2048 길이의 1차원 벡터로 변환된다.
RNN
시계열과 같은 순차적 데이터는 과거가 미래에 영향을 주기 때문에 데이터 사이에 독립을 가정한 모형을 적합시키면 좋은 성능을 기대하기 어렵다.
RNN(Recurrent Neural Network) 은 음성 인식과 자연어처리와 같이 순차적 데이터에 사용되는 대표적인 아록리즘으로 LongShort-Term Memory(LSTM) 과 Gated Recurrent Unit(GRU) 의 근간이 되는 모델이다. 인공신경망과 CNN 은 입력층에서 은닉층으로, 은닉층에서 출력층으로 움직이는 순방향 신경망이다. 반면, RNN 은 입력층에서 출력층으로 입력값을 보내는 동시에 다음 시점의 은닉층으로도 입력이 흐르는 형태이다.
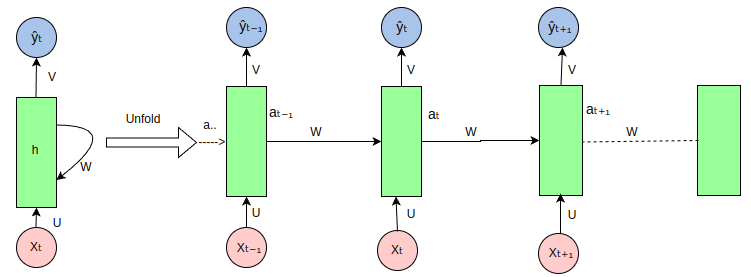
RNN 은 다양한 입력, 출력 시퀀스에 따라 유연하게 네트워크 구조를 설계할 수 있으며, 그만큼 여러 문제에 적용될 수 있다.
- One to Many : 이미지를 설명할 수 있는 문장을 생성하는 문제
- Many to One : 텍스트에서 정보를 추출하여 감정, 태도를 파악하는 감정 분석
- Many to Many : 동영상의 각 이미지 프레임별 분류
- Delayed Many to Many : 입력된 언어를 다른 언어로 변환하는 기계 번역
RNN 은 입력과 출력 사이의 시점이 멀어질수록 그 관계가 학습되기 어려우며 가까운 시점의 입력만 잘 기억한다.
LSTM
RNN 에서 입력과 출력시점이 멀어질수록 학습이 잘안되는 현상을 Long-Term Dependency Problem 이라고 한다. 예를 들어 "나는 민수와 밥을 먹고 있다. 그는 피자를 좋아한다"는 문장에서 "그"가 "민수"임을 쉽게 알 수 있다. 하지만 "나는 오늘 오후에 민수를 만나기로 했다. 집을 나서기 전, 남동생과 함께 게임을 했다... 오후에 약속장소인 피자집에 도착했다. 피자는 그가 가장 좋아하는 음식이다"라는 긴 문장에서 "그"가 "민수"임을 알기 위해서는 단락의 첫 문장 정보까지 파악해야한다. RNN 의 특징은 과거의 정보를 은닉층에 저장하는 것인데 이로 인해 치명적인 단점이 발생한다.
매 시점이 지날수록 의 가중치와 활성함수가 누적되어 곱해지기 때문에 과거의 정보가 점점 잊히는 것이다.
LSTM 은 RNN 구조에 몇 가지 기능을 추가하여 Long-Term Dependency Problem 을 해결한 모델이다. RNN 은 활성 함수 하나로 구성된 은닉층이 반복되는 체인 구성이었다면 LSTM 은 상호작용하는 여러 모듈이 속한 구조가 반복된다.
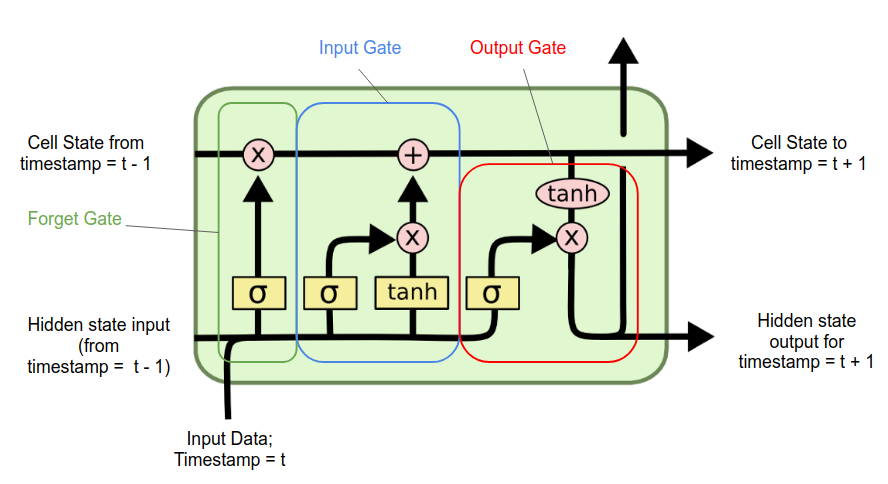
LSTM 의 핵심인 은 Cell State 라고 부르며 RNN 에서는 없던 개념이다. Cell State 은 LSTM Cell 을 관통하고 있으며 중간에 어떠한 연산으로 업데이트되어 통과하게 된다. 각 연산에는 과거의 정보를 얼마큼 기억하고 현재의 데이터를 얼마큼 더할 것인가를 조절한다. '얼마큼'의 정도는 수도꼭지의 밸브 역할을 하는 Gate 에 의해 정해진다. Cell State 은 Forget Gate 와 Input Gate 2개와 연결된다.
Forget Gate 은 '과거 메모리를 얼마나 기억할 것인가'에 대한 의사결정을 해주는 Gate 이다.
input gate 은 '현재 정보를 과거 메모리에 얼마큼 더할 것인가'에 대한 의사결정을 하는 gate 이다.
