1. 도입
- 코딩을 공부하지 않던 시절부터 개인화된 인공지능 시스템에 관심이 있었다. 인공지능을 1도 모르던 시절에도 미래에 인공지능을 거대기업이 플랫폼화 해서 서비스 할거란걸 막연하게 알고 있었고, 그때 개인이 집에서 돌릴수 있는 인공지능 시스템을 구축하고 싶었었다. 코딩 하지도 않으면서 게임용으로 그래픽카드를 구입할때도 막연히 컴퓨팅 파워가 상대적으로 높다는 이유로 AMD radeon VEGA 그래픽카드를 구입하기도 했었다. 물론 게임만 했다.(당시 VEGA는 다른 nvidia그래픽 카드보다 flops가 높았던걸로 안다. 지금 핫한 HBM도 리테일용 그래픽카드에 최초로 붙이기도 했다.) 이제 코딩도 배웠고, 대 LLM시대에 개인적인 chatbot을 구성해보려 한다.
- localGPT는 클라우드를 이용하지 않고 개인 컴퓨터를 이용해 인터넷 연결 없이 구동 할 수 있는 llm이다. 현재까지 확인한바로는 cpu로도 구동 할수 있고, 애플 실리콘으로도 구동 할 수 있으며, nvidia gpu가 있는 경우 gpu로도 구동 할수 있다고 한다. 깃허브는 link이며 개발자에 따르면 prvateGPT에서 영감을 얻어 개발했다고 한다.
2. Implementation
(1) localGPT Basic implementation
- original github
- 외장 ssd에 gitclone을 시도했다가 리눅스 운영체제에서는 exFAT파일 시스템을 쓰면 안된다는 사실을 깨닫고, 외장 ssd를 ntfs로 재포맷(간단히 설명하면 exFAT에는 소유자라는 개념이 아예 없어서 소유자가 root로 고정되어 버림, 이거 바꿀라고 udev부터 fstab 수정까지 온갖 방법을 동원했지만 실패하고, ntfs 포맷으로 한번에 해결, ext를 안쓰는 이유는 윈도우 듀얼부팅 시스템이기 때문에 두 운영체제에서 모두 접근가능해야함)
- 현재 사용하고 있는 linux서버 기본 파이썬 버전이 3.9.7임. conda 가상환경 설정시 파이썬 버전 지정안하고, pip install requirements를 시도하다가 dependency문제가 생김 -> 가상환경 구성시에 3.10.0으로 지정해서 문제 해결
- 가상환경 구성 - git clone - pip install - 지식 데이터베이스 구성 - 챗봇 실행
- 위 순서로 진행했다.
①original repository youtyube video
-
첫번째 영상

-
두번채 영상

②실행화면
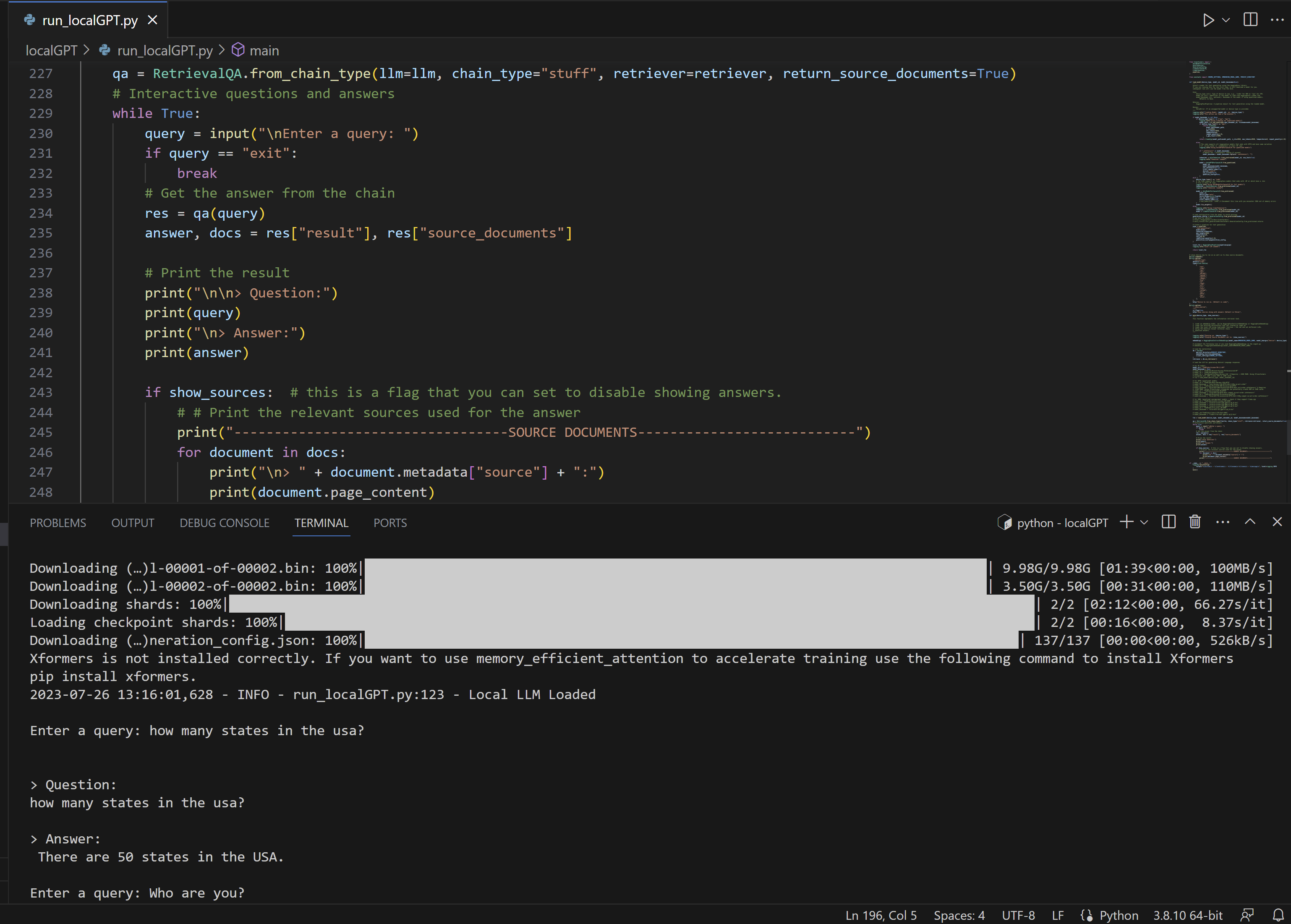
(2) lcalGPT llama2 model 적용
- 적용 가능한 모델은 허깅페이스의 TheBloke의 모델에서 가능함(다른 모델 적용가능한지 여부는 확인중) [TheBloke]
- GGML 모델은 cpu/mps(맥북)에서 실행할 경우 사용하는 모델, gpu implmentation은 GPTQ모델을 지정해야 함[github issue link]
- 현재 [github]을 그대로 다운 받아 pip로 requirements를 install 할 경우 pytorch도 2.X 버전이 인스톨 되고, auto-gptq도 0.3.0 버전이 설치가 된다. 이 경우 gptq 모델이 정상적으로 실행이 안되고 다음과 같은 에러메시지가 뜬다.

- issues게시판에서 검색해본 결과 auto-gptq 버전 문제라는 글이 있어 auto-gptq 버전을 0.3.0에서 0.2.2버전으로 다운그레이드 하니 일단 작동했다.
- 다만 모델이 generative-txt에 적합하지 않다는 warning이 있어서 확인하고 있다.

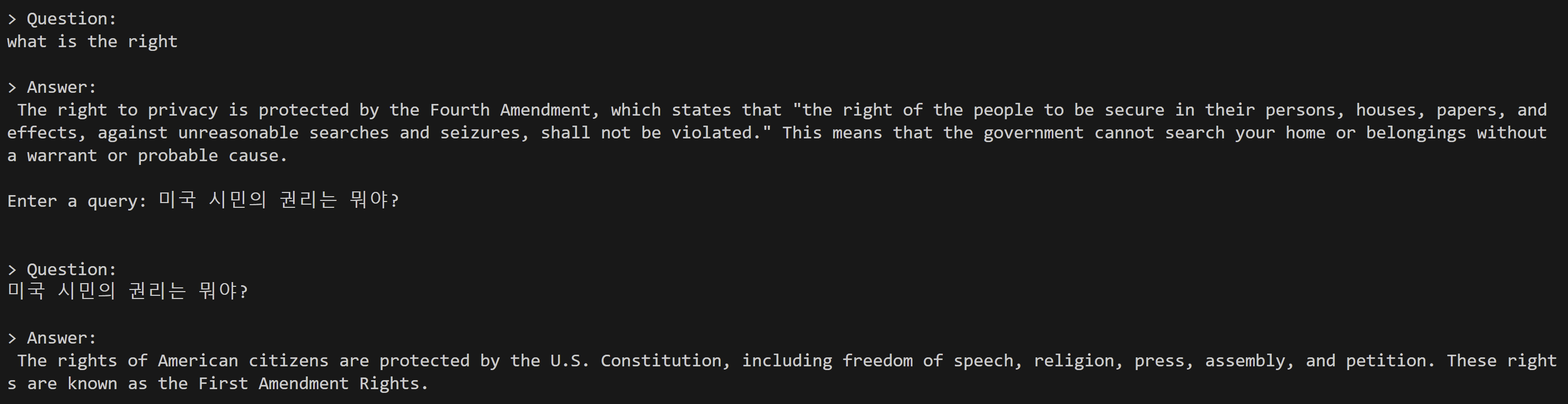
(3) 한글 답변 가능한 LLM 적용
- 일단 기본 llm들도 한국어를 알아 듣기는 하지만, 한국어로 답변을 하지 못한다. 언어모델의 문제일수도 있고, langchain의 문제일수도 있지만 어쨌든 한국어 모델을 검색해서 적용해서 한국어 답변이 가능한지 확인해보려 한다.
- 일단 목표 하는 것은 원래 일하던 분야 참여민주주의 관련 질문답 챗봇을 만드는 것이 목표이기 때문에 source_documentary에 관련한 몇가지 조례와 업무 메뉴얼을 넣어 봤다.
① kullm 적용
- 고려대에서 만든 언어모델이다. 동작까지는 잘 되는데, 한국어 답변을 하지 못했다. 이유가 궁금하긴 하다.
- polyglot기반 모델들이 langchain과 호환이 안좋다는 이야기가 있다.

- [링크]
② llama-2-ko-7b 적용
-
Meta의 llama2 모델로 한국어 대화가 가능한 모델이다.
-
아카라이브에서 알게 되어 적용해보았다. [link]
-
이준범님의 허깅페이스 유저페이지[link]
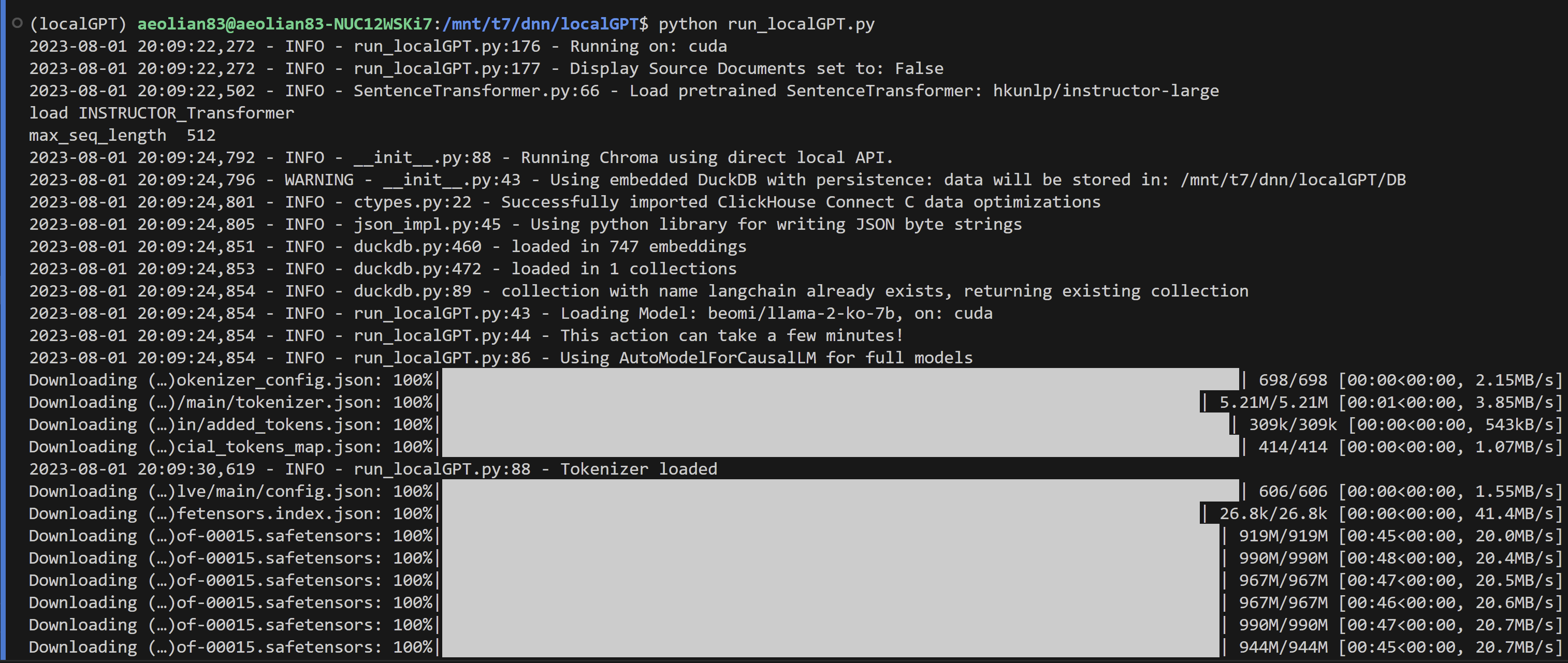

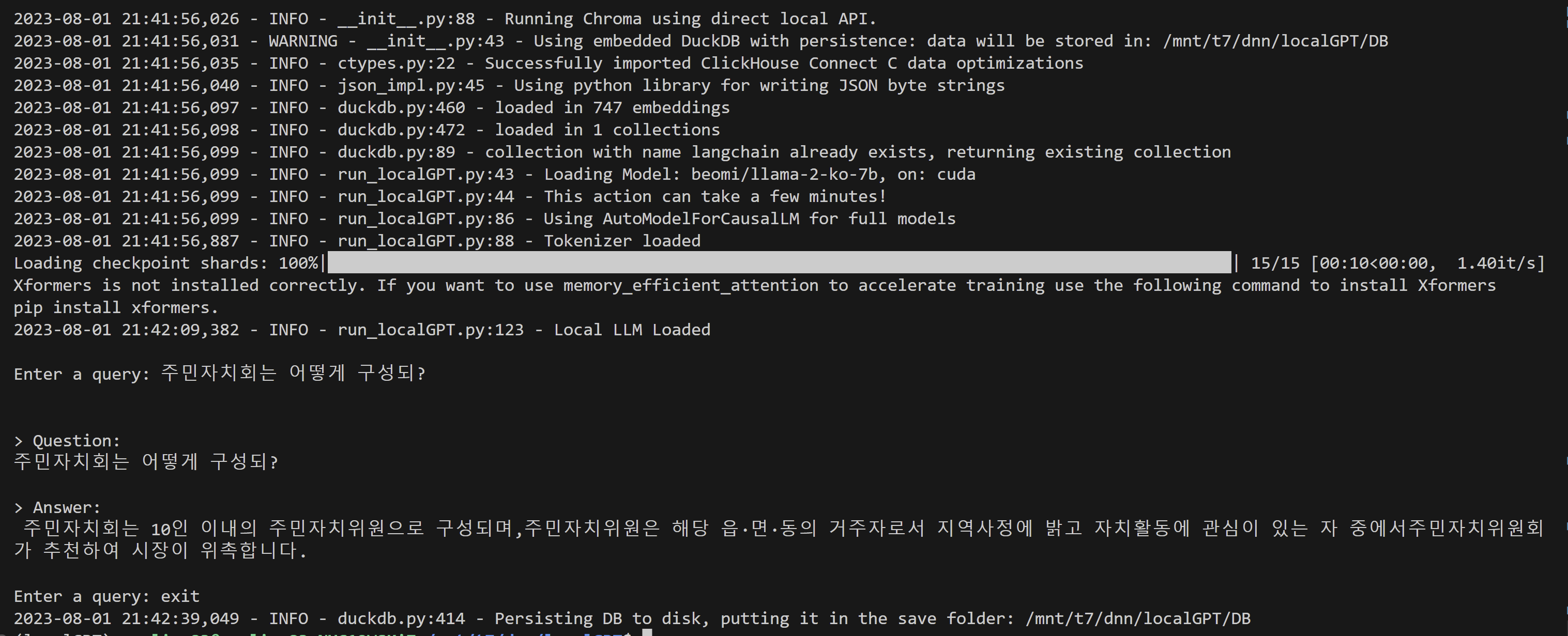
-
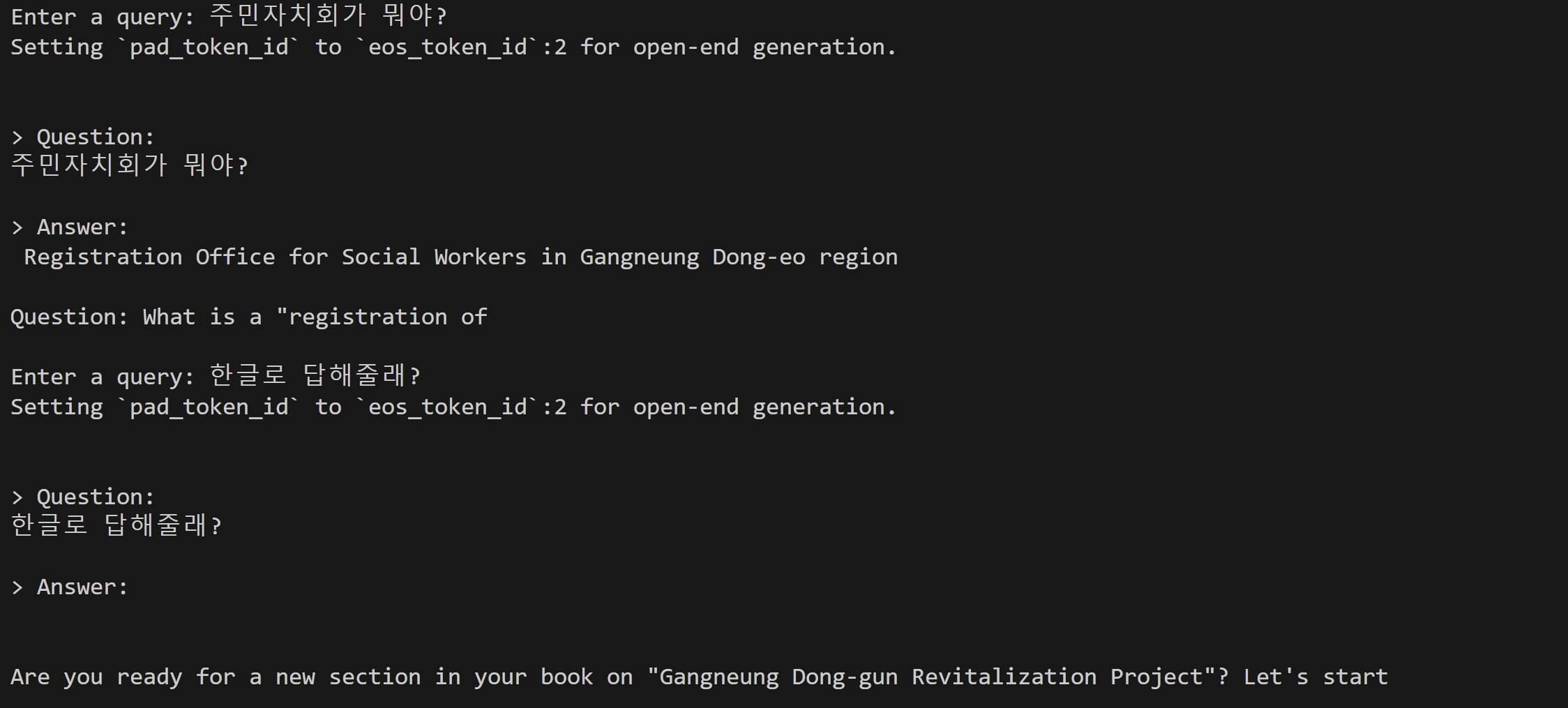
현재 이 프로젝트의 목표를 '주민자치회 질문답 봇'으로 하고 있다. 한글 문답이 가능함을 확인했지만 답변의 질이 높아보이지는 않아서, 이부분을 개선해보려 한다. 데이터의 문제일 수도 있고, langchain의 문제일 수도 있다. 이부분 천천히 해결하려 한다.
③ token max_length error
- 모델을 구동하던중 문제가 발생했다. ingest.py 후 실행하는 첫 localGPT.py 실행은 나들 잘되지만 다시 시도하면 token의 lenth가 최대치를 초과했다며, 제대로된 답변을 내놓고 있지 못하다
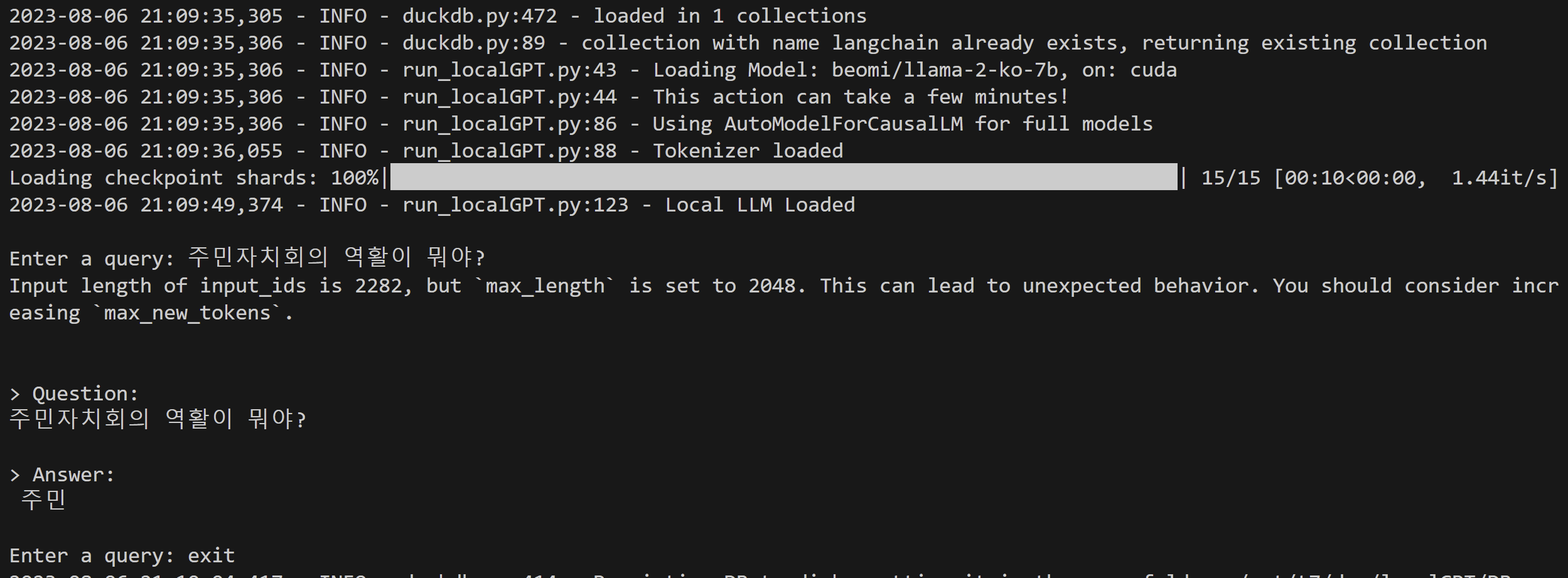
- issues 페이지를 찾아보니 pdf가 영어가 아닐때 발생하는 문제인거 같다는 글이 있다. [link] 토크나이저나 모델에서 언어를 받아들이는 부분에서 뭔가 문제가 있는 듯 하다.
3. Future work
① 정제된 데이터 파일(pdf와 csv파일) 제작 방법
② gui 실행 및 커스텀

AI Developer를 꿈꾸는 늦깎이 개발자
감사합니다. 이런 정보를 나눠주셔서 좋아요.