
단위 테스트 Why, How, What?
매일 작성하는 단위 테스트…
단위테스트를 왜(why) 작성하는지를 알아보고, 좋은 테스트코드를 작성하기 위한 방법(how)과 단위 테스트를 하면 좋은 부분(what)에 대해 알아봅니다.
이 글은 구글 엔지니어는 이렇게 일한다 테스트 부분(CH11-13), 단위테스트 책을 기반으로 정리한 내용입니다.
1. 테스트를 작성하는 이유?
보통 테스트의 대상이 되는 요소들에는 다음이 있습니다.
- 테스트 하려는 단 하나의 행위 (메서드나 API)
- 특정한 입력(전달하는 값)
- 관측 가능한 출력 또는 동작
- 통제된 조건
위와 같은 테스트를 실행하면 시스템에 특정 값을 입력하고 출력 결과를 확인하는 과정을 자동화할 수 있고 시스템이 잘 동작하는지를 판단하게 됩니다. 그리고 이런 간단한 테스트가 여러개 모이면 제품이 전체적으로 의도한대로 잘 동작하는지 확인할수 있게됩니다.
2. 단위 테스트란?
구글에서 말하는 단위테스트는 단일 클래스나 메서드처럼 범위가 상대적으로 좁은 테스트를 말합니다. (단위 테스트는 일반적으로 크기가 작지만 반드시 그런 것은 아니라고 합니다.)
테스트의 가장 중요한 목적은 버그 예방이고, 그 다음으로 중요한 목적은 엔지니어의생산성 개선에 있는데,
범위가 더 넓은 테스트들과 비교해서 단위 테스트는 생산성을 끌어올리는 훌륭한 수단이 될 수 있는 특성을 많이 지니고 있습니다.
단위 테스트가 가진 장점
- 단위 테스트는 대체로 작은 테스트에 속하기 때문에, 빠르고 결정적이어서 개발자들이 수시로 수행하고 피드백을 얻을 수 있습니다.
- 단위 테스트는 대체로 대상 코드와 동시에 작성할 수 있을 만큼 작성하기 쉽습니다.
- 빠르게 작성할 수 있으므로 커버리지를 높이기 쉽습니다.
- 각각의 테스트는 개념적으로 간단하고 시스템의 특정 부분에 집중하기 때문에 실패 시 원인을 파악하기 쉽습니다.
- 대상 시스템의 사용법과 의도한 방식을 알려주는 문서자료 혹은 예제 코드 역할을 해줍니다.
단위 테스트는 엔지니어의 일상에서 비중이 크기 때문에, 구글은
테스트 유지보수성(test maintability)를 상당히 중시합니다.
그럼 유지보수성(test maintability)이란?
유저보수성이 높은 테스트, 즉 유지보수하기 쉬운 테스트는 그냥 잘 작동하는(just work),한 번 작성해두면 실패하지 않는 한 엔지니어가 신경 쓸 필요 없고, 실패한다면 진짜 버그를 찾았다는 뜻인 테스트를 의미합니다.
테스트가 깨져서 오류가 났는데 실패한 테스트들을 하나씩 해결하느라 하루를 다 소비했다면..?
근데 그 테스트가 깨져서 확인해보 버그를 찾은것이 아니라 내부 구현에 의해 난 오류라면...
위와 같은 상황에서 테스트는 원래 의도와는 정반대의 효과를 냈습니다. 코드의 품질을 의미있게 높여주지도 못했고, 생산성을 갉아먹었습니다.
이러한 상황을 방지하기 위해 질 나쁜 테스트는 반영되기 전에 수정돼야 합니다. 위와 같은 문제는 아래와 같은 상황에 의해 발생했을 확률이 높습니다.
- 버그도 없고 자신의 검증 대상과 관련이 없는 변경 때문에 실패하는
“깨지기 쉬운”테스트라서 - 무엇이 잘못되어 실패했는지, 어떻게 어디를 고쳐야 하는지를 파악하기 어려운
“불명확한”테스트라서
그럼 어떻게, “깨지지 않고”, “명확한” 테스트 코드를 작성해서 생산성을 높일 수 있는지 알아봅시다.
3. 깨지지 않는 테스트 만들기
테스트에 영향을 줄 수 있는 상황들
- 순수 리팩토링 (테스트 변경 X)
- 새로운 기능 추가 (테스트 변경 X, 새 기능에 대한 테스트만 추가)
- 버그 수정 (테스트 변경 X, 누락된 테스트만 추가)
- 행위 변경 (테스트 변경 O)위와 같은 상황에서의 요점은 리팩토링, 새 기능 추가, 버그 수정 시에는 기존 테스트를 손볼일이 없어야 한다는 것입니다. 기존 테스트를 수정해야 하는 경우는 시스템의 행위 달라지는 파괴적인 변경이 일어날 때 뿐입니다.
그럼 이런 상황에서 깨지지 않는 테스트를 만들기 위해서는 어떻게 해야될까요?
3-1. 깨지지 않는 테스트 첫번째: 공개 API를 이용해 테스트하기
테스트 대상을 다른 사용자 코드와 똑같은 방식으로 호출하는 것입니다. 내부 구현을 위한 코드가 아닌 공개되어 있는 API를 사용하면 됩니다. 즉, 테스트가 시스템을 사용자와 똑같은 방식으로 사용하는 것입니다.
- 예) 거래가 유효하면, 거래를 진행시키는 API
// 은행 거래 API
public void processTransaction(Transaction transaction){
if(isValid(transaction)){
saveToDatebase(transaction);
}
}
private boolean isValid(Transaction t){
return t.getAmount() < t.getSender().getBalance();
}🔴 거래 메소드의 구현을 바로 검증하는 안좋은 테스트
@Test
public void empyAccountShouldNotBeValid(){
assertThat(processor.isValid(newTransaction().setSendor(EMPTY_ACCOUNT)))
.isFalse();
}- 이처럼 private 접근 제한자를 제거하고, 구현 로직을 직접 테스트하게 되면, 이 테스트를 깨지기 쉬워집니다.
- 가령 내부 메소드의 이름이 바뀌었다거나 isValid메소드의 인자나, 내부 로직이 변경되도 테스트는 깨지게 됩니다.
🟢 공개 API로 테스트
@Test
public void shouldTransferFunds(){
processor.setAccountBalance("me", 150);
processor.processTransaction(newTransaction()
.setSender("me")
.setRecipient("you")
.setAmount("100"));
assertThat(processor.getAccountBalance("me")).isEqualTo(50);
}- 한편, 공개 API만 사용해도 원하는 목적의 테스트를 작성할 수 있습니다.
- 공개 API만 사용하는 테스트는 대상 시스템을 사용자와 똑같은 방식으로 사용하기 때문에 잘 깨지지 않습니다. 만약에 여기에 문제가 있다면, 해당 공개 API를 사용하고 있는 사용자도 똑같은 문제를 겪고 있다는 엔지니어에게 유용한 신호가 됩니다.
3-2 깨지지 않는 테스트 두번째: 상호작용이 아니라 상태를 테스트하기
시스템이 기대한대로 동작하는지 검증하는 방법은 크게 두가지가 있습니다. 첫번째는 상태 테스트로, 메소드 호출 후 상태변화를 관찰하는 것이고, 두번째는 상호작용 테스트로 과정에서 다른 모듈들과 협력해서 기대한 동작을 수행하는지를 확인하는 것입니다.
대체로 상호작용 테스트가 상태 테스트보다 깨지기 쉽습니다. 이유는, 결과가 “무엇(what)”인지를 테스트하는것이 아니라, “어떻게(how)” 작동하냐를 확인하려 들기 때문입니다.
🔴 상호작용 테스트
@Test
//테스트의 목적: 데이터가 반영이 됐는지.
public void sholdWriteToDatabase(){
accounts.createUser("foobar");
//database 의 메소드를 호출했는지를 검증(상호작용검증)
verify(database).put("foobar"); // 데이터베이스의 put()메서드가 호출됐는지를 확인
}- 하지만 이 테스트는 설계 의도와 다르게 판단할 수 있는 시나리오들이 존재합니다.
- 만약에 put()메소드 호출 성공 이후 버그가 있어서 데이터가 반영이 안됐으면? (실패해야되는 상황이지만 테스트는 성공합니다.)
- 시스템을 리팩토링해서 같은 기능을 put()이 아닌다른 API를 호출하도록 바꿨다면? (성공해야되는 상황이지만 테스트는 실패합니다.)
보통 상호작용 테스트가 만들어지는 가장 큰 원인은 모킹 프레임워크에 지나치게 의존하기 때문인데, 모킹 프레잌워크를 이용하면 테스트 대역을 쉽게 만들수 있지만 깨지기 쉬운 테스트 코드를 작성하게 되는 원인이 되기도 합니다.
🟢 상태 테스트
@Test
public void sholdCreateUsers(){
accounts.createUser("foobar");
assertThat(accounts.getUser("foobar")).isNotNull();
}- 기능 호출 후에 시스템이 어떤 상태에 놓여있는지를 확인하고 있습니다.
- 위 테스트 코드는 우리가 무엇에 관심있는지를 더 정확하게 표현할 수 있습니다. 테스트 코드가 깨질 확률이 낮아지게 됩니다.
4. 명확한 테스트 작성하기
깨지기 쉬운 요소를 제거했다고 해도, 언젠간 테스트는 실패할 수 있습니다. 실패한 테스트는 엔지니어에게 유용한 신호가 되기 때문에 단위 테스트의 존재 가치를 증명하는 중요한 수단입니다.
이때, 테스트 실패의 원인을 빠르게 파악하는 것이 중요한데, 이것이 바로 테스트의 명확성에 달려있습니다.
명확한 테스트란 테스트의 존재 이유와 실패 원인을 엔지니어가 곧바로 알아 차릴 수 있는 테스트를 말합니다.
4-1. 완전하고 간결하게 만들기
- 완전한 테스트 : 결과에 도달하기 까지 필요한 모든 정보를 담고 있는 테스트
- 간결한 테스트 : 코드가 산만하지 않고, 관련 없는 정보는 포함하지 않은 테스트
아래 예제는 계산기를 생성하고, 계산이 잘동작하는지를 테스트하는 코드입니다.
🔴 불완전하고 산만한 코드
@Test
public void sholdPerformAddition(){
Calculator calculator = new Calculator(new RoundingStrategy(),
"unused", ENABLE_COSINE_FEATURE, 0.01)
int result = calculator.calculate(newTestCalculation());
assertThat(result).isEqualTo(5);
}- Calculator() 생성자가 관련 없는 정보를 잔뜩 받고 있습니다.
- 정작 중요한 내용은 newTestCalculation()이라는 도우미 메서드에 숨겨져 있습니다.
- 이를 개선하기 위해서 도우미 메서드의 입력값의 의미가 명확하게 드러나라도록 수정하고, 계산기 생성과 관련이 없는 내용을 숨기면 보다 명확한 테스트 코드를 작성할 수 있습니다.
🟢 완전하고 간결한 코드
@Test
public void sholdPerformAddition(){
Calculator calculator = new Calculator();
int result = calculator.calculate(newCalculation(2, Optation.PLUS, 3));
assertThat(result).isEqualTo(5);
}4-2. 메서드가 아니라 행위를 테스트하기
많은 엔지니어가 본능적으로 테스트의 구조를 대상 코드의 구조와 일치시키려고 하는데, 이 방식은 처음에는 편리하지만 시간이 지날수록 문제를 발생시킬 확률이 높습니다.
- 예) 분기를 포함하는 여러 종류의 메시지를 출력하는 메소드
function display(user:User, transation:Transaction){
ui.showMessage(transaction.getItemName() + '을(를) 구입하셨습니다.');
if(user.getBalance() < LOW_BALANCE_THRESHOLD){
ui.showMessage('경고 : 잔고가 부족합니다');
}
}🔴 메서드의 두 메시지를 모두 검증하려는 모습.
//메서드를 테스트하는 경우
test("display메소드 전체를 한번에 테스트하는 경우", ()=>{
display(new User(LOW_BANLANCE_THRESHOLD + 2, new Transaction('물품',3));
expect(ui.getText()).contains("물품을(를) 구입하셨습니다.");
expect(ui.getText()).contains("잔고가 부족합니다.");
})이런상황에서 메서드가 더 복잡해지고 더 많은 기능을 구현한다면(분기가 많아지고, 메세지도 추가된다면..?), 이 단위 테스트 역시 계속 복잡해지고 커져서 다루기가 까다로집니다. 테스트를 메서드별로 작성하지 않고 행위별로 작성하면 됩니다.
여기서 행위란 특정 상태에서 특정한 일련의 입력을 받았을 떄 시스템이 보장하는
반응을 의미합니다.
🟢 행위별로 검증하는 모습
//행위를 테스트하는 경우
test("물품 이름을 보여준다.", ()=>{
display(new User(), new Transaction('물품'));
expect(ui.getText()).contains("물품을(를) 구입하셨습니다.");
}
test("은행 잔고가 부족하면, 거래를 거부한다.", ()=>{
display(new User(LOW_BANLANCE_THRESHOLD + 2, new Transaction('물품',3));
expect(ui.getText()).contains("잔고가 부족합니다.");
})이와 같이 행위 주도 테스트는 대체로 메소드 중심 테스트보다 다음과 같은 이유에서 명확한다.
- 자연어에 더 가깝게 읽히기 때문에 쉽게 이해할 수 있다.
- 테스트 각각이 더 좁은 범위를 검사하기 때문에 원인과 결과가 더 분명하게 드러난다.
- 각 테스트가 짧고 서술적이어서 이미 검사한 기능이 무엇인지 쉽게 확인할 수 있다.
명확한 행위주도 테스트를 작성할 수 있는 방법 TIP!
- 테스트의 구조는 행위가 부각되도록 구성
- given, when, then, 테스트 각각은 단 하나의 행위만 다뤄야 한다.
- 테스트 이름은 검사하는 행위에 어울리게 짓기
- 시스템이 수행하는 동작과 예상 결과를 모두 담아야 좋은 이름이다. (테스트 중첩도 가능)
- 테스트에 논리를 넣지 말자
- 연산자, 반복문, 조건문 등.. 논리가 조금이라도 들어가도 추론하기 어려워진다.
- 실패 메시지를 명확하게 작성하자
- 테스트 라이브러리가 제공하는 단정문을 사용하면 실패 메시지를 확인하기 쉬워진다. (ex. jest, junit 등..)
4-3. 테스트와 코드 공유 : DRY가 아니라 DAMP!
- 대부분의 소프트웨어에는 ‘반복하지 말라’ 라는 뜻의 DRY를 원칙으로 중시하는데, 테스트 코드에서는 코드 중복을 없애는 것보다는 테스트를 단순하고 명료하게만 만들어 주는 것을 중시합니다.
- 즉 DAMP(Descriptive And Meaningful Phase) ‘서술적이고 의미 있는 문구’ 를 추구합니다.
- 물론 DAMP가 DRY를 완전히 대체하지는 않습니다. 서로 보완해주는 개념이고 행위와 관련 없이 반복되는 세세한 단계들은 추상화해줄 수 있습니다.
- 공유값 : 도우미 메서드를 사용해서 원하는 값 생성
- 공유 셋업 : 셋업 메서드를 사용해서 검증할 행위와는 상관없는 초기화 로직이 반복되는 걸 없애줌.
5. 그럼 시스템관점에서 어떤 부분을 단위테스트하는 것이 좋을까?
지금까지, 단위 테스트를 왜(why) 작성해야하는지, 그리고 어떻게 단위테스트를 작성해야하는지(how) 에 대해 알아봤습니다.
그럼 시스템관점에서 어떤 부분(what)을 테스트하는 것이 가치 있는일인지, 그리고 어떤 코드를 테스트했을 때 가장 효과가 좋은지에 대해 알아봅시다.
5-1. 코드의 네가지 유형
모든 제품 코드는 다음과 같이 크게 2개의 차원으로 분류할 수 있습니다.
- 복잡도 또는 도메인 유의성
- 협력자 수
먼저,복잡도와 도메인 유의성에 대해 살펴봅시다.
- 코드 복잡도(code complexity) 코드 내 의사결정(=분기) 지점 수로 정의할 수 있으며, 이 숫자가 클수록 복잡도도 높아집니다.
- 도메인 유의성 (domain significance)는 코드가 프로젝트 문제 도메인에 대해 얼마나 의미있는지를 나타냅니다. (도메인 레이어 코드 : 높음, 유틸성 코드: 낮음)
두번째로 협력자의 수란, 해당 클래스 또는 메서드 가진 의존성 개수을 의미합니다. 협력자가 많을 수록 코드는 길어지고 테스트 비용이 높아집니다.
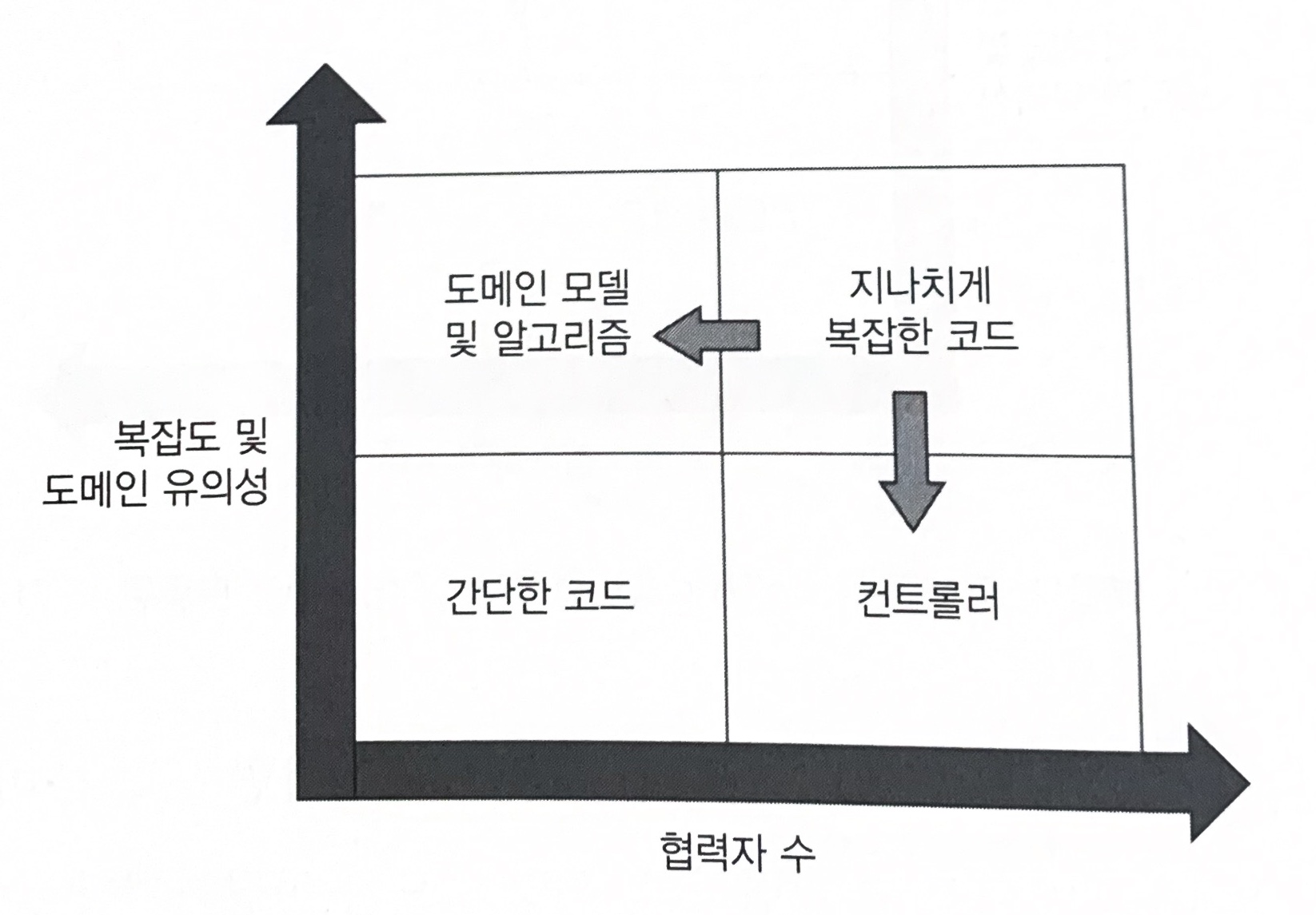
이를 도표로 나눠서 유형을 구분하면 다음과 같은 네가지 코드 유형을 볼 수 있습니다.
- A. 도메인 모델 및 알고리즘
- 도메인과 관련이 있거나, 복잡한 알고리즘을 포함한 코드
- B. 컨트롤러
- 복잡하거나 비즈니스에 중요한 작업을 하는 것이 아니라 도메인 클래스와 외부 애플리케이션 같은 다른 구성 요소의 작업을 조정
- C. 간단한 코드
- 협력자도 없고. 복잡도나 도메인 유의성도 없는 경우
- D. 지나치게 복잡한 코드
- 두가지 지표(복잡도, 도메인 유의성 / 협력자 수) 가 모두 높은 코드
이 때 좌측 상단 사분면(도메인 모델 및 알고리즘)을 단위 테스트하면 노력 대비 가장 이롭습니다. 협력자가 없어 유지보수성은 높지만, 코드가 복잡하고 중요한 로직을 수행하기 때문에 회귀 방지 가 뛰어나기 때문입니다.
회귀 방지
SW 버그를 방지할 수 있어야 한다는 의미
반면 간단한 코드는 테스트할 필요가 없다고 합니다.. (책에서는 거의 가치가 0에 가깝다고 표현할정도록)
컨트롤러의 경우 포괄적인 통합 테스트의 일부로서 간단히 테스트해야 한다고 합니다.
가장 문제가 되는 코드는 복잡한 코드인데, 단위 테스트가 어렵겠지만 테스트 커버리지 없이 내버려두는 것은 위험합니다. 이때 어떻게 이 딜레마를 우회할 수 있는지를 책에서 소개하고 있어 그 방법을 간단하게 설명하고 세미나를 마무리해보려고 합니다.
💡 TIP . 코드가 더 중요해지거나, 복잡해질수록 협력자는 적어야한다. **목표: 지나치게 복잡한 코드를 알고리즘과 컨트롤러로 나눠서 리팩토링 하기.**5-2. 가치 있는 단위 테스트를 위해 복잡한 코드 리팩토링 해보기
예시 시스템) 사용자 이메일 변경 시스템
- 사용자 이메일 변경 : 회사 도메인인 경우 직원으로 표시하고, 아닌 경우 고객으로 표시함.
- 직원수 추적 : 사용자 유형이 직원으로 표시되면 직원수에 반영되어야 함.
- 알림: 이메일이 변경되면 시스템이 메시지 버스로 메시지를 보내 외부 시스템에 알려야함.
public class User{
// 구체적인 구현 생략
public changeEmail(userId: number, newEmail: string ):void{
// 1. 데이터베이스에서 사용자 정보 검색 (이메일, 유형)
const userData = DataBase.getUserById(userId);
const userEmail= userData[1];
const userType = userData[2];
if(userEmail === newEmail){
return;
}
// 2. 데이터베이스에서 조직의 도메인 이름과 직원 수 검색
const companyData = DataBase.getCompany();
const companyDomainName = companyData[0];
const numberOfEmployees = companyData[1];
const emailDomain = newEmail.split('@')[1];
const isEmailCorporate = emailDomain === companyDomainName;
const newType = isEmailCorporate ? UserType.Employee : UserType.Customer
//3. 필요한 경우 직원의 수 업데이트
if(userType !== newType){
const delta = newType === UserType.Employee ? 1: -1;
const newNumber= numberOfEmployees + delta;
DataBase.saveCompany(newNumber);
}
this.email = newEmail;
this.userType= newType;
//4. 데이터베이스에 사용자 저장
DataBase.saveUser(this);
//5. 메시지 버스에 알림 전송
MessageBus.sendEmailChangeMessage(userId, newEmail);
}
}
}
- 코드 복잡도
- 위의 코드의 내부 복잡도(분기)는 매우 복잡한 편은 아닙니다. 사용자를 직원으로 식별할지, 직원수를 어떻게 업데이트할지의 두가지 의사결정 지점만 포함되어 있기 때문입니다. 간단하지만 이러한 결정은 중요하고, 핵심 비즈니스 로직이므로 이 클래스는 복잡도와 도메인 유의성 측면에서 점수가 높습니다.
- 협력자 수
- 이 클래스에는 네가지 의존성이 있습니다.
- 그중 useId, newEmail 은
명시적 의존성이고, - Database, MessageBus는
암시적 의존성입니다.
- 그중 useId, newEmail 은
위 두가지 측면에서 도메인 유의성이 높고, 외부 협력자 수가 높으므로 User는 지나치게 복잡한 코드로 분류됩니다.
1단계: 암시적 의존성을 명시적으로 만들기
- 데이터베이스와 메시지 버스에 대한 인터페이스를 두고, 이 인터페이스를 User에 주입한 후 테스트에서 목으로 처리할 수 있습니다.
- 하지만 이것만으로 충분하지 않습니다. 해당 의존성은 여전히 존재하고, 클래스를 테스트하기 위해서는 복잡한 목 체계가 필요하고 테스트 유지비가 증가합니다.
- 결국 도메인 모델은 직접적으로든, 간접적으로든 프로세스 외부 협력자에게 의존하지 않는 것이 깔끔합니다.
2단계: 의존성 제거 (함수형 아키텍처 도입)
- 프로세스 외부든, 내부든 외부 의존성과 통신할 필요가 없도록 설계를 합니다. 리팩토링 이후 User 클래스의 형태를 아래와 같습니다.
public changeEmail(newEmail: string, companyDomainName: string, numberOfEmployees: number):number|undefined{
if(this.email === newEmail){
return;
}
const emailDomain = newEmail.split('@')[1];
const isEmailCorporate = emailDomain === companyDomainName;
const newType = isEmailCorporate ? UserType.Employee : UserType.Customer
//3. 필요한 경우 직원의 수 업데이트
if(this.userType !== newType){
const delta = newType === UserType.Employee ? 1: -1;
const newNumber= numberOfEmployees + delta;
}
this.email = newEmail;
this.userType= newType;
return numberOfEmployees;
}- 이제 더이상 User는 협력자를 처리할 필요가 없기 때문에, 도메인 모델 사분면으로 수직축에 가깝게 이동합니다.
3단계: 애플리케이션 서비스 계층 도입 (험블래퍼 (aka 컨트롤러) 사용)
- 정현
- 데이터베이스, 메시지버스 의존성
- 내부 코드 사용중.
class UserController{
private readonly database: InstanceType<typeof DataBase> = DataBase;
private readonly messageBus: InstanceType<typeof MessageBus>= MessageBus;
public changeEmail(userId:number, newEmail:string){
const userData = this.database.getUserById(userId);
const user = UserFactory.create(userData);
const companyData = this.database.getCompany();
const company = CompanyFactory.create(companyData);
user.changeEmail(newEmail, company.domainName, company.numberOfEmployees);
// 변경전
this.database.saveUser(user);
this.database.saveCompany(company);
// 변경후
this.database.save(user,company);
this.messageBus.sendEmailChangeMessage(userId, newEmail)
}
}- UserController가 컨트롤러 사분면에 있으려면 협력자에 대한 의존성만 지니고 있어야 합니다. ORM 을 사용해 데이터베이스에서 가져온 값들을 도메인 모델에 매핑하면, 이 외의 비즈니스 로직 처리에 대한 책임을 도메인 클래스에 옮기기 수월해집니다.
- 만약에 ORM을 사용하지 않으면 데이터베이스를 데이터로 도메인 클래스를 인스턴스화 하는 팩토리 클래스를 작성하면 됩니다. (위에서 사용한 방법)
- 사용자의 이메일을 바꾸는 로직은 User 도메인 클래스에게, 회사의 직원수를 변경하는 로직은 Company 라는 새 도메인 클래스에게 위임합니다.
- 이처럼 험블 객체 패턴은 복잡한 코드에서 비즈니스 로직을 별도의 클래스로 추출해 복잡한 코드를 테스트할 수 있는데 도움이 됩니다.
🚫 주의 : 위 예제는 단위 테스트의 관점에서 리팩토링한 것이기 때문에 성능에 대한 고려는 하지 않았습니다. 위와 같이 모든 외부 데이터에 대한 읽기/쓰기를 비즈니스 끝으로 밀어냈을 경우, 불필요한 읽기/쓰기가 발생할 확률이 있다고 책에서도 말하고 있습니다. (trade-off 항상 고려해야됨) 성능을 고려해서 도메인 클래스의 로직을 컨트롤러쪽으로 가져올 수 도 있습니다.
요약
WHY?. 단위테스트를 작성하는이유
- 테스트의 가장 중요한 목적은 버그 예방, 그 다음으로 중요한 것이 생산성 개선
- 범위가 넓은 테스트들과 비교해서 단위테스트는 생산성을 끌어올리는 훌륭한 수단이 될 수 있다.
HOW?. 좋은 단위테스트란 무엇이고, 어떻게 작성할 수 있는지
- 변하지 않는 테스트를 만들기 위해 노력해야 한다. (테스트의 유지보수성)
- 공개 API를 통해 테스트 해야한다.
- 상호작용이 아닌 상태를 테스트해야 한다.
- 명확한 테스트를 만들어야한다.
- 행위가 부각되게끔 테스트를 구성해야한다.
- 이름은 검사하는 행위가 잘 드러나게 지어야한다.
- 로직이 들어가면 안된다.
- 테스트들이 코드를 공유할 떄는 DRY 보다는 DAMP를 우선시하는 것이 좋다.
WHAT?. 시스템에서 어떤 부분을 단위테스트하는 것이 효과적인지
- 제품 코드는 복잡도 또는 도메인 유의성과, 협력자 수에 따라 네 가지 유형의 코드로 분류할 수 있다.
- 코드가 중요하거나 복잡할 수록 협력자가 적어야 한다.
- 이때, 협력자가 적고 복잡하면서 도메인 유의성이 높은 코드를 테스트했을 때 회귀 방지가 뛰어나기 때문에 효과가 좋다.
- 협력자 수가 높은 코드를 리팩토링하기 위해 험블 객체 패턴(위에 서 본 컨트롤러)을 적용할 수 있다.
참고
