과제로 나온 '주인과 개', '배우와 영화'를 리뷰해 보겠다.
가상환경,프로젝트,git repo 생성과 DB 설정등의 초기 설정을 끝내고, 주인과 개는 feature/owner 브랜치에서, 배우와 영화는 feature/movie 브랜치에서 진행하기 위한 branch 설정도 마쳤다.
주인과 강아지
owner/models.py
### My code
from django.db import models
class Owner(models.Model):
name = models.CharField(max_length=45)
email = models.CharField(max_length=300)
age = models.IntegerField()
class Meta:
db_table = 'owners'
class Dog(models.Model):
owner = models.ForeignKey('Owner',on_delete=models.CASCADE)
name = models.CharField(max_length=45)
age = models.IntegerField()
class Meta:
db_table = 'dogs'### Wrap-up code
/...
email = models.CharField(max_length=300,unique=True)
# email은 중복되면 안되므로 unique=True 작성
age = models.PositiveIntegerField()
# 나이는 음수가 되면 안되므로 PositiveIntegerField 사용
/...이외에도 나는 과제 단위로 app을 만들었는데, wrap-up에서는 view 단위로 app을 나누어서 주인과 강아지의 models.py urls.py views.py을 각각 작성하고 필요할때마다 import 해서 사용하는 차이점이 눈에 띄었다.
owner/views.py
views.py에서는 다음과 같은 내용을 배웠다.
- 1) import시 빌트 인 모듈 / 외부 패키지 모듈 / 사용자 정의 모듈 convention 지키기
- 2) 메서드 정의 시 목적 / input / output 주석으로 작성
- 3) response시 owner_id나 customer_id같은 요청자 id가 출력되게 작성
- 4) one to many 관계에서 POST 메서드 작성 시 foreign key 참조는 id(pk)로
- 5) one to many 관계에서 GET 메서드 작성 시 역참조의 3가지 방법
(related_name사용,get또는filter메서드와_set사용,
dog.owner.name처럼 테이블 중첩 사용) - 6) GET 메서드 실행 시 결과값이 중첩 딕셔너리 구조일 때, 리스트 컴프리헨션 중첩해서 작성하기
4~6번에 대해 자세하게 알아보겠다. 먼저 4번의 코드를 비교해보자.
owner = Owner.objects.get(name=data["owner"]) # My code
owner_id = data['owner_id'] # Wrap-up codeone to many 관계에서 many에 해당하는 테이블은 owner 테이블에 대한 정보를 owner_id로 가지고 있기 때문에, owner 테이블을 get으로 조회하지 않아도 post기능을 작성하는데 문제가 없는 것을 확인할 수 있었다.
다음으로 5번 역참조와 6번 리스트 컴프리헨션 중첩에 대해 살펴보자.
# OwnerView My code
def get(self, request):
owners = Owner.objects.all()
result = []
for owner in owners:
dogs_list = [
{'dog_name':dog.name} for dog in Dog.objects.filter(owner_id=owner.id)]
]
result.append(
{
'name' : owner.name,
'email' : owner.email,
'age' : owner.age,
'dogs' : dogs_list
}
)
return JsonResponse({"dogs" : result}, status=200)
# OwnerView Wrap-up code
/...
for owner in owners:
results.append({
"id" : owner.id,
"name" : owner.name,
"age" : owner.age,
"dogs" : [{"id" : dog.id, "name" :dog.name} for dog in owner.dog_set.all()]
}
)주인이 소유한 강아지의 리스트인 dog_list를 작성하는데 my code에서는 단순 이중 for문을 사용하였지만, wrap-up에서는 리스트 컴프리헨션이 사용되었다.
또한 my code에서는 one 테이블에서 many 테이블을 역참조할 때 get이나 filter 메소드를 사용하는 방법을 사용했는데, wrap-up에서는 _set 방법을 사용하였다.
wrap-up code에서는 다시 리스트 컴프리헨션을 중첩해서 사용하여 다시 한 번 코드를 간결하게 바꿀 수 있다.
result = [{"id": owner.id, "name":owner.name,"age":owner.age,"dogs": [{"id" : dog.id, "name" : dog.name} for dog in owner.dog_set.all()]} for owner in owners]
return JsonResponse({"MESSAGE" : result}, status=200)코드가 간결해지긴 했지만 너무 길어 읽기 힘들어서 중간에 줄바꿈을 해 보았다.
result = [{"id": owner.id, "name":owner.name,"age":owner.age,"dogs":
[{"id" : dog.id, "name" : dog.name} for dog in owner.dog_set.all()]} for owner in owners]
return JsonResponse({"MESSAGE" : result}, status=200)훨씬 나아졌다.
이처럼 적절한 리스트 컴프리헨션의 사용은 연산 성능의 향상 뿐만 아니라 코드 또한 간결해지니, 적절한 가독성이 받쳐준다면 가능하면 사용하는 것이 좋겠다.
# DogView My Code
def get(self,request):
dogs = Dog.objects.all()
result = []
# My code == case 3(many.one table)
for dog in dogs:
result.append({
'dog_name' : dog.name,
'dog_age' : dog.age,
'owner' : {
"id" : dog.owner.name,
"name" : dog.owner.id
}
})
# DogView Wrap-up code case1(related_name)
for dog in dogs:
owner = Owner.objects.get(dogs__id = dog.id)
result.append({
"id" : dog.id,
"name" : dog.name,
"age" : dog.age,
"owner" : {
"id" : owner.id,
"name" : owner.name
}
})
# DogView Wrap-up code case2(NOT USE related_name)
for dog in dogs:
owner = Owner.objects.get(dog__name = dog.id)
result.append({
"id" : dog.id,
"name" : dog.name,
"age" : dog.age,
"owner" : {
"id" : owner.id,
"name" : owner.name
}
}) wrap-up에서 배운 역참조의 3가지 방식을 차례대로 살펴 보겠다.
먼저 case 1처럼 related_name을 사용하는 경우에는 먼저 model에 related_name을 설정해줘야 한다.
# models.py
class Dog(models.Model):
owner = models.ForeignKey('Owner',on_delete=models.CASCADE,related_name="dogs")related_name으로 지정한 dogs를 사용하면, owner 테이블이 아닌 dog 테이블의 데이터를 read할 때, owner.dogs.all()으로 열람이 가능해진다.
다음으로는 case 2처럼 related_name을 사용하지 않아도 dog_set처럼 테이블명_set으로 역참조가 가능하다. 이 때는 owner.dog_set.all()로 read가 가능하다.
related_name을 사용하지 않아도 역참조는 가능하지만, 사용하지 않았을 경우에 충돌이 발생하는 경우가 있고, 테이블명이 복잡하거나 길 때 related_name을 사용하면 짧게 바꿀 수 있어서 웬만하면 사용하는 것이 권장된다.
*dogs__id에서 함수의 모델 쿼리셋에서 __가 의미하는 내용은 무엇일까?
첫번째는 Field Lookup(필드 조회)다. SQL 쿼리문에서 사용하는 WHERE절을 django에서도 사용하기 위해 사용된다. 예를들어
Owner.objects.filter(name__contains="김")위 코드는 Owner 모델의 name field에서 "김"을 포함하는 데이터를 filter하겠다는 코드다.
contains 이외에도 gt , startwith과 같은 여러가지 Field Lookup 메서드가 존재한다.
두번째는 외래키 모델의 속성 참조다.
dog__id가 여기에 해당한다고 볼 수 있다.
views.py를 작성할 때 owner = Owner.objects.get(dog__id = dog.id)와 같이 작성해 owner 테이블에서 dog 테이블을 참조하게 했다.
여기서 __를 통해서 dog 테이블의 pk인 id를 owner에서 참조할 수 있게 된 것이다.
[ __(double underscore) 참고 사이트]
장고의 모델 쿼리셋에서 더블 언더스코어(__)(언더바 두개)는 무슨 의미 인가요?
원본 사이트
마지막으로 내가 작성한 코드와 일치하는 case3을 살펴보자.
위의 두 case하고는 다르게 owner = Owner.objects.get(dogs__id = dog.id)의 코드를 작성하지 않았다.
대신 dog.owner.name과 같이 테이블의 이름을 중첩해서 사용했는데, many에 해당하는 dog모델은 owner_id라는 외래 키 때문에 one에 해당하는 owner를 속성으로 가지고 있기 때문에, get 메서드를 사용할 필요 없이 바로 접근이 가능하기 때문이다.
배우와 영화
git checkout -b 명령어를 통해 feature/movie branch를 생성하고 이동하여 추가 과제를 진행했다. 초기 세팅부터 GET,POST 매서드 작성은 첫번째 과제와 비슷하게 진행되었으나, 배우와 영화는 one to many 관계가 아닌 many to many 관계라는 차이가 있었다.
movie/models.py
# models.py My code
from django.db import models
class Actor(models.Model):
first_name = models.CharField(max_length=45)
last_name = models.CharField(max_length=300)
date_of_birth = models.DateField()
class Meta:
db_table = 'actors'
class Movie(models.Model):
title = models.CharField(max_length=45)
release_date = models.DateField()
running_time = models.IntegerField()
class Meta:
db_table = 'movies'
class Actor_Movie(models.Model):
actor = models.ForeignKey("Actor",on_delete=models.CASCADE)
movie = models.ForeignKey("Movie",on_delete=models.CASCADE)
class Meta:
db_table = 'actors_movies'
# models.py Wrap-up code
/..
class ActorMovie(models.Model):
/..
class Actor(models.Model):
/..
movies = models.ManyToManyField('movies.Movie', through = ActorMovie)
/..- Class 이름에 언더바를 사용하지 않았다. coding convention 적용.
- django가 지원하는 다대다관계 매서드인
ManyToManyField()사용
처음에는 ManyToManyField()를 사용하면 참조와 코드 작성 면에서 훨씬 편리하지만, 중간 테이블이 django에서 내부적으로 생성되어서 ManyToManyField() 사용을 지양하고 중간 테이블만 생성해야 한다고 이해했다.
하지만 이것은 완전히 잘못된 생각이었다. django에서 중간 테이블을 내부적으로 생성하는 것은 ManyToManyField()의 through 옵션의 유무에서 결정된다. 즉 through 옵션을 사용하지 않으면 django가 중간 테이블을 내부적으로 생성하고, 사용하면 사용자가 생성한 중간 테이블을 지정해줄 수 있는 것이다.
movie/views.py
import json
from django.views import View
from django.http import JsonResponse
from .models import Actor, Movie, Actor_Movie
class ActorView(View):
def get(self, request):
actors = Actor.objects.all()
result = []
for actor in actors:
# views.py My code (case 1, 중간테이블 사용)
actors_movies = Actor_Movie.objects.filter(actor_id = actor.id)
movie_list = []
for actor_movie in actors_movies:
movie_list.append(
{
'title' : actor_movie.movie.title
}
)
result.append(
{
'Name' : actor_movie.actor.first_name + actor_movie.actor.last_name,
'Birth' : actor_movie.actor.date_of_birth,
'Filmography' : movie_list
}
)
return JsonResponse({"Actors" : result}, status=200)
/..
# views.py Wrap-up code (case2, Movie 테이블 이용)
/..
movies = Movie.objects.filter(actor_movie__actor_id = actor.id)
movie_list = []
for movie in movies:
movie_list.append({
"id" : movie.id,
"title" : movie.title
})
results.append({
"first_name" : actor.first_name,
"last_name" : actor.last_name,
"movies" : movie_list
/..
# views. py Wrap_up code (case3, recommend)
/..
results.append({
"first_name" : actor.first_name,
"last_name" : actor.last_name,
"movies" : [{"title" : movie.title} for movie in actor.movies.all()]
})
/..
django가 지원하는 ManyToManyField()를 사용하지 않고 오로지 중간테이블만 이용한 나는 첫번째 GET 메서드를 구현하는데 애를 먹었다. 오로지 중간테이블만을 이용하여 배우의 데이터와 그 배우가 출연한 영화의 데이터를 딕셔너리로 저장하는 반복문은 코드가 길이 뿐만 아니라 들여쓰기 또한 복잡했다.
마찬가지로 wrap-up에서 나온 case2의 형태도 중간 테이블이 아니라 Movie 테이블을 사용했을 뿐 코드의 큰 차이는 없었다.
하지만 ManyToManyField()를 사용한 case3의 경우에는, 참조 관계가 편해져 코드 작성이 쉬워졌고, 중간 테이블을 사용하기 때문에 테이블명이 길어져 코드가 길게 늘어진 것이 사라진 것을 눈으로 확인할 수 있었다.through를 통해 커스텀으로 중간 테이블까지 지정하면 중간 테이블 관리의 문제까지 사라진다.
이처럼 프레임워크에서 미리 만들어 놓은 편리한 메서드를 코딩할 때 적극적으로 사용해야겠다는 생각이 들었다.
'주인과 개' 부분에서 중첩 리스트 컴프리헨션을 사용하여 코드를 간결하게 바꿨던 것 처럼 똑같이 적용해 보겠다.
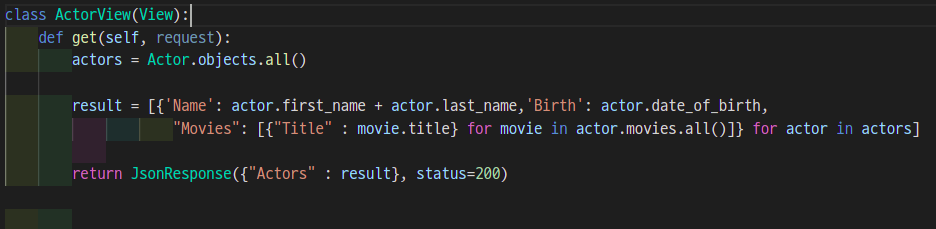
마지막으로 중간 테이블을 사용할때는 ActorView와 구조가 동일했던 MovieView를 ManyToManyField()를 사용하는 리스트 컴프리헨션 형태로 바꿔보겠다.
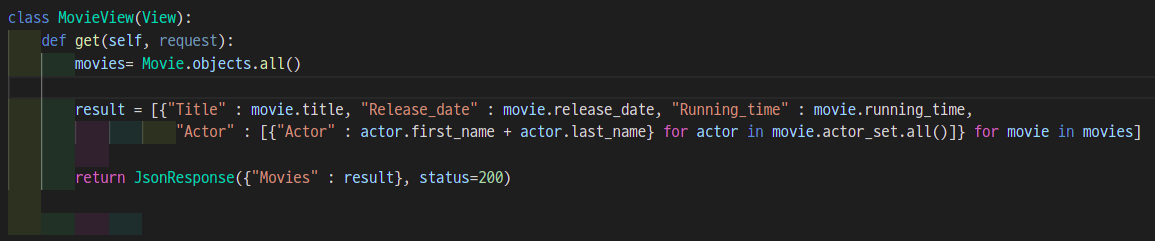
model에서 related_name을 사용하지 않았으므로 actor_set.all()을 통해 역참조를 한 것을 알 수 있다.
