
Hegde, Deepti, Jeya Maria Jose Valanarasu, and Vishal Patel. "Clip goes 3d: Leveraging prompt tuning for language grounded 3d recognition."
Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
0. Abstract
- CLIP과 같은 Vision-Language models들이 zero-shot capability들로 인해 널리 적용되고 있다.
- 그러나 CLIP은 3D geometry features를 뽑는데에 suitable하지 않다. ← 이미지와 텍스트로 natural language supervision으로만 학습되었기 때문
- 이러한 한계를 다루고 CG3D(CLIP goes 3D)라는 새로운 프레임워크를 제안(3D encoder가 zero-shot capability를 다룰 수 있게 학습됨)
- CG3D는 pointclouds, corresponding rendered 2D images, texts using natural language supervision 이렇게 3가지로 학습된다.
- CLIP을 학습하기 위한 natural image와 CG3D에서의 rendered 2D image는 distribution shift가 있다.
→ 해결하려 했으나 Catastrophic forgetting(새로운 데이터에 일반화되지 않고 이전 학습 데이터에만 치중되는 것)과 성능 감소 발생
→ CLIP을 3D pre-training dataset으로 shift하기 위해 prompt tuning을 employ
1. Introduction
- 2D vision의 많은 task에서 가장 efficient하고 정확한 결과를 가져오는 것들은 large-scale data로 pre-train된 foundation models를 적용함으로써 얻어진다.
← 이러한 vision 분야의 경향은 몇 년 전 NLP 분야의 경향과 유사하다. - 이미지와 텍스트같은 multimodal data로 pre-train된 foundation models는 zero-shot capabilities를 exhibit하는 데에도 유용하다.
- Vision과 NLP에서의 foundation model의 장점들은 아직 3D 영역으로 오지 않았음
- 저자들은 “CLIP과 같은 foundation model같은 functionalities를 가진 3D network를 어떻게 만들지?”라고 생각
- 3D 영역에서 각 포인트의 특성과 의미를 이해하는 것은 downstream task를 다루기 위해 중요하다.
- zero-shot capanilities를 가진 powerful 3D network는 존재하는 3D backbones의 성능을 향상시키는 것 뿐만 아니라 open 3D scene과 3D retrieval tasks 이해를 가능하게 한다.
- CLIP은 인터넷에 존재하는 다양한 image-caption pairs를 large pre-training dataset으로 쓸 수 있었지만 3D data의 scarcity(부족)때문에 이를 3D encoder를 pre-train하는데 쓸 수는 없었다.
PointCLIP
- CLIP의 zero-shot capabiliites를 3D zero-shot 문제에 utilize하려고 했던 기존 연구
- 3D point cloud depth map을 CLIP의 2D visual encoder에 적용
→ 3D zero-shot problem을 빠르고 간단하게 해결할 solution이었지만, 3D fine-tuning이나 3D open scene 이해 작업에 사용될 수 었기 떄문에 foundational model의 특성을 갖추지 못함
→ 3D 이해에 대한 downstream tasks에서 3D geometric features를 추출할 수 있는 능력을 갖추지 않고 있음 - CG3D는 CLIP의 지식을 활용하면서 natural language supervision을 이용해서 3D encoder를 학습
- pre-training dataset(3D point clouds, images, corresponding text descriptions)
- point clouds from ShapeNet
ShapeNet
- consists of textured CAD models
- 각 object에 대해 random views를 render하여 image pair로 사용

- 동일한 object의 3D point clound와 image는 고유한 속성을 가지고 있지만 공통적인 sementic attributes(의미 속성)을 공유한다.
← single image reconstruction, transfer of pre-trained weights from an image-based network to a 3D point cloud classification network를 통해 확인된다. - CG3D는 동일한 object에 대해 3D feature와 2D feature, 3D feature와 text feature간에 similarity를 보장하기 위해 목표한다.
→ contrastive approach(대조적인 접근방법)은 3D encoder가 CLIP과 유사한 zero-shot capabilities를 습득할 수 있도록 함
- 3D encoder를 contrastive loss로 훈련하고 CLIP의 visual encoder로부터 3D feature를 2D feature과 비교하는 과정은 CLIP의 semantic features를 3D encoder에 요약하는 수단
- CLIP의 visual encoder를 3D object의 data distribution과 related image와 일치시키는 것이 더 효율적일 것 같지만, CLIP의 visual 및 text encoder와 3D encoder를 함께 훈련할 때 성능이 크게 떨어짐
→ CLIP이 새로운 distribution으로 shift하도록 훈련됨에 따라 이전 feature를 catastrophically forget하기 때문 - 그러나 visual encoder를 완전리 frozen 상태로 유지하는 것은 이상적이지 않다. CLIP은 주로 natural images에 대해 훈련되는데, 이는 3D objects의 graphically rendered view와 distribution이 다르기 때문
- 이러한 domain gap을 다루기 위해, prompt tuning techniques를 도입 → visual encoder로 전달하기 전에 input space의 distribution을 변경하여 distribution을 sift
- CLIP의 visual encoder의 transformer backbone에 visual prompts를 추가하여 input space의 parameter를 작은 양만 추가하면서도 CLIP visual encoder의 weights를 frozen(고정된) 상태로 유지.
- 이러한 parameters는 CLIP에 맞게 input distribution을 조정하여 3D pre-training이 효과적이도록 함
- CG3D의 효과를 증명하기 위한 실험 수행
- MobileNet이나 ScanObjectNN과 같은 합성 및 실제 object dataset에서 zero-shot capabilities를 보임
- text-based quieries를 활용하여 open scene 이해에서 3D model의 능력을 보여줌
- image 혹은 text queries를 활용하여 cross-modal 3D data retrieval(검색)을 수행하는 능력을 보임
- CG3D를 사용하여 3D encoder를 pre-train한 weights는 다른 3D tasks에 대한 model의 finetuning에 효과적인 initial weights
Summary
- We propose CG3D, a contrastive pre-training framework for training 3D networks using natural language supervision while also leveraging the knowledge of CLIP.
- We utilize prompt tuning to shift the input space of a pre-trained visual encoder from rendered images of CAD objects to natural images, allowing for more effective use of CLIP for 3D shapes.
- We conduct extensive experiments to demonstrate the versatile capabilities of CG3D. It exhibits strong zero-shot, 3D retrieval and 3D scene understanding capabilities with language. CG3D also acts as strong starting weights for multiple 3D recognition tasks.
2. Background
CLIP
- Class label 대신 이미지에 달린 caption을 supervision으로 사용 - contrastive learning으로 학습
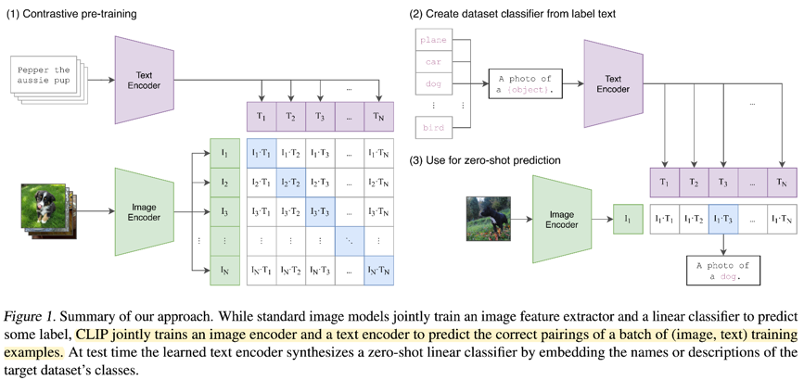
- 이미지,텍스트 인코더(ViT, ResNet)를 함께 훈련시키면서 각 훈련 샘플들을 같은 차원에 맵핑 -> 행렬곱을 수행하고 코사인 유사도를 계산
- 대각선의 행렬은 각 이미지,텍스트의 맞는 쌍이므로 Positive Pair가 되고 나머지는 Negative Pair가 된다.
- N(배치개수)개의 Positive Pair의 코사인 유사도를 최대화 하며 나머지 N2−NNegative Pair의 코사인 유사도는 최소화시키며 훈련을 진행
- (2),(3) 한 개의 이미지(초록)가 입력되고 클래스를 직접 여러개(보라)를 지정할 수 있게 됨(a photo of a “”)
- 이미지를 가장 잘 설명하는 text feature와의 cosine similarity가 가장 크게 나옴
Visual Prompt Tuning
- VPT는 이미지와 텍스트 간의 상호작용을 통해 이미지를 분류하거나 생성하는 모델을 fine-tune하는 기술
- Input: 이미지와 텍스트 prompt / Output: 분류작업에서는 class label
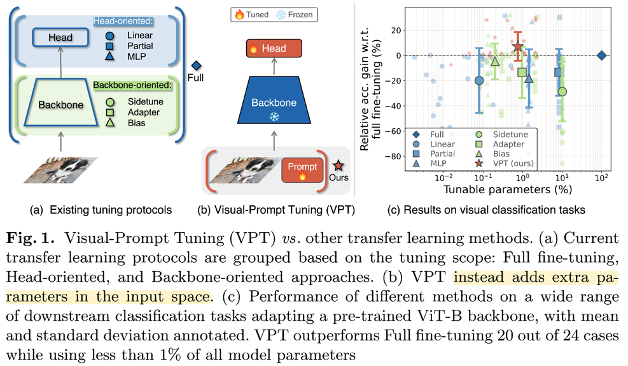
- 기본적인 fine-tuning 방법은 2가지
- end-to-end: 전체 모델을 낮은 learning rate로 학습하여 성능이 좋지만 재학습해야할 모델의 파라미터가 많다
- Linear probing: pretrained encoder는 고정시키고 task를 위한 head layer만 추가하여 학습
- VPT는 backbone(pretrained model의 encoder)은 고정하고, head와 learnable한 visual prompt 도입
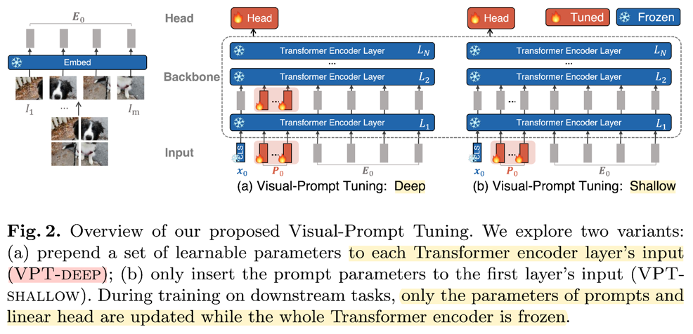
- 학습과정
- Pre-training: 먼저, 대규모 Transformer 모델과 대규모 데이터셋으로 pre-training한다. 이를 통해 모델은 이미지의 시각적 특징을 학습하고, 이를 바탕으로 다양한 downstream recognition task에서 좋은 성능을 보일 수 있게 된다.
- Prompt 생성: 각 task에 대해 task-specific한 prompt를 생성한다. 이 prompt는 input 이미지와 함께 입력되어 fine-tuning 과정에서 모델이 해당 task에 맞게 조정될 수 있도록 도와준다.
- Fine-tuning: 생성된 prompt를 input으로 추가한 후, pre-trained 모델의 encoder를 고정시키고 나머지 부분을 fine-tuning한다.
- Prompt는 image token과 같은 사이즈를 가진 vector, 제일 처음의 prompt는 gaussian distribution을 따르는 random한 vector로 initialize -> 이후에는 downstream task에 맞게 loss function에 의해 update
- VPT의 2가지 방법
- VPT-Deep: Transformer encoder를 거칠 때마다 learnable한 visual prompt를 두고 학습
- VPT-Shallow: 제일 처음 input 시에만 learnable한 visual prompt를 두고 학습
- VPT-Deep을 선택한 이유
- CLIP의 visual encoder를 튜닝하여 input space를 real image로 이동시키기 위해서
- VPT-Deep은 learnable prompt를 도입해서 CLIP의 visual encoder의 input space를 조정하고, 이를 통해 3D pre-train이 잘 이루어지도록 함
PointTransformer
- Transformer 구조를 기반으로 한 모델
- 각 포인트 간의 상호작용을 모델링하기 위해 self-attention 메커니즘을 사용
- 기존의 transformer처럼 attention을 계산할 때 global한 모든 점을 이용하는 것이 아니라, 각 기준점에 인접한 k개의 점들만 이용
- 모든 점을 이용한 경우에, 중심점과 거리가 먼 점들에 대한 attention score가 오히려 noise로 작용해서 성능이 저하됨
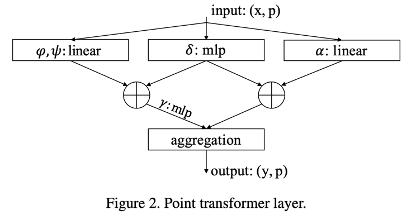
- Input: Point Encoding(각 포인트의 특성)
- Point Transformer Layer
- x: point의 좌표(공간적 위치)
- p: point에 대한 feature
- φ, ψ, α, γ: pointwise feature transformations
- δ: position encoding
- Self-Attention은 입력 시퀀스 내의 각 원소 간의 상호작용을 계산하는 메커니즘
- 이를 통해 모델은 시퀀스 내의 각 원소의 중요성을 학습하고 이를 기반으로 출력을 생성
- point transformer layer를 정의하고, 이를 통해 점들 간의 관계를 고려한 feature vector를 multi-scale로 추출
- Linear transformation: 입력 결과에 대해 선형으로, 즉 각 특성에 대한 가중치를 곱하고 모두 합산하여 변환된 값이 계산
PointMLP
- 기존 point cloud model들은 CNN, graph, attention 등 복잡한 local geometric extractor를 이용 → computational overhead가 너무 큼
- Residual feed-forward MLP만을 이용하여 point clolud analysis
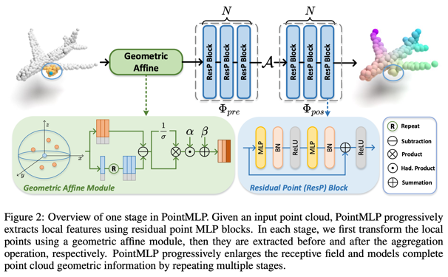
- Input: 각 point
- Output: Softmax로 나온 classification을 위한 확률 값
- MLP(다층 퍼셉트론)은 인공 신경망(ANN)의 한 유형으로, 여러 개의 은닉층을 가진 피드포워드(feedforward) 신경망
- 각 층은 여러 개의 뉴런(또는 노드)으로 구성되어 있고, 인접한 층 간에는 완전 연결(fully connected)이 이루어집니다.
- MLP를 사용하여 permutation invariant
- 저자들은 깊이에 성능이 크게 좌우되지 않음을 강조한다. ablation study 를 진행했을 때 40층이 최적이라고도 기록했다.
- geometric affine module: 각 local 영역에는 다양한 geometric structure가 있는데, 하나의 shared MLP만을 이용해서 이들의 특성을 추출하는 것은 쉽지 않다. 이를 해결하기 위해 도입
- local neighbor point들을 normalization
PointCLIP
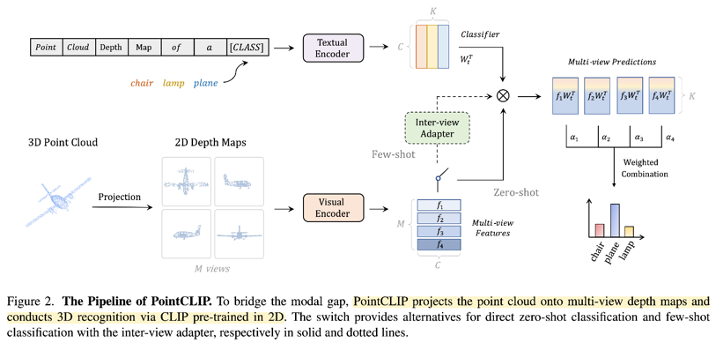
- 3D point cloud를 다양한 각도에서 project한 2D maps로 바꾼 뒤 이를 clip의 visual encoder에 입력하여 3D와 2D간의 modal gap을 감소
- K category names를 CLASS라는 token으로 대체
- 3D multi-view feature에 대해 inter-view adapter를 적용해서 최종적으로 class를 predict
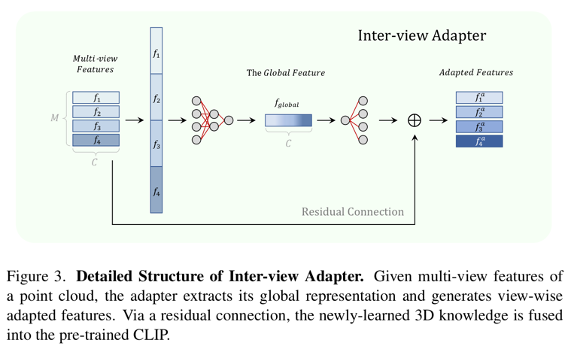
- 하나의 3D point cloud에 대해 생성된 multi-view들을 concatenate하여 compact global feature를 얻음
- multi-view feature가 요약된 하나의 표현으로 융합됨
- 이것을 original에 더하여 view-wise adapted feature를 만듦
3. Method
3.1. CG3D Framework
3D Encoder
- Input: 3D point cloud
- object의 essential shape characteristics를 capture하기 위해
→ point cloud를 분석하고 object를 represent하는 feature vector를 generate하는 3D encoder 사용 - 추가된 projection layer는 output feature dimension이 consistent하게 유지되도록 함
2D Visual Encoder
- Input: 3D point cloud의 corresponding rendered image
- large data로 학습된 CLIP의 visual encoder를 사용
- vision encoder를 활용함으로써 point cloud dataset에 존재하는 category의 효과적이고 함축적인 representation을 얻음 → 이후에 3D feature와 align하기 위해 사용됨
- CLIP은 visual encoder용으로 ResNet과 ViT weights를 둘다 제공
Text Encoder
- Input: 3D point cloud의 corresponding text caption
- CLIP의 text encoder는 text description을 이미지와 대응시키기 위해 train되었으며, 이와 동일한 구성으로 즉시 사용
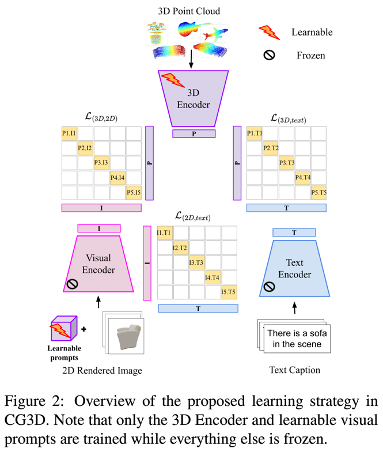
3.2. Training the 3D Encoder
- 주요 목표: 3D point cloud를 해당 category 수준의 image 및 text와 align하는 것
- 이러한 alignment는 각 modality의 data가 modality별 encoder와 projection head로부터 project(투영)된 common embedding space에서 발생
- Training strategy: contrastive learning
→ 동일한 쌍의 cross-modal feature가 embedding space에서 서로 가까이 있도록 유도하면서 다른 쌍에 속한 sample을 멀리 유지하는 것 - encoded feature를 common dimension으로 project하여 common embedding에서의 각 샘플의 feature representation을 얻음
- a set of N pointcloud-image-text triplets → encoder(3D, 2D, text)
- i: 1 ~ number of samples N
- = encoder for each modality
- = projection operation for each modality
- Total loss used to train the 3D encoder:
- : feature
- : batch
Contrastive learning - NCE
- contrastive losses(InfoNCE objective)
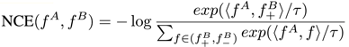
- 앞의 과정에서 contrastive learning으로 쓰이는 것이 바로 이 NCE인데, Information Noise-Contrastive Estimation의 약자, 대조 학습(contrastive learning)에서 널리 사용되는 손실 함수
- 비지도 학습 방식에서 데이터의 유용한 표현을 학습하기 위해 설계
- 분모에서는 모든 음의 예시들에 대한 유사도 점수의 합이 사용되어, feature가 양의 예시에 비해 음의 예시들과 얼마나 덜 유사한지를 측정 -> NCE Loss를 minimize하면 분자는 minimize, 분모는 maximize(loss를 최소화하려면 log안이 최대화 되어야함)
3.3. Prompt Tuning for Visual Encoder
- CLIP visual encoder는 vast amounts of internet data로 학습되고 highly resilient한 반면, CG3D의 pre-training에서는 rendered images of the 3D point cloud만 쓰인다.
→ CLIP visual encoder가 rendered images를 다룰 수 있도록 fine-tuning하는 것은 3D encoder의 training process를 improve할 수 있다. - CLIP loss function을 사용하여 image와 text feature간의 similarity를 계산하는 방식으로 visual encoder를 훈련하는 방법을 시도했으나, 성능이 저하됨
- CLIP encoder를 훈련하는 것이 catastrophic forgetting을 야기함 → 새로운 data distribution에 적응하려는 동안 encoder가 이전의 지식을 잃게 됨
- 보통 이런 문제는 fine-tuning을 위해 new data의 양을 늘리면 해결되는데, 이 task에서는 충분한 3D dataset을 구할 수 없으므로 visual encoder를 frozen 상태로 둔 채 new pre-training data로 모델을 효과적으로 pre-train하는 새로운 방식을 생각함. → visual prompting(기본 모델을 세밀하게 조정하기 위해 입력 공간에 소수의 학습 가능한 parameter를 추가하는 방법)
- CG3D의 pre-training에서 visual prompting을 채택하여 원래 CLIP 모델의 visual encoder와 더 잘 일치하도록 input space를 modify
→ visual encoder가 더 높은 품질의 feature를 produce하게 되어 3D encoder의 train을 강화할 수 있다 - Deep Prompting을 사용하여 ViT의 각 레이어에서 학습 가능한 prompt로서의 learnable tokens를 introduce(도입)
Visual prompt tuning
- transformer layer 에 대해, 해당 레이어의 learnable tokens의 집합을 로 정의
- : 개별 tokens
- : total number of learnable tokens
- 에서 deep prompt visual encoder:
- : output
- : input to the current layer
- prompt tokens 는 CG3D framework의 3D encoder와 함께 학습된다.
- prompt를 훈련하기 위해 image와 text 특성간의 contrastive loss인 original CLIP loss를 사용
- : feature
- : batch
3.4. Using CG3D
Datasets
- Pre-training dataset: ShapeNet - Textured CAD models with large number of classes and samples
-
Object categories: 55
-
Total samples: 52,460
→ 각 object mesh에서 고정 크기의 point cloud를 샘플링하고 unit sphere에 적합하도록 normalize
-
2D: Blender에서 색이 칠해진 CAD 모델 뷰를 렌더링하여 각 포인트 클라우드에 대한 이미지 쌍을 얻음
-
3D: Input point cloud는 object scaling. rotation, random drop, and perturbations로 증강
-
Text: 각 point cloud-image pair의 text caption은 “A photo of a {OBJECT}”와 같은 standard template 형태로 구성
-
- Fine-tuning datasets: ModelNet40, ScanObjectNN - popular 3D dataset → zero-shot classification and downstream fine-tuning 수행 → ZS classification을 위해 total dataset(MobileNet40), 10-class subset(MobileNet10)으로 evaluate
- ModelNet40: 12,311 synthetic meshes of common objects from 40 categories (down-sampled and normalized to fit a unit sphere)
- ScanObjectNN: a real-world point cloud dataset of objects from laser-scanned indoor scenes
- ShapeNet

- ModelNet40

- ScanObjectNN

Implementation Details
- CG3D를 학습하기 위해
- SLIP의 pre-trained visual and text weight를 leverage → 성능과 유연성이 좋음
- Image Backbone: ViT-Base
- SLIP
- SLIP은 입력 이미지에 대한 언어 감독 및 이미지 자기 감독을 결합하는 프레임워크입니다. SLIP은 다음과 같은 과정을 거쳐 output을 도출합니다.
- 입력 이미지의 언어 감독 및 이미지 자기 감독 분기를 통해 각 입력 이미지의 별도 뷰를 구성합니다.
- 이후, 이러한 뷰들은 공유 이미지 인코더를 통해 전달됩니다.
- 훈련 과정에서 이미지 인코더는 시맨틱하게 의미 있는 방식으로 시각적 입력을 표현하는 방법을 학습합니다.
- 이렇게 학습된 표현의 품질은 downstream 작업에서의 유틸리티를 평가하여 측정됩니다.
- 이러한 과정을 통해 SLIP은 입력 이미지에 대한 언어 감독 및 이미지 자기 감독을 결합하여 시맨틱하게 의미 있는 시각적 표현을 학습하고, 이를 통해 다양한 작업에 활용할 수 있는 output을 도출합니다.
- Input: Image,text
- Output: Image representation, text representation
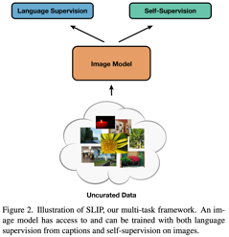
- SLIP은 입력 이미지에 대한 언어 감독 및 이미지 자기 감독을 결합하는 프레임워크입니다. SLIP은 다음과 같은 과정을 거쳐 output을 도출합니다.
- ViT
- ViT는 이미지를 패치로 나눈 후 각 패치를 벡터로 변환하고, 이러한 패치 벡터를 입력으로 사용하여 Transformer의 구조를 적용
- Transformer 아키텍처에서는 입력 시퀀스의 각 요소에 대한 상대적인 위치 정보를 제공하기 위해 position embedding이 사용
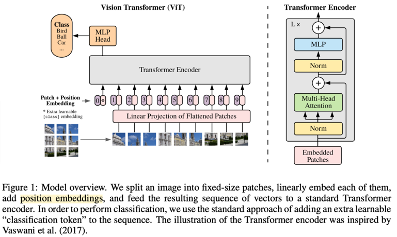
- Input: Image
- Output: Image classification
- Pre-training: Visual prompt parameter와 3D encoder parameter가 번갈아가며 다른 optimizer에서 조정됨 → 각각 disjoint loss function으로 supervised되며 서로 다른 learning rate가 필요하기 때문 - 100 epochs with a batch size of 32
- ViT의 encoder layer input에 5개의 learnable prompt tokens 추가하고 randomly initialize
- Optimizer: SGD optimizer
- Scheduler: cosine annealing scheduler
- Learning rate: 2 × 10^(-3)
- Weight decay: 10^(-4)
- Minimum learning rate: 10^(-6)
- PointTransformer
- Optimizer: AdamW optimizer
- Scheduler: cosine annealing scheduler
- Learning rate: 2 × 10^(-4)
- Weight decay: 0.05
- Minimum learning rate: 10^(-6)
- PointMLP
- Same optimizer-scheduler scheme
- Learning rate: 10^(-4)
- Weight decay: 0.01
- Fine-tuning: PyTorch로 prototype을 만들었으며, 모든 실험은 8GPU NVIDIA A100 cluster에서 수행 → 300 epochs with a batch size of 64(PointTransformer), 32(PointMLP)
- PointTransformer
- Optimizer: AdamW optimizer
- Scheduler: cosine annealing scheduler
- Learning rate: 2 × 10^(-4)
- Weight decay: 0.05
- Minimum learning rate: 10^(-6)
- PointMLP
- Optimizer: SGD optimizer
- Scheduler: cosine annealing scheduler
- Learning rate:0.02
- Weight decay: 〖2 × 10〗^(-4)
- Minimum learning rate: 〖5 × 10〗^(-3)
3.4.1. Zero-shot 3D Recognition
- Zero-shot 3D Recognition: object에 대해 previous training 없이 3D object를 classify하는 방법
- CG3D는 input point cloud에서 shape feature를 extract하는 3D encoder를 통해 zero-shot 3D recognition을 직접적으로 가능하게 한다.
- Framework: CG3D의 3D 및 text encoder
- Input:
- : individual text prompts - “This is a OBJECT” 형태로 나온다
- OBJECT: name of a test class
- : total number of text prompts
- 모델의 추론 절차는 CLIP과 유사: 각 prompt와 test sample간의 similarity score를 계산하고, 가장 높은 점수를 얻는 프롬프트를 최종 예측으로 선택:
- : feature vectors of the point cloud inputs
- : feature vectors of the text inputs - actually a collection of feature vectors collected from forwarding text queries to the text encoder
- : class prediction
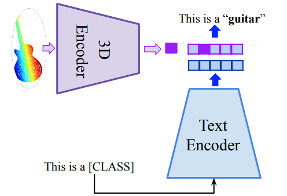
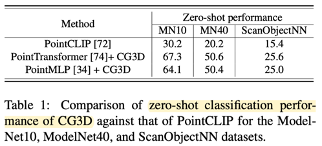
- Experiment: ModelNet10, ModelNet40, ScanObjectNN의 test distribution에서 zero-shot 수행
- Backbone: PointTransformer, PointMLP pre-trained with CG3D
- Compare against: PointCLIP
- Result:
- ModelNet10 - 37.1%
- ModelNet40 - 30.4%
- ScanObjectNN - 10.2%
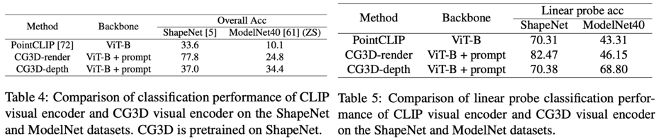
- Additional experiment: ShapeNet, ModelNet dataset
- CG3D-render: ShapeNet object의 rendered image / CG3D-depth: depth projections are used to inputs to the visual encoder
- Result: 44.2% point(ShapeNet image), 24.3% point(ModelNet depth image)
3.4.2. Scene Querying with Language
- 3D scene understanding: 3D 장면의 이해에서도 language queries를 이용하여 scene을 querying하여 장면의 key details를 이해하는 것
- answering queries such as “What is the location of the sofa?” of “Where can the chair be found?”
- CG3D는 language queries를 사용하여 zero-shot scene understanding을 가능하게 함
- 실내 장면에 대해 모델을 훈련하지 않거나 직접 지도를 사용하지 않고도 CG3D framework를 사용하여 text query로 장면을 이해할 수 있다
- Input: scene
- k-means clustering을 통해 장면을 meaningful segments로 나눔
- CG3D framework에서 모든 cluster를 3D encoder로 전달하고 a set of 3D features 을 얻음
- : total number of clusters obtained from the scene
- : 3D feature vector from 3D encoder of CG3D for the cluster
- text queries를 text encoder에 전달하여 를 얻음
- 이러한 3D feature을 input query를 text encoder에 forwarding하여 얻은 text feature와 match:
- : predicted class
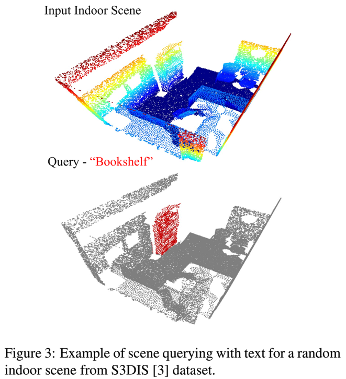
- 본 논문에서는 not real인 ShapeNet에서 pre-train 진행했음
- S3DIS, ScanNet dataset의 mesh indoor scene을 query하기 위해 ScanObjectNN dataset에 대한 additional pre-train 진행
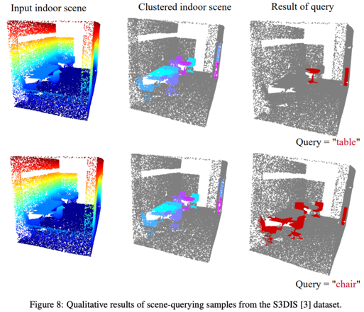
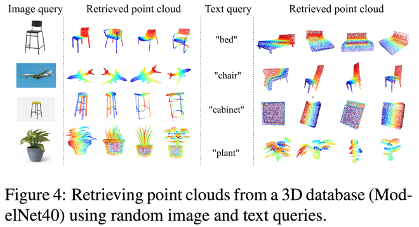
3.4.3. Retrieval
- 3D cloud point retrieval: 주어진 query와 유사한 3D point cloud data를 search & retrieve
- query는 different modality like an image or text
- CG3D를 사용하여 retrieve data하기 위해, pre-trained encoder가 query와 3D point cloud의 feature representations를 obtain → feed the image or text query into the corresponding encoder to obtain its feature vector & same to the 3D point cloud(3D encoder)
- 3D encoder로 전달되는 point cloud는 관련 shape을 retrieving하기 위한 complete database를 구성
- query feature과 3D feature간의 similarity score를 얻고, 가장 높은 similarity score를 가진 point cloud를 출력으로 선택
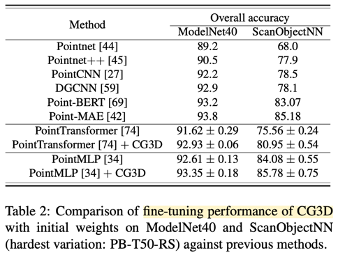
3.4.4. Fine-tuning for Supervised Tasks
- Pre-training techniques: 3D computer vision tasks에서 fine-tuning의 성능을 강화하는 효과적인 방법
- large datasets of unlabeled images에 대해 pre-training하면 generic and transferable features를 학습할 수 있어 robust to variations in data하게 만들고 new tasks와 datasets에 잘 generalize하게 한다.
- CG3D는 model-agnostic하므로 any 3D backbone can be pre-trained using CG3D
- 그 결과로 얻은 weight는 downstream task의 starting point로 사용 가능
- Dataset: synthetic(ModelNet40) and real(ScanObjectNN) dataset
- Compare against: Point-BERT and Point-MAE
- Experiment: PointTransformer, PointMLP의 backbone에 대한 fine-tuning 수행
- Result: random weight 보다 CG3D starting weight를 사용할 때 성능 향상
- PointTransformer - ScanObjectNN 5.31% / ModelNet40 1.31%
- PointMLP - ScanObjectNN 1.7% / ModelNet40 0.74%

4. Discussion
- Ablation Study: CG3D의 각 요소가 zero-shot 성능에 미치는 역할 분석을 위해 ablation study 수행
- 서로 다른 loss configurations로 pre-trained PointTransformer 3D encoder의 zero-shot accuracy를 report
- 3D encoder를 개별적으로 L((3D,2D)), L((3D,text))로 학습 → L((3D,text))로 train하는 것이 L((3D,2D))보다 slight improved
- Loss를 모두 사용하여 CG3D를 pre-train하면 individual configurations보다 더 나은 성능을 가질 수 있었다.
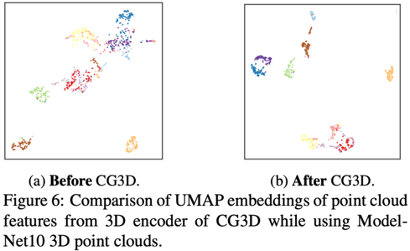
- Visualization of 3D Feature Representations: feature quality를 분석하기 위해 ModelNet10을 사용하여 UMAP embedding 시각화
- CG3D pre-train 전후에 PointTransformer에 의해 trained 3D feature
- Pre-train 후에 unseen category에 대해 class discrimination feature 생성
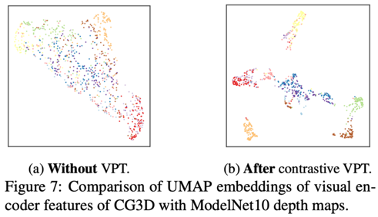
- Effect of Prompt Tuning: CG3D의 trained prompt와 visual encoder에 의해 trained image feature 시각화
- 모든 sample에 대해 texture가 있는 CAD model이 없으므로, 2D plane에 projected depth maps of the points 확인
- Pre-train 후에 improved class separability를 가진 feature를 produce
- Limitations:
- pre-train dataset이 작고, simulated point cloud objects 뿐이다.
- 더욱 강력한 foundation model을 위해 image와 text caption을 가진 3D point cloud 데이터에 대해 가공해야한다.
참고문헌
- Radford, Alec, et al. "Learning transferable visual models from natural language supervision." International conference on machine learning. PMLR, 2021.
- Jia, Menglin, et al. "Visual prompt tuning." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
- Zhao, Hengshuang, et al. "Point transformer." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
- Ma, Xu, et al. "Rethinking network design and local geometry in point cloud: A simple residual MLP framework." arXiv preprint arXiv:2202.07123 (2022).
- Zhang, Renrui, et al. "Pointclip: Point cloud understanding by clip." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022.
- Chang, Angel X., et al. "Shapenet: An information-rich 3d model repository." arXiv preprint arXiv:1512.03012 (2015).
- Wu, Zhirong, et al. "3d shapenets: A deep representation for volumetric shapes.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
- Uy, Mikaela Angelina, et al. "Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
- Mu, Norman, et al. "Slip: Self-supervision meets language-image pre-training." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
- Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." arXiv preprint arXiv:2010.11929 (2020).

딥러닝을 공부하는 학생입니다.