
머신러닝이란?
- 결정 = 비교 + 선택
- A와 B의 대소관계를 모르거나, 비교해야 할 특징이 너무 많을 때
결정을 내리는 일은 어려워진다. - 이 일을 기계에 부여해서 스스로 결정하도록 할 수 없을까?
머신러닝이란 우리의 두뇌가 가진 중요한 기능인 판단능력을 확장해서 우리의 두뇌가 더욱 빠르고 정확하게 결정할 수 있게 돕는 도구이다.
꿈
- 우리에게 제일 절실한 것을 무엇일까? 바로 '해결하고자 하는 문제'
- 모든 사람들이 빠짐없이 경험하고 있는 가장 오래된 문제 -> 습관
- 습관을 고치는 데에 머신러닝을 이용해 보자.
- 습관을 고치려면 전략이 필요하다.
- 습관은 의지를 이긴다.
- 의지는 환경을 이긴다.
- 환경은 습관을 이긴다.
의지만으로 습관을 바꾸는 것은 무모한 일일 것이다.
따라서 의지로 환경을 조성하여, 환경이 습관을 손봐주는 우회 전략을
구사해보면 좋을 것이다.
내가 손톱을 깨무는 습관이 있다면 이것을 알려주는 환경을 조성한다면, 습관을 개선하기 쉬울 것이다.
이런 환경을 만드는 데에 머신러닝을 이용할 수는 없을까?
'오랜 습관을 바꾸고 싶다'는 꿈이 생긴 것이다.
궁리하는 습관
내가 손톱을 물어뜯는 습관이 있다고 생각해보자.
손톱을 깨물고 있을 때 잔소리를 해줄 기계를 만들면 어떨까?
집에 안 쓰는 스마트폰이 있는데 이걸 활용하면 좋겠는데?
나를 계속 촬영하면서 내가 손톱을 깨물면 '그 손 당장 내려놔!'라고
말해줬으면 좋겠어.
이런걸 만드려면 일단 카메라로 촬영된 영상을 보고 손톱을 깨물고 있는지, 아닌지를 알려줄 수 있는 기능이 필요한데
여기에 머신러닝을 이용해보자!
손톱을 깨물고 있는 사진과 그렇지 않은 사진을 구분해서 컴퓨터에게 학습시키고 훈련시키면 보여준적이 없는 사진을 보고도 손톱을 깨무는 사진인지, 그렇지 않은 사진인지 '결정'해 줄수 있을거야.
이런식으로 머신러닝이라는 '도구'를 이용할 궁리를 해보자.
Teachable Machine
수학과 코딩 없이도 머신러닝을 이용할 수 있게 해주는 서비스들이 생겨나고 있다.
https://teachablemachine.withgoogle.com/
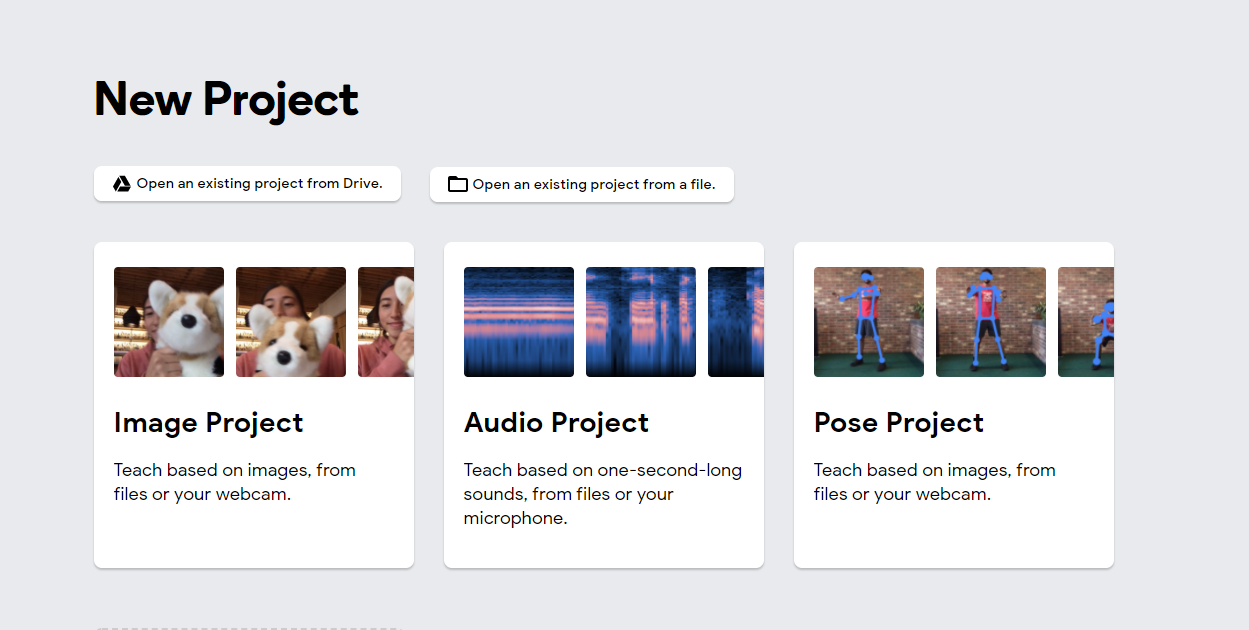
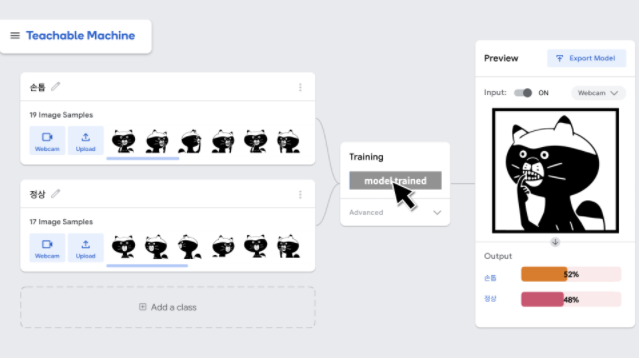
- Image Project를 이용하여 손톱을 깨물고 있는 사진과 그렇지 않은 사진 구별 가능
- 손톱을 깨물고 있는지 아닌지를 구분할 수 있는 판단력을 기계로 구현
- 머신러닝에서는 이 판단력을 '모델'이라고 한다.
모델
- 모델은 머신러닝을 이해하는 중요한 열쇠
- 머신러닝에서의 모델은 '판단력'이라는 의미이다.
- 모델을 만드는 '과정'을 '학습(learning)'이라고 부른다.
머신러닝머신
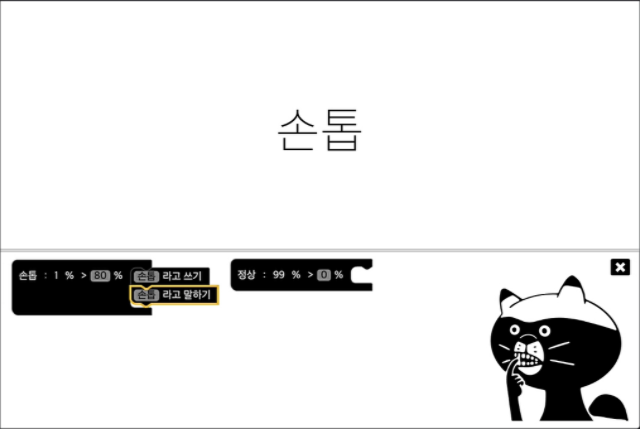
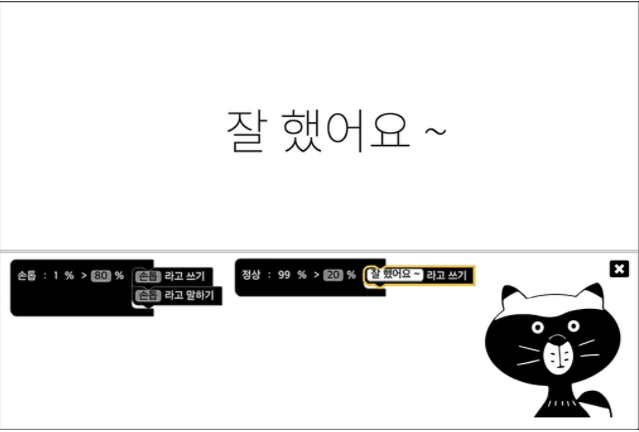
- 머신러닝머신은 Teachable Machine에서 생성한 모델을 이용하여 애플리케이션을 만들어주는 서비스
- Teachable Machine에서 다운로드한 모델 파일을 업로드하면 손톱을 깨물고 있는지 여부를 판단할 수 있다.
직업의 시작
- 머신러닝으로 무엇인가를 하려면 데이터가 필요하다.
- 복잡한 현실에서 관심사만 뽑아 단순한 데이터로 만들어야 한다.
- 데이터 산업은 '데이터 과학'과 '데이터 공학'으로 나뉘어 진다.
- 데이터 과학은 데이터를 만들고, 만들어진 데이터를 이용하는 일을 한다.
- 데이터 공학은 데이터를 다루는 도구를 만들고, 도구를 관리하는 일을 한다.
표
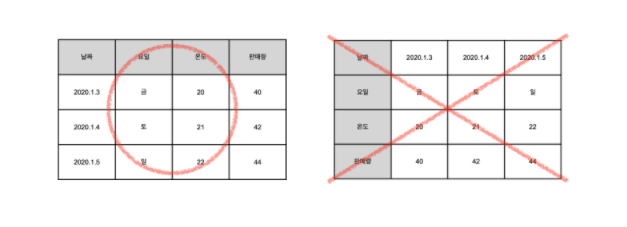
- 데이터 산업에서는 표를 왼쪽과 같이 입력한다.
- 표는 데이터들의 모임으로, 데이터 셋(data set)이라고도 부른다.
- 행(row)
- 개체(instance)
- 관측치(observed value)
- 기록(record)
- 사례(example)
- 경우(case)
- 열(column)
- 특성(feature)
- 속성(attribute)
- 변수(variable)
독립변수와 종속변수
- 독립변수 = 원인이 되는 열
결과에 영향을 받지 않는다. - 종속변수 = 결과가 되는 열
결과는 원인에 종속되어 있다.
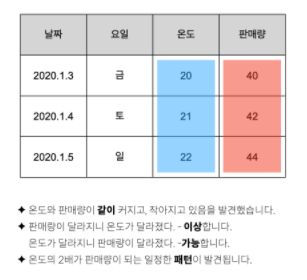
상관관계
- 한쪽의 값이 바뀌었을 때, 다른 쪽의 값도 바뀐다면, 두 개의 특성은 '서로 관련이 있다'고 추측할 수 있다.
- 이런 관계를 '상관관계'라고 한다.
인과관계
- 위 사진을 보면, '온도'는 '원인'이고, '판매량'은 '결과'라고 할 수 있다.
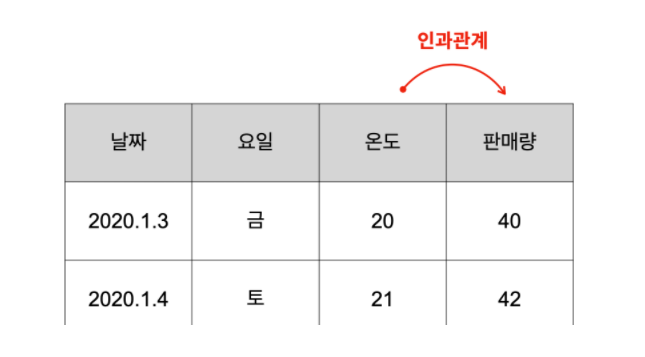
- 위 사진과 같이 각 열이 원인과 결과의 관계일 때 인과관계가 있다고 한다.
정리해보면,
- 독립변수는 원인이다.
- 종속변수는 결과이다.
- 독립변수와 종속변수의 관계를 인과관계라고 한다.
- 인과관계는 상관관계에 포함된다.
머신러닝의 분류
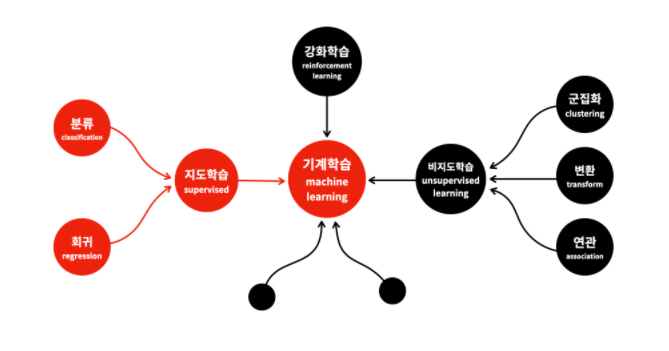
- 지도학습, 비지도학습, 강화학습으로 나뉜다.
지도학습
- 문제집으로 학생을 가르치듯이 데이터로 컴퓨터를 학습시켜서 모델을 만드는 방식
- 지도학습을 하려면 과거의 데이터가 있어야 한다. 그리고 그 데이터를 독립변수(원인)과 종속변수(결과)로 분리해야 한다.
- 독립변수와 종속변수의 관계를 컴퓨터에게 학습시키면 컴퓨터는 그 관게를 설명할 수 있는 공식인 '모델'을 만들어낸다.
- 모델을 만들면 아직 결과를 모르는 원인을 모델에 입력했을 때 결과를 계산하여 알려준다.
- 지도학습은 크게 '회귀'와 '분류'로 나뉜다.
- 회귀 : 예측하고 싶은 종속변수(결과)가 숫자일 때 이용
ex) 시험점수, 판매량 - 분류 : 예측하고 싶은 종속변수(결과)가 이름 혹은 문자일 때 이용
ex) 합격 여부(합격/불합격)

- 회귀 : 예측하고 싶은 종속변수(결과)가 숫자일 때 이용
- 양적 데이터 : 산업에서는 숫자라는 표현 대신에 '양적'이라는 말을 사용한다. 즉, 얼마나 큰지, 얼마나 많은지, 어느 정도인지를 의미하는 데이터라는 뜻에서 '양적'데이터라고 한다.
- 종속변수가 아래와 같은 양적 데이터라면 '회귀'를 사용하면 된다.
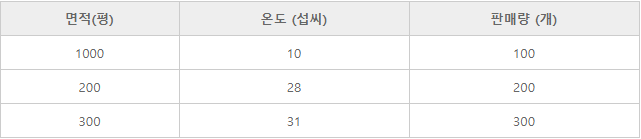
- 범주형 데이터 : 산업에서는 '이름'이라는 표현 대신에 '범주'라는 말을 사용한다.
- 종속변수가 아래와 같은 범주형 데이터라면 '분류'를 사용하면 된다.
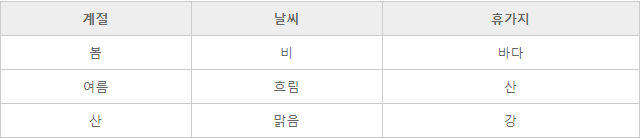
비지도학습
- 기계가 스스로 무언가에 대한 관찰을 통해 새로운 의미나 관계를 밝혀내는 것. 주로 데이터의 성격을 파악하거나 데이터를 잘 정리정돈 하는 것에 사용된다.
- 비지도학습은 '군집화'와 '연관규칙' 그리고 '변환'으로 분류된다.
- 군집화 : 군집화는 비슷한 것들을 찾아서 그룹을 만드는 것이다.
- 분류와 혼동할 수 있는데, '군집화'는 어떤 대상들을 구분해서 그룹을 만드는 것이라면, '분류'는 어떤 대상이 어떤 그룹에 속하는지를 판단하는 것이다.
- 연관규칙학습 : 연관규칙학습은 서로 연관된 특징을 찾아내는 것이다.
ex)쇼핑 추천, 음악 추천 등 추천관련 기능 - 관측치(행)를 그룹핑 해주는 것 군집화
- 특성(열)을 그룹핑 해주는 것 연관규칙
비지도 학습은 데이터를 정리 정돈하여 그 표에 담긴 '데이터의 성격'을 파악하는 것이 중요한 목적이다.
강화학습
- 기계 스스로 더 좋은 보상을 받기 위해 수련하도록 고안된 방법.
- 강화학습의 핵심은 일단 해보는 것이다.
- 지도학습이 배움을 통해서 실력을 키우는 것이라면, 강화학습은 일단 해보면서 경험을 통해서 실력을 키워가는 것이다.
- 어떤 행동의 결과가 자신에게 유리한 것이었다면 상을 받고, 불리한 것이었다면 벌을 받는 과정을 매우 많이 반복하면, 더 많은 보상을 받을 수 있는 더 좋은 답을 찾아낼 수 있다는 것이 강화학습의 기본 아이디어이다.
