
Spring 공부를 하다보니 싱글톤... 싱글톤... 수없이 많이 들었다. 대강은 뜻을 알고 있었지만 깊게 공부할 생각은 이제서야 하게 된 것 같다. 그래서 이제부터 공부한 디자인 패턴들에 대해 정리하여 블로그에 시리즈로 포스팅 하려 한다! 이름하야 '자바 디자인 패턴 정복해 보자!' 시리즈!
내가 작성한 Spring 프로젝트 코드를 보면서 이런 생각이 들었다.
- "이 코드, 대체 왜 이렇게 복잡하지? 더 깔끔하게 작성할 방법이 없나?"
- "코드 리뷰 때마다 객체 생성 방식으로 논쟁이 일어나는데..."
- "프레임워크 코드는 어떻게 이렇게 우아하게 설계됐을까?"
결국 이런 고민들의 해답은 대부분 디자인 패턴에 있었다. 특히 오늘 다룰 생성 패턴은 객체 생성 메커니즘에 관한 패턴으로, 자바 백엔드 개발자로서 실전에서 가장 많이 활용하게 될 패턴들이다.
목차
- 디자인 패턴 소개
- 싱글톤 패턴(Singleton Pattern)
- 팩토리 메소드 패턴(Factory Method Pattern)
- 빌더 패턴(Builder Pattern)
- 결론 및 비교
디자인 패턴 소개
디자인 패턴이란?
처음 '디자인 패턴'이라는 말을 들었을 땐 거창한 느낌이 들었다. 근데 GoF(Gang of Four)의 책을 보면서 그냥 선배 개발자들이 오랜 시간 동안 "이런 상황에서는 이렇게 코드를 짜는 게 좋더라"라고 정리해 놓은 일종의 best practice catarog 걸 깨달았다.
디자인 패턴은 소프트웨어 설계에서 자주 발생하는 문제들에 대한 검증된 해결책이다. 그런데 단순한 코드 템플릿이 아니라 특정 맥락에서 발생하는 문제와 이를 해결하기 위한 접근법을 담고 있는 것이 핵심이다.
핵심 요약
디자인 패턴은 특정 상황에서의 문제 해결 방식을 추상화한 것으로, 객체지향 설계 원칙(SOLID)을 적용한 실전적 예시라고 볼 수 있다.
디자인 패턴은 크게 3가지 카테고리로 나뉜다.
- 생성 패턴(Creational Patterns) - 객체 생성 메커니즘에 관한 패턴
- 객체 생성 로직을 캡슐화하여 시스템이 사용할 구체 클래스를 분리
- 객체가 어떻게 생성되고 구성되는지에 대한 유연성 제공
- 구조 패턴(Structural Patterns) - 클래스와 객체의 구성에 관한 패턴
- 객체들을 더 큰 구조로 조합하는 방법 제공
- 다양한 인터페이스 간의 호환성 문제 해결
- 행동 패턴(Behavioral Patterns) - 객체 간 상호작용과 책임 분배에 관한 패턴
- 객체 간 통신 방식 정의
- 알고리즘과 객체 간 책임 할당에 중점
오늘 다룰 생성 패턴은 객체를 생성하는 다양한 방법을 제공하는데, 이게 왜 중요한지 실제 개발 경험에서 느꼈다. 객체 생성 코드가 지저분하면 전체 시스템의 결합도가 높아지고 유지보수성이 급격히 저하된다. 심지어 기능 확장 시 전체 코드를 뜯어고쳐야 하는 상황까지 발생한다.
이번 내 포스트에서는 자바 개발에서 가장 자주 사용하게 될 세 가지 생성 패턴을 깊이 있게 다룰 것이다.
- 싱글톤 패턴(Singleton Pattern) - 클래스의 인스턴스가 하나만 존재하게 보장
- 팩토리 메소드 패턴(Factory Method Pattern) - 객체 생성을 서브클래스에 위임
- 빌더 패턴(Builder Pattern) - 복잡한 객체의 생성 과정 분리
내가 공부한 각 패턴의 이론적 배경부터 실제 구현 방법, 그리고 Spring Framework에서의 활용 방식까지 살펴볼 것이다.
싱글톤 패턴 (SingleTon Parttern)
싱글톤 패턴이란?
싱글톤 패턴은 내가 가장 먼저 깊이 공부한 디자인 패턴이다. 개념은 간단하다. 클래스의 인스턴스가 오직 하나만 생성되도록 보장하는 패턴이다. 여러 번 객체를 생성하려고 해도 항상 같은 인스턴스를 반환하는 것이다. (스프링에 등록되는 bean들이 여기에 해당한다.)
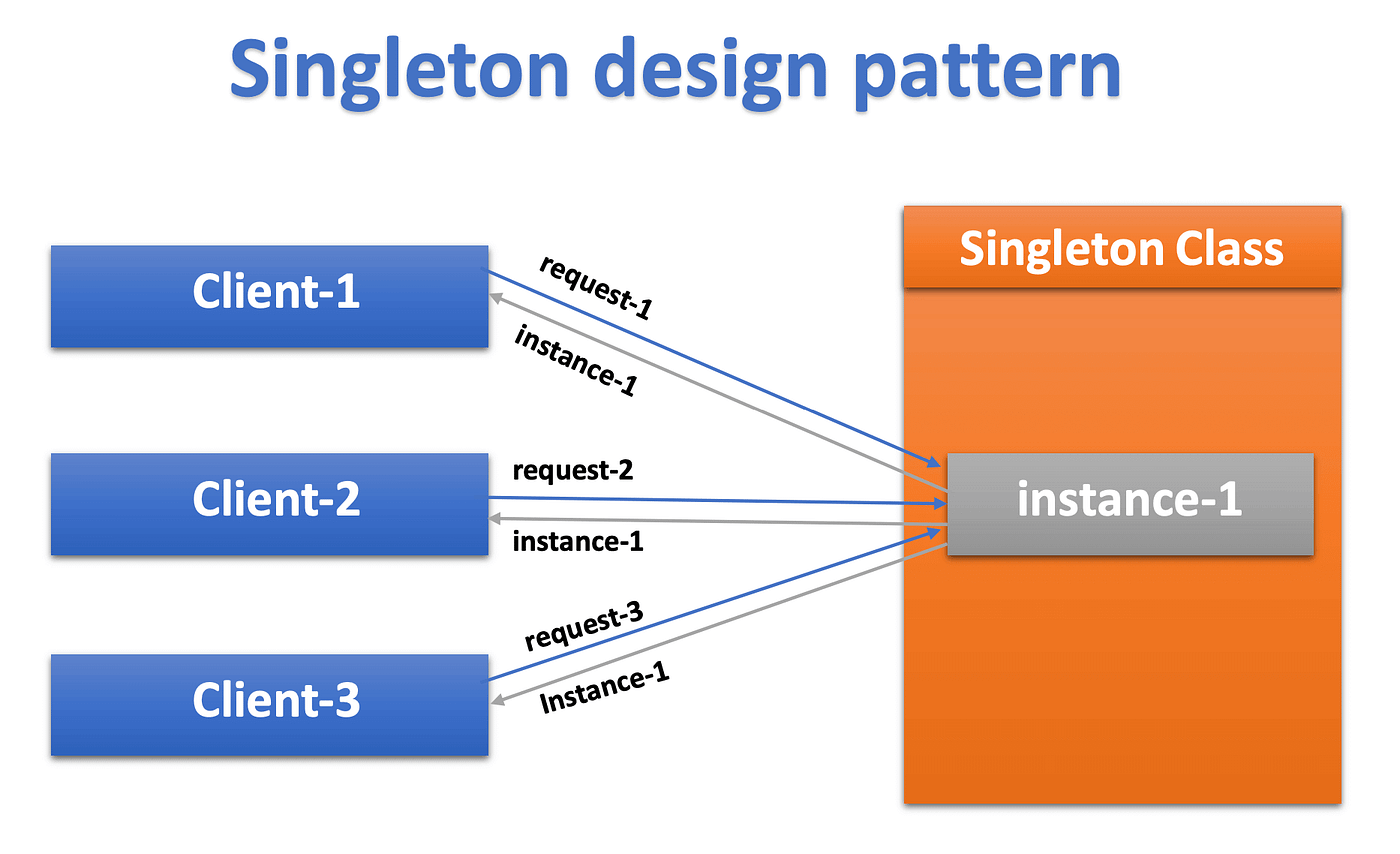 객체지향 원칙을 배울 때는 "객체를 필요할 때마다 생성하라"는 방식을 배웠는데, 싱글톤은 이와 반대로 "하나의 인스턴스만 사용하라"고 하니 처음에는 좀 혼란스러웠다. 그러나 실제로 전역 상태 관리나 리소스 공유가 필요한 상황에서는 이 패턴이 아주 유용하다는 것을 알게 됐다.
객체지향 원칙을 배울 때는 "객체를 필요할 때마다 생성하라"는 방식을 배웠는데, 싱글톤은 이와 반대로 "하나의 인스턴스만 사용하라"고 하니 처음에는 좀 혼란스러웠다. 그러나 실제로 전역 상태 관리나 리소스 공유가 필요한 상황에서는 이 패턴이 아주 유용하다는 것을 알게 됐다.
활용 사례
실무에서 싱글톤 패턴은 다음과 같은 경우에 활용된다고 한다!
-
데이터베이스 커넥션 풀 - DB 연결은 리소스 집약적인 작업으로, 커넥션 풀을 싱글톤으로 관리하면 리소스 사용을 최적화할 수 있다.
-
캐시(Cache) - 애플리케이션 전체에서 공유되는 캐시는 데이터 일관성을 위해 하나의 인스턴스로 관리하는 것이 효율적이다. 여러 캐시 인스턴스가 있다면 캐시 무효화와 갱신이 복잡해진다.
-
로깅(Logging) - 로그 파일 쓰기 작업이 충돌하지 않도록 하나의 로거 인스턴스를 사용한다.
-
스프링 빈(Bean) - 스프링 프레임워크의 기본 스코프는 싱글톤이다.
@Component,@Service,@Repository등으로 정의된 빈은 모두 싱글톤으로 관리된다.그래서 내가 가장 좋아하는 디자인 패턴 ㅎㅎ -
설정 정보 - 애플리케이션 설정은 로드 후 변경되지 않는 경우가 많아 싱글톤으로 관리하는 것이 적합하다.
실제 프로젝트에서는 외부 API 클라이언트나 서비스 인스턴스 관리에 싱글톤을 적용할 때가 많다. 예를 들어, 무신사와 같은 쇼핑 어플리케이션에 결제 게이트웨이 API 클라이언트를 매번 생성하면 연결 관리와 트랜잭션 추적이 어려워지므로 싱글톤으로 구현하는 것이 합리적일 것이다.
구현 방법
싱글톤을 구현하는 방법은 여러 가지가 있는데, 멀티스레딩 환경에서의 안전성과 성능이라는 두 가지 요소를 고려해야 한다. 실제 나도 구현해 가면서 공부했다. 기본적인 방법부터 고급 구현까지 살펴보자!
1. 기본 싱글톤 (Thread-unsafe)
public class BasicSingleton {
// private static 변수로 인스턴스 보관
private static BasicSingleton instance;
// private 생성자로 외부 생성 방지
private BasicSingleton() {
System.out.println("싱글톤 객체 생성");
// 초기화 코드
}
// public static 메소드로 인스턴스 접근 제공
public static BasicSingleton getInstance() {
if (instance == null) {
instance = new BasicSingleton();
}
return instance;
}
// 비즈니스 메소드
public void doSomething() {
System.out.println("비즈니스 로직 수행");
}
}이 코드의 문제점은 멀티스레드 환경에서 두 스레드가 동시에 if (instance == null) 조건을 검사하면 두 개의 인스턴스가 생성될 수 있다는 것이다. 이는 전형적인 Race Condition 문제다!
한번은 토이 프로젝트에서 이런 방식으로 구현했다가 간헐적으로 객체가 두 개 생성되는 이슈를 겪어 정말 고생한 기억이 있다 ㅠㅠ.. 해당 사건을 정말 쎄게 겪고서 동시성 문제의 중요성을 깨닫게 되었다.
2. 스레드 안전한 싱글톤 (Thread-safe with synchronized)
public class ThreadSafeSingleton {
private static ThreadSafeSingleton instance;
private ThreadSafeSingleton() {
// 초기화 코드
}
// synchronized 키워드 추가
public static synchronized ThreadSafeSingleton getInstance() {
if (instance == null) {
instance = new ThreadSafeSingleton();
}
return instance;
}
}synchronized 키워드는 한 번에 하나의 스레드만 메소드에 접근할 수 있게 하여 스레드 안전성을 보장한다. 그러나 이 방식의 명백한 단점은 성능 저하다. 인스턴스가 이미 생성된 후에도 매번 메소드 호출 시 동기화 오버헤드가 발생한다.
메소드 전체를 동기화하는 것은 마치 "화장실을 사용하기 위해 건물 전체를 잠그는 것"과 같다. 효과적이지만 비효율적인 방법이다.
3. 이중 검사 잠금(Double-Checked Locking)
이중 검사 잠금(DCL)은 앞선 방법의 성능 문제를 개선할 수 있다고 한다!
public class DCLSingleton {
// volatile 키워드 사용
private static volatile DCLSingleton instance;
private DCLSingleton() {
// 초기화 코드
}
public static DCLSingleton getInstance() {
// 첫 번째 검사 (락 없이)
if (instance == null) {
// 동기화 블록 - 인스턴스 초기화에만 락 사용
synchronized (DCLSingleton.class) {
// 두 번째 검사 (락 내부에서)
if (instance == null) {
instance = new DCLSingleton();
}
}
}
return instance;
}
}이 방식을 이해하는 오래 걸렸다 ㅎㅎ.. 이 방식의 핵심은 두 가지다.
1. 첫 번째 null 체크로 인스턴스가 이미 존재하면 동기화 블록에 진입하지 않아 성능이 향상된다.
2. volatile 키워드는 Java 메모리 모델에서 변수의 가시성(visibility)을 보장하여 CPU 캐시와 메인 메모리 간 동기화 문제를 해결한다.
volatile의 역할은 특히 중요한데, Java에서 instance = new DCLSingleton()은 다음 세 단계로 실행된다.
- 객체를 위한 메모리 할당
- 객체 초기화
instance변수가 할당된 메모리를 가리키도록 설정
JVM의 최적화로 인해 이 단계들의 순서가 바뀔 수 있는데(특히 2와 3), volatile이 이를 방지하여 반드시 올바른 순서로 실행되게 한다. 이는 Java 5 이상에서만 제대로 작동한다.
4. 초기화 지연 홀더 클래스(Initialization-on-demand holder)
이 방식은 Java의 클래스 로딩 메커니즘을 활용하여 스레드 안전성과 초기화 지연을 모두 얻는 방법이다.
public class HolderSingleton {
private HolderSingleton() {
// 초기화 코드
}
// private static 내부 클래스
private static class Holder {
// final로 한 번 초기화됨을 보장
private static final HolderSingleton INSTANCE = new HolderSingleton();
}
public static HolderSingleton getInstance() {
return Holder.INSTANCE;
}
}이 방식은 JVM의 클래스 로딩 지연 특성과 초기화 안전성을 이용한다. Holder 클래스는 getInstance()가 호출될 때까지 로드되지 않으며, 클래스 로딩 과정은 JVM에 의해 스레드 안전하게 처리된다.
Java 명세에 따르면 클래스는 처음 사용될 때만 초기화되며, 이 초기화는 JVM에 의해 동기화된다. 따라서 별도의 synchronized나 volatile 키워드 없이도 스레드 안전성을 보장할 수 있다.
Bill Pugh가 제안한 이 방식은 현재 Java에서 가장 널리 사용되는 싱글톤 구현 방법이다.
5. Enum을 사용한 싱글톤 (가장 간결한 방법)
Joshua Bloch(이펙티브 자바 저자)가 추천하는 방법으로, 직렬화와 리플렉션에 의한 공격에도 안전하다.
public enum EnumSingleton {
INSTANCE;
// 필요한 필드와 메소드
private Connection dbConnection;
// enum 생성자 (기본적으로 private)
EnumSingleton() {
// DB 연결 등 초기화 코드
dbConnection = createDBConnection();
}
private Connection createDBConnection() {
// DB 연결 로직
return null; // 실제 연결 코드로 대체
}
// 비즈니스 메소드
public void doSomething() {
System.out.println("비즈니스 로직 수행");
}
// getter
public Connection getDbConnection() {
return dbConnection;
}
}
// 사용 예시
EnumSingleton.INSTANCE.doSomething();Enum 방식의 장점
- 코드가 간결하다
- 스레드 안전성이 보장된다
- 직렬화 문제를 자동으로 처리한다
- 리플렉션을 통한 공격에 안전하다 (Java는 enum 생성자 호출을 제한한다)
단점
- 초기화를 제어하기 어렵다 (enum은 로딩 시점에 초기화된다)
- 정말 치명적인 단점이 아닐 수 없다. - 상속이 불가능하다 (enum은 클래스를 상속할 수 없다)
- 지연 초기화(lazy initialization)가 필요한 경우에 적합하지 않다
장단점 분석
이제 이론적 설명은 그만하고 싱글톤 패턴을 실제 프로젝트에 적용해보며 경험한 장단점을 분석해보자.
장점
-
리소스 효율성 - 메모리와 같은 시스템 리소스를 효율적으로 사용할 수 있다. 많은 객체 생성이 필요 없어 메모리를 절약한다.
-
전역 접근성 - 애플리케이션의 어느 부분에서든 싱글톤 인스턴스에 쉽게 접근할 수 있다.
-
상태 일관성 - 인스턴스가 하나만 존재하므로 상태 변경이 모든 클라이언트에게 즉시 반영된다.
-
인스턴스 제어 - 인스턴스 생성을 제한하고 엄격하게 관리할 수 있다.
단점
-
단일 책임 원칙(SRP) 위반 - 싱글톤 클래스는 자신의 생성과 생명주기 관리, 그리고 비즈니스 로직을 모두 처리한다. 이는 단일 책임 원칙에 위배된다.
-
테스트 어려움 - 전역 상태를 가진 싱글톤은 단위 테스트를 복잡하게 만든다. 테스트마다 싱글톤 상태를 초기화해야 하며, 테스트 간 독립성을 보장하기 어렵다.
-
의존성 은닉 - 싱글톤에 의존하는 클래스는 외부에서 볼 때 그 의존성이 명시적으로 드러나지 않는다. 이는 코드 이해와 유지보수를 어렵게 한다.
-
결합도 증가 - 싱글톤은 코드 전반에 걸쳐 강한 결합을 만들어내므로 변경이 어려워진다.
-
동시성 문제 - 싱글톤 패턴은 멀티스레드 환경에서 구현이 까다롭고, 잘못 구현하면 Race Condition이 발생할 수 있다.
주의할 점
싱글톤 구현 시 다음 사항들을 특히 주의해야 한다.
-
스레드 안전성 - 멀티스레드 환경에서는 안전한 구현(DCL, Holder, Enum)을 선택해야 한다.
-
직렬화/역직렬화 문제 - 역직렬화 시 새 인스턴스가 생성될 수 있으므로
readResolve()메소드를 구현하거나 Enum을 사용해야 한다.// 역직렬화 시 새 인스턴스 생성 방지 private Object readResolve() { return getInstance(); } -
리플렉션을 통한 private 생성자 접근 - 리플렉션으로 private 생성자에 접근하면 싱글톤을 깨트릴 수 있다. 이를 방지하려면 생성자에서 두 번째 생성 시도를 차단하거나 Enum을 사용해야 한다.
private static boolean instanceCreated = false; private Singleton() { if (instanceCreated) { throw new IllegalStateException("이미 인스턴스가 생성되었습니다."); } instanceCreated = true; } -
과도한 사용 자제 - "싱글톤이라는 망치를 들면 모든 것이 못으로 보인다." 정말 필요한 경우에만 사용하고, 가능하면 의존성 주입을 활용하는 것이 좋다.
-
클래스 로더 이슈 - 여러 클래스 로더가 사용되는 환경(예: 일부 애플리케이션 서버)에서는 각 클래스 로더마다 별도의 싱글톤 인스턴스가 생성될 수 있다. 이는 JNDI와 같은 외부 레지스트리를 통해 해결할 수 있다.
스프링에서의 싱글톤
Spring Framework는 기본적으로 모든 빈을 싱글톤으로 관리한다. 이는 Spring의 가장 중요한 특징 중 하나다.
@Service
public class UserService {
// 이 서비스는 스프링 컨테이너에 의해 싱글톤으로 관리된다
}찾아보니 싱글톤들의 단점들이 치명적이라 Spring의 싱글톤 관리 방식은 일반적인 싱글톤 패턴과 다르게 관리된다고 한다!
-
Spring은 싱글톤 레지스트리를 사용한다. 즉, 싱글톤 객체의 생성과 관리를 스프링 컨테이너가 담당한다.
-
의존성 주입이 가능하다. 일반 싱글톤 패턴과 달리 스프링 빈은 의존성 주입을 통해 결합도를 낮출 수 있다.
-
전역 변수를 사용하지 않는다. 스프링 빈은 애플리케이션 컨텍스트를 통해 접근하므로 전역 상태를 갖지 않는다.
-
테스트 용이성이 높다. 모의 객체(mock)를 주입하거나 다른 구현체로 대체하기 쉽다.
이런 차이점 때문에 Spring의 싱글톤 방식은 전통적인 싱글톤 패턴의 단점을 많이 극복했다고 볼 수 있다.
팩토리 메소드 패턴
팩토리 메소드 패턴이란?
팩토리 메소드 패턴은 객체 생성 로직을 서브클래스에 위임하는 패턴이다. 이 패턴은 객체 생성 코드와 사용 코드를 분리하여 결합도를 낮추고 확장성을 높인다.
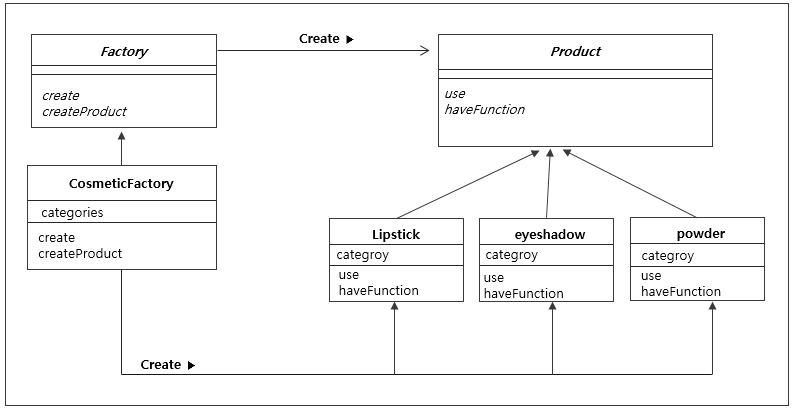
객체 지향 설계의 핵심 원칙 중 하나는 "구체적인 클래스보다 인터페이스에 의존하라"는 것이다. 팩토리 메소드 패턴은 이 원칙을 실현하는 방법 중 하나로, 객체 생성 과정을 추상화하여 클라이언트 코드가 구현 클래스가 아닌 인터페이스에 의존하게 한다. (사실 이것도 스프링에서 고수준 컴포넌트가 저수준 컴포넌트에 의존하지 않게 하기 위해 많이 쓰인다 ㅎㅎ)
활용 사례
실제 개발 과정에서 팩토리 메소드 패턴은 다음과 같은 상황에서 특히 유용하다.
-
데이터베이스 연결 관리 - 여러 종류의 데이터베이스(MySQL, PostgreSQL, MongoDB 등)에 대응하는 연결 객체를 생성할 때, 각 데이터베이스에 맞는 구체적인 연결 객체를 반환하는 팩토리를 구현할 수 있다.
-
결제 처리 시스템 - 신용카드, 페이팔, 계좌이체 등 다양한 결제 방식을 처리하는 객체를 생성할 때 사용한다.
-
문서 변환기 - 동일한 문서를 PDF, HTML, DOCX 등 다양한 형식으로 변환하는 객체를 생성할 때 활용할 수 있다.
-
UI 컴포넌트 생성 - 다양한 플랫폼이나 테마에 맞는 UI 컴포넌트를 생성해야 할 때 팩토리 메소드를 활용하면 클라이언트 코드를 변경하지 않고도 다양한 스타일의 컴포넌트를 제공할 수 있다.
-
메시지 처리 시스템 - 다양한 형식(XML, JSON, Binary 등)의 메시지를 처리하는 파서를 생성할 때 팩토리 메소드를 사용할 수 있다.
최근 개발했던 프로젝트에서는 다양한 외부 API와 통합해야 했다. 각 API에 맞는 클라이언트 객체를 생성하는 팩토리를 구현함으로써, 코드 변경 없이 새로운 API를 추가할 수 있었고 클라이언트 코드는 구체적인 API 구현에 의존하지 않게 되었다.
구현 방법
팩토리 메소드 패턴의 기본 구현부터 살펴보자.
1. 기본 팩토리 메소드 패턴
// 제품 인터페이스
public interface Payment {
void processPayment(double amount);
}
// 구체적인 제품들
public class CreditCardPayment implements Payment {
@Override
public void processPayment(double amount) {
System.out.println("신용카드로 " + amount + "원 결제 처리");
// 신용카드 결제 로직
}
}
public class PayPalPayment implements Payment {
@Override
public void processPayment(double amount) {
System.out.println("페이팔로 " + amount + "원 결제 처리");
// 페이팔 결제 로직
}
}
// 생성자 인터페이스 (Creator)
public abstract class PaymentFactory {
// 팩토리 메소드 - 서브클래스에서 구현
public abstract Payment createPayment();
// 템플릿 메소드 - 공통 로직 포함
public void processOrder(double amount) {
Payment payment = createPayment();
payment.processPayment(amount);
// 공통 후처리 로직 (로깅, 트랜잭션 관리 등)
}
}
// 구체적인 생성자들
public class CreditCardPaymentFactory extends PaymentFactory {
@Override
public Payment createPayment() {
return new CreditCardPayment();
}
}
public class PayPalPaymentFactory extends PaymentFactory {
@Override
public Payment createPayment() {
return new PayPalPayment();
}
}
// 클라이언트 코드
public class Client {
public static void main(String[] args) {
// 팩토리를 통한 객체 생성 및 사용
PaymentFactory factory = new CreditCardPaymentFactory();
factory.processOrder(15000);
factory = new PayPalPaymentFactory();
factory.processOrder(30000);
}
}이 패턴의 핵심 구성요소는 다음과 같다.
- Product(제품): 팩토리 메소드가 생성하는 객체의 인터페이스(
Payment) - ConcreteProduct(구체적 제품): Product 인터페이스의 구현체(
CreditCardPayment,PayPalPayment) - Creator(생성자): 팩토리 메소드를 선언하는 추상 클래스 또는 인터페이스(
PaymentFactory) - ConcreteCreator(구체적 생성자): 팩토리 메소드를 구현하는 클래스(
CreditCardPaymentFactory,PayPalPaymentFactory)
이 패턴의 핵심 이점은 클라이언트 코드가 특정 구현 클래스에 의존하지 않고 인터페이스에 의존하여 DIP(의존성 역전 원칙)를 따른다는 것이다. 나중에 새로운 결제 방식(예: 암호화폐 결제)이 추가되어도 기존 코드를 수정하지 않고 새로운 구현 클래스와 팩토리만 추가하면 된다.
2. 매개변수화된 팩토리 메소드 (Simple Factory)
실무에서는 팩토리 메소드 패턴의 간소화된 버전인 '간단한 팩토리'(Simple Factory)를 더 자주 사용한다.
public enum PaymentType {
CREDIT_CARD, PAYPAL, BANK_TRANSFER
}
public class SimplePaymentFactory {
// 정적 팩토리 메소드
public static Payment createPayment(PaymentType type) {
switch (type) {
case CREDIT_CARD:
return new CreditCardPayment();
case PAYPAL:
return new PayPalPayment();
case BANK_TRANSFER:
return new BankTransferPayment();
default:
throw new IllegalArgumentException("지원하지 않는 결제 유형: " + type);
}
}
}
// 사용 예시
Payment creditCardPayment = SimplePaymentFactory.createPayment(PaymentType.CREDIT_CARD);
creditCardPayment.processPayment(20000);이 방식은 엄밀한 의미에서 GoF의 팩토리 메소드 패턴은 아니지만, 객체 생성을 캡슐화한다는 기본 아이디어를 유지하며 더 간결하다. 단, 새로운 유형이 추가될 때마다 팩토리 클래스를 수정해야 하므로 OCP(개방-폐쇄 원칙)를 완벽히 따르지는 않는다.
3. DI 컨테이너를 활용한 팩토리
실무에서 Spring과 같은 DI 프레임워크를 사용한다면, 컨테이너 자체가 팩토리 역할을 맡을 수 있다.
@Component
public class PaymentProcessor {
private final Map<String, Payment> paymentStrategies;
// 생성자 주입으로 모든 Payment 구현체를 Map으로 주입받음
public PaymentProcessor(Map<String, Payment> paymentStrategies) {
this.paymentStrategies = paymentStrategies;
}
public void processPayment(String paymentType, double amount) {
Payment payment = paymentStrategies.get(paymentType);
if (payment == null) {
throw new IllegalArgumentException("지원하지 않는 결제 유형: " + paymentType);
}
payment.processPayment(amount);
}
}
@Component("creditCard")
public class CreditCardPayment implements Payment {
// 구현...
}
@Component("paypal")
public class PayPalPayment implements Payment {
// 구현...
}이 방식은 Spring의 DI 기능을 활용하여 모든 Payment 구현체를 자동으로 주입받는다. 새로운 결제 방식을 추가하려면 새 구현체 클래스를 만들고 @Component 어노테이션만 추가하면 된다.
4. 스프링의 FactoryBean 인터페이스 활용
Spring은 FactoryBean 인터페이스를 통해 복잡한 객체 생성 로직을 캡슐화할 수 있게 해준다.
@Component
public class PaymentFactoryBean implements FactoryBean<Payment> {
@Value("${payment.type}")
private String paymentType;
@Override
public Payment getObject() throws Exception {
switch (paymentType.toUpperCase()) {
case "CREDIT_CARD":
return new CreditCardPayment();
case "PAYPAL":
return new PayPalPayment();
default:
throw new IllegalArgumentException("지원하지 않는 결제 유형: " + paymentType);
}
}
@Override
public Class<?> getObjectType() {
return Payment.class;
}
@Override
public boolean isSingleton() {
return true;
}
}FactoryBean을 구현한 클래스는 Spring이 빈을 생성할 때 특별하게 처리된다. 컨테이너가 빈을 생성할 때 getObject() 메소드를 호출하여 실제 빈 객체를 얻는다. 위 예제에서는 외부 설정(application.properties)에 따라 다른 결제 구현체가 빈으로 등록된다.
장단점 및 고려사항
팩토리 메소드 패턴을 적용한 경험을 바탕으로 장단점을 분석해보자.
장점
-
결합도 감소 - 객체 생성 코드와 사용 코드를 분리하여 시스템의 결합도를 낮춘다. 클라이언트 코드는 구체 클래스가 아닌 인터페이스에 의존한다.
-
OCP(개방-폐쇄 원칙) 준수 - 새로운 제품 클래스를 추가할 때 기존 코드를 수정하지 않고 확장할 수 있다.
-
SRP(단일 책임 원칙) 준수 - 객체 생성 책임과 비즈니스 로직 책임을 분리한다.
-
테스트 용이성 - 팩토리를 모의 객체(mock)로 대체하여 테스트할 수 있으며, 다양한 객체 생성 시나리오를 테스트하기 쉽다.
-
코드 중복 제거 - 공통 객체 생성 로직을 집중화하여 코드 중복을 방지한다.
단점
-
코드 복잡성 증가 - 많은 인터페이스와 클래스가 필요하므로 시스템이 복잡해질 수 있다.
-
간단한 경우 과도한 설계 - 생성할 객체 종류가 적고 변경 가능성이 낮은 경우, 팩토리 메소드 패턴은 오히려 불필요한 복잡성을 가져올 수 있다.
-
계층 구조 관리 비용 - 제품과 생성자의 클래스 계층 구조를 함께 관리해야 하므로 유지보수 비용이 증가할 수 있다.
-
디버깅 어려움 - 객체 생성이 간접적으로 이루어지므로 디버깅이 더 복잡해질 수 있다.
고려사항
팩토리 메소드 패턴을 적용할 때 다음 사항들을 고려해야 한다.
-
패턴의 적용 범위 - 시스템 전체에 걸쳐 적용할지, 특정 모듈에만 적용할지 결정한다.
-
확장성 요구사항 - 향후 새로운 유형의 객체가 추가될 가능성이 높은지 평가한다.
-
인터페이스 설계 - 제품 인터페이스는 모든 구현체가 공통으로 지원해야 하는 기능만 포함해야 한다.
-
구현 복잡성 - 간단한 팩토리(Simple Factory)부터 시작하여 필요에 따라 완전한 팩토리 메소드 패턴으로 확장하는 것을 고려한다.
-
의존성 주입과의 통합 - Spring과 같은 DI 프레임워크를 사용하는 경우, 컨테이너의 기능을 활용하여 팩토리 메소드 패턴을 간소화할 수 있다.
디자인 패턴은 항상 트레이드오프를 수반한다. 복잡성이 증가하더라도 얻을 수 있는 유연성과 확장성이 필요한 상황인지 신중하게 판단해야 한다.
빌더 패턴
빌더 패턴이란?
빌더 패턴은 복잡한 객체의 생성 과정과 표현 방법을 분리하는 생성 패턴이다. 이 패턴은 특히 많은 매개변수를 가진 객체를 단계적으로 생성할 때 유용하다.
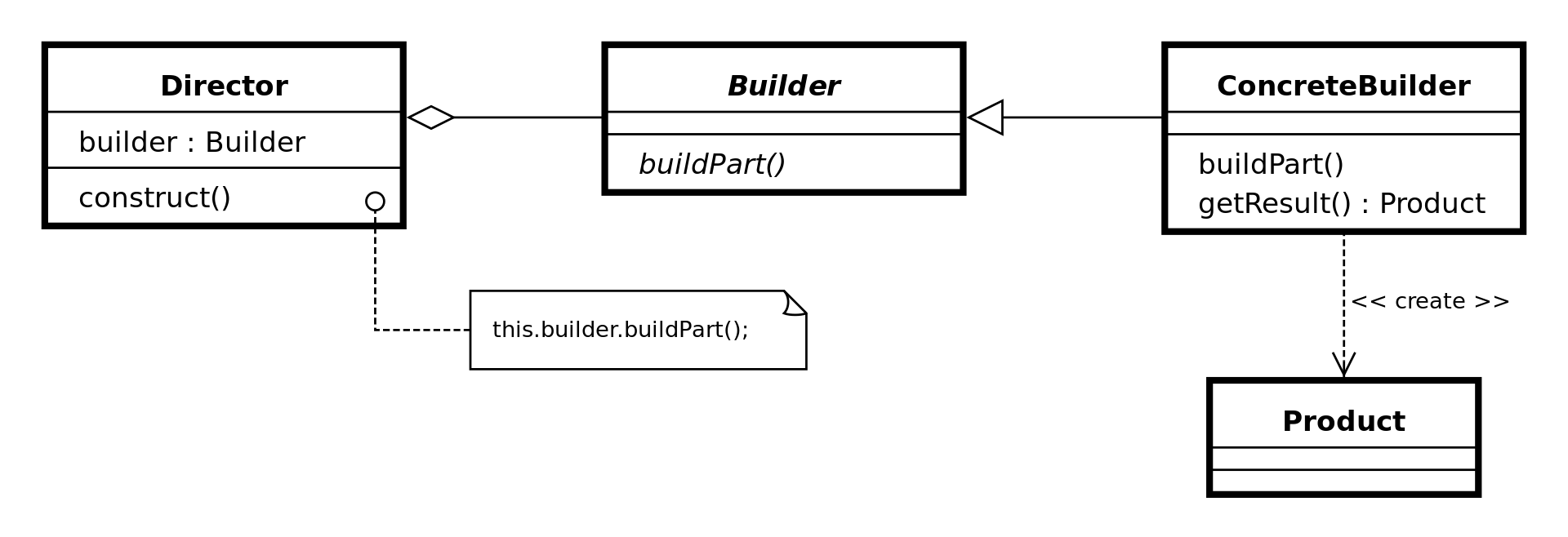
빌더 패턴의 핵심 아이디어는 객체 생성 과정을 여러 단계로 나누고, 각 단계에서 필요한 매개변수를 설정한 후 최종적으로 완성된 객체를 반환하는 것이다. 이는 점층적 생성자 패턴(telescoping constructor pattern)이나 자바빈즈 패턴(JavaBeans pattern)의 단점을 보완한다.
점층적 생성자 패턴: 매개변수 수를 늘려가며 생성자를 오버로딩하는 방식. 매개변수가 많아지면 코드 가독성이 떨어지고 매개변수 순서를 기억하기 어려워진다.
자바빈즈 패턴: 기본 생성자와 setter 메서드를 사용하는 방식. 객체 생성이 완료될 때까지 일관성이 무너지고, 불변 객체를 만들 수 없다.
활용 사례
실무에서 빌더 패턴이 특히 유용한 상황은 다음과 같다.
-
많은 매개변수를 가진 객체 생성 - 생성자에 많은 매개변수가 필요한 경우, 빌더 패턴은 코드 가독성을 크게 향상시킨다.
-
불변 객체 생성 - 불변(immutable) 객체를 생성할 때, 빌더 패턴은 객체가 완전히 생성된 후에는 변경할 수 없도록 보장한다.
-
객체 생성에 조건 로직이 필요한 경우 - 특정 필드 조합이 유효한지 검증하거나, 필드 간 의존 관계를 처리할 때 빌더 패턴이 유용하다.
-
복잡한 DTO(Data Transfer Object) 구성 - API 요청/응답, 리포트 데이터 등 복잡한 DTO를 구성할 때 빌더 패턴이 효과적이다.
-
테스트 객체 생성 - 단위 테스트에서 다양한 상태의 객체를 쉽게 생성하기 위해 빌더 패턴을 활용할 수 있다.
최근 REST API 서버를 개발하면서, 다양한 필터 조건을 포함하는 검색 쿼리 객체를 빌더 패턴으로 구현했다. 사용자가 선택한 필터에 따라 조건부로 매개변수를 설정할 수 있어 매우 유연한 검색 기능을 구현할 수 있었다.
구현 방법
빌더 패턴의 여러 구현 방법을 살펴보자.
1. 전통적인 빌더 패턴 구현
// 제품 클래스
public class User {
// 필수 필드
private final String id;
private final String name;
// 선택적 필드
private final int age;
private final String email;
private final String address;
private final String phoneNumber;
// private 생성자 - 외부에서 직접 생성 불가
private User(UserBuilder builder) {
this.id = builder.id;
this.name = builder.name;
this.age = builder.age;
this.email = builder.email;
this.address = builder.address;
this.phoneNumber = builder.phoneNumber;
}
// Getter 메소드들 (setter는 없음 - 불변 객체)
public String getId() { return id; }
public String getName() { return name; }
public int getAge() { return age; }
public String getEmail() { return email; }
public String getAddress() { return address; }
public String getPhoneNumber() { return phoneNumber; }
// toString, equals, hashCode 메소드는 생략
// 정적 내부 빌더 클래스
public static class UserBuilder {
// 필수 매개변수 - final로 선언
private final String id;
private final String name;
// 선택적 매개변수 - 기본값으로 초기화
private int age = 0;
private String email = "";
private String address = "";
private String phoneNumber = "";
// 빌더 생성자 - 필수 매개변수만 받음
public UserBuilder(String id, String name) {
this.id = id;
this.name = name;
}
// 선택적 매개변수를 위한 메소드 - 체이닝을 위해 this 반환
public UserBuilder age(int age) {
this.age = age;
return this;
}
public UserBuilder email(String email) {
this.email = email;
return this;
}
public UserBuilder address(String address) {
this.address = address;
return this;
}
public UserBuilder phoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
return this;
}
// 최종 빌드 메소드 - 유효성 검증 후 객체 생성
public User build() {
// 객체 생성 전 유효성 검증
validateUserObject();
return new User(this);
}
private void validateUserObject() {
// 이메일 형식 검증, 나이 범위 검증 등
if (age < 0) {
throw new IllegalStateException("나이는 음수가 될 수 없습니다.");
}
// 이메일 형식 검증 등 추가 검증 로직
}
}
}(길다... ) 코드를 보면 알겠지만 우리가 스프링에서 entity 생성 시 자주 사용되는 디자인 패턴이다! 사용법은 다음과 같다.
User user = new User.UserBuilder("user123", "홍길동")
.age(30)
.email("hong@example.com")
.phoneNumber("010-1234-5678")
.build();이 패턴의 주요 특징을 정리해 봤다.
- 이름 있는 매개변수(named parameters) - 각 설정 메소드 이름이 매개변수의 역할을 명확하게 한다.
- 메소드 체이닝(method chaining) - 설정 메소드가 this를 반환하여 연속적인 호출이 가능하다.
- 필수/선택적 매개변수 구분 - 빌더 생성자에는 필수 매개변수만 포함하고, 선택적 매개변수는 메소드로 설정한다.
- 불변 객체 생성 - 모든 필드가 final로 선언되어 변경 불가능하다.
- 유효성 검증 - 객체 생성 전에 모든 필드의 유효성을 한번에 검증할 수 있다.
2. 롬복(Lombok)을 활용한 빌더 패턴
자바에서는 롬복(Lombok) 라이브러리의 @Builder 어노테이션을 사용하면 빌더 코드를 자동 생성할 수 있다.
import lombok.Builder;
import lombok.Getter;
import lombok.ToString;
@Getter
@ToString
@Builder
public class UserLombok {
// 필수 필드
private final String id;
private final String name;
// 선택적 필드
private final int age;
private final String email;
private final String address;
private final String phoneNumber;
// lombok이 자동으로 빌더 클래스와 관련 메소드를 생성한다
}사용법은 방금 보여준 것과 같이 수동 구현과 유사하다.
UserLombok user = UserLombok.builder()
.id("user123")
.name("홍길동")
.age(30)
.email("hong@example.com")
.phoneNumber("010-1234-5678")
.build();롬복의 @Builder는 코드량을 크게 줄여주지만, 필수 매개변수 지정이나 복잡한 유효성 검증 등 고급 기능은 별도로 구현해야 한다. 필수 매개변수 문제는 생성자를 추가하고 @Builder(builderMethodName = "hiddenBuilder")와 같이 설정하여 해결할 수 있다.
@Getter
@ToString
@Builder(builderMethodName = "hiddenBuilder")
public class UserLombok {
// 필드 생략
// 필수 매개변수만 받는 생성자
public UserLombok(String id, String name) {
this(id, name, 0, "", "", "");
}
// 롬복이 사용할 모든 필드를 포함한 생성자
@Builder
private UserLombok(String id, String name, int age,
String email, String address, String phoneNumber) {
this.id = id;
this.name = name;
this.age = age;
this.email = email;
this.address = address;
this.phoneNumber = phoneNumber;
}
// 커스텀 빌더 메소드 - 필수 매개변수 지정
public static UserLombokBuilder builder(String id, String name) {
return hiddenBuilder().id(id).name(name);
}
}3. 계층적 빌더 패턴
여러 타입의 관련 객체를 생성해야 할 때 계층적 빌더 패턴을 사용할 수 있다. 이펙티브 자바에서 제안된 피자 예제로 설명해보자.
// 추상 제품
public abstract class Pizza {
public enum Topping { HAM, MUSHROOM, ONION, PEPPER, SAUSAGE }
final Set<Topping> toppings;
// 추상 빌더
abstract static class Builder<T extends Builder<T>> {
EnumSet<Topping> toppings = EnumSet.noneOf(Topping.class);
public T addTopping(Topping topping) {
toppings.add(topping);
return self();
}
abstract Pizza build();
// self() 메소드 - 자바의 self-type 제한 우회
protected abstract T self();
}
Pizza(Builder<?> builder) {
toppings = builder.toppings.clone(); // 방어적 복사
}
}
// 구체적인 제품 - 뉴욕 스타일 피자
public class NYPizza extends Pizza {
public enum Size { SMALL, MEDIUM, LARGE }
private final Size size;
// 구체적인 빌더
public static class Builder extends Pizza.Builder<Builder> {
private final Size size;
public Builder(Size size) {
this.size = size;
}
@Override
public NYPizza build() {
return new NYPizza(this);
}
@Override
protected Builder self() {
return this;
}
}
private NYPizza(Builder builder) {
super(builder);
size = builder.size;
}
}
// 또 다른 구체적인 제품 - 칼조네 피자
public class Calzone extends Pizza {
private final boolean sauceInside;
public static class Builder extends Pizza.Builder<Builder> {
private boolean sauceInside = false; // 기본값
public Builder sauceInside() {
sauceInside = true;
return this;
}
@Override
public Calzone build() {
return new Calzone(this);
}
@Override
protected Builder self() {
return this;
}
}
private Calzone(Builder builder) {
super(builder);
sauceInside = builder.sauceInside;
}
}사용 예시 코드다.
NYPizza nyPizza = new NYPizza.Builder(NYPizza.Size.LARGE)
.addTopping(Pizza.Topping.MUSHROOM)
.addTopping(Pizza.Topping.ONION)
.build();
Calzone calzone = new Calzone.Builder()
.addTopping(Pizza.Topping.HAM)
.sauceInside()
.build();이 패턴은 복잡하지만 강력하다. 추상 빌더 클래스에 공통 설정 메소드를 구현하고, 구체적인 빌더 클래스에서는 특정 제품에 관련된 설정만 추가하면 된다. 이는 제네릭을 사용한 재귀적 타입 제한(recursive type parameter)과 공변 반환 타입(covariant return typing)을 활용한다.
장단점 및 패턴 사용 베스트 케이스
장점
-
가독성 향상 - 매개변수가 많을 때 코드 가독성이 크게 향상된다. 각 필드의 역할이 메소드 이름으로 명확히 드러난다.
-
유연한 객체 구성 - 필요한 필드만 선택적으로 설정할 수 있어 다양한 구성의 객체를 쉽게 생성할 수 있다.
-
불변성 확보 - 빌더 패턴은 불변 객체를 쉽게 생성할 수 있다. 불변 객체는 스레드 안전성을 보장하고 오류 가능성을 줄인다.
-
단계적 생성 - 필요에 따라 객체 생성 단계를 나눌 수 있다. 특히 생성 과정이 복잡한 경우 유용하다.
-
유효성 검증 집중화 -
build()메소드에서 한 번에 모든 매개변수의 유효성을 검증할 수 있다.
단점
-
코드량 증가 - 롬복을 사용하지 않는 경우, 빌더 패턴 구현을 위해 많은 상용구(boilerplate) 코드가 필요하다.
-
복잡성 증가 - 매우 간단한 객체의 경우 빌더 패턴이 오히려 과도한 설계일 수 있다.
-
별도 빌더 클래스 필요 - 각 제품 클래스마다 별도의 빌더 클래스가 필요하여 시스템 복잡도가 증가한다.
-
성능 영향 - 객체 생성에 여러 단계가 추가되어 미세한 성능 저하가 있을 수 있다. 그러나 대부분의 경우 무시할 수 있는 수준이다.
베스트 프랙티스
-
필수 매개변수 강제 - 빌더 생성자에 필수 매개변수를 포함시켜 누락을 방지한다.
// 좋은 예 public static UserBuilder builder(String id, String name) { return new UserBuilder(id, name); } // 나쁜 예 - 필수 매개변수를 설정하지 않을 수 있음 public static UserBuilder builder() { return new UserBuilder(); } -
불변 객체 생성 - 빌더 패턴으로 생성되는 객체는 불변(immutable)으로 설계한다.
// 좋은 예 - 모든 필드가 final private final String name; // 나쁜 예 - 객체 생성 후 상태 변경 가능 private String name; -
단계적 빌더 설계 - 특정 순서로 메소드를 호출해야 하는 경우, 단계적 빌더(step builder)를 고려한다.
Order order = Order.builder() .customer(customer) // 1단계: 고객 정보 (필수) .items(items) // 2단계: 주문 항목 (필수) .deliveryAddress(address) // 3단계: 배송 주소 (필수) .paymentMethod(payment) // 4단계: 결제 방법 (필수) .coupon(coupon) // 5단계: 쿠폰 (선택) .build(); -
유효성 검증 통합 - 모든 유효성 검증을
build()메소드에서 수행한다.public User build() { // 복합 유효성 검증 if (age < 0) { throw new IllegalStateException("나이는 음수가 될 수 없습니다."); } if (email != null && !email.isEmpty() && !email.contains("@")) { throw new IllegalStateException("유효하지 않은 이메일 형식입니다."); } return new User(this); } -
빌더 재사용 방지 - 빌더는 일회용으로 설계하는 것이 안전하다.
// 나쁜 예 - 빌더 재사용 UserBuilder builder = new User.UserBuilder("user1", "홍길동"); User user1 = builder.age(30).build(); User user2 = builder.email("hong@example.com").build(); // user1의 age도 포함됨 // 좋은 예 - 매번 새 빌더 생성 User user1 = new User.UserBuilder("user1", "홍길동").age(30).build(); User user2 = new User.UserBuilder("user2", "김철수").email("kim@example.com").build(); -
롬복 활용 - 가능하면 롬복의
@Builder를 사용하여 코드량을 줄인다. 필요한 경우 커스터마이징한다.
빌더 패턴은 복잡한 객체 생성을 위한 강력한 도구지만, 모든 상황에 적합하지는 않다. 객체 생성 로직의 복잡성과 매개변수 수를 고려하여 적절히 적용해야 한다.
결론 및 비교
지금까지 세 가지 생성 패턴을 깊이 있게 살펴보았다. 이 패턴들은 모두 객체 생성에 관한 것이지만, 각각 다른 문제를 해결하기 위해 설계되었다.
패턴 비교
| 패턴 | 주요 목적 | 사용 시점 | 장점 | 단점 |
|---|---|---|---|---|
| 싱글톤 | 클래스의 인스턴스를 하나만 생성 | 공유 리소스 관리, 전역 상태 필요 시 | 메모리 효율성, 전역 접근성 | 테스트 어려움, 결합도 증가 |
| 팩토리 메소드 | 객체 생성을 서브클래스에 위임 | 생성할 객체 유형을 런타임에 결정해야 할 때 | 결합도 감소, 확장성 | 클래스 증가, 복잡성 |
| 빌더 | 복잡한 객체의 생성 과정 분리 | 많은 매개변수, 불변 객체 생성 시 | 가독성, 유연성, 안전성 | 코드량 증가, 간단한 객체에 과도 |
언제 어떤 패턴을 선택해야 할까?
디자인 패턴 선택은 항상 문제 상황과 트레이드오프를 고려해야 한다. 다음은 패턴 선택 시 고려할 사항이다.
-
싱글톤 패턴
- 리소스가 비싸거나 공유가 필요한 경우 (DB 연결 풀, 캐시 등)
- 전역 상태 관리가 필요한 경우 (설정, 로깅 등)
- 사용 시 주의: 과도한 사용은 피하고, 가능하면 의존성 주입으로 대체. 단위 테스트 시 모의 객체로 대체할 수 있는지 고려
-
팩토리 메소드 패턴
- 객체 생성 로직이 복잡하거나 조건부 로직이 많은 경우
- 클라이언트가 생성할 객체의 구체적인 클래스에 의존하지 않아야 하는 경우
- 객체 생성 시 환경이나 설정에 따라 다른 클래스의 객체를 생성해야 하는 경우
- 확장성이 중요한 시스템에서 (새로운 클래스가 자주 추가되는 경우)
-
빌더 패턴
- 매개변수가 많은 복잡한 객체를 생성하는 경우 (4개 이상의 매개변수)
- 불변 객체를 생성해야 하는 경우
- 객체 생성 시 매개변수에 대한 유효성 검증이 필요한 경우
- 객체 생성이 여러 단계로 이루어지는 경우
패턴의 조합
실무에서는 이러한 패턴들을 조합하여 사용하는 경우가 많다.
-
빌더 + 팩토리 메소드 - 팩토리 메소드가 빌더를 반환하여 복잡한 객체를 유연하게 생성
public interface ReportBuilder { ReportBuilder addHeader(String header); ReportBuilder addBody(String body); ReportBuilder addFooter(String footer); Report build(); } public class ReportFactory { public static ReportBuilder createPdfReportBuilder() { return new PdfReportBuilder(); } public static ReportBuilder createHtmlReportBuilder() { return new HtmlReportBuilder(); } } // 사용 예 Report pdfReport = ReportFactory.createPdfReportBuilder() .addHeader("제목") .addBody("내용") .addFooter("바닥글") .build(); -
싱글톤 + 팩토리 - 팩토리 자체를 싱글톤으로 구현하여 팩토리 생성 비용 절감
public class PaymentProcessorFactory { private static final PaymentProcessorFactory INSTANCE = new PaymentProcessorFactory(); private PaymentProcessorFactory() {} public static PaymentProcessorFactory getInstance() { return INSTANCE; } public PaymentProcessor createProcessor(PaymentType type) { // 다양한 결제 처리기 생성 로직 } }
SOLID 원칙과의 관계
이 생성 패턴들은 모두 객체지향 설계의 SOLID 원칙을 반영하고 있다.
- 단일 책임 원칙(SRP) - 팩토리 메소드와 빌더 패턴은 객체 생성 책임을 별도 클래스로 분리한다.
- 개방-폐쇄 원칙(OCP) - 팩토리 메소드 패턴은 기존 코드 수정 없이 새로운 제품 클래스를 추가할 수 있게 한다.
- 의존 역전 원칙(DIP) - 모든 패턴이 구체 클래스보다 추상화에 의존하도록 유도한다.
핵심 요약
생성 패턴은 객체 생성 메커니즘을 캡슐화하여 코드의 유연성, 재사용성, 유지보수성을 향상시킨다. 그러나 패턴은 도구일 뿐이며, 상황에 맞는 도구를 선택하는 것이 중요하다. 때로는 단순한 해결책이 최선일 수 있다. 패턴을 위한 패턴 적용은 피하자.
다음 시리즈 예고!! (힘들다..)
다음 시리즈에서는 구조 패턴(Structural Patterns)에 대해 알아볼 예정이다. 어댑터, 데코레이터, 프록시 등 클래스와 객체를 조합해 더 큰 구조를 만드는 패턴들을 공부하고 한 번 정리해 보겠다! 이 패턴들은 시스템의 구조를 유연하고 효율적으로 만드는 데 중요한 역할을 한다고 해서 중요해 보이기 까지 한다..
참고 자료
- Gamma, E., Helm, R., Johnson, R., & Vlissides, J. (1994). Design Patterns: Elements of Reusable Object-Oriented Software. (번역 요약본)
- Freeman, E., & Robson, E. (2004). Head First Design Patterns.
- Spring Framework Documentation - https://docs.spring.io/
- 백기선, 이펙티브 자바 강의
