Rand_Chat 프로젝트의 성능최적화
프로젝트가 마무리에 다다르면서 백엔드,DevOPs의 역할로서 , 성능최적화를 계획하려한다.
성능최적화의 계획 및 개요는 이러하다.
- 대용량
테스트 데이터생성병목예상지점파악(API)및 선정- 부하테스트를 통해 선정된 대상API의
TPS및 Latency파악 ,병목지점파악- 성능 최적화해야할
API 선정- API별 상황에 따른
최적화- 최초 TPS및 Latency과 성능개선된 API의 TPS 및 Latency비교
테스트 환경
- 실제 운영환경과 유사한 환경 구성
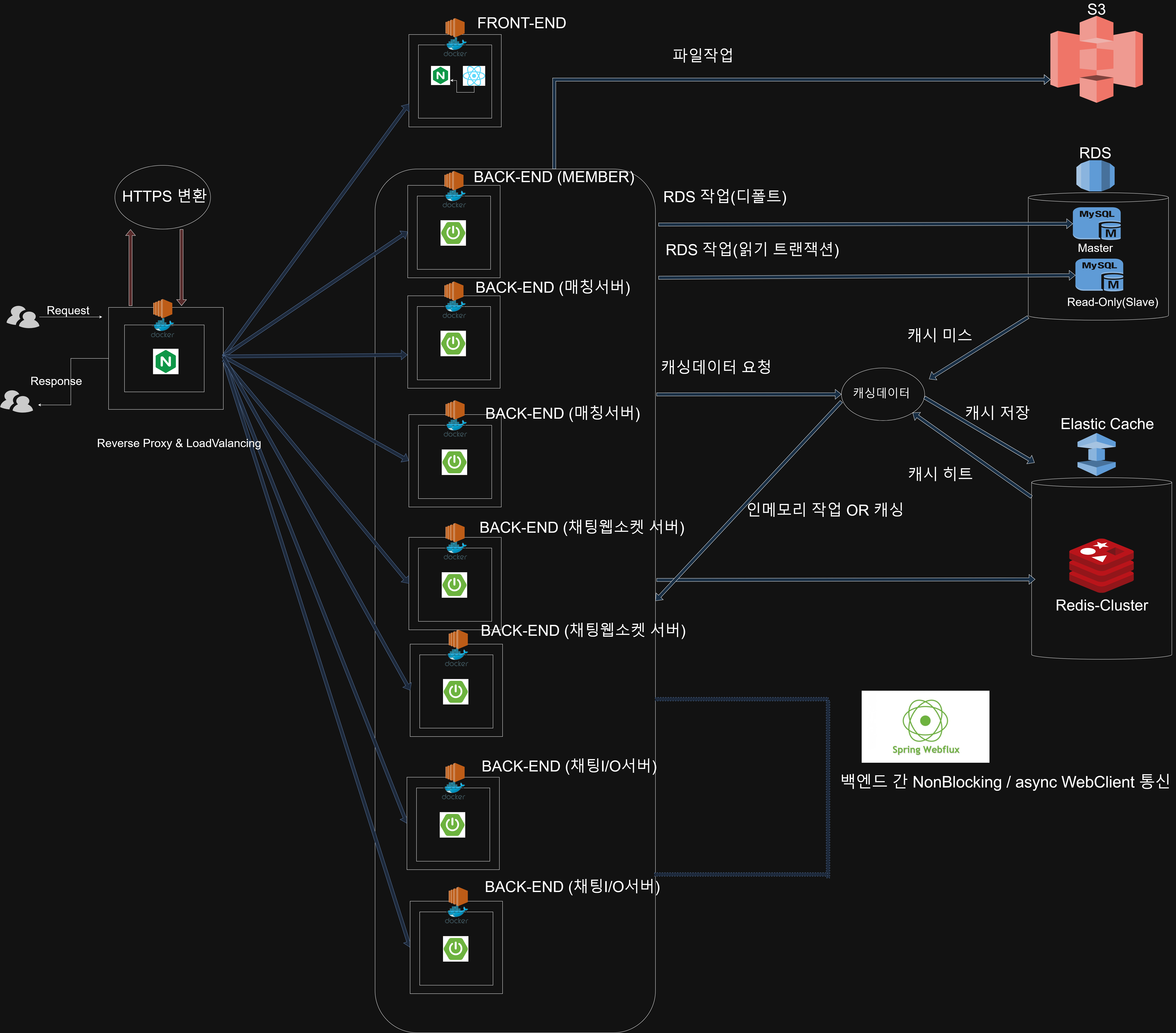
- SPEC
RDS : db.t4g.micro (Master , Slave)
EC2 : t2.micro
캐시는 테스트 목적상 비활성화 한다.
t2.micro 인스턴스를 활용하기 때문에 성능 최적화에 조금 제한적이다. ㅠ
추후에 스케일업이나 스케일 아웃을 고려하겠지만 기본적으로 스레드풀과 커넥션풀은 아래 값으로 하는게 적절하다고 판단했다.
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.maximum-pool-size=14
spring.datasource.hikari.idle-timeout=30000
spring.datasource.hikari.max-lifetime=1800000
spring.datasource.hikari.connection-timeout=30000
server.tomcat.threads.min=2
server.tomcat.threads.max=15
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {
@Override
public Executor getAsyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(5);
executor.setThreadNamePrefix("taskExecutor-");
executor.initialize();
return executor;
}
}
대용량 테스트 데이터 생성
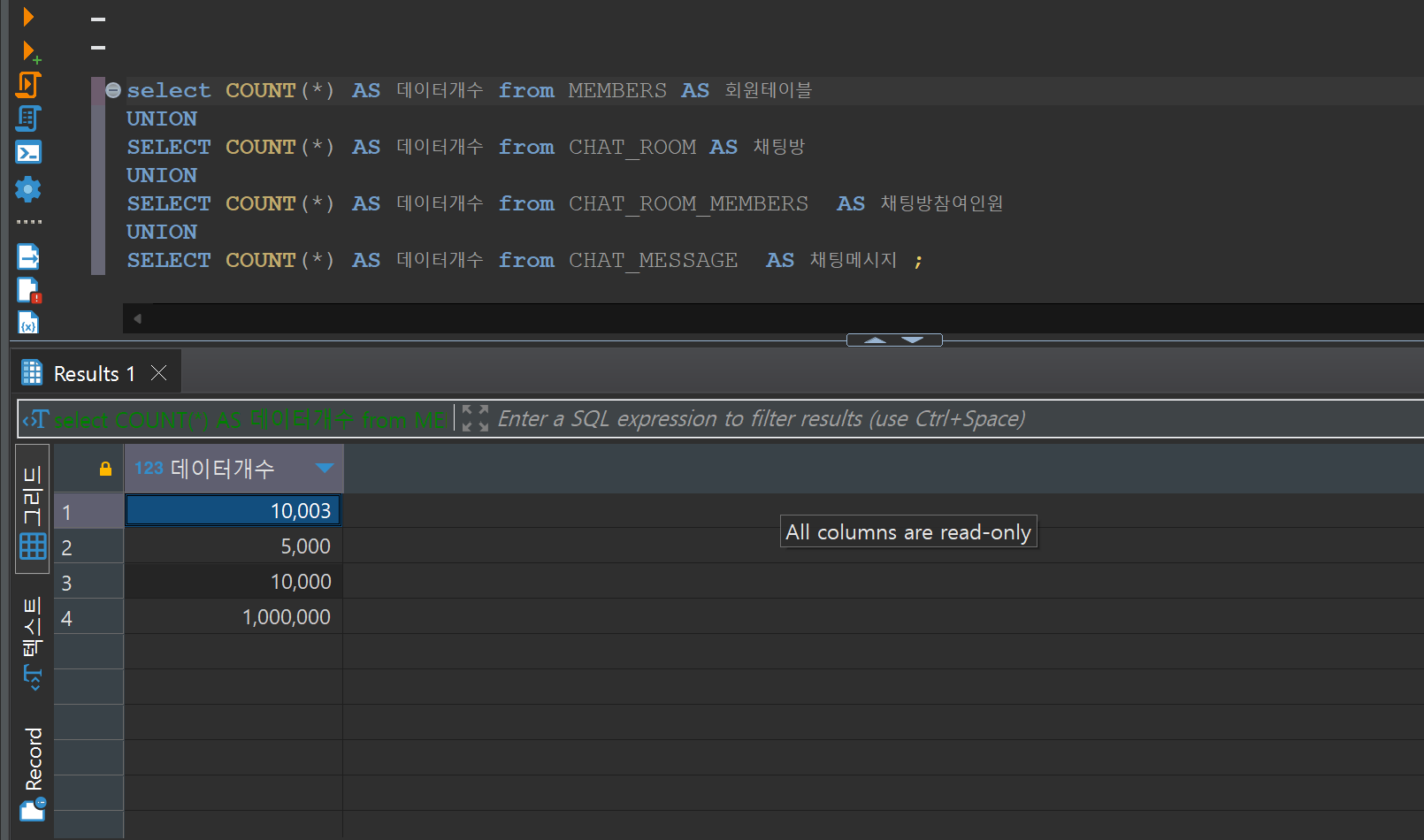
- 병목 예상과 관련된 테이블에 각각 대용량 더미 데이터를 INSERT 하였다.
- 회원테이블 10000개
- 채팅방 마스터 테이블 5000개
- 채팅방 참여인원 테이블 10000개
- 채팅 메시지 테이블 100,0000개
- 회원테이블 10000개
병목예상지점 파악(API)및 선정
1. 회원 참여 채팅방 리스트 조회 API
- 회원이 참여하고 있는 채팅방 목록을 조회하는 API (정렬 포함)
WHY?
- 해당 API는 사용자의 채팅방 리스트를 조회하는 내용으로 호출이 빈번할 것으로 예상된다.
- 또한 캐싱을 사용하지 않기에 반드시 부하테스를 수행해야한다. (물론 실제로직은 매 호출하지 않고 , optimistic update를 사용하고 있다.)
API 명세서 : https://rand-chat.gitbook.io/rand_chat-docs/i-o/i-o-api/undefined
2. 채팅메시지 리스트 조회 (오래된 메시지 조회) API
- 채팅메시지 리스트 조회 API (이전 메시지 조회)
WHY?
- 해당 API는 채팅방의 채팅메시지 리스트를 조회하므로 , 핵심기능이라 볼 수 있다.
- 물론 1페이지는 Redis에 캐싱이 되어있지만, 캐시미스 시 1페이지를 조회하며, 오래된 메시지를 보려면 해당API를 호출해야한다.
API 명세서 : https://rand-chat.gitbook.io/rand_chat-docs/i-o/i-o-api/undefined-3

백엔드