목표
- Servlet이 무엇인지 이해한다.
- JDBC가 무엇인지 이해한다.
- Servlet과 JDBC의 연관성을 이해한다.
- 아키텍처 관점에서 JDBC와 Servlet의 유기적 연관성을 이해한다.
새로운 데이터를 구현해야 할 때 JDBC와 Servlet의 동작은 어떻게 연관이 있는걸까?
내가 생각한 포인트
- servlet의 동작
- Spring framework에서 동작
- 서블릿만 쭉 보다보니 뭔가 MVC 아키텍처와 연관이 있다고 생각
- 이 과제를 내신 이유가 계층과 구조, 그 동작이 맞는걸까?
Servlet
나는 서블릿과 JSP가 단순히 Server-side Rendering을 위해서 동작하는 줄 알고 있었는데 교수님께서 CGI(Common Gateway Interface)를 말씀하셨고 JDBC와 Servlet이 어떤 연관성을 가졌는지 알아보라고 하셨기에 다시 공부해 봄.
일단 서블릿이 할 수 있는 역할은 다음과 같다.
- Page Rendering
- CGI
동적 페이지 생성은 알고 있던건데 CGI라니 내가 아는 그 CGI가 맞나 해서 찾아보니 맞았는데 원래 클라이언트와 서버, 서버와 다른 플랫폼(프로토콜) 간 이기종 통신은 이루어질 수 없지만 CGI를 구현 한다면 가능하다.
DB와 애플리케이션 프로그램은 서로 다르지만 통신할 수 있는 것도 CGI 덕분이고, HTTP에서 FTP로 접속이 가능한 것도 CGI 때문이다.
기존의 웹 환경이 단방향 전달에서 CGI를 통해 양방향 전달로 변경된 것이다.
Servlet
- 서블릿은 CGI를 자바 클래스로 구현하기 위해 나옴
- 자바 코드 내 HTML이 삽입되어 있으므로 일정 부분만을 Rendering
- CGI 자체는 프로토콜이기 때문에 구현이 필요
- 구현체 생성을 위해 Servlet Container가 존재
서블릿의 Life-Cycle을 관리 - Servlet Container를 통해 각 서블릿은 프로세스가 아닌 스레드 기반 생성
- WAS(Tomcat)를 통해 코드를 컴파일하고 Servlet Instance를 생성
Servlet 동작
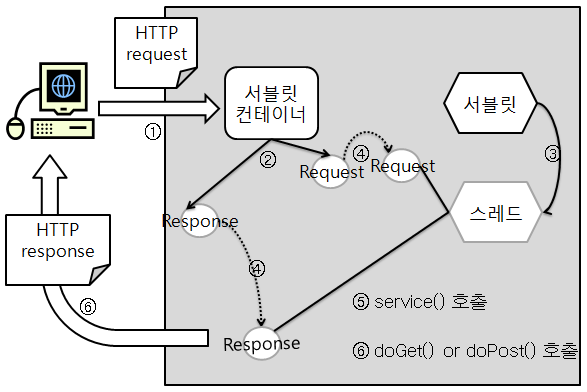
- HTTP 요청이 서블릿 컨테이너의 Request 객체로 들어옴
- 서블릿 컨테이너는 각 서블릿 즉 스레드마다 각 Task를 가지고 있음
이 Task와 URL이 동일한지 확인 - 동일하다면 그 서블릿의 서비스를 호출
HTTP 메소드 GET/POST에 따라 다른 메소드가 호출 - 완료된 작업은 Response 객체에 담아 반환
여기서 핵심은 서블릿 객체는 내가 작성 했지만 호출은 Life-Cycle에 의해 이루어 진다는 것, 코드의 호출이 내가 아닌 다른 프로그램에 있기에 이를 IOC(Inversion of Control) 제어의 역전이라고 함.
Servlet 호출
- 서블릿의 호출은 HTTP 메소드로도 구현 가능
- 라우팅 방식을 이용, 어노테이션을 걸고 URL에 따라 코드를 구현하면 됨
(express.js의 라우트 방식과 유사)
Spring Container에 의한 Servelt 관리
- 서블릿 컨테이너는 HTTP 요청을 처리함
- 대부분의 웹 프레임워크는 서블릿 컨테이너 위에서 동작하는 서블릿, 필터, 이벤트 리스너 등을 적절히 구현
- 사용자가 웹 프레임워크로 작성한 웹 애플리케이션은 결국 서블릿 컨테이너 위 서블릿으로 동작하는 것
그리고 이 서블릿 객체들을 프레임워크가 생성하여 관리할 때 Spring Beans라고 함 - HTTP 프로토콜로 전달된 메세지는 서블릿 컨테이너에서 해석, 재조합되어 서블릿으로 전달하여 동작
결국 스프링 웹 프레임워크는 서블릿 객체를 관리하기 위해 스프링 컨테이너를 소유해야 함 - Spring Container는 Bean들의 생명주기를 관리
Spring Container는 어플리케이션을 구성하는 Bean들을 관리하기 위해 IoC를 사용한다. (서블릿들 즉 Bean의 소유권을 Inversion)
Spring Container 종류에는 BeanFactory와 이를 상속한 ApplicationContext가 존재한다. 이 두개의 컨테이너로 의존성 주입된 빈들을 제어하고 관리할 수 있다
결론
스프링 웹 프레임워크가 서블릿들을 관리하기 위해선 서블릿 컨테이너가 필요하다.
서블릿 컨테이너는 WAS에 의해 먼저 동작하고, IoC를 통해 Bean이라는 개념으로 스프링 컨테이너에서 관리한다.
이러한 일들을 한번에 처리하기 위해 스프링 부트에서는 내장 Tomcat을 사용하여 시작 시 바로 스프링 컨테이너를 생성하고 dispatcher servlet을 동작한다.
JDBC 아키텍처
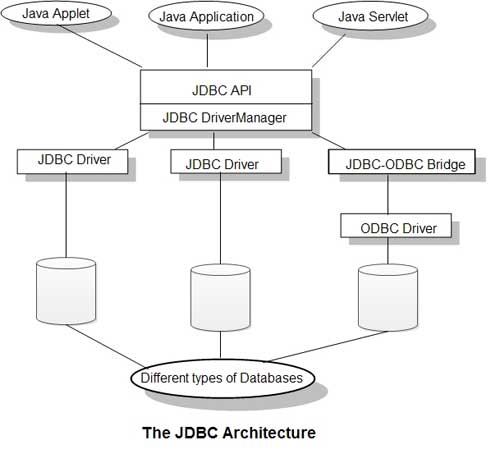
- JDBC는 Persistent Layer에 속하는 데이터베이스와의 연결을 위한 새로운 API 계층임
- 자바 코드 자체만으로는 DB 서버에서 접근이 불가능해 JDBC를 이용
JDBC API -> 드라이브 커넥터 호출 -> SQL -> DBMS - 이 때 자바 코드와 DAO를 매핑한다면 SQL Mapper를 이용
이외에도 JDBC Template를 사용하여 반복되는 SQL 작업을 관리할 수 있음 - ORM을 사용한다면 객체 관계를 통해 JDBC에 접근 가능
JDBC와 자바 애플리케이션 사이에 JPA가 추가되는데 이 계층은 JDBC를 추상화한 계층으로 개발자에게 추상화 된 DAO를 제공하여 객체지향적 접근을 도움
결국 자바 Obejcts는 DAO(Data Access Object)를 통해 Objects를 CRUD 가능한 SQL로 변경하거나 매핑
DTO는 DB 데이터를 Request/Response 하기 위한 분리된 엔티티를 담는 객체임
Application Code <-DTO-> JDBC API <-Entity-> DAO <-> DB
유기적 연관성
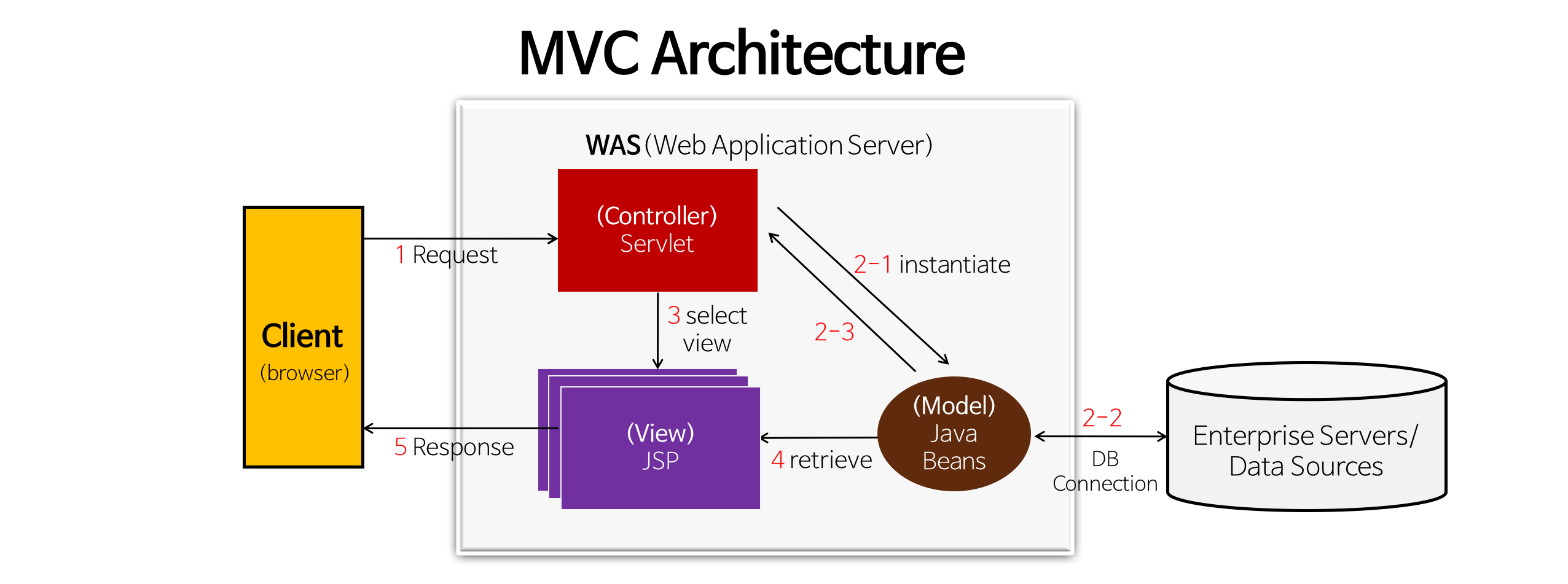
- HTTP 요청이 Servlet 컨테이너로 들어온다면 서블릿 컨테이너를 통해 요청을 관리
- 그렇게 하면 서블릿 컨테이너만으로 요청에 대한 리소스 라우팅이 가능
- 서블릿 객체를 스프링 컨테이너가 소유하므로 각 서블릿에 대한 서비스(자바코드 일명 java beans)가 호출 되고 이 서비스들이 각 DAO/DTO를 통해 JDBC API에 접근
결론
- HTTP 요청에 대해서 서블릿이 핸들링을 하고, JDBC API를 통해 데이터를 조작한다는 것
- 하지만 JDBC 그러니까 모델의 경우에는 API가 존재
핵심은 따로 구현체가 존재하지 않는 서블릿을 어떻게 구현할 것인가? 서블릿과 서블릿 컨테이너에 대한 이해와 구현이 백엔드 '개발자'로써의 능력이다.
