하둡 에코 시스템
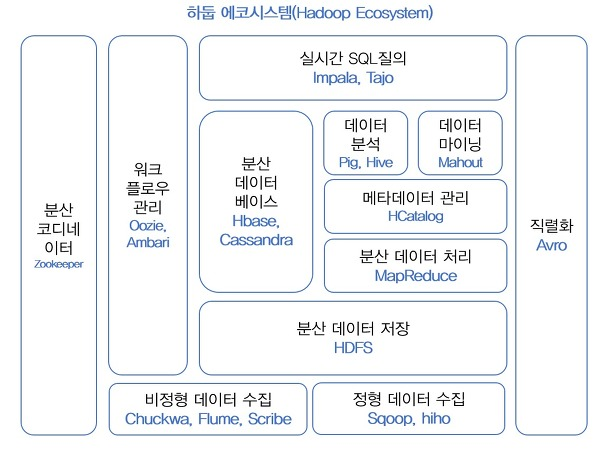
- 하둡 중심의 프로젝트 집합
- 분산 코디네이터 Zookeeper
분산환경에서 서버간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템이다.
분산 동기화를 제공하고 그룹 서비스를 제공하는 중앙 집중식 서비스로 알맞은 분산처리 및 분산 환경을 구성하는 서버 설정을 통합적으로 관리 한다. - 분산 리소스 관리 YARN
작업 스케줄링 및 클러스터 리소스 관리를 위한 프레임워크로 맵리듀스, 하이브, 임팔라, 스파크 등 다양한 애플리케이션들은 얀에서 작업을 실행한다. - 클라우드 리소스 관리 Mesos
Mesos는 Linux커널과 동일한 원칙을 사용하며 컴퓨터에 API(예:Hadoop,Spark,Kafka,Elasticsearch)를 제공한다. 페이스북, 트위터, 이베이등 다양한 기업들이 메소스 클러스터 자원을 관리하고 있다. - 데이터저장 HBase (분산 데이터베이스)
HBase는 구글 Bigtable을 기반으로 개발된 비관계형 데이터베이스이며, Hadoop및 HDFS위에 Bigtable과 같은 기능을 제공하게 된다. 네이버 라인 메신져에 HBase를 적용한 시스템 아키텍쳐를 발표 하기도 했다. - 코어
- 분산 파일 데이터 시스템 HDFS(Hadoop Distribute File System)
애플리케이션 데이터에 대한 높은 처리량의 액세스를 제공하는 분산 파일 시스템 - MapReduce
MapReduce는 대용량 데이터를 분산 처리 하기위한 프로그램으로 정렬된 데이터를 분산처리한다.Map하고 이를 다시 합치는 Reduce 과정을 거친다.하둡에서 대용량 데이터 처리를 위한 기술중 큰 인기를 누리고 있다.
- 분산 파일 데이터 시스템 HDFS(Hadoop Distribute File System)
- 컬럼기반 스토리지 Kudu
컬럼기반 스토리지로 하둡 에코 시스템에 새로 추가되어 급변하는 데이터에 대한 빠른 분석을 위해 설계되었다. 클라우데라에서 시작된 프로젝트로, 15년말 아파치 인큐베이션 프로젝트로 선정 되었다. - 데이터수집/분석
- Chukwa
Chukwa는 분산 환경에서 생성되는 데이터를 안정적으로 HDFS에 저장하는 플랫폼이다.
대규모 분산 시스템을 모니터링 하기 위한 시스템으로, HDFS및 MapReduce 에 구축되어 수집된 데이터를 최대한 활용하기 위한 모니터링 및 유연한 툴킷을 포함한다. - Flume
Flume은 많은 양의 데이터를 수집, 집계 및 이동하기위한 분산형 서비스이다. - Scribe
페이스북에서 개발한 데이터 수집 플랫폼이며, Chukwa와 다르게 데이터를 중앙서버로 전송하는 방식이며, 최종 데이터는 다양한 저장소로 활용할 수 있다. - Kafka
카프카는 데이터 스트림을 실시간으로 관리하기 위한 분산 시스템으로, 대용량 이벤트 처리를 위해 개발 되었다.
- Chukwa
- 데이터처리
- Pig
하둡에 저장된 데이터를 맵리듀스 프로그램을 만들지 않고 SQL과 유사한 스크립트를 이용해 데이터를 처리, 맵리듀스 API를 매우 단순화한 형태로 설계 되었다. - Mahout
분석 기계학습에 필요한 알고리즘을 구축하기위한 오픈소스 프레임워크이며, 클러스터링, 필터링, 마이닝, 회귀분석 등 중요 알고리즘을 지원해 준다. - Spark
대규모 데이터 처리를 위한 빠른 속도로 실행시켜 주는 엔진이다.
스파크는 병렬 애플리케이션을 쉽게 만들수 있는 80개 이상의 고급 연산자를 제공하며 파이썬,R등에서 대화형으로 사용할 수 있다. - Impale
임팔라는 하둡기반 분산 엔진으로, 맵리듀스를 사용하지 않고 C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보여준다. - Hive
하둡기반 데이터 솔루션으로, 페이스북에서 개발한 오픈소스로 자바를 몰라도 데이터분석을 할수 있게 도와 준다. SQL과 유사한 HiveQL이라는 언어를 제공하여 쉽게 데이터 분석을 할 수 있게 도와 준다.
- Pig
하둡
- 데이터 저장소의 물리적 한계를 극복하고자 나온 기술
- 파일 저장의 경우 물리 디스크의 사용으로 인해 발생하는 물리적 한계인 디스크 읽기/쓰기(I/O 작업)에 대한 작업에 대한 영향을 최소화 하기 위해 하나의 디스크가 아닌 여러 디스크를 통해 데이터를 읽어오는 분산 파일 시스템을 적용가능한 아파치 재단의 자바 기반 오픈소스 프레임워크
하둡의 아키텍처
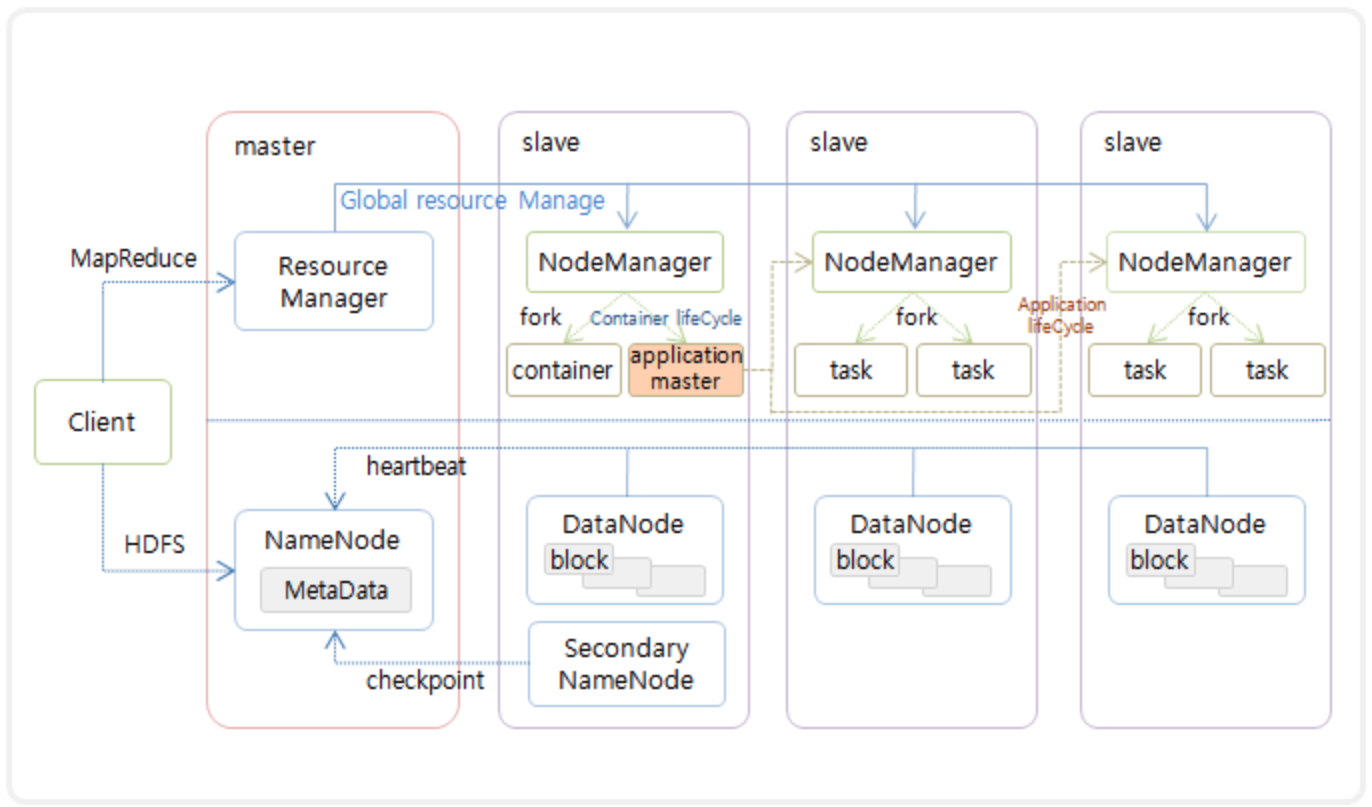
- 하나의 물리적 서버 내 분산 파일 시스템(HDFS)와 MapReduce(분산 처리 시스템)을 구성
- 저사양의 다중 서버를 구성하고, 각 서버는 HDFS와 MapReduce가 구성된 네임노드(마스터)로부터 데이터 노드(Slave)를 구성
- 네임노드의 HDFS를 통해 각 데이터노드로 데이터를 분산저장/관리하고, MapReduce를 통해 Key-Value로 구성된 각 데이터들에 대한 읽기/쓰기 작업을 진행
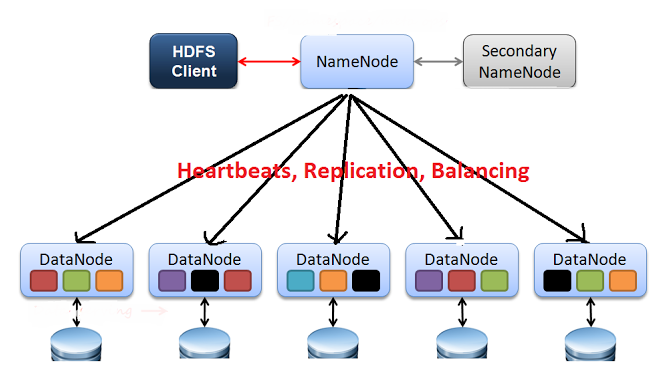
HDFS
MapReduce
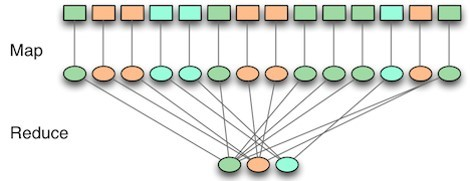
- HDFS를 통해 저장/관리되는 데이터를 실제 사용하기 위한 분산 프로그래밍 프레임워크
- HDFS를 통해 분산된 각 데이터를 모으는 Map, Filtering과 Sorting을 수행하는 Reduce로 구성
- 무분별하게 구성된 대용량 분산 데이터를 유효한 데이터로 사용가능
하둡 2.0
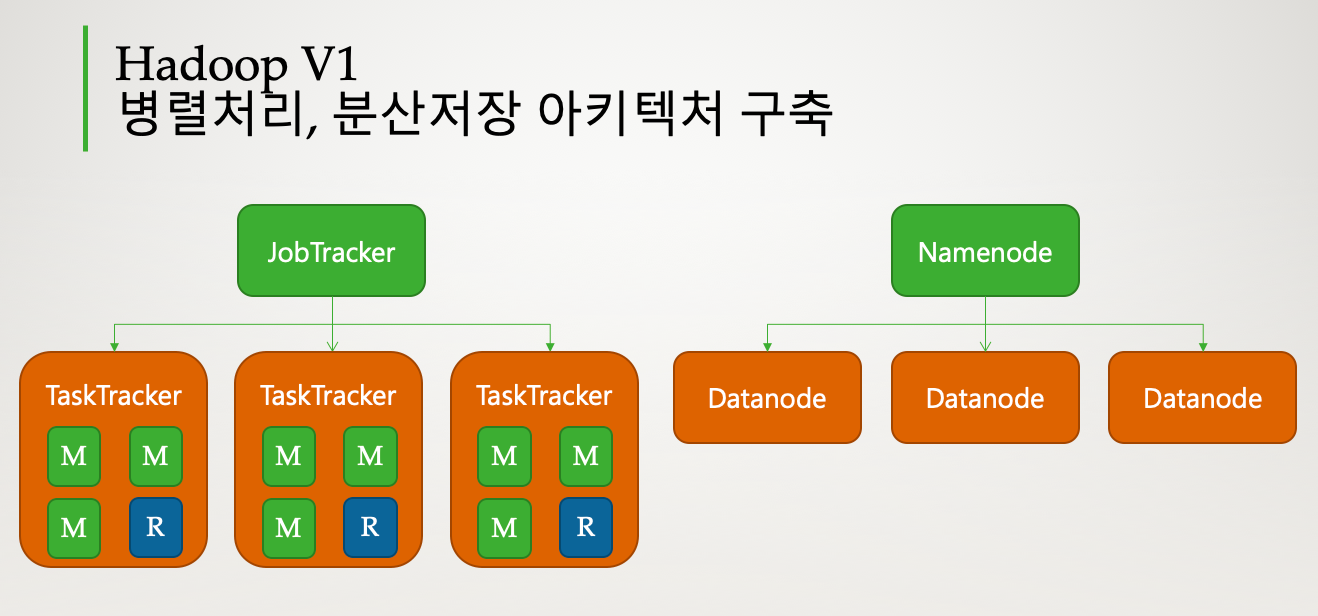
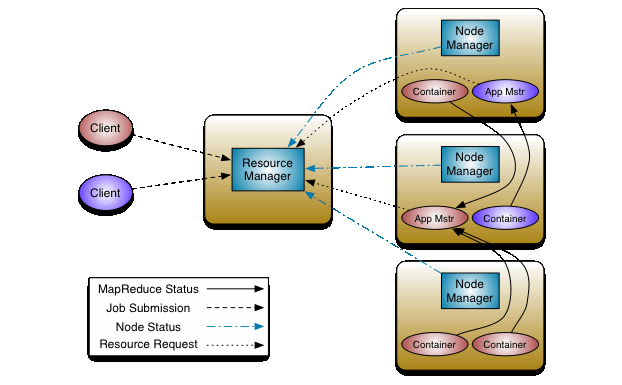
- 하둡 1.0에서 Job Tracker가 파일의 분산관리와 분산처리를 모두 처리하는 프로세스로 인해 분산관리와 분산처리 중 한곳에서라도 지연이 발생하면 병목현상이 발생
- 하둡 2.0에서는 Job Tracker의 역할을 분산관리의 경우 리소스/노드 매니저를, 분산처리는 컨테이너를 통해 진행함으로서 병목현상을 제거

안아줘요