
1.Scikit-learn이란?
사이킷런은 파이썬의 머신러닝 라이브러리로 다양한 머신러닝 알고리즘을 사용할 수 있다. 사이킷런을 이용해 머신러닝을 사용하는 작업의 대부분은 데이터를 정제하는 작업이다. 사이킷런 자체에서 머신러닝을 위한 알고리즘을 제공하고 있기 때문에 사용자는 이 알고리즘에 넣어줄 데이터만 다듬어주면 되는 것이다.
1) 머신러닝이란?
머신러닝을 설명하기 위해서는 가장 큰 개념인 AI를 먼저 설명해야 한다. AI란 Artificial Intelligence로 기계나 시스템이 사람의 행동을 모방하게 하는 기술을 의미한다. 이때 시대가 변함에 따라 데이터의 양이 급격하게 증가하고 컴퓨터 하드웨어의 발전, 알고리즘의 발전도 이루어지면서 자연스럽게 AI기술이 발전하게 되는데, 이때 생긴 것이 머신러닝이다. 즉, 머신러닝은 AI기술의 하나로 AI를 만드는 기술 중 하나인 것이다. 머신러닝은 데이터 학습에 기반한 인공지능의 한 분야로 대부분의 동작방식은 일반적인 프로그래밍 방식인 입력값과 알고리즘을 input으로 넣어주면 출력값을 output으로 반환하는 형식대신, 입력값과 출력값을 input으로 넣어주면 알고리즘을 output으로 반환하는 형식을 많이 사용한다.
2) 머신러닝 관련용어
Feature: 위에서 설명한 input으로 넣어줄 입력값. 즉. 예측을 하기 위해 필요한 값들을 의미한다. 일반적으로X로 표현한다.Label: 위에서 설명한 input으로 넣어줄 출력값. 즉, 예측해야하는 값을 의미한다. 일반적으로y로 표현한다Model: 어느 정도 만들어진 알고리즘이라고 생각하면 된다. 이 모델에 위에 설명한 feature와 label을 넣어주고 이 데이터에 맞춰서 모델을 만들어준다. 이렇게 완성된 모델이 위에서 설명한 output으로 반환되는 알고리즘을 의미한다.
3) 머신러닝 종류
- 지도학습(Supervised Learning)
모델에게 데이터의 특징(Feature)과 정답(Label)을 알려주며 학습시킨다. 대부분의 머신러닝은 지도학습을 이용하고 분류와 회귀 두 종류가 존재한다.- 분류(Classification) : 두개 이상의 클래스(범주)에서 선택을 묻는 지도 학습방법
- 이진 분류 : 맞는지 틀린지를 분류.
- 다중 분류 : 여러개의 클래스중 하나를 분류- 의사결정나무(Decision Tree)
- 로지스틱 회귀(Logistic Regression)
- K-최근접 이웃(K-Nearest Neighbors, KNN)
- 나이브 베이즈(Naive Bayes)
- 서포트 벡터 머신(Support Vector Machine, SVM)
- 랜덤 포레스트(Random Forest)
- 신경망(Neural Network)
- 회귀(Regression) : 숫자(연속된값)를 예측 하는 지도학습**
- 의사결정나무(Decision Tree)
- 선형 회귀(Linear Regression)
- 릿지 회귀(Rige Regression)
- 라쏘 회귀(Lasso Regression)
- 엘라스틱 넷(Elastic Net)
- K-최근접 이웃(K-Nearest Neighbors, KNN)
- 나이브 베이즈(Naive Bayes)
- 서포트 벡터 머신(Support Vector Machine, SVM)
- 랜덤 포레스트(Random Forest)
- 신경망(Neural Network)
- 분류(Classification) : 두개 이상의 클래스(범주)에서 선택을 묻는 지도 학습방법
- 비지도학습 (Unsupervised Learning)
정답(Label)이 없이 데이터의 특징(Feature)만 학습하여 데이터간의 관계를 찾는 학습방법- 군집(Clustering)
- 비슷한 유형의 데이터 그룹을 찾는다. 주로 데이터 경향성을 파악하는 비지도 학습
- K-평균 클러스터링(K-Means Clustering)
- 평균점 이동 클러스터링(Mean-Shift Clustering)
- DBSCAN(DensityBased Spatial Clustering of Applications with Noise)
- 차원축소(Dimensionality Reduction)
- 예측에 영향을 최대한 주지 않으면서 변수(Feature)를 축소하는 한다.
- 고차원 데이터를 저차원의 데이터로 변환하는 비지도 학습
- 주성분 분석(Principal Component Analysis, PCA)
- 군집(Clustering)
- 강화학습
학습하는 시스템이 행동을 실행하고 그 결과에 따른 보상이나 벌점을 받는 방식으로 학습. 학습이 계속되면서 가장 큰 보상을 얻기 위한 최상의 전략을 스스로 학습하게 한다.
2.Scikit-learn 구성요소
사이킷런은 크게 추정기(Estimator)와 변환기(Transformer)로 구성되어있다.
- Estimator : 데이터를 학습하고 예측하는 알고리즘(모델)들을 구현한 클래스들
- fit() : 데이터를 학습하는 함수
- predict() : 학습된 모델로 예측하는 함수
- Transformer : 데이터 전처리를 하는 클래스들. 데이터 셋의 값의 형태를 변환한다.
- fit() : 데이터를 학습하는 함수(어떻게 변환할지)
- transform() : 학습된 모델로 변환하는 함수
- fit_transform() : 데이터 학습과 변환을 한번에 하는 함수
3.머신러닝 프로세스
먼저 사이킷런 라이브러리를 설치한다.
pip install scikit-learn1) 데이터셋 분할
데이터셋이란 데이터를 모아놓은 것을 의미하며 데이터를 모을 때는 필요한 정보와 관련된 데이터를 모은다. 이런 데이터셋은 머신러닝의 input으로 사용되는데 크게 3종류로 분할해 사용한다.
- train(훈련) 데이터셋 : 모델을 학습시킬 때 사용하는 데이터셋
- validation(검증) 데이터셋 : 학습된 모델을 검증할 때 사용하는 데이터셋
- test(평가) 데이터셋 : 검증된 데이터셋을 평가하는 데이터셋
이때 데이터셋을 분할하는 방식으로 Hold Out방식과 K-Fold Cross Validation방식이 존재한다.
1.1 Hold Out 방식
- 설명
데이터셋을 위에서 설명한 데이터셋 3종류로 나누는 방식이다. - 문제점
train / validation / test 데이터셋이 어떻게 나눠 지냐에 따라 결과가 달라진다. 만약 train 데이터셋에 우연하게 이상치의 비율이 굉장히 높았다면, validation과 test 데이터셋에 표준 데이터가 많이 존재하더라도 정확한 예측이 이루어지지 못할 것이다.(이상치를 기준으로 학습했을 것이므로) 즉, Hold Out 방식은 학습할 데이터가 방대하여 이상치에 대한 영향이 적을 때 사용하는 것이 좋다 - 사이킷런 코드
먼저sklearn.model_selection모듈의train_test_split함수를 이용하는데 이 함수는 데이터를 훈련 데이터셋과 평가 데이터셋으로 나눠준다. 즉, 데이터셋을 두 개로 분리해주는 함수라고 볼 수 있는데 이 함수를 이용해 먼저 전체 데이터셋을 훈련 데이터셋과 평가 데이터셋으로 나눠주고, 나눠진 훈련 데이터셋에 다시 이 함수를 이용해 훈련 데이터셋과 검증 데이터셋으로 나눠서 전체 데이터셋을 총 3개의 데이터셋으로 분할한다.from sklearn.model_selection import train_test_split # X는 feature데이터, y는 lable데이터라고 가정 # 훈련/평가 데이터셋 분리 X_train, X_test, y_train, y_test = train_test_split(X, # feature 데이터 y, # label 데이터 test_size=0.2, # 전체 데이터셋 중 평가 데이터셋의 비율 설정 stratify=y, # 해당 데이터의 분포와 비슷하게 훈련/평가 데이터셋으로 나눔 random_state=0) # 랜덤 제너레이터 시드값 설정 # 분리된 훈련 데이터셋을 훈련/검증 데이터셋 분리 X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2, stratify=y_train, random_state=0)
1.2 K-Fold Cross Validation 방식
-
설명
전체 데이터셋을 설정한 K개로 나누고, K개중 하나를 검증 데이터셋으로 나머지를 훈련 데이터셋으로 하여 모델을 학습시키고 검증한다. K개로 나뉜 데이터셋들이 모두 검증 데이터셋으로 한번씩 이용되도록 K번 해당 작업을 반복한다. 분할 방식에 따라 KFold 방식과 StratifiedKold 방식으로 나뉜다. -
분할 방식
- KFold
회귀에 사용된다. 지정한 개수(K)만큼 분할한다.
from sklearn.model_selection import KFold # 리스트 형식 data변수가 존재한다고 가정 kfold = KFold(n_splits=5) # 5개로 나누기 gen = kfold.split(data) # 데이터셋을 지정한 5개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성- StratifiedKold
분류에 사용된다. 나뉜 fold 들에 label들이 같은(또는 거의 같은) 비율로 구성 되도록 나눈다.
from sklearn.model_selection import StratifiedKFold # 리스트 형식 data변수가 존재한다고 가정 s_fold = StratifiedKFold(n_splits=3) # 3개로 나누기 s_gen = s_fold.split(X, y) # 데이터셋을 지정한 3개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성 - KFold
-
사이킷런 코드
sklearn.model_selection모듈의cross_val_score함수를 사용한다. 이 함수는 데이터셋을 K개로 나누고 평가하는 작업을 K번 처리해준다.from sklearn.model_selection import cross_val_score # X, y데이터가 존재한다고 가정 tree =DecisionTreeClassifier(random_state=0) cross_val_score(estimator=tree, # 모델 객체 설정 X=X, # Feature 데이터 설정 y=y, # Label 데이터 설정 scoring="accuracy", # 평가지표 설정 cv=4) # 나눌 개수(K) 설정
2) 데이터 전처리(Data Preprocessing)
전처리는 전(before)에 하는 처리라고 생각하면 된다. 즉, Raw Data(날것의 데이터)를 사용할 수 있도록 잘 깎고 다듬는 작업을 의미한다. 결측치 처리, 이상치 처리 등의 작업이 포함된다.
2.1 - 결측치 처리
결측치란 수집하지 못하거나 모르는 값을 의미한다. 이때 없는 값 혹은 0값과 헷갈리면 안 된다. 예를 들어 결혼의 유무를 판단하는 특징에서 결혼을 하지 않음은 수집된 값이지, 결측치가 아니다.
결측치는 데이터를 학습하는 과정에서 문제가 되므로 따로 처리가 필요하다. 결측치에 대한 처리는 크게 삭제하거나 대체하는 방법 두 가지로 나뉠 수 있다.
삭제
만약 특정 열에 대한 결측치가 너무 많으면 해당 열을 삭제할 수 있다. 혹은 특정 행에서 특정 열에 대한 결측치가 있으면 해당 행을 삭제할 수 있다. 일반적으로는 결측치가 존재하는 행을 삭제하는 방식을 많이 이용한다.대체
수치형일 경우 평균, 중앙값 등으로 대체하거나 범주형일 경우 최빈값 등으로 대체한다. 아니면 다른 열들의 데이터를 이용해 해당 결측치를 추론하기도 한다.
2.2 - 이상치 처리
이상치란 이상한 값을 의미한다. 특징에 아예 맞지 않는 값이거나 다른 값들과 너무 동떨어진 값이 있다.
- 오류값
특징에 맞지 않는 잘못된 값을 의미한다. 예를 들어 나이를 데이터로 받았는데 -12라는 값이 들어오면 이것은 나이라는 특징에 맞지 않는 값이므로 이상치다. 보통 오류값은결측치로 대체한다. - 극단치
극단치는 오류값은 아니지만 다른 값들과 너무나도 다른 값을 가지는 값을 의미한다. 예를 들어 키를 데이터로 받았는데 250m라는 값이 들어오면 이것은 키라는 특징에 부합하기는 하지만, 보통 250m라는 키값은 굉장히 드물기 때문에 극단치로 여겨진다. 극단치는값을 유지하거나 결측치로 대체한다. 혹은 min/max값을 따로 설정하고 min/max값 중 하나로 대체하기도 한다.
2.3 - 타입별 처리
먼저 타입 종류를 알아본다.
-
범주형(Categorical) 변수
대상값들이 서로 떨어진 값을 가지는 변수. 대부분 몇 개의 범주 중 하나에 속하는 값들로 구성되어 어떤 분류에 대한 속성을 가진다.- 명목(Norminal) 변수 : 서열이 없는 변수 ex) 남자, 여자
- 순위(Ordinal) 변수 : 서열이 있는 변수 ex) 1등, 2등, 3등
-
연속형(Continuous) 변수
대상값들이 서로 연속된 값을 가지는 변수를 말한다. 대상 값은 보통 정해진 범위 안의 모든 실수이다.- 등간(Interval) 변수 : 0이 상대적인 값이다 ex) 온도 (온도에서 0은 절대적 0값을 의미하는 것이 아니라 어느점의 온도를 표시하는 값일뿐)
- 비율(Ratio) 변수 : 0이 절대적인 값이다 ex) 무게 (온도와 달리 무게 0은 무게가 없다는 뜻이다.)
해당 타입의 변수들에 대한 처리 방법을 알아본다.
- 범주형 변수
레이블 인코딩(Label enconding): 각 범주에 대한 정수값을 부여하는 방식이다. 예를 들어 남자는 0, 여자는 1로 값을 부여하는 식이다. 이 경우는 숫자의 차이가 모델에 영향을 주지 않는트리 계열 모델들에 주로 적용한다.(의사결정나무, 랜덤포레스트 등등) 하지만 이 숫자의 차이가 모델에 영향을 주는 선형 계열 모델들에는 적용하지 않는다.(로지스틱회귀, SVM, 신경망 등등)sklearn.preprocessing.LabelEncoder함수 사용- fit(1차원범주데이터) : 범주형 데이터들에 대한 학습(범주마다 0,1,2 값 부여..)
- transform(1차원범주데이터) : 학습된 내용으로 '범주->정수' 변환
- fit_transform(1차원범주데이터) : 학습과 변환을 한번에 처리
- inverse_transform(1차원범주데이터) : 숫자를 문자열로 변환
- classes_ : 인코딩한 클래스 조회
# 사용예시
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
items = ["A반", "B반", "C반","C반", "B반", "C반", "A반"]
le.fit_transform(items)출력결과 =>
array([0, 1, 2, 2, 1, 2, 0], dtype=int64)
즉, "A반"->0, "B반"->1, "C반"->2 로 변환된 결과를 확인할 수 있다.
원핫 인코딩(One-Hot encoding): n개의 범주가 존재하면 n개의 컬럼을 생성해 해당하는 컬럼값에 1, 나머지는 0으로 표시하는 방법이다. 예를 들어 남자, 여자를 구분하려면 남자, 여자 컬럼을 생성하고 남자일 시 남자 1, 여자 0으로 표시하고 여자일 시 남자 0, 여자 1로 표시한다. 이 경우는 숫자의 차이가 모델에 영향을 주는선형 계열 모델들에 주로 적용한다.(로지스틱회귀, SVM, 신경망 등등)sklearn.preprocessing.OneHotEncoder함수 이용- fit(2차원범주데이터): 데이터셋을 기준으로 어떻게 변환할 지 학습
- transform(2차원범주데이터): Argument로 받은 데이터셋을 원핫인코딩 처리
- fit_transform(2차원범주데이터): 학습과 변환을 한번에 처리
- get_feature_names_out() : 원핫인코딩으로 변환된 Feature(컬럼)들의 이름을 반환
# 사용예시
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
items = ["A반", "B반", "C반","C반", "B반", "C반", "A반"]
items = pd.DataFrame(items)
print(items.shape)
ohe.fit_transform(items) 출력결과 =>
(7, 1)
<7x3 sparse matrix of type '<class 'numpy.float64'>'
with 7 stored elements in Compressed Sparse Row format>
이렇게 OneHotEncoding한 결과는 csr_matrix(희소행렬 객체)객체로 반환된다. 이는 원래 OneHotEncoder로 변환한 결과가 낭비가 많은 데이터 형태이므로(만약 feature가 10개이면 해당하는 feature만 1, 나머지는 0값을 가질 것임) 데이터 낭비를 막기 위한 목적으로, csr_matrix는 1로 표시된 feature의 위치만을 알려준다. csr_matrix를 2차원 배열형태로 표현하고 싶다면 toarray()를 이용한다. 혹은 OneHotEncoder()의 sparse매개변수 값을 False로 주면 csr_matrix타입 대신 array타입이 반환되는 방식을 이용할 수도 있다.
ohe.fit_transform(items).toarray()출력결과 =>
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[0., 1., 0.],
[0., 0., 1.],
[1., 0., 0.]])
ohe = OneHotEncoder(sparse=False)
ohe.fit_transform(items)출력결과 =>
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 1.],
[0., 1., 0.],
[0., 0., 1.],
[1., 0., 0.]])
- 연속형 변수
정규화(Feature Scaling): 각각의 feature(칼럼) 간의 값의 범위가 다를 때 이를 비슷한 수준으로 맞춰주는 작업이다. 간단한 예로 단위를 맞춰주는 작업을 생각할 수 있다. 너비는 미터로, 높이는 센티미터로 값을 받았을 때 실제 너비와 높이 값의 범위가 같을지라도 단위가 달라서 범위가 다르게 느껴질 수 있다. 이때 두 값을 같은 단위로 변환하면 두 feature의 값의 범위가 비슷하게 될 것이다. 이것이 정규화다. 정규화의 종류로는 표준화, Min Max Scaling 두 가지가 존재한다.
표준화(StandardScaler): 평균 0 , 분산 1이 되도록 모든 값을 변환해준다.
from sklearn.preprocessing import StandardScaler
data = np.array([10,2,30]).reshape(3,1)
stn_scaler = StandardScaler()
result = stn_scaler.fit_transform(data)MinMaxScaler: 최대값을 1로 최솟값을 0으로 기준을 잡고 모든 값을 0~1 사이값으로 변환해준다.
from sklearn.preprocessing import MinMaxScaler
data = np.array([10,2,30]).reshape(3,1)
mm_scaler = MinMaxScaler()
result = mm_scaler.fit_transform(data)3)모델 평가
3.1 - 혼동행렬(Confusion Matrix)
실제값과 예측값을 각각 행과 열로 표현해 전체 데이터를 행렬로 표시한 것을 혼동행렬이라고 한다. 이진분류(Postivie, Negative를 구분하는 분류)를 혼동행렬로 나타낸 모습을 확인해본다.
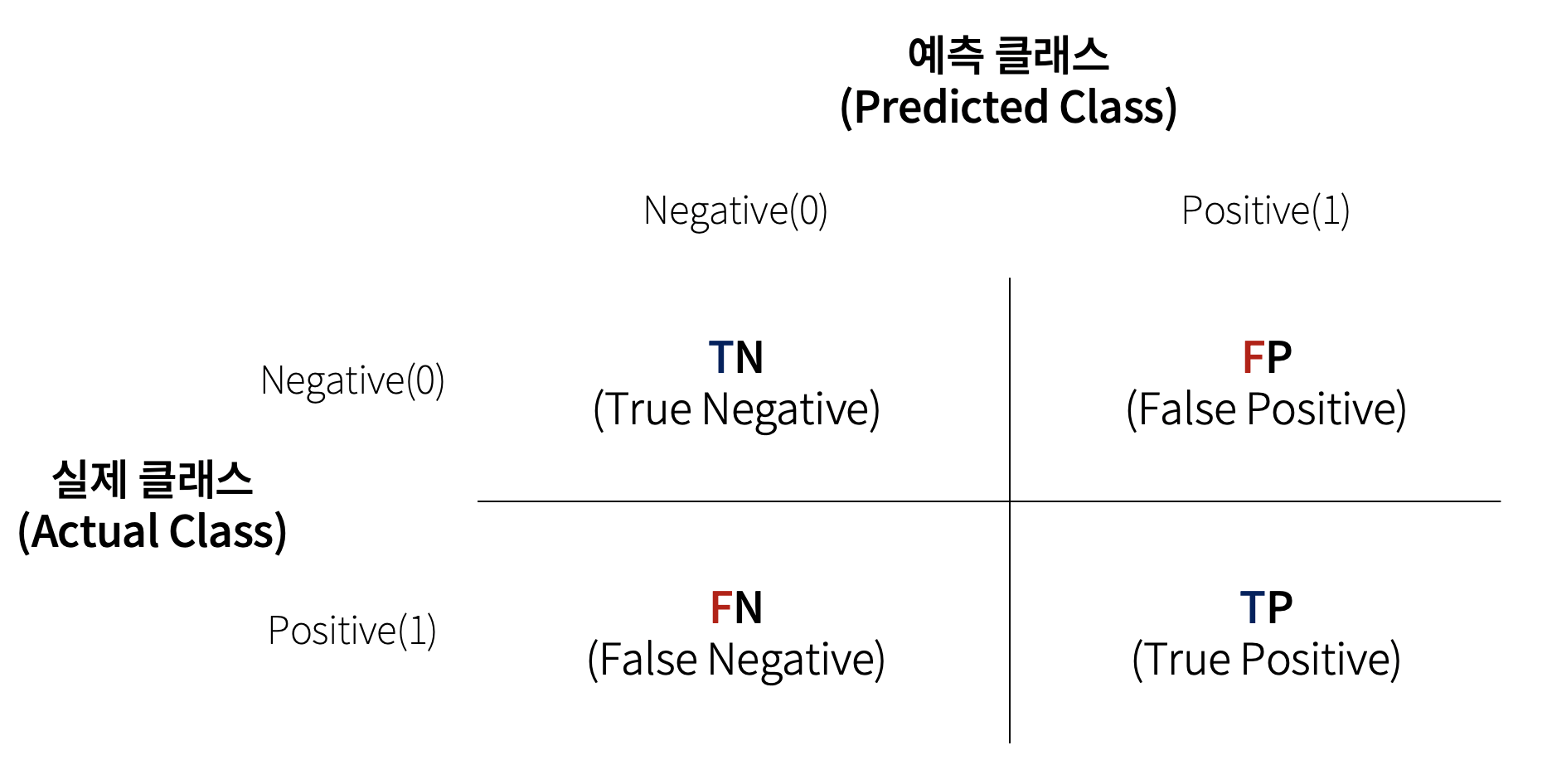
다음은 혼동행렬에서 모델을 평가하는 기준들이다.
정확도(Accuracy): ( TP +TN ) / ( TP + TN + FP + FN )
: 정확도는 전체 데이터에서 얼마나 오류 없이 판단했는지, 즉 positive와 negative의 정답 확률을 의미한다.정밀도(Precision): ( TP ) / ( TP + FP )
: 정밀도는 예측 positive값 중 실제 positive값의 비율을 의미한다. 쉽게 말해 예측 positive값이 얼마나 신뢰성있느냐의 척도이다. 만약 실제 positive값들은 5개이지만 5개 중 단 1개만 positive로 예측하고 negative는 모두 negative로 예측했다면, 4개의 positive값을 놓쳤음에도 불구하고 정밀도는 100%다.(예측한 내용은 100%로 맞았으므로)특이도(Specificity): ( TN ) / ( TN + FP )
: 특이도는 실제 negative값 중 예측 negative값 판정이 난 비율을 의미한다.재현율(Recall): ( TP ) / ( TP + FN )
: 재현율은 실제 positive값 중 예측 positive값 판정이 난 비율을 의미한다. 쉽게 말해 실제 positive값을 얼마나 negative로 예측하지 않고 제대로 positive 예측을 했느냐의 척도이다. 만약 모든 데이터를 positive로 예측한다면 재현율은 무조건 100%가 된다.(negative를 positive로 예측했지만 재현율을 실제 positive값들이 positive로 예측됐느냐만 중요)
<sklearn.metrics 모듈>
- confusion_matrix(y 실제값, y 예측값) : 혼동행렬을 numpy의 ndarray타입으로 반환
- ConfusionMatrixDisplay(confusion_matrix객체, display_labels=[라벨명]) : confusion matrix를 시각화해준다. (예전에는 plot_confusion_matrix()을 사용했지만 1.0버전에서 deprecated됨.)
- recall_score(y 실제값, y 예측값) : 재현율값 반환
- precision_score(y 실제값, y 예측값) : 정밀도값 반환
- f1_score(y 실제값, y 예측값) : F1 점수 반환 (recall과 precision의 조화 평균값)
- classification_report(y 실제값, y 예측값) : 클래스 별로 recall, precision, f1 점수와 accuracy를 종합해서 보여준다.
이때, positive와 관련된 값이 `정밀도`와 `재현율`인데, 이 두 값은 `임계값(Threshold)`에 따라 달라진다.임계값(Threshold): 모델이 분류 Label을 결정할 때 기준이 되는 확률 기준값으로 위 예시에서는 positive일 확률을 의미한다. 디폴트값은 0.5이고 이 값을 조정함으로 정밀도를 올리고 재현율을 낮추거나, 정밀도를 낮추고 재현율을 올릴 수 있다.
임계값을 높이면 양성으로 예측하는 기준을 높여서(엄격히 해서) 정말 정확한 양성이 아니면 음성으로 예측하게 된다. 그래서 정밀도는 높아지지만 재현율은 낮아진다. 임계값을 낮추면 양성으로 예측하는 기준이 낮아져서 조금이라도 양성 의심이 가면 양성으로 예측하게 된다. 그래서 재현율은 높아지지만 정밀도는 낮아진다. 즉, 재현율과 정밀도는 반비례 관계다.
3.2 - 그래프로 시각화
PR Curve와 AP Score
PR Curve: Precision Recall Curve로 임계값(threshold)이 변화함에 따른 재현율(recall)값과 정밀도(precision)값의 그래프를 의미한다.(재현율과 정밀도는 반비례 관계)AP Score: Average Precision Score로 PR Curve에서 전체 면적 중 PR Curve가 차지하는 면적의 비율을 의미한다. 이 값이 높을수록 성능이 우수하다고 평가된다.
<sklearn모델 모듈>
- predict_proba() : class별 확률을 반환
(ex. 0과 1(negatvie와 positive)를 나눌 때 1(positive)로 예측되었다면 0.3 0.7 이런식의 확률이 반환될 것이다.)
<sklearn.metrcis 모듈>
- precision_recall_curve(y정답, y예측확률) : (precision리스트, recall리스트, threshold리스트) 튜플값 반환
- PrecisionRecallDisplay(precision값, recall값) : recall과 precision을 시각화해준다.
- average_precision_score(y정답, y예측확률) : 그래프가 차지하는 면적의 비율값을 반환ROC curve와 AUC score
ROC curve: Receiver Operating Characteristic Curve로 임계값(threshold)이 변화함에 따른 FPR과 TPR의 그래프를 의미한다.AUC score: Area Under the Curve
<sklearn.metrcis 모듈>
- roc_curve(y정답, y예측확률) : (FPR리스트, TPR리스트, Threshold리스트) 튜플값 반환
- roc_auc_score(y정답, y예측확률) : 그래프가 차지하는 면적의 비율값을 반환
- RocCurveDisplay(fpr, tpr, roc_auc,estimator_name) : 그래프 시각화3.3 - 과적합과 일반화
과소적합(Underfitting): train, test 둘 다 성능이 나쁨- 발생 원인 : 학습 데이터 양에 비해 모델이 너무 단순한 경우 발생
과대적합(Overfitting): train은 성능이 좋고, test는 성능이 나쁨- 발생 원인 : 학습 데이터 양에 비해 모델이 너무 복잡한 경우 발생
ex) 학습 데이터 자체가 적은데, 그 안에 이상치가 존재할 경우 그 이상치에 맞춰진 학습결과가 생성되어 테스트 과정에 표준 데이터가 들어갔을 때 문제가 생길 수 있다.
- 발생 원인 : 학습 데이터 양에 비해 모델이 너무 복잡한 경우 발생
일반화(Generalization): train, test 둘 다 성능이 좋음
이렇게 모델의 복잡도에 따라 성능이 달라지므로 이런 모델의 복잡도를 조절할 수 있도록 머신러닝 모델마다 있는 값을 규제 하이퍼파라미터라고 한다.
ex) DecisionTreeClassifier의 규제 하이퍼파라미터
- max_depth : 트리의 최대 깊이
- max_leaf_nodes : 리프노드 개수
- min_samples_leaf : leaf 노드가 되기위한 최소 샘플수
- min_samples_split : 나누는 최소 샘플수
이렇게 규제 하이퍼파라미터는 여러개가 존재하므로 각각의 규제 하이퍼파라미터의 값을 변경하면 여러 하이퍼파라미터들의 조합이 생기게 된다. 이 조합들을 모두 직접적으로 평가하기에는 너무 많은 조합이 존재하게 되므로 사이킷런에서 최적의 하이퍼파라미터 조합을 찾는 방식을 제공해준다.
-
GridSearchCV : 하이퍼파라미터들을 지정하면 모든 조합에 대해 교차검증 후 제일 좋은 성능을 내는 하이퍼파라미터 조합을 찾아준다.
from sklearn.model_selection import GridSearchCV tree = DecisionTreeClassifier(random_state=0) params = { "max_depth":[None,1,2,3,4,5,6,7], "max_leaf_nodes":[3,4,5,6,7,8,9] } gs = GridSearchCV(tree, # 모델객체 선정 param_grid=params, # 하이퍼파라미터와 값들을 딕셔너리 형태로 전달 scoring=["accuracy","roc_auc","average_precision"], # 평가지표 (디폴트 : "accuracy") refit="roc_auc", # scoring 중 가장 최우선으로 삼을 기준 cv=4, # 교차검증할 fold 개수 n_jobs=-1 # 사용할 CPU개수(디폴트 : 1) -1은 모든 CPU사용한다는 의미 ) gs.fit(X_train, y_train) # 적당한 X_train과 y_train값으로 학습시킨다고 가정 print(gs.best_params_) print(gs.best_score_)=> 출력결과
{'max_depth': None, 'max_leaf_nodes': 4}
0.9406522348919737
이런 느낌으로 출력이 된다. -
RandomizedSearchCV : 위에서 설명한 GridSearchCV와 거의 같다. 다른점은 모든 조합을 검사하지 않고 설정한 개수만큼만 검사한다. n_iter라는 매개변수만 추가된 형태다.
from sklearn.model_selection import RandomizedSearchCV tree = DecisionTreeClassifier(random_state=0) params={ "max_depth":range(1,11), "max_leaf_nodes":range(3,31,3), "min_samples_leaf":[10,30,50,70,90] } rs = RandomizedSearchCV(tree, param_distributions=params, scoring="accuracy", cv=4, n_jobs=-1, n_iter=60 # 하이퍼파리미터 조합 중 몇개 선택할 것인가 (디폴트값:10) )
4) 파이프라이닝
머신러닝에서 파이프라인이란 여러 단계의 머신러닝 프로세스들을 한 줄로 묶어 한번에 실행할 수 있도록 하는 구조를 의미한다. 기본적으로 파이프라인에는 (이름, 변환기)의 튜플 형태로 프로세스들을 추가한다.
