교내 학회에서 방학동안 논문 리뷰와 함께, 간단한 toy project를 한다.
주제를 고민하던 중, 벨로그 상단에 있던 에겐/테토 개발자 유형 테스트를 만드신 내용을 보고 영감 받았다.
https://velog.io/@wkddudgk4869/출시-하루만에-트래픽-16만-사용자-3000명
나도 큐시즘이나 붙캠에서 종종 작은 서비스를 만들 때, 빠르게 유저들의 반응을 확인해 보고 싶다는 생각을 자주 했어서, 이런 유형 테스트에 관심이 많았다.
그런데 이번 toy project는 AI 학회에서 진행하는 LLM을 주제로 하는 거라, 나는 좀 다른 방향으로 LLM 모델에 에겐/테토 성향을 부여하는 실험을 하고자 했다. 페르소나 실험은 많이 되고 있지만 좀 트렌디함을 반영해보면 재밌을 것 같았다.
개인적으로 페르소나 실험을 해보고 싶었기도 했고!

여튼 그래서 간단히 그 과정을 기록해보려고 한다.
내 벨로그의 목표는 비전문가가 보더라도 이해할 수 있도록 쉽게 풀어 작성해 보는 것이다.
프로젝트 개요
- 프로젝트 과제 : LLM을 활용한 간단한 프로토타입 제작
- 프로젝트 주제 : 에겐/테토 성향의 챗봇 제작
- 프로젝트 기간: 2025.07~2025.08 (총 8주)
- 참여 인원 : 총 5명
어떻게 만들 것인가?
주제가 선정되고, "데이터 수집, 모델 선정, 학습 방법" 등에 대한 고민들을 본격적으로 시작했다.
학습 방법론 개요
본격적인 학습 방법론은 그림과 같다.
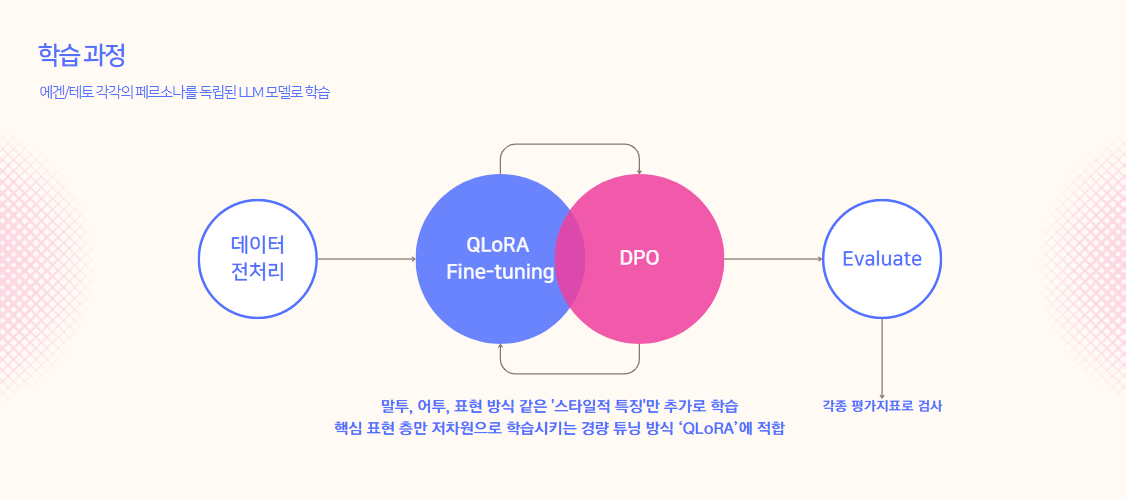
입력(instruction) → 출력(output) 형태의 지도학습 데이터로
모델이 원하는 스타일(에겐/테토)에 맞춰 반응하도록 QLoRA를 활용한 파인튜닝을 하고, DPO로 SFT로 만든 모델을 선호도 기반으로 재조정한다.
모델 후보
- 0 ~ 3B
- 7 ~ 9B
이중에 그래도 규모가 있는 7~9B 모델들, ko-gemma와 ko-Llama을 주로 학습해보기로 했다!
학습 방법론 관련 개념
요러한 프로젝트에서 모델을 학습시킨다는 것은,
이미 잘 만들어진 Base 모델에
우리가 원하는 task—(여기서는 에겐/테토 성향에 따른 대화)—를 잘 수행하도록 추가 학습하는 것이다.
Base 모델은 사전학습(pretraining)을 거친 후, 목적에 맞게 파인튜닝(Fine-Tuning) 과정을 거친다.
우리 프로젝트에서는 QLoRA 방식으로 진행하며, 이는 SFT(Supervised Fine-Tuning)에 해당한다.
1. SFT & DPO
SFT와 DPO 모두 Base모델을 추가 학습하는 방법론에 해당한다.
둘 다 모델의 가중치를 조정해 성능·스타일을 바꾸지만, 학습 신호와 단계가 다르다.
① SFT(Supervised Fine-Tuning, 지도학습)
정답(label)이 있는 데이터로 학습하는 방식
- LLM 분야에서 “파인튜닝”이라고 하면 보통 SFT를 의미한다.
정답(label)이 있는 데이터로 학습하는 방식이며, 명령문(instruction) 형태일 수도 있고 아닐 수도 있다. - 일반적으로 파인튜닝한다고 했을 때, 이 방법에 해당된다.
Supervised Fine-Tuning, 말 그대로 지도학습으로 즉, 정답이 있는 데이터로 학습하는 방법이다.
①-1 Instruction Fine-Tuning (IFT, 지시문 기반 SFT)
- 정답 데이터가 지시문 구조로 되어있다면 IFT라고 부르기도 한다.
{ "instruction": "이 문장을 영어로 번역해줘: 오늘 날씨는 맑아", "input": "", "output": "The weather is sunny today." }
①-2 기타 SFT (Non-Instruction SFT)
-
반드시 명령문일 필요 없음
-
태스크별 입력/정답 쌍으로 학습
예시 1) 번역 task
{ "source": "오늘 날씨는 맑아", "target": "The weather is sunny today." }예시 2) 감성 분류 task
{ "text": "이 영화 너무 재밌다!", "label": "positive" }
② Unsupervised / Self-Supervised Fine-Tuning
라벨(정답)이 없고, 문맥 기반 예측하는 방법
- Masked LM, causal LM 방식
- 사실상 fine-tuning개념보단 Pre-training개념에 가깝다고 할 수 있을 것 같다..
③ Preference-Based / RLHF 계열 Fine-Tuning
더 나은 응답을 만들기 위한 학습 과정
SFT로 기본 능력을 갖춘 모델을 선호도·보상 기준에 맞춰 조정하는 단계
- 주로 SFT 단계에서 모델은 지시문을 이해하고 기본적으로 태스크를 수행할 수 있는 능력을 갖춘 이후에, DPO·PPO 같은 Preference-Based Fine-Tuning이 효과를 발휘한다.
- 모델이 논리적으로 맞더라도 사용자 취향과 맞지 않으면 낮은 점수를 받을 수 있다
③-1 DPO (Direct Preference Optimization)
-
같은 프롬프트에 대해 선호(chosen) vs 비선호(rejected) 비교 학습
-
데이터셋에 이미 “이게 좋다/이건 별로”가 기록돼 있음
⇒ 모델이 주어진 선호도를 기반으로 학습
{ "prompt": "여행 가방 추천해줘", "chosen": "가볍고 튼튼한 하드케이스를 추천합니다.", "rejected": "가방은 그냥 사세요." }
③-2 PPO (Proximal Policy Optimization, RLHF)
-
RM(Reward Model) 점수를 바탕으로 학습됨
-
때문에 학습 중에도 RM이 매번 새로 점수를 계산하고, 이것이 학습에 반영됨
⇒ 모델이 선호도를 직접 계산하면서 학습
{ "prompt": "고양이에 대해 시를 써줘", "response": "하늘빛 눈동자, 부드러운 발걸음..." }
⇒ SFT와 Preference-Based Fine-Tuning은 모두 파인튜닝 범주지만, 동일 레벨이 아니라 순차 관계로 보는 게 더 적합할 듯하다.
즉, 순서: Pretraining → SFT → DPO/PPO
2 QLoRA/LoRA
SFT / DPO 같은 것은 학습 유형(무엇을 어떻게 가르칠지)이고,
QLoRA / LoRA는 학습 기법(어떤 방식으로 파라미터를 조정할지)에 해당한다.
PEFT
기존의 파인튜닝은 모델의 모든 파라미터를 업데이트하지만,
대형 LLM의 경우 연산량·메모리 사용량이 매우 크고 시간도 오래 걸린다.
때문에,
일부 모듈/추가 파라미터만 업데이트하는 방식으로 효율을 높이는 방법들을
PEFT 라고 부른다
- 장점:
- GPU 메모리 절약
- 학습 속도 향상
- 저장 용량 감소 (LoRA 어댑터만 저장 가능)
LoRA, QLoRA는 이러한 PEFT의 대표 기법들에 속한다.
일반적으로 파인튜닝이 모델의 파라미터 전체를 재학습 시킨다면, 그렇게 할 경우 오래 걸리니까, 일부만 해서 효율적으로 하고자 하는 걸 PEFT 기법이라 부르고, 이에 대표적인 방법들이 QloRA/LoRA이다.
① LoRA (Low-Rank Adaptation)
- 기존 모델의 가중치 행렬(W)에 저차원(저랭크) 행렬(A, B)을 추가해 학습
- 원본 가중치는 그대로 두고, A와 B만 업데이트
- 수식: W' = W + (A × B)
- A, B는 학습 중 업데이트
- W는 고정(freeze)
- 장점:
- 메모리·연산 효율적
- 기존 모델 파라미터를 훼손하지 않음
- 여러 태스크별 LoRA 모듈을 독립적으로 저장·적용 가능
② LoRA (Quantized LoRA)
- LoRA를 양자화(Quantization)된 모델에 적용한 기법
- 양자화:
- 모델 가중치를 16bit/32bit에서 4bit 등으로 압축해 메모리 절약
- e.g)
nf4= rmal float 4-bit 사용
- QLoRA 학습 흐름:
- 사전학습 모델을 4bit로 로드 (GPU 메모리 절약)
- LoRA 어댑터를 삽입
- LoRA 파라미터만 학습
- 장점:
- 대형 모델도 단일 GPU에서 학습 가능
- 원본 성능을 최대한 유지하면서 비용 절감
- 단점:
- 극단적인 양자화 비트수 선택 시 성능 손실 가능
이러한 이해를 바탕으로 프로젝트 수행 과정에 대한 자세한 설명은 다음 포스팅에 해보겠다! 많관부~
