딕셔너리
{key1: Value1, Key2: Value2, Key3: Value3, ...}
-> 딕셔너리 자료형
1) 대응관계를 나타내는 자료형
2) 연관 배열 또는 해시
3) Key와 Value를 한 쌍으로 갖는 자료형
4) 순차적으로 해당 요솟값을 구하지 않고, Key를 통해 Value를 바로 얻는 것이 특징
키 값이 문자면 따옴표 붙여야 함!
-> 딕셔너리 쌍 추가/삭제
1) a={1:'a'}에 {2:'b'}를 추가하고 싶다면 a[2]='b'; 라고 해주면 됨 (순차적으로 추가) 또 하고 싶으면 a['name']='pey'
2) 리스트처럼 del키워드로 삭제가능하다. del a[2]; a는 {1:'a','name':'pey'}이다.
del 쓸 때 []안에 들어가는 거 : list는 인덱스, 딕셔너리는 키 이름.
-> 딕셔너리 사용 방법
1) Key 사용해서 Value 가져오기 ex) a['name'] 하면 'pey'
리스트나 튜플, 문자열은 요소값 접근할 때 인덱싱이나 슬라이싱 기법 중 하나를 사용하는데, 딕셔너리는 Key를 사용해 Value에 접근한다.
2) 주의사항
- 딕셔너리에는 동일한 Key가 중복하여 존재할 수 없다. 만약 중복이라면? 맨 처음 키만 인정됨. 다른 중복키들 무시됨.
- key로 구분하기 때문에 리스트나 튜플처럼 순서 없음
- 리스트는 값이 변할 수 있어 Key로 사용할 수 없음. 그러나 Value로는 사용 가능함.
-> 딕셔너리 관련 함수
1) keys - Key 리스트 만들기
- key만 모아서 dict_keys 객체를 리턴한다.
- 리스트처럼 사용할 수 있지만, 리스트 관련 함수 (append,insert,pop,remove,sort등)는 사용 불가하다 -> 당연함. 딕셔너리는 배열같은 게 아님.
- 사용 방법 예시) a={'k1':'pey','k2':'apple','k3':'bana'}; a.keys() 하면 dict_keys(['k1','k2','k3']) 반환.
- dict_keys()를 list로 변환할 수 있음 ex) list(a.keys()) 하면 ['k1','k2','k3']
2) values - value 리스트 만들기 - value만 모아서 dict_values 객체를 리턴한다.
- 위에서 key설명한 거와 같은 방식 ex) a.values() 하면 dict_values(['pey','apple','bana'])
3) items - key, value 쌍 얻기 - key와 values의 쌍을 튜플로 묶어 dict_items 객체를 리턴한다.
- 위에서 key, value 설명한 거와 같은 방식 ex) a.items() 하면 dict_items([('k1':'pey'),('k2':'apple'),('k3':'bana')])
4) clear - key:value 쌍 모두 지우기 - 딕셔너리 내의 모든 요소 삭제
- 빈 딕셔너리는 {}로 표현 ex) a.clear(); a하면 {}출력
5) in - 해당 키가 딕셔너리 안에 있는지 조사하기 - Key가 딕셔너리 안에 존재하면 True, 존재하지 않으면 False 리턴 ex) 'k1' in a; 하면 true출력, 'k' in a; 하면 False출력
6) get - key로 value 얻기 - key에 대응되는 value를 리턴한다.
- ex) print(a.get('k1'))하면 'pey'출력된다.
- 그렇다면 a['k1']과 a.get('k1')의 차이점은? get함수는 해당 키가 존재하지 않을 때 None를 리턴한다는 점이 오류를 내는 a['k1']과 다르다
- key 값이 없을 경우 미리 정해 둔 디폴트 값을 대신 가져오도록 지정 ex) a.get('nokey','sorry') 하면 None 대신 sorry출력
-> 실습 문제 중 볼만한 거

일단 딕셔너리는 key로 구분하기 때문에 인덱스가 있을수가 없음. print(x[2][2])는 함정을 가지고 있다. 첫번째 [2]는 key가 2인 value를 보자는 것이고 두번째 [2]는 그 value에서 2번째 인덱스 값을 보자는 것이다. 그래서 5가 출력된 것. C언어에서는 절대 이렇게 일차원적으로 접근 못 함 보면 볼수록 파이썬 대괄호는 신기한 듯?
집합(set)
s1 = set([1,2,3])
-> 집합 자료형
1) set 키워드를 사용하여 생성
- set()에 리스트를 입력하여 생성 ex) s1=set([1,2,3]); s1은 {1,2,3}
- set()에 문자열을 입력하여 생성 ex) s2=set("Hello"); s2는 {'e','H','l','o'}
-> 특징
1) 중복을 허용하지 않음
2) 순서가 없음. 리스트나 튜플은 순서가 있어 인덱싱을 통해 요솟값을 얻지만 set자료형은 순서가 없기 때문에 인덱싱 사용 불가. (딕셔너리와 유사)
3) 인덱싱 사용을 원할 경우 리스트나 튜플로 변환 필요 (list(), tuple() 함수 사용)
ex) s1=set([1,2,3]); l1=list(s1); l1은 [1,2,3] 또는 l1=tuple(s1); l1은 (1,2,3)
-> 교집합, 합집합, 차집합
1) 교집합은 '&'기호나 intersection() 함수 사용 ex) s1=set([1,2,3,4,5]); s2=set([4,5,6,7,8]); s1&s2는 {4,5} 또는 s1.intersection(s2)는 {4,5}
2) 합집합은 '|'기호나 union() 함수 사용 ex) s1|s2는 {1,2,3,4,5,6,7,8} 또는 s1.union(s2)는 {1,2,3,4,5,6,7,8}
3) 차집합은 '-' 기호나 difference() 함수 사용 ex) s1-s2는 {1,2,3}이고 s2-s1은 {6,7,8} 또는 s1.difference(s2)는 {1,2,3}
-> 집합 자료형 관련 함수
1) add - 값 1개 추가하기 ex) s1.add(4); s1은 {1,2,3,4}
2) remove - 특정 값 제거하기 ex) s1.remove(2); s1은 {1,3,4}
3) update - 값 여러 개 추가하기 ex) s1.update([4,5,6]); s1은 {1,2,3,4,5,6}
-> 실습 문제 볼만한 거 
중복되어 있는 list a 중복 없애기 위해 set()을 사용함.
불 자료형(bool)
참(True)과 거짓(False)을 나타내는 자료형 / 조건문의 반환 값으로도 사용됨 (1==1 은 True)
-> 자료형의 참과 거짓
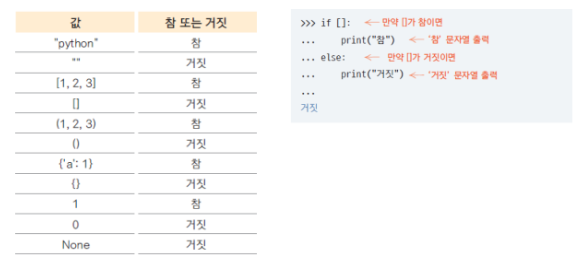
위 표를 보면 알 수 있듯이 "",[],{},(),0,None는 모두 거짓이다. []같은 게 거짓인지 참인지 헷갈리면 그 옆에 if문 보이는 거처럼 사용해봐도 좋을듯하다.
-> 불 연산
1) bool() 함수
- 자료형의 참/거짓을 식별하는 내장 함수 ex) bool('python') 은 True
2) type() 함수 - 자료형을 확인 할 수 있는 함수 ex) a=True; type(a)는 <class 'bool'>
변수
변수명 = 변수에 저장할 값
1) 변수란
객체를 가리키는 것이라고 할 수 있음. 객체는 자료형과 같은 것으로, [1,2,3] 값을 가지는 리스트 데이터가 자동으로 메모리에 생성되면 변수 a는 [1,2,3]의 주소를 가리킨다
2) id() 함수
id() 함수를 통해서 메모리 주소를 확인할 수 있음 ex) id(a)는 4303029896
3) 리스트 복사 (깊은 복사 - 바로대입)
- a=[1,2,3]; b=a; id(a)와 id(b)는 동일하다. id대신 a is b; 또는 a[1]=4; a출력,b출력을 비교하는 것으로도 깊은 복사가 되었는지 확인할 수 있다.
4) 리스트 복사 (얕은 복사 - 슬라이싱, copy) - a=[1,2,3]; b=a[:]; a[1]=4; a는 [1,4,3]이고 b는 [1,2,3]이다. 즉, 얕은 복사
from copy import copy(copy 모듈에 있는 copy 함수 import하고) a=[1,2,3]; b=copy(a); b하면 a와 동일한 값 가지지만 b is a하면 false 나온다
