개요
실시간 채팅 기능 구현 중 카카오톡처럼 메시지를 읽지 않은 사람의 수가 메시지 옆에 작게 숫자로 표시되도록 하고 싶었습니다. 그럴려면 누가 어떤 메시지를 읽었는지 DB에 저장 해놓을 필요가 있었습니다.
이 과정에서 DB에 저장되는 방식을 수정하여 성능개선을 한 사례를 공유하고자 합니다.
🤔 누가 어떤 메시지를 읽었는지 어떻게 알 수 있을까?
각각의 메시지에 해당 메시지를 읽은 유저의 id 를 저장하는 방식
-
처음에 생각한 방식은 메시지 테이블에
read_user라는 필드를 둬서 각각의 메시지를 어떤 유저가 읽었는지 저장하도록 하는 방식으로 접근했습니다.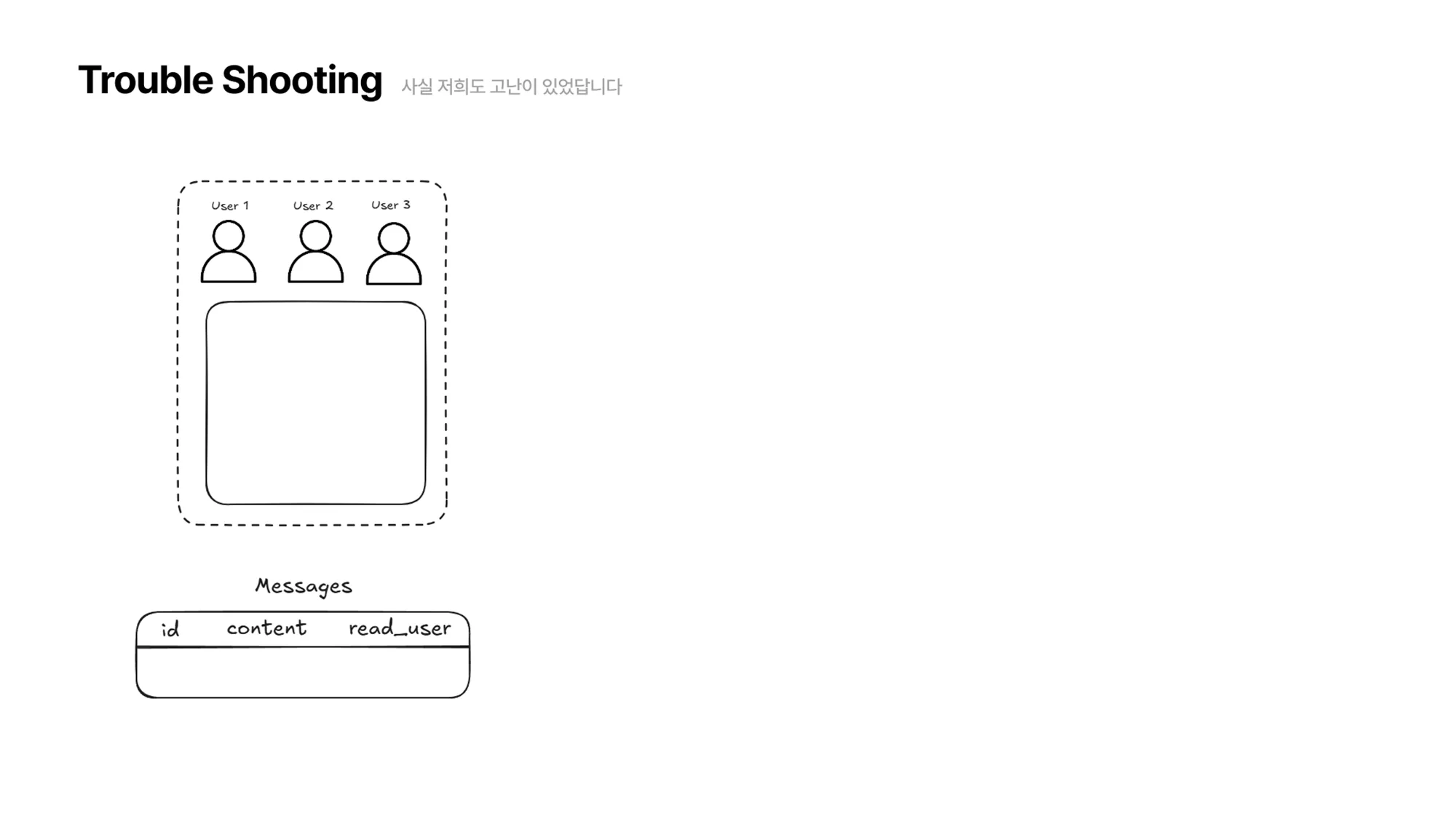
-
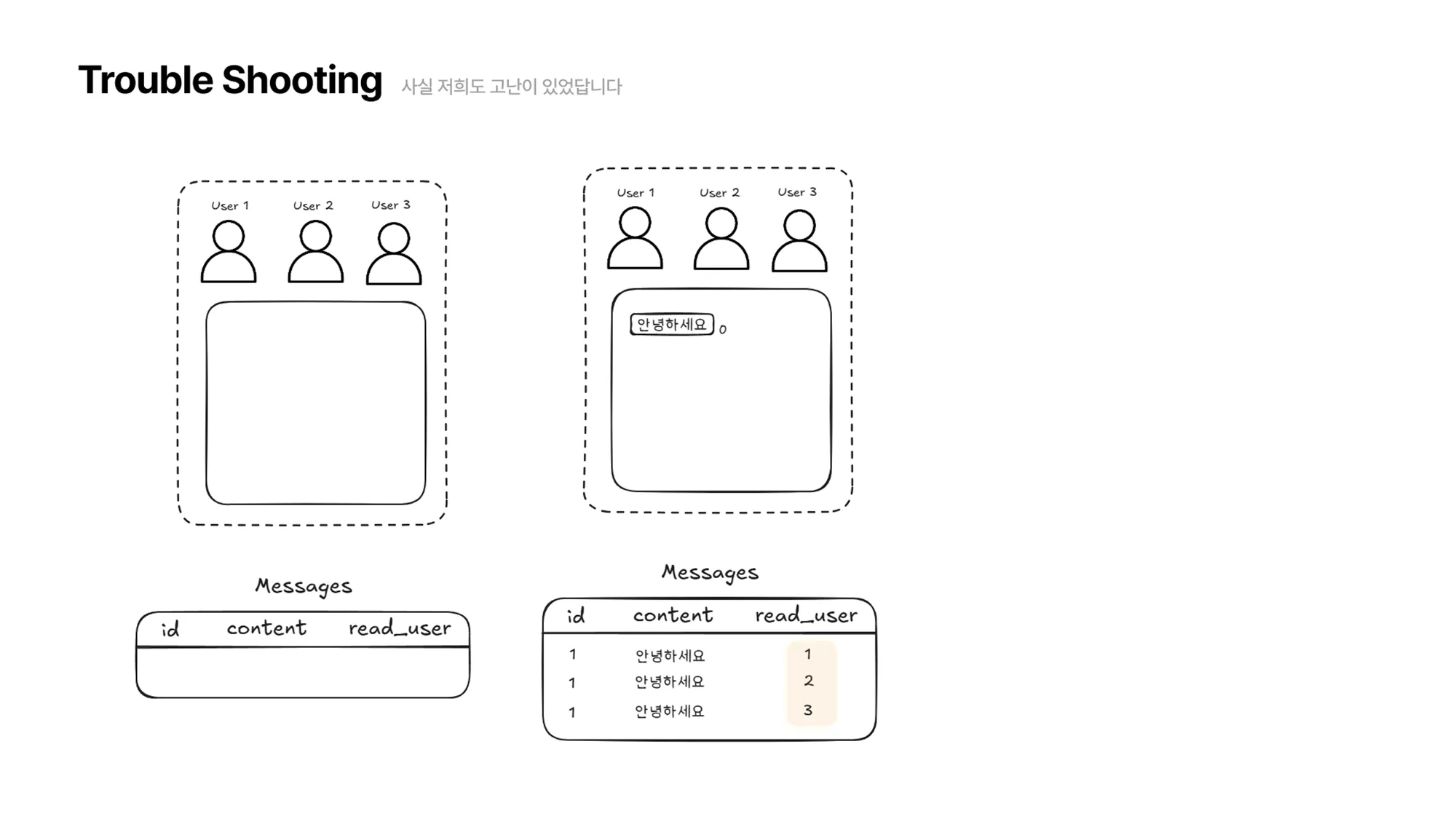
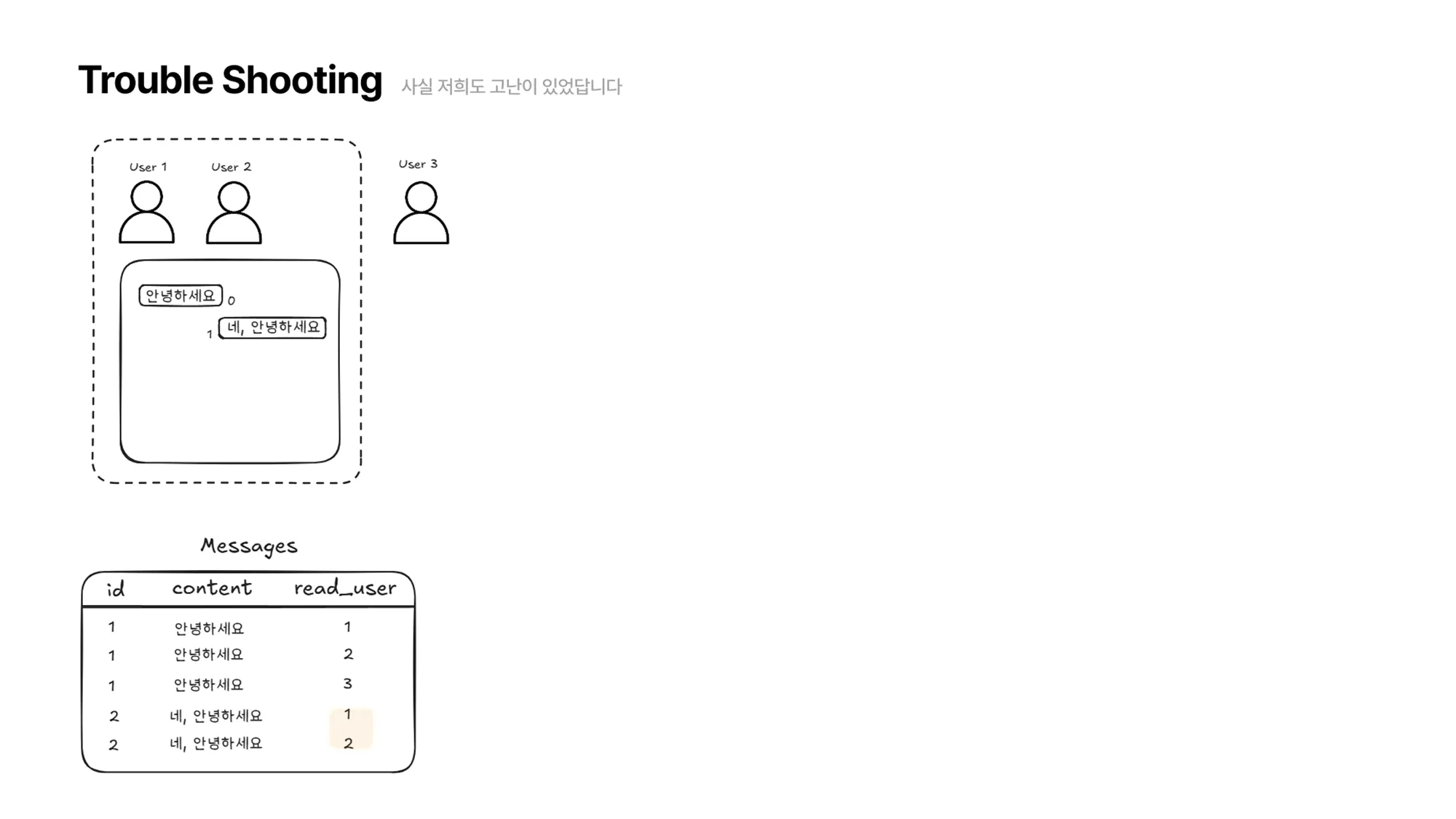
아래 그림에서, User1,2,3 이 채팅방에 접속해있고, 누군가 “안녕하세요”라는 메시지를 보냈습니다. 현재 User1,2,3 이 모두 해당 메시지를 읽었으므로 메시지 테이블은 그림과 같이 업데이트됩니다.
-
그리고 잠시 User3이 채팅방을 닫고 다른 걸 하러 갔다고 가정해봅시다.
-
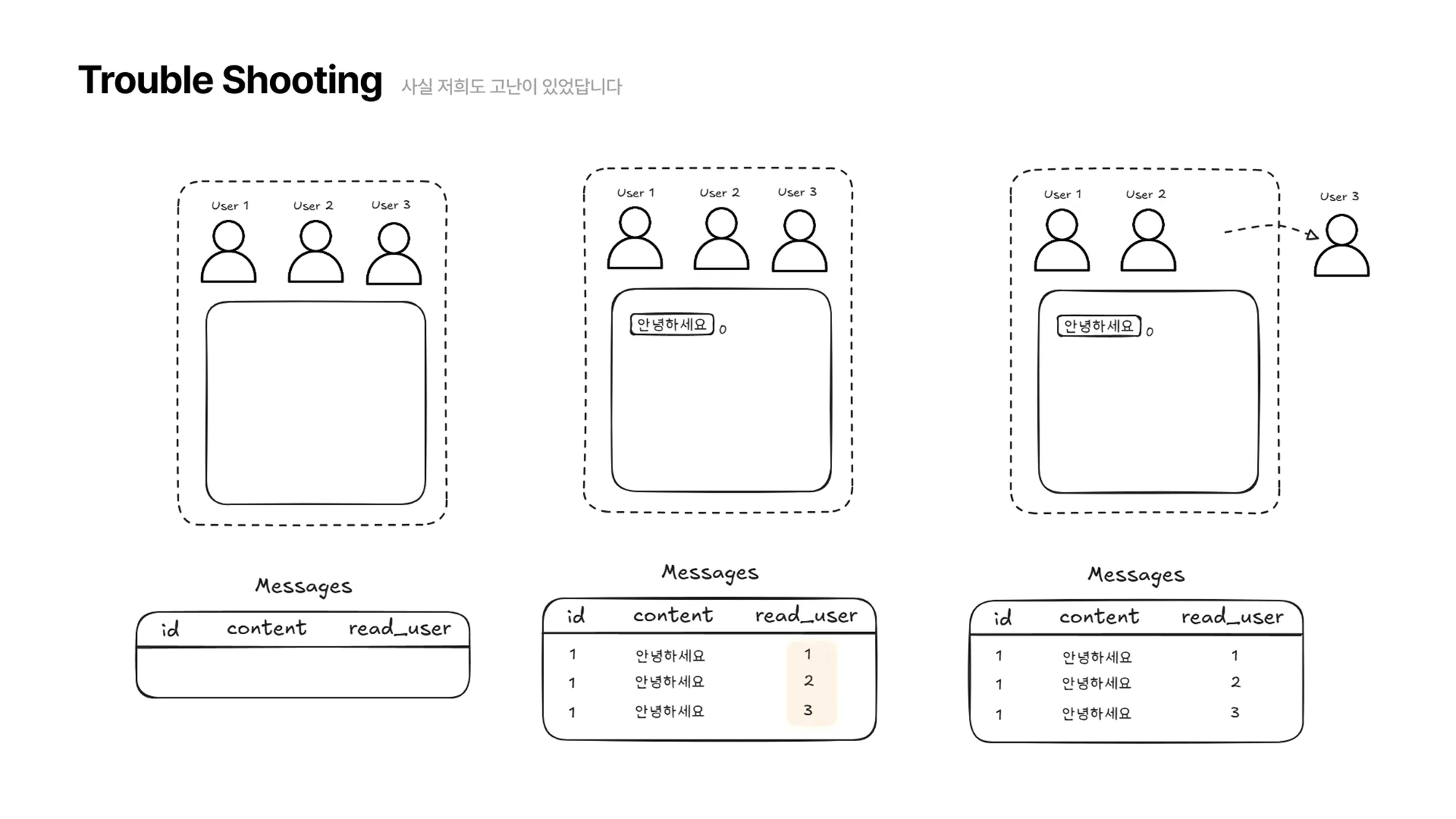
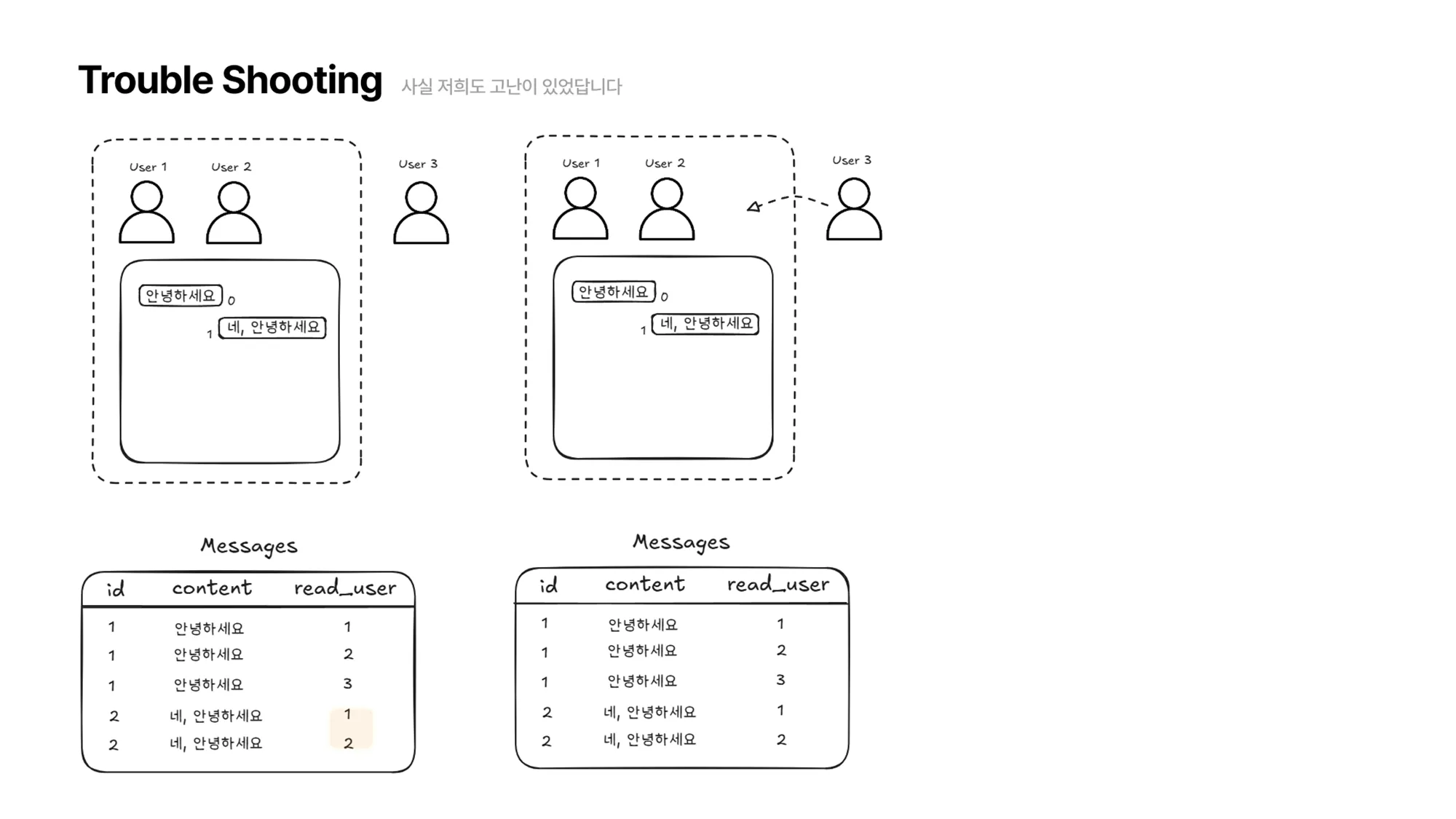
User3이 자리를 비운 사이 “네, 안녕하세요”라는 메시지가 왔습니다. 그럼 채팅방에는 User1,2 만 접속해 있기 때문에 메시지 테이블은 다음과 같이 업데이트 됩니다.
-
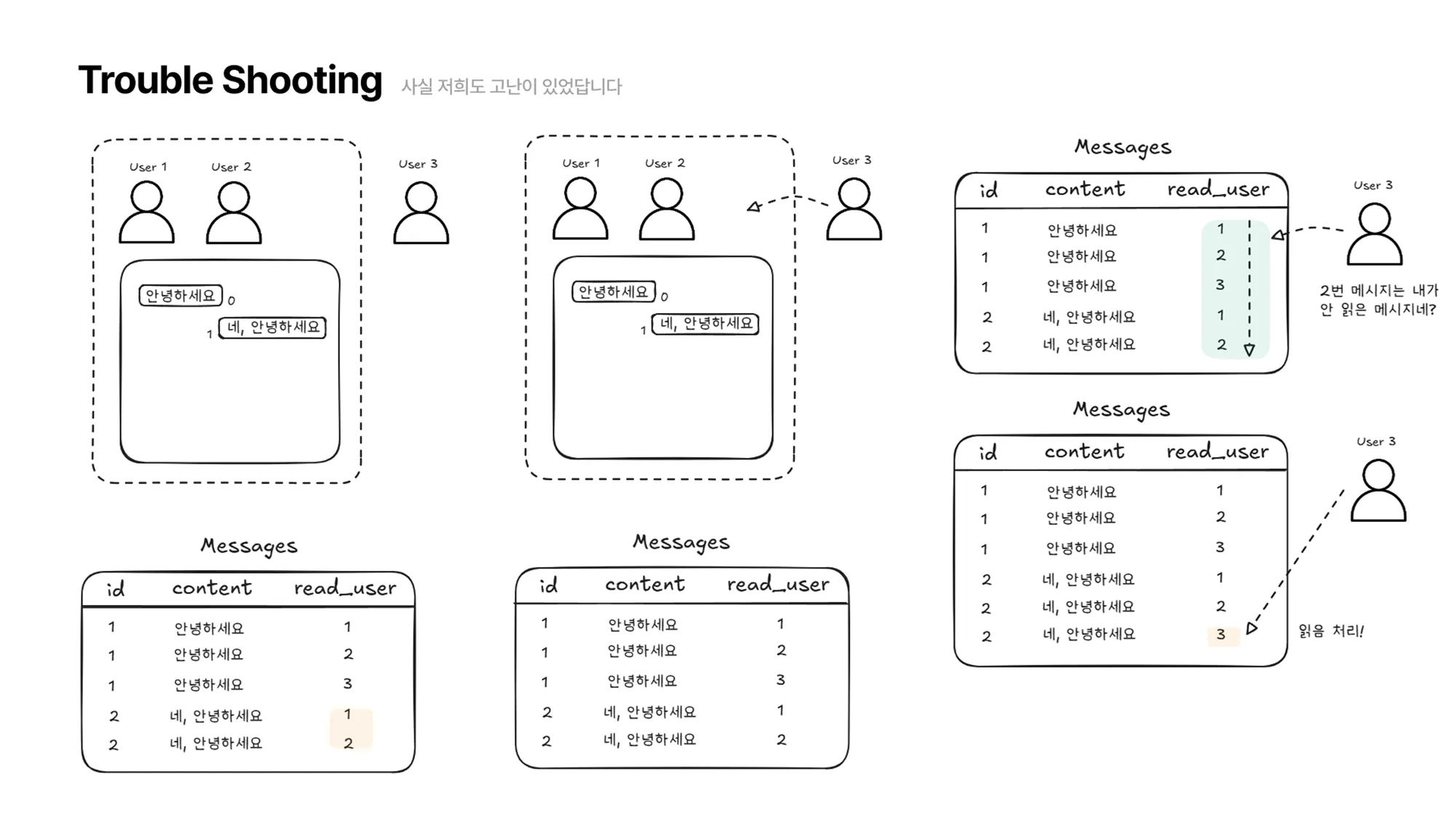
여기서 User3이 다시 채팅방에 접속하면 메시지 읽음 처리를 하기 위해 메시지 테이블의 첫 번째 메시지부터 자신이 읽지 않은 메시지가 있는지 탐색해야 합니다.
-
아래 그림에서 보이듯이 2번 메시지는 User3 이 읽지 않았기 때문에 2번 메시지에 대해 User3을 추가하여 읽음 처리를 해줍니다.
-
이 방식은 두 가지 문제점이 있습니다.
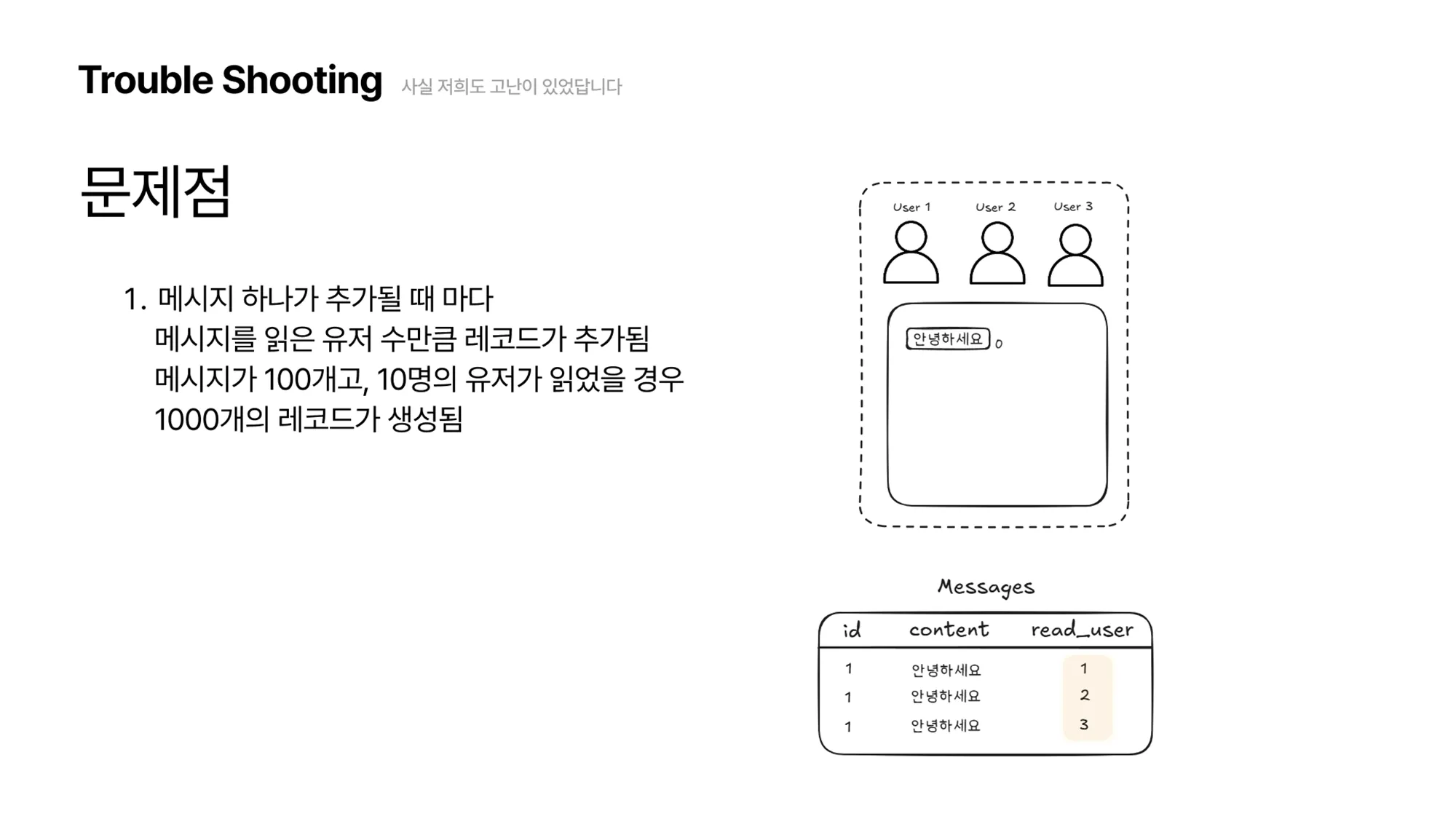
- 첫 번째 문제점은 메시지 하나가 추가될 때마다 메시지를 읽은 유저 수만큼의 레코드가 추가로 생성된다는 것입니다.그림에서 보이듯이 하나의 메시지를 3명의 유저가 읽었을 경우 3개의 레코드가 생성되는데요. 만약 메시지가 100개고, 10명의 유저가 모든 메시지를 읽었을 경우 1000개의 레코드가 생성되는 것입니다.
- 두 번째 문제점은 유저가 채팅방에 다시 접속할 때마다 메시지 읽음 처리를 하기 위해 항상 처음부터 메시지를 탐색해야 한다는 점입니다.

따라서 첫 번째 문제점으로 인해 공간 복잡도 측면에서 좋지 않고, 두 번째 문제점으로 인해 시간 복잡도 측면에서 좋지 않습니다.
예를 들어
read_user필드가 Int(4byte) 타입을 사용한다고 했을 때, 메시지가 100개고, 10명의 유저가 모든 메시지를 읽었다면read_user필드의 레코드만 해도 약 4KB 의 공간이 사용됩니다.즉, 채팅방에 유저의 수가 많을 경우, 메시지 개수가 많아질수록 테이블 사이즈가 매우 빠르게 증가하는 문제가 있습니다.
- 첫 번째 문제점은 메시지 하나가 추가될 때마다 메시지를 읽은 유저 수만큼의 레코드가 추가로 생성된다는 것입니다.
🔍 해결 방법
-
위 문제의 핵심은 각각의 메시지가 자신을 읽은 유저의 id를 저장하기 때문에 발생합니다. 그럼 반대로 유저가 자신이 마지막으로 읽은 메시지 id 를 저장하도록 하면 어떨까요?
메시지 id가 오름차순으로 저장되는 특성을 이용해서 10번 메시지를 마지막으로 읽었다면 그것보다 id가 작은 메시지는 모두 읽은 것이라고 가정하는 것입니다. 이렇게 하면 읽음 처리를 할 때 10번 메시지보다 id가 큰 메시지들만 읽음 처리를 수행하면 이 문제를 개선할 수 있습니다.
한번 동일한 예시로 비교를 해보겠습니다.
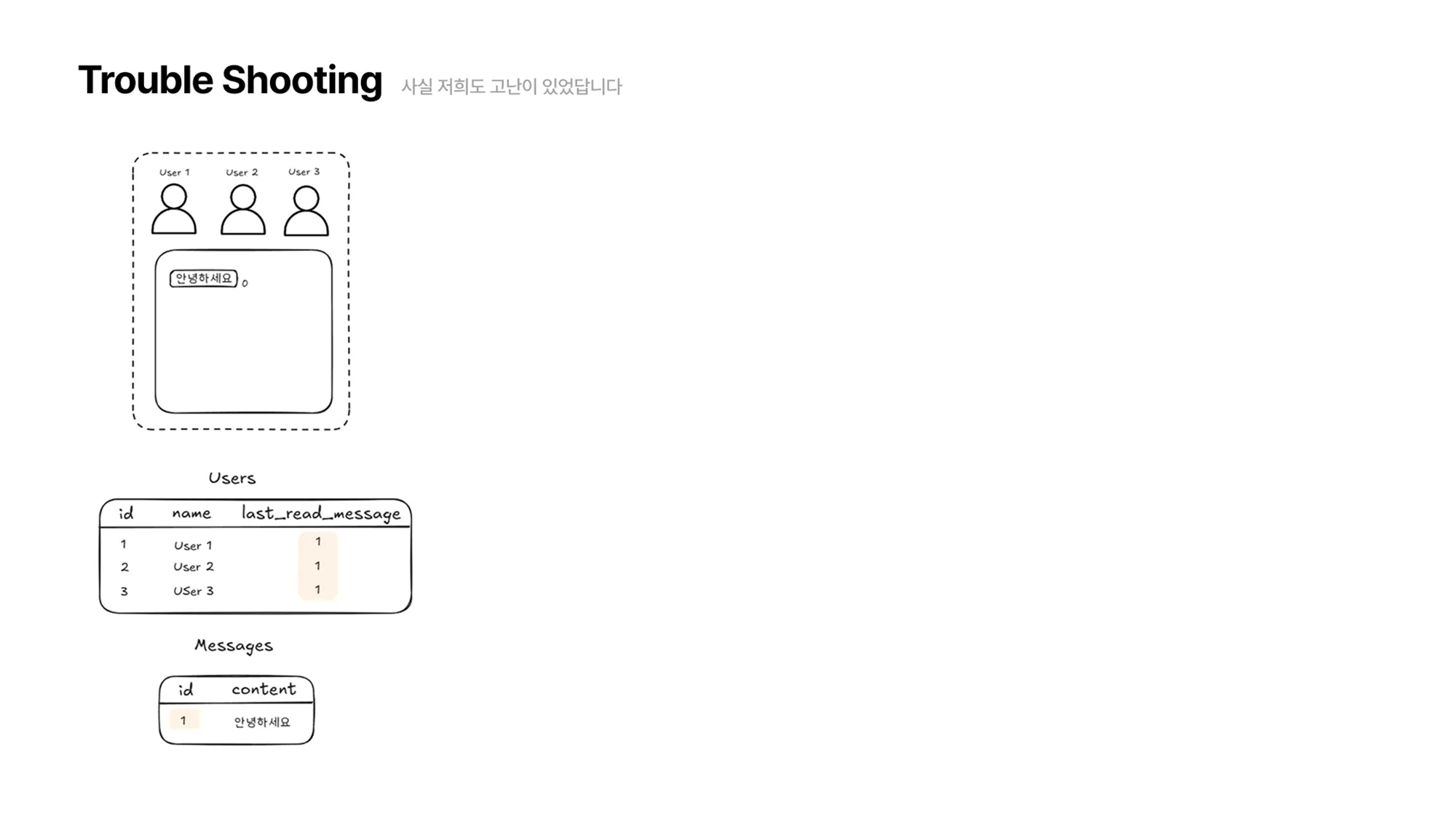
이전과 마찬가지로 User1,2,3이 채팅방에 접속해있습니다. 그 상태로 “안녕하세요” 라는 메시지가 전송됩니다.
메시지가 추가되었으므로 메시지 테이블이 업데이트 되고, 유저가 마지막으로 읽은 메시지가 변했으니 유저 테이블도 업데이트 됩니다.
이전 방식과의 가장 큰 차이점은 메시지 테이블에 레코드가 ‘한 개 씩’ 추가된다는 점입니다.
-
User3이 잠시 채팅방을 닫고 다른 걸 하러 갑니다.
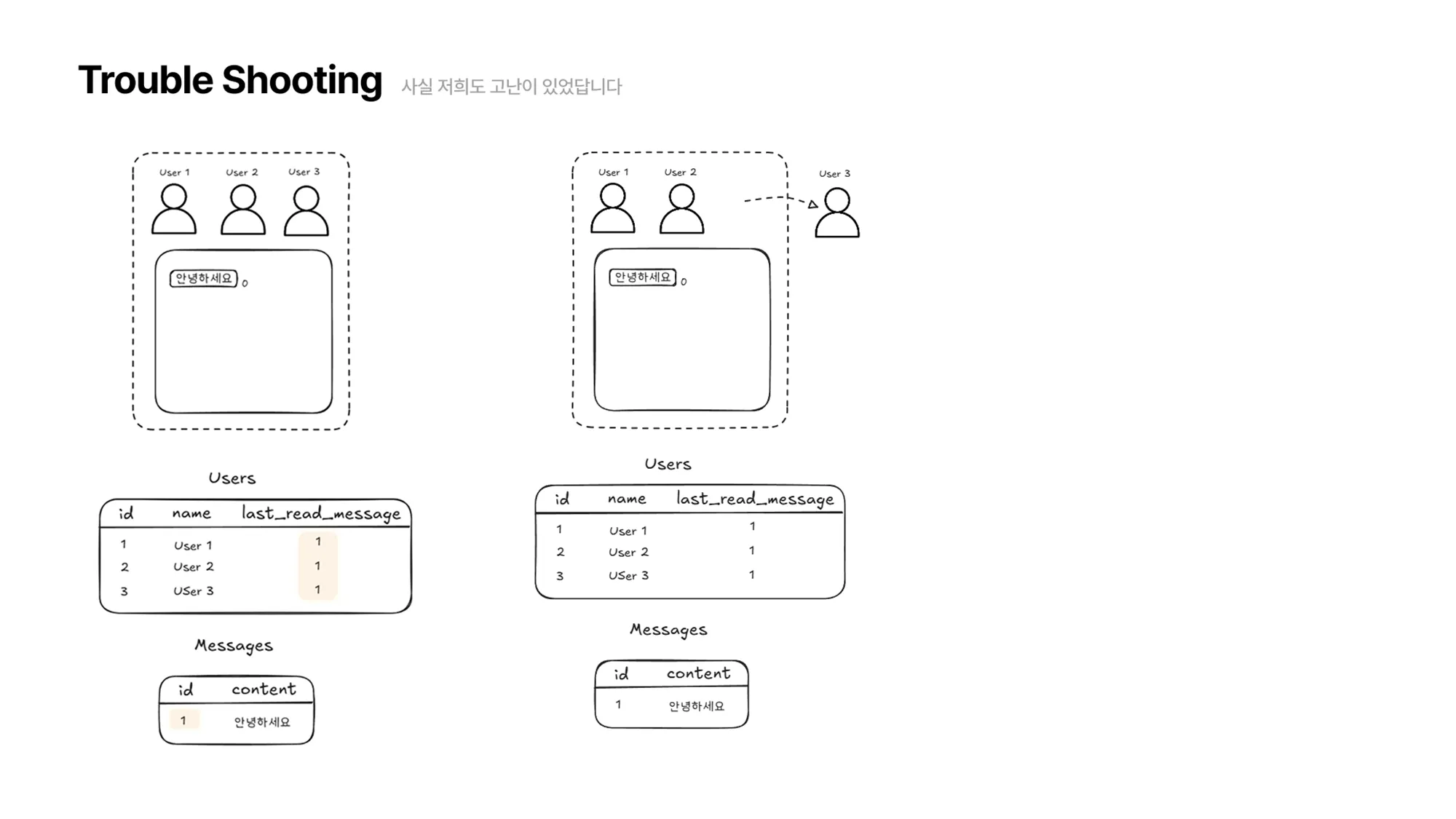
-
그 사이 “네, 안녕하세요” 라는 메시지가 전송됩니다.
User1,2 가 채팅방에 접속해있기 때문에 User1,2 의
last_read_message가 업데이트 되고, 메시지 테이블에 “네, 안녕하세요” 메시지가 추가됩니다.이때도 마찬가지로 레코드는 하나만 추가됩니다.
-
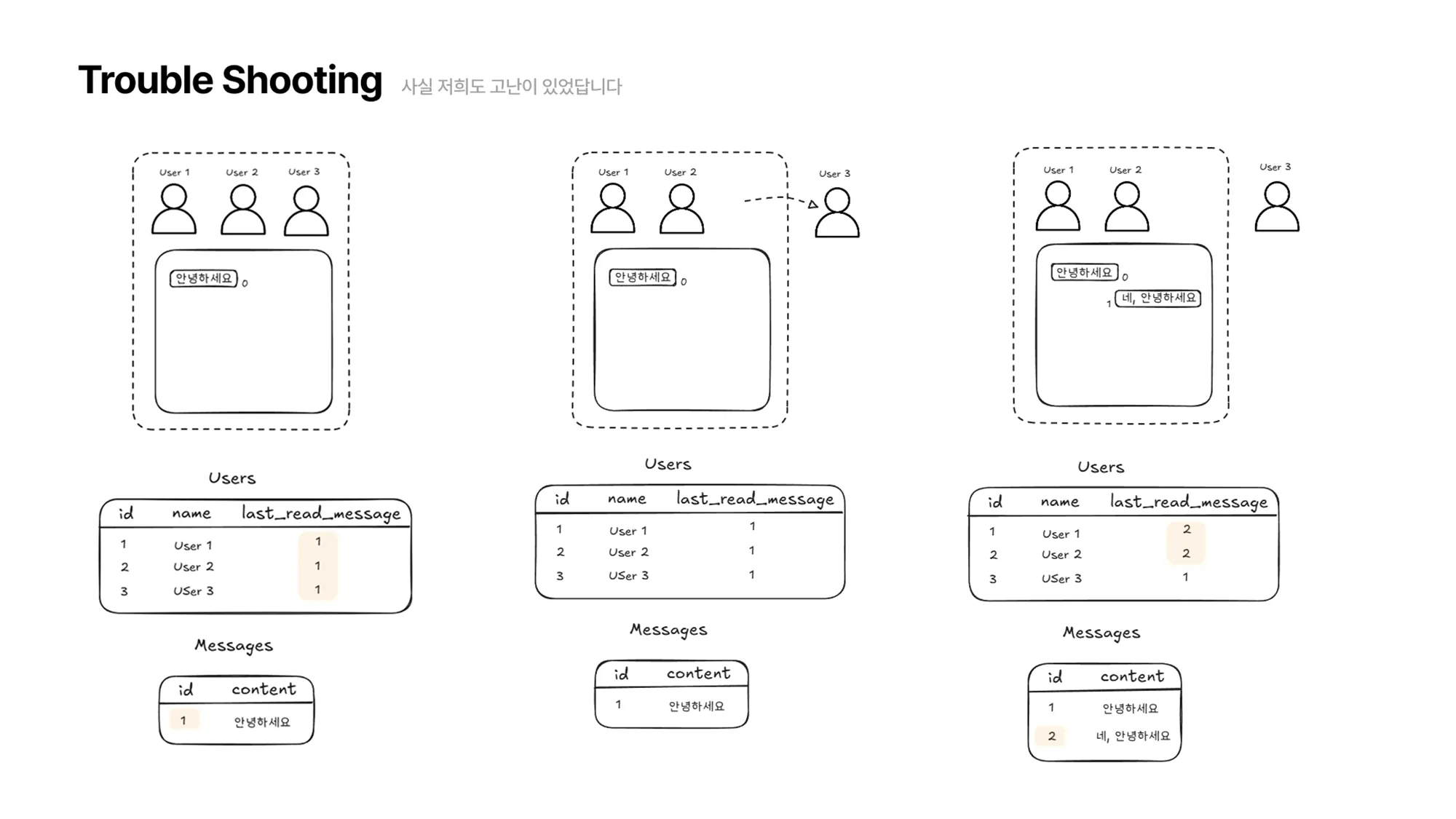
다시 User 3이 채팅방에 접속합니다.
-
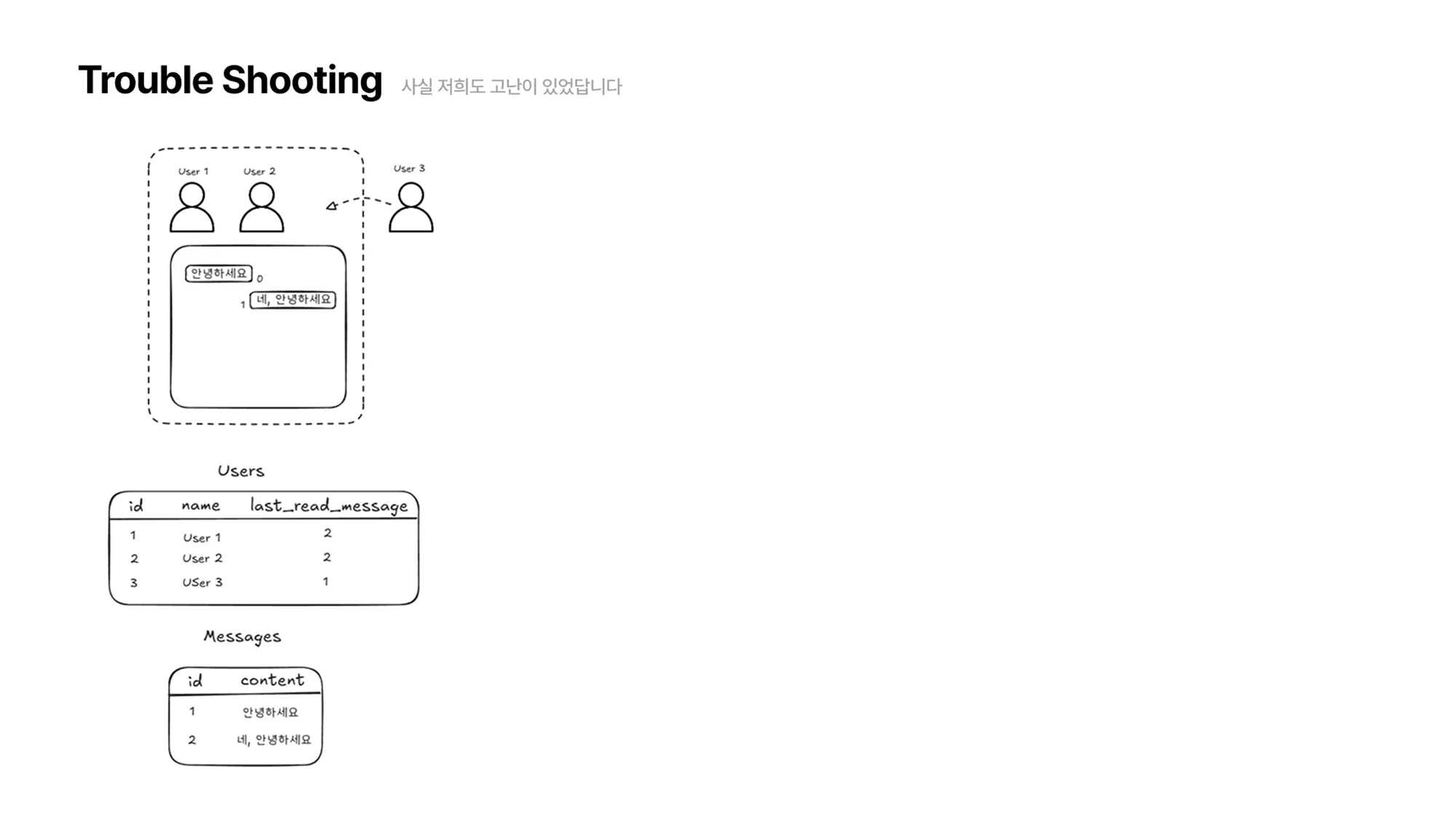
그럼 다음과 같이 User3의
last_read_message를 확인해서 그 다음 메시지부터 탐색을 수행하고, User3의last_read_message를 갱신하면 읽음 처리가 완료됩니다.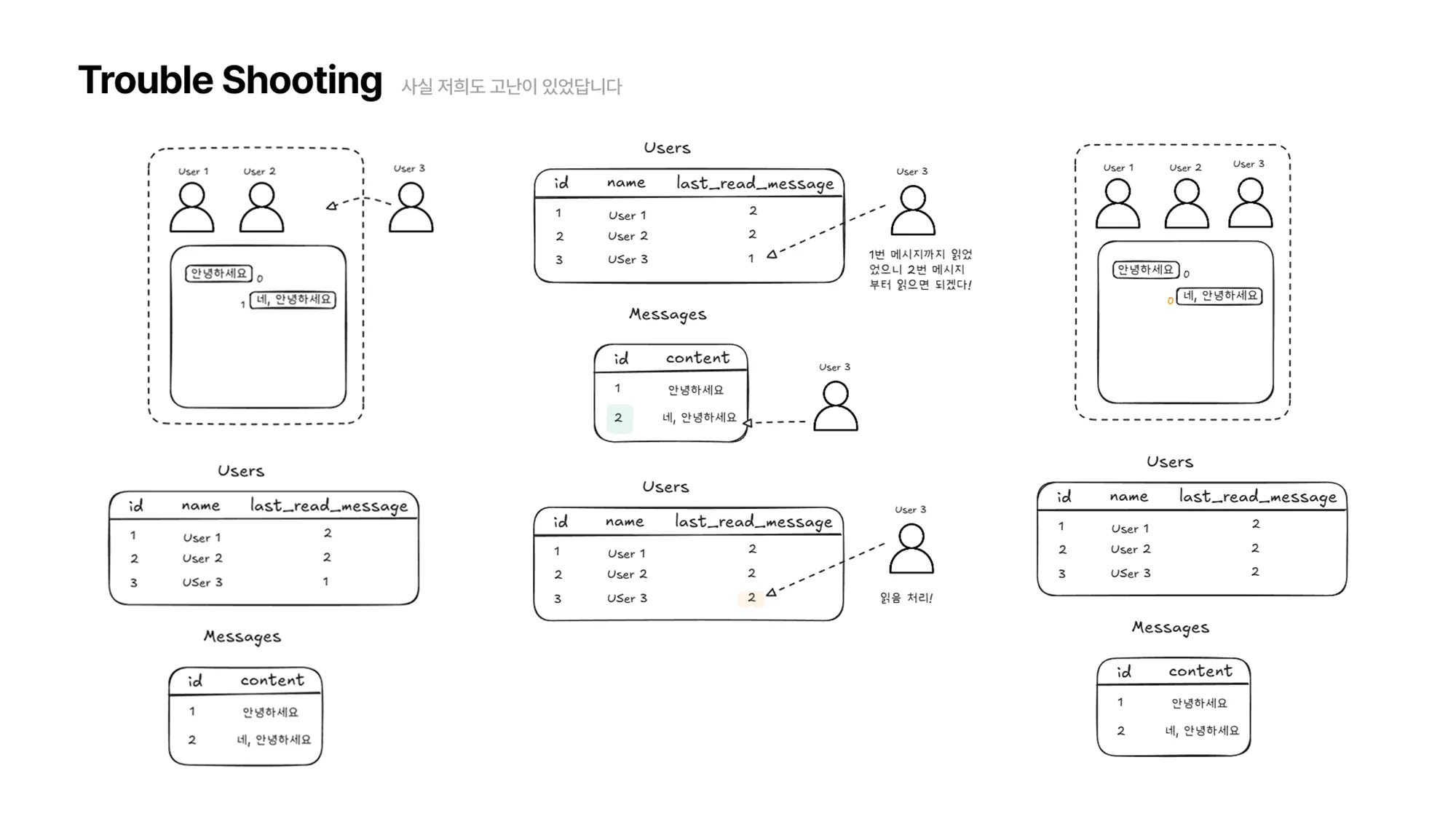
-
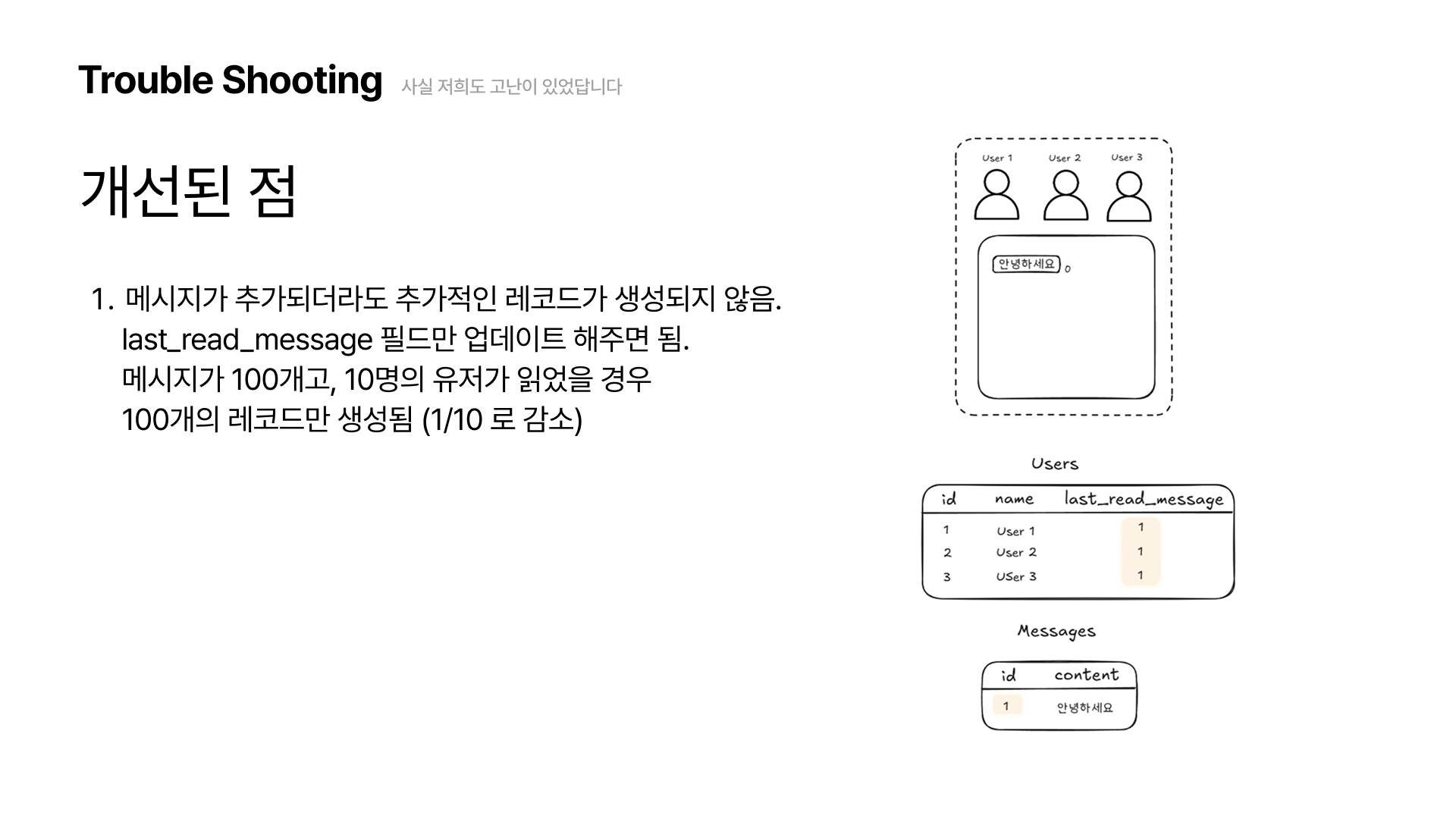
개선된 점은 메시지가 추가되더라도 메시지 레코드를 한 개 씩만 생성해주면 된다는 점입니다. 만약 100개의 메시지가 있고, 10명의 유저가 모든 메시지를 읽었을 경우 총 100개의 레코드만 추가됩니다. 몇 명의 유저가 메시지를 읽든 레코드는 메시지의 수 만큼만 추가됩니다.
첫 번째 방식에 비해 1/10로 줄었죠.
-
또한 유저가 채팅방에 다시 접속했을 때 읽음 처리를 위해 처음부터 메시지를 확인할 필요가 없어졌습니다.
last_read_message의 다음 메시지부터 확인하면 되죠.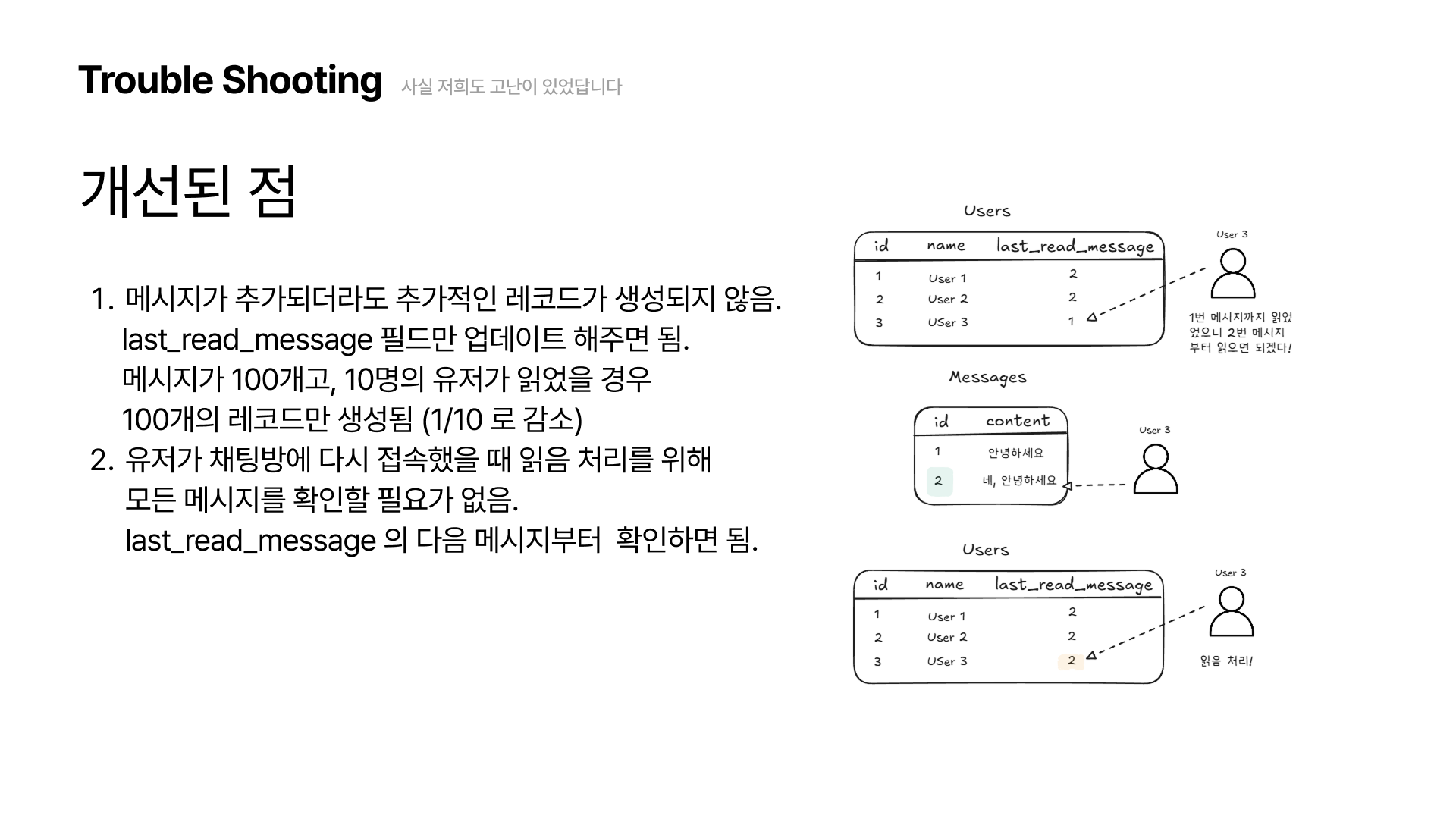
이를 통해 시간 복잡도 측면에서나 공간 복잡도가 다음과 같이 개선되었습니다.
따라서
last_read_message필드가 Int(4byte) 타입일 때, 메시지가 100개고, 10명의 유저가 메시지를 모두 읽었다면 440byte만 사용하면 됩니다.4,000byte 에서 400byte로 월등히 개선되었음을 알 수 있습니다.
🎯 결과
따라서 이전 방식에 비해 월등히 작은 메모리 공간을 사용하고, 유저가 채팅방에 다시 접속 했을 때 모든 메시지를 읽을 필요가 없으므로 시간적인 측면과, 저장 공간 측면에서 성능을 개선할 수 있었습니다.
before
after
