
내가 바로 써먹기 위한 LGBM 속성, 야매 글입니다.
자세한 설명은 생략한다
LGBM은 무엇인가?
LGBM은 Light GBM이다. Light하다는 것은 속도가 빠르고, 적은 메모리를 이용한다고 생각하면 된다. 당연히 GPU 가속기를 이용할 수 있다.
GBM은 Gradient Boosting Machine이다. 잔여오차(residual error)에 가중치를 gradient descent로 진행한다
kaggle 코드를 보면, regression과 classification에서 거의 LGBM을 사용하여 높은 LB(Leader Board)에 있는 것을 알 수 있다. 이제까지 배운 linear/logistic regression은 효율이 안좋다.
가끔 시계열 문제(Time series)에서도 회귀로 접근하여 LGBM을 사용하는 것도 볼 수 있다.
예제. 분류 (유방암 진단하기)
Dataset은 이곳에서 다운받을 수 있다. (로그인 하면 다운로드 가능)
1. 데이터 확인 및 EDA (EDA는 생략)
사실 EDA 작업은 정말로 중요하다. 이 글은 야매글이니까....
pandas의 DataFrame을 이용하여 csv 파일을 읽어오자.
그리고 df.shape, df.info()로 데이터의 크기, 정보를 확인하자.
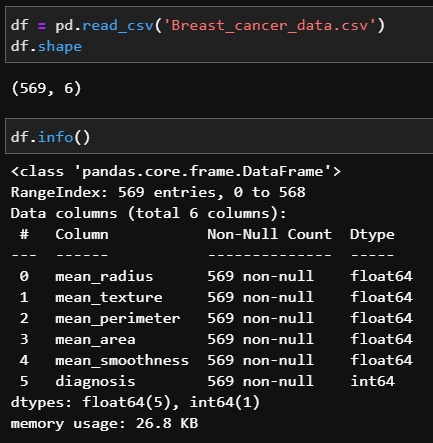
df.shape로 데이터의 크기가 (569, 6)임을 알 수 있다. 이 데이터는 csv파일이므로 feature가 6인 데이터가 569가 있다고 해석하자.
df.info()로 데이터 자료형을 확인하자. 전체 데이터는 569인데 Non-Null Count역시 569이므로 비어있는 데이터가 없다는 것을 알 수 있다.(매우 좋은 데이터이다. 대부분 비어있는 데이터를 처리하는 작업(e.g. 0이나 False로 채우기)도 필요하다). 데이터 5번 column만 정수이고 나머지는 실수형이다.
df.head()로 데이터 일부분을 확인하자. ()안에 숫자가 없으면 기본적으로 5개를 보여준다.
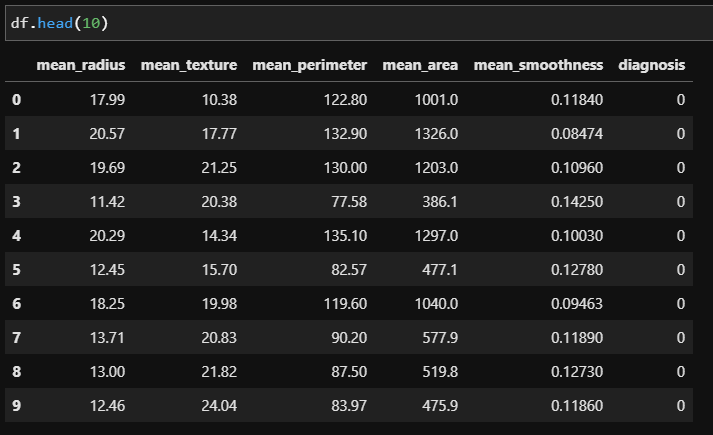
5번째 column은 diagnosis이므로 column이 0~4까지가 feature임을 알 수 있다. (실제로 어떤 feature는 유방암 진단에 영향을 안 줄 수도 있다. 자세한 데이터 분석은 EDA로 열심히 파악해야 한다. 이부분은 skip)
2. 데이터셋 만들기
이제 이 데이터에서 실제로 유방암과 아닌것의 개수를 확인해보자
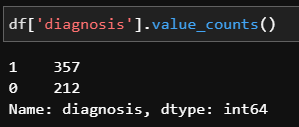
질병데이터의 경우, 잘못하면 질병의 데이터가 매우 적어서 학습하기 곤란한 경우가 있는데, 이 경우 데이터셋을 구성할 때 음성인 데이터의 일부만 사용하여 데이터셋을 구성한다.
우리의 경우, 그래도 양성/음성의 개수가 비슷한 편이므로 그대로 데이터셋을 구성하자.
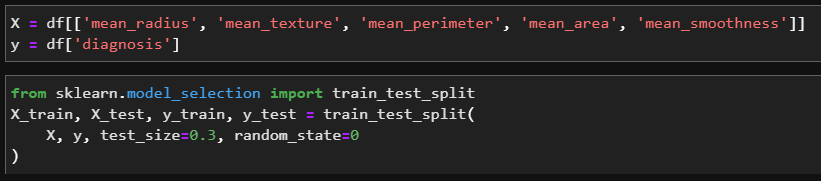
주어진 데이터에서 30%는 test set으로 분리시키자.
(보통 train/test는 8:2로 분리하지만 이 데이터셋이 1000개도 못넘는 작은 데이터라서....)
3. 모델 생성 및 학습
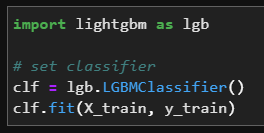
clf.fit()로 모델을 train한다.
4. 결과 확인
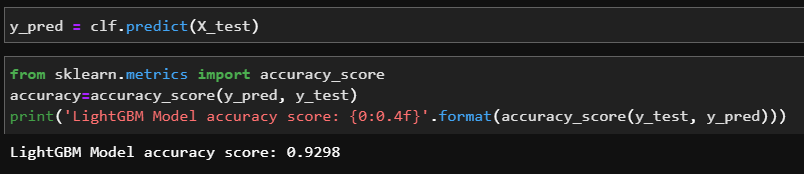
test_set에서 약 93%의 정확도를 보여주었다.
overfitting인지 확인해보자
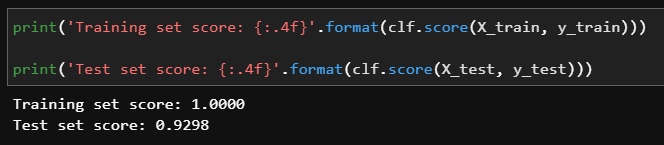
train_set에서 100%, test_set에서 93%이므로 overfitting에서 벗어난 듯 하다.
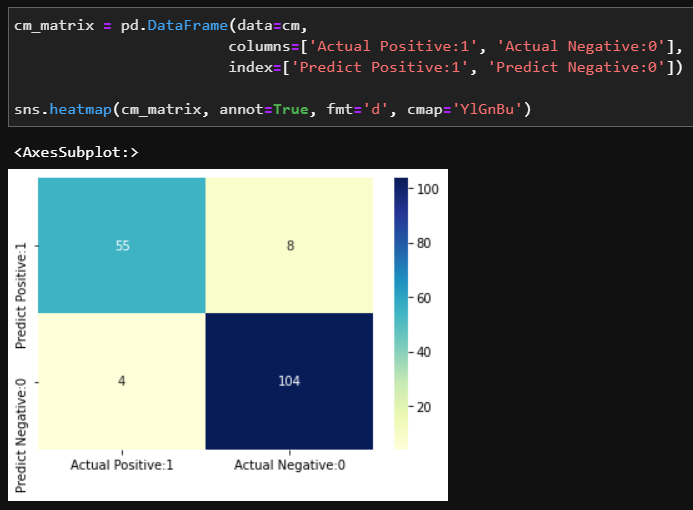
분류 문제이므로 confusion matrix로 어떤 경우를 잘 분류했는지 확인해보자
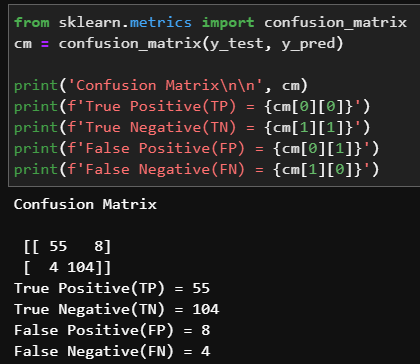
12(=8+4)개의 경우를 제외하고 잘 분류한 것을 알 수 있다.
색칠해서 시각화해보자.
model tuning
위에서 모델을 생성할 때 lgb.LGBMClassifier()로 간단히 생성했었다.
원래 LGBM 모델을 생성할때는 다음처럼 생성한다.
링크
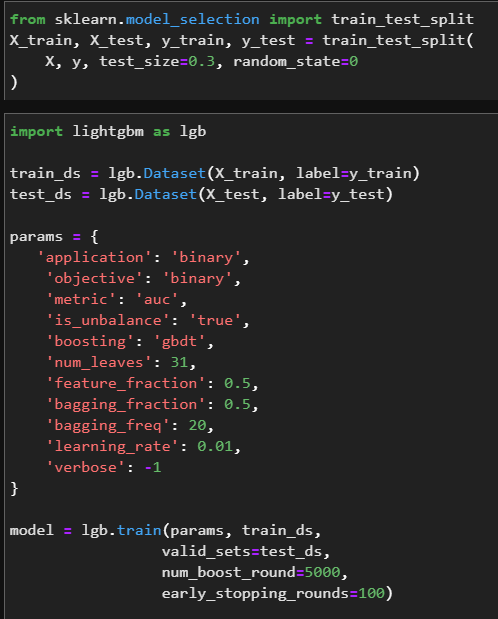
import lightgbm as lgb
train_set = lgb.Dataset(X_train, label=y_train)
# X_test 대신에 X_val(for validation)도 가능하다
test_set = lgb.Dataset(X_test, label=y_test)
params = {
'num_leaves': 80,
'objective': 'regression',
'min_data_in_leaf': 200,
'learning_rate': 0.02,
'feature_fraction': 0.8,
'bagging_fraction': 0.7,
'bagging_freq': 1,
'metric': 'l2',
'num_threads': 16
}
model = lgb.train(params, train_set, num_boost_round=MAX_ROUNDS,
test_set, early_stopping_rounds=125, verbose_eval=50)
y_pred = model.predict(X_test)
왜냐하면 params로 hyperparameter를 튜닝할 수 있기 때문이다.
Parameters Documents
params은 dict의 형태이어야 한다.
자세한 parameter tuning은 구글링, document를 보자 (이 글은 야매글이다)
parameter tuning을 해보자
objective는 회귀라면 regression, 분류라면 binary, multiclass를 사용하면 된다.
metric은 분류모델에서 binary_logloss나 auc를 이용한다.
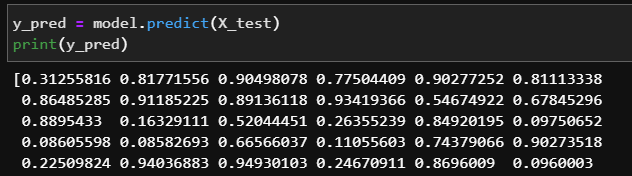
y_perd는 확률을 나타낸다. y_pred의 threshold를 0.5로 하여 0.5보다 넘으면 1(Treu)로 세팅하자
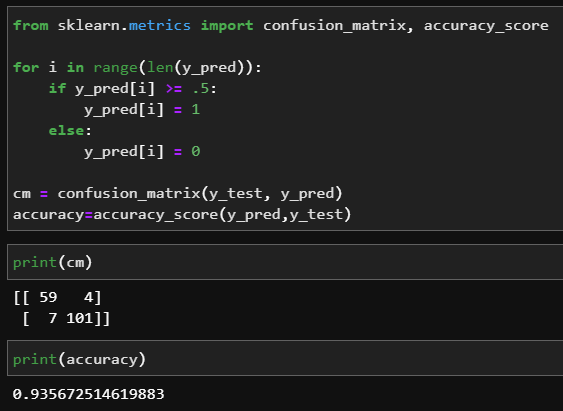
정확도는 93.5%로 조금 좋아졌다.
Reference
