

Kaggle, Dacon 또는 실제 모델링을 하다보면 feature를 여러개 추가해서 학습을 하게 된다. 이때, feature가 너무 많으면 오히려 학습에 방해되는데 필요없는 feature들은 제거하는 것이 좋다. 이때 어떤 feature를 살리고 버려야 할까?
결정트리모델의 경우, 블랙박스 모델이 아니기 때문에 XAI기법 몇 가지를 이용하면 feature의 중요도를 알 수 있다.
이 글은 feature importance를 구하는 식은 제외하고 간단히 뜻과 사용방법만 대해 논한다.
1. Gain / Split
XGBoost에는 Weight, Gain, Cover 3가지 feature importance를 제공하는데, LightGBM은 Gain, Split 이렇게 2가지를 제공한다.\
# model: 이미 학습이 완료된 LGBMModel, or Booster
# FEATURES: model 학습에 사용된 모든 features
# PATH: 그림을 저장할 경로
# SPLIT
ax = lgb.plot_importance(model, max_num_features=len(FEATURES), importance_type='split')
ax.set(title=f'Feature Importance (split)',
xlabel='Feature Importance',
ylabel='Features')
ax.figure.savefig(f'{PATH}/fi_split.png', dpi=300)
# GAIN
ax = lgb.plot_importance(model, max_num_features=len(FEATURES), importance_type='gain')
ax.set(title=f'Feature Importance (gain)',
xlabel='Feature Importance',
ylabel='Features')
ax.figure.savefig(f'{PATH}/fi_gain).png', dpi=300)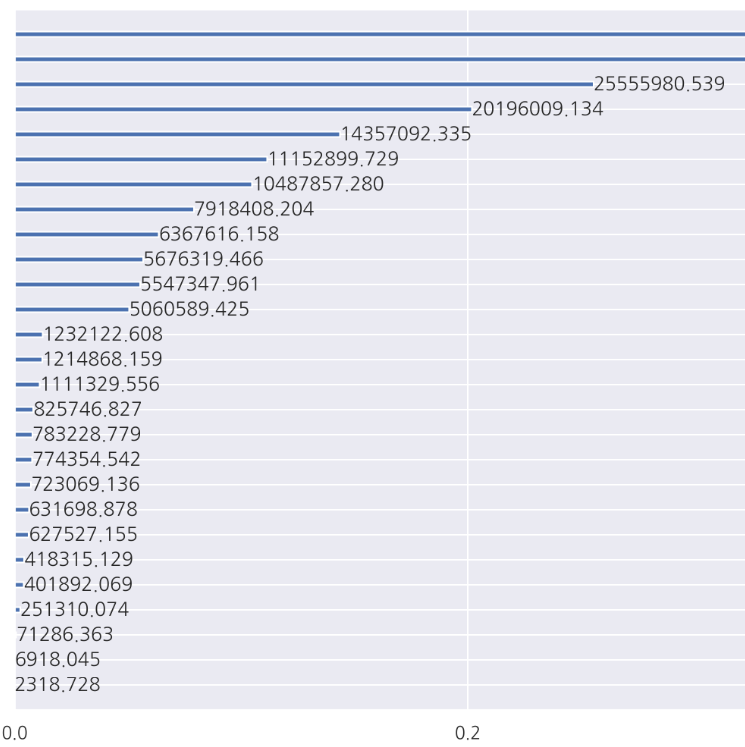 (그림이 잘렸지만, score가 너무 커서 xtick에 을 곱해야 한다)
(그림이 잘렸지만, score가 너무 커서 xtick에 을 곱해야 한다)
해석 및 이용
gain, split로 feature importance를 계산할 경우, 어떤 feature가 중요한지는 알 수 있지만, 그 평가 방식이 다르기 때문에 피쳐의 중요도가 다를 수 있다. 대부분 feature의 일관성이 유지되기 때문에 gain, split 모두 중요도 점수가 떨어진다면 제외하는 것을 고려할 수 있다.
같은 방식으로 gain, split 모두 중요도 점수가 높다면 버리지 않는 것을 고려할 수 있다.
이 feature importance는 점수의 영향이 양의 영향인지, 음의 영향인지 알 수 없다는 단점이 있다.
2.SHAP (shapely value)
게임이론을 바탕으로 각 feature가 점수에 기여한 정도를 계산한 방식이다. gain, split와 달리 양/음의 영향도를 알 수 있다. (음의 영향이 크다고 나쁜 것이 아니다. 영향이 큰 것이 중요하다)
import shap
shap.initjs()
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
fig = shap.summary_plot(shap_values, X_test)
plt.savefig(f'{PATH}/shap.png', dpi=300, bbox_inches="tight")원래 shap value를 계산할 때는 test data를 이용하지만, testset을 이용할 수 없을 경우 validset을 사용해도 된다. (모델이 보지 않은 dataset을 넣어야 하는 것 같다)
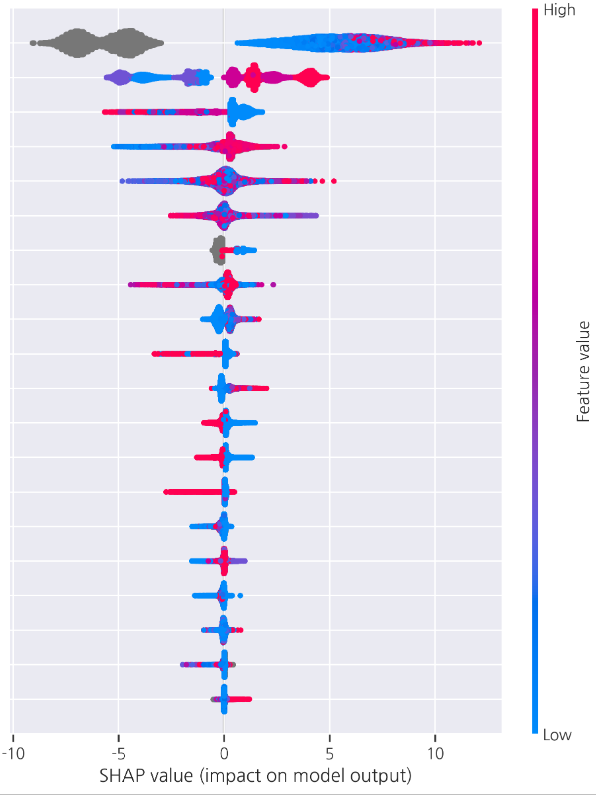 (변수 이름은 가렸다)
(변수 이름은 가렸다)
해석 및 이용
SHAP 그래프는 자동적으로 맨 위 feature가 중요하다. 중요한 feature 일수록 SHAP value의 범위가 넓다.
3. Permutation Importance
permutation importance는 특정 feature를 무작위로 섞어 성능 손실에 얼만큼 영향을 주는지 계산한다. 성능이 크게 안좋아지면 해당 feature는 중요도가 높다고 해석할 수 있다.
코드는 아래 캐글을 참고했다.
Permutation Importance - Kaggle
from eli5.lightgbm import *
from eli5.sklearn import *
import eli5
perm = PermutationImportance(model, random_state=42).fit(X_valid, y_valid)
print(eli5.format_as_text(explain_weights.explain_permutation_importance(perm, feature_names = features, top=40)))
explain_weights.explain_permutation_importance(perm, feature_names = features, top=47)
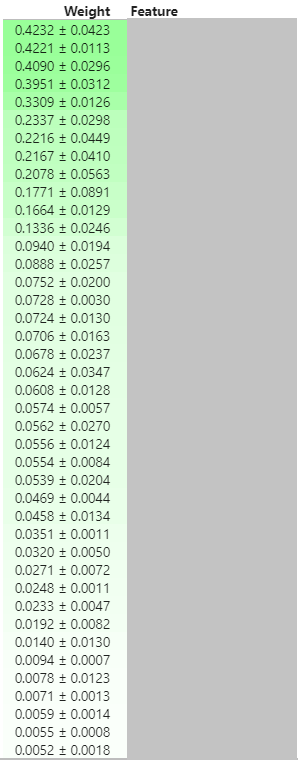 (feature 이름은 가렸다)
(feature 이름은 가렸다)
해석 및 이용
짙은 녹색일 수록 중요도가 높고, 흰색일 수록 중요도가 낮다고 해석할 수 있다. 간혹 빨간색이 나오는 경우가 있는데, feature를 섞었을 때 오히려 점수가 높아지는 경우이다. 사실상 우연에 의한 것이므로 중요도가 높지 않다는 반증이다.
4. 종합적인 해석 및 이용
인턴을 하면서 실제 사용한 순서는 다음과 같다.
- 모든 feature를 사용하여 모델을 학습한다. ()
- permutation importance
- SHAP value
- 상위 20개의 feature만 나올 것이다
- 2)과 3)를 고려하여 40~50%의 feature를 base로 삼는다. 그리고 모델을 재학습한 후 metric score를 기록한다. ()
- base feature에서 하나씩 넣어보며 모델을 재학습시킨다.
- 이 때는 importance를 계산하지 않고 오로지 metric의 점수만 본다. ()
- 보다 좋은 중에서 제일 좋은 feature를 최종적으로 선택한다.

도움이 됐습니다 감사합니다~