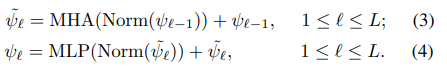
전편에서 이어집니다.
5. Method + 코드 리뷰
이번 파트에서는 TS TCC논문에서 나온 TS TCC가 어떻게 동작하는지와, 코드에 대해서 분석하겠습니다.
코드:https://github.com/emadeldeen24/TS-TCC
논문:https://arxiv.org/pdf/2106.14112.pdf
이번 포스팅에선 논문의 내용 번역과 함께 논문의 내용이 되는 코드를 분석하기 때문에 매우 길어질 수 있음을 양해바랍니다.
논문의 내용과 코드 리뷰가 섞여 있을 거라, 논문의 내용은 굵은 글씨로 나타겠습니다.
깃허브의 코드를 클론해오면 다음과 같은 모습을 볼 수 있습니다.
main.py는 프레임워크를 돌리는 메인 파일입니다.
utils.py에는 모델의 일부 파라미터를 훈련가능하게 만드는 함수와, 에포마다 지나간 시간을 계산하거나, 로그를 남기는 등 편의기능에 대한 함수가 구현되어 있습니다.
trainer 폴더 안에는 trainer.py가 들어있으며 main.py로부터 arguments들을 받아 supervised나 self-supervised등 의 옵션으로 훈련시키는 파일입니다.
model에는 basemodel이 정의되어있는 model.py와 TS TCC의 메인 기능이 구현되어있는 TC.py, NT-cross entropy가 구현되어있는 loss.py, 어텐션과 트랜스포머, 그리고 시계열 데이터에 맞게 트랜스 포머를 개조한 seq_transformer가 정의된 attention.py가 있습니다.
dataloader에는 논문에 사용되었던 총 네가지의 데이터셋인 Epilepsy, HAR, sleep-EDF, pFD 데이터셋을 불러와 데이터 변조를 가한 후 데이터 로더에 담는 파일이 있습니다.
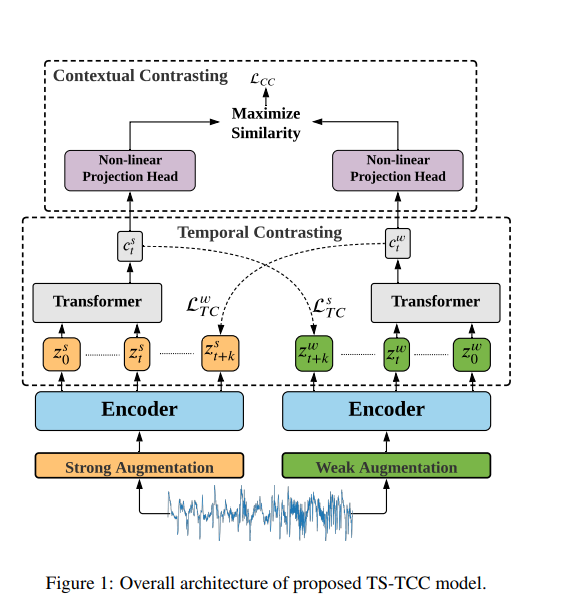
Figure1: TS-TCC 모델의 전체적인 구조
위 그림은 모델의 전체적인 구조를 도식화한 것입니다. 먼저 원본 신호가 있고, 그 신호를 강한 증대기법과 약한 증대기법을 적용합니다. 서로 다른 증대기법을 적용한 신호를 인코더에 통과시킨 것을 Z Z라고 정의합니다.
무작위 시간t를 기준으로 t이후 고정 타임스텝 k만큼인 Z~Z+k와 Z~Z+k의 신호와 Z~Z, Z~Z의 신호를 교차시켜 예측합니다. 이것을 cross-view prediction이라고 논문에서 소개하고 있습니다.
이러한 cross-view prediction을 통해 얻은 두 값을 L 와 L로 정의합니다. 이 값이 Temporal Contrasting에 관한 항이 되며, 최종 로스 식에 계수 , 에 곱해져 최종 로스값이 됩니다.
는 위쪽 박스인 Contextual Contrasting에 관련된 계수로 0~t사이의 신호를 트랜스포머에 통과시킨 텐서인 C와 C를 비선형 프로젝션 헤드에 통과시켜 값을 구하고, 그 값에 를 더하여 최종 로스를 만들어냅니다.
아래는 논문의 3.method의 일부를 번역한 내용입니다.
이 섹션에서는 우리의 TS-TCC를 자세하게 설명하겠습니다. 그림 1과 같이, 우리는 처음에 입력 데이터를 두개의 상호 연관된 데이터 뷰를 만들어냅니다. 그 다음, temporal contrasting 모듈은 자가회귀 모델을 이용하여 데이터의 시간적인 정보를 찾아냅니다. 이 모델은 서로 다른 데이터의 과거 데이터로 부터 미래 데이터를 예측하는 힘든 크로스-뷰 예측을 수행합니다. 우리는 contextual contrasting 모델을 통해 자가회귀 모델의 합의?(agreement)를 극대화합니다.. 다음, 우리는 하위 섹션의 각 요소에 대해 소개하겠습니다.
In paper, 3.1 Time-Series Data Augmentation
이 부분에서는 데이터 증대 기법에 대해 다룹니다.
데이터 변조는 대조 학습의 가장 중요한 포인트입니다. 대조학습은 같은 샘플에서 나온 뷰의 유사도를 최대화하고, 다른 샘플에서 다온 뷰의 유사도를 최소화 하도록 훈련됩니다. 그래서 대조학습에 적합한 데이터 변조 방법은 아주 중요합니다. 일반적으로 대조학습은 두(혹은 무작위)개의 변조를 사용합니다.
샘플 를 생각해 봅시다. 샘플 는 다른 데이터 변조를 거쳐 와 가 됩니다. 이 데이터는 같은 패밀리인 로 취급합니다. 다시말해, 와 는 패밀리에 속한다는 것입니다.
그러나, 우리는 다른 데이터 변조 방식이 특징을 배우는 데 있어 견고함을 향상시킬 수 있다고 논의했습니다. 결과적으로, 우리는 데이터 변조를 두 방식으로 나눴습니다. 첫 번째 것은 약한 변조, 두 번째 것은 강한 변조라고 하겠습니다. 이 논문에서의 약한 변조는 jitter-and-scale 방법입니다. 우리는 무작위 상수를 신호에 더하거나, 신호의 진폭에 무작위 상수를 곱합니다.
강한 변조를 우리는 permutation-and-jitter 방법이라고 하겠습니다. 퍼뮤테이션, 즉 순열은 신호를 최대 개 이내의 무작위 숫자개수의 구역으로 나누고, 그 구역을 섞는 것입니다.그 다음, 무작위 지터링이 섞인 신호에 더해집니다.
주목할 점은, 데이터 변조의 하이퍼 파라미터는 시계열 데이터의 특성에 따라 신중하게 정해야 한다는 것입니다. 예를 들어, 시계열 데이터에서의 값을 정할 때에는 긴 길이의 시계열 데이터의 값이 짧은 길이의 시계열 데이터의 값보다 커야 할 것입니다. 비슷하게, 정규화된 데이터에서의 지터링 비율이 정규화 되지 않은 데이터에서의 지터링 비율보다 작아야 할 것입니다.
**
각각의 입력 샘플 마다, 우리는 강한 변조를 받은 데이터를 , 약한 변조를 받은 데이터를 이라고 할 것입니다. 즉, 는 이고, 는 이 될 것입니다. 이러한 데이터들은 인코더로 들어가 고차원의 은닉된 특징을 추출하게 됩니다. 특별히, 인코더는 [Wang이 2017년에 연구한] 3개의 블록을 가진 컨볼루션 구조를 가지고 있습니다.
입력 신호 x에 대해, 인코더는 x를 고차원의 은닉 특징 벡터인 z=(x)를 추출하게 됩니다. z = [, , ,....]로 정의하겠습니다. T는 총합 타임스텝이 됩니다. 에 대해, d는 feature의 길이가 됩니다. 우리는 를 강한 변조를 받은 뷰, 를 약한 변조를 받은 뷰라고 할 것입니다. 이러한 뷰들은 temporal contrasting 모듈에 입력이 됩니다.
def DataTransform(sample, config):
weak_aug = scaling(sample, config.augmentation.jitter_scale_ratio)
strong_aug = jitter(permutation(sample, max_segments=config.augmentation.max_seg), config.augmentation.jitter_ratio)
return weak_aug, strong_aug
def jitter(x, sigma=0.8):
# https://arxiv.org/pdf/1706.00527.pdf
return x + np.random.normal(loc=0., scale=sigma, size=x.shape)
def scaling(x, sigma=1.1):
# https://arxiv.org/pdf/1706.00527.pdf
factor = np.random.normal(loc=2., scale=sigma, size=(x.shape[0], x.shape[2]))
ai = []
for i in range(x.shape[1]):
xi = x[:, i, :]
ai.append(np.multiply(xi, factor[:, :])[:, np.newaxis, :])
return np.concatenate((ai), axis=1)
def permutation(x, max_segments=5, seg_mode="random"):
orig_steps = np.arange(x.shape[2])
num_segs = np.random.randint(1, max_segments, size=(x.shape[0]))
ret = np.zeros_like(x)
for i, pat in enumerate(x):
if num_segs[i] > 1:
if seg_mode == "random":
split_points = np.random.choice(x.shape[2] - 2, num_segs[i] - 1, replace=False)
split_points.sort()
splits = np.split(orig_steps, split_points)
else:
splits = np.array_split(orig_steps, num_segs[i])
warp = np.concatenate(np.random.permutation(splits)).ravel()
ret[i] = pat[0,warp]
else:
ret[i] = pat
return torch.from_numpy(ret)
위는 코드에서 발췌한 data augmentation.py의 주요 알고리즘입니다.
TS TCC의 데이터 전처리에는 데이터의 크기 정규화가 포함되어있는데, 그 이유는 본 논문에서 실험하는 총 데이터가 4종류가 되고, 각 데이터마다 진폭, 즉 시계열 데이터의 최대값과 최소값이 다르기 때문데 jittering을 할 때 제대로 변조가 되지 않을 수 있습니다.
예를 들어, 최대값이 1이고 최소값이 -1인 시계열 데이터에서 0.1이란 값을 jittering에 사용할경우와 최대값이 100이고 최소값이 -100인 시계열 데이터에서 0.1이란 값을 jittering에 사용할경우 전자는 큰 변조 효과를 얻지만, 후자는 거의 변조효과를 얻지 못하게 됩니다. 이러한 이유로 데이터 변조를 하기 전 정규화 과정을 먼저 거치게 됩니다.
jitter은 시계열 데이터 x의 길이만큼 평균이 0인 정규분포를 가진 텐서를 만들어 x에 더해줍니다.
scailing은 시계열 데이터의 각 시점마다 정규 분포를 가진 랜덤값을 곱해주게 되는데, 위의 구현에서는 weak_aug에는 jittering 함수가 사용되지 않았습니다. 신호의 각 시점에 랜덤으로 다른 값을 곱해주게 되면, 예를들어 시점1에는 1.001235를 곱하고, 시점 2에는 1.451을 곱하게 되면 이 또한 원본신호에 무작위 값을 내는 것과 같은 효과를 볼 수 있기 때문입니다.
permutation은 신호를 max_segments의 개수로 나누고, 뒤섞는 방법입니다.
시퀀스의 길이 -2 까지의 값으로 스플릿할 포인트를 선택합니다. 스플릿할 포인트를 정했으면, 그 순서를 섞어 준 후, jittering을 더해주게됩니다.
In paper, 3.2 Temporal Contrasting
Temporal Contrasting 모듈은 자가 회귀모델을 이용하여 은닉공간으로부터 시간적인 특징을 추출해서 contrastive loss를 계산합니다. 은닉 특징 z를 생각해 봅시다. 자가회귀 모델 은 t 시점 이전인 은닉 특징를 트랜스포머에 입력해 컨텍스트 벡터 = (z을 만들어냅니다. ∈ R 이며 h는 의 은닉공간이 됩니다. 컨텍스트 벡터 는 부터 까지 z의 타입스텝을 예측하는데 사용됩니다. 미래의 타임스텝을 예측하기 위해서, 우리는 log-bilinear모델을 상호 정보 보존을 위해 사용합니다. 예를 들자면, ()= (( , 같은 것입니다. 는 를 와 같은 차원으로 매칭해주는 선형 함수입니다.
우리의 접근에서, 강한 변조는 를 만들어내고 약한 변조는 를 만들어냅니다. 우리는 예측하기 힘든 cross-view prediction 태스크를 수행하게 했습니다. 강한 변조에서 나온 를 이용해 약한 변조에서 에서 나온 특징의 미래인 를 예측시킵니다. 또, 그 반대도 수행합니다. Contrastive loss는 같은 샘플에서 나온 두가지 특징의 유사도를 최대하하고, 다른 샘플에서 나온 유사도인 를 최소화 합니다. 따라서 우리는 두가지 로스인 와 를 계산하게 됩니다.
temporal contrasting의 loss식은 다음과 같습니다.
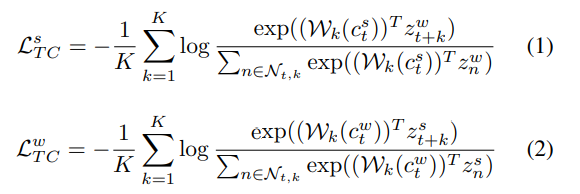
for i in np.arange(0, self.timestep):
linear = self.Wk[i]
pred[i] = linear(c_t)
for i in np.arange(0, self.timestep):
total = torch.mm(encode_samples[i], torch.transpose(pred[i], 0, 1))
nce += torch.sum(torch.diag(self.lsoftmax(total)))
nce /= -1. * batch * self.timestep해당 부분을 계산하는 코드입니다.
i가 타임스텝인 K만큼 반복하게되고, total은 W인encode_samples[i]와 c인 pred[i]계산하는 파트입니다.
특이하게 코사인 유사도()에서 분모 부분을 없앴는데, 그럼으로써 log 안에 들어가는 식이 softmax 함수와 같은 형태를 띄게 됩니다. 그래서 코드엔 logsoftmax에 total을 통과시켜 더하게됩니다. nce는 total의 값을 누적해서 더하는 부분으로 loss식의 가장 바깥쪽 시그마가 됩니다.
마지막으로 리턴을 해줄 때 nce에 -를 곱해줘 논문의 temporal contrasting loss 값을 구하게 됩니다. 논문의 within the minibatch 에서 언급된 부분에서 배치크기만큼 로스 식이 반복되기 때문에 배치 사이즈로 나눠주게 됩니다.
temporal contrasting loss는 요약하자면, 인코더와 트랜스포머를 통해 뽑아낸 feature들을 이용해, 트랜스포머를 통과한 컨텍스트 벡터 c를 이용해 반대편 뷰의 t+k를 예측하는 것입니다. 이 때, time step은 시계열의 시간과는 다릅니다. 시계열의 시간이 아닌, 은닉공간 상태에서의 시간적 요소가 됩니다. 분자는 논문에 나온대로 크로스 - 뷰 프레딕션 내용이지만 분모의 의 부분은 쉽게 이해하기 어려웠습니다.
여러번 코드와 논문의 식을 다시 읽어본 결과 다음과 같이 이해할 수 있게 되었습니다.
timestep값 k에 대하여, z의 값과 값을 트랜스포즈 한 값(유사도)을 t~k까지의 유사도의 합으로 나눠주게 됩니다.
즉, temporal contrasting 의 cross-view prediction은 뒷 내용의 k 길이만큼 feature의 시퀀스를 예측하는 것이 아닌, timestep 만큼의 뒤의 시점 t+k의 값을 예측하고, 그 유사도를 계산에 사용하는 것이었습니다.
우리는 트랜스포머를 자가 회귀모델로 사용했습니다. 트랜스포머는 효율과 스피드가 굉장히 좋기 때문입니다. 트랜스포머의 구조는 Figure 2에 나와있습니다. 이것은 멀티 헤드 어텐션(MHA)이후에 오는 멀티 레이어 퍼셉트론(MLP)의 구조로 이루어져 있습니다. MLP블록은 두 개의 Fully-Connected 레이어로 이루어져 있고, 두 선형 레이어 사이에 ReLU 활성함수와 드롭아웃 레이어를 추가하여 비선형성을 추가하였습니다. LayerNorm과 잔차 연결을 합한 블록은 좀더 안정적인 그레디언트를 생성해주기 때문에 우리의 트랜스 포머에 적용했습니다.
우리는 개의 identical 레이어를 최종 feature를 추출하기 위해 사용했습니다. BERT 모델에 영감을 얻어, 우리는 출력에서 특징 문맥 벡터로서 작용할 수 있는 토큰 c ∈ 를 입력에 상요했습니다. 트랜스포머는 특징 를 선형 프로젝션인 레이어에 매핑하는 것으로 부터 시작됩니다. 이 레이어는 특징들을 은닉공간으로 이동시킵니다. 다시말해, : 가 됩니다. 선형 프로젝션의 출력은 트랜스포머로 보내집니다. 다시말해, = () 입니다.
다음으로, 우리는 문맥 벡터를 특징 벡터 에 연결합니다. 이렇게 되면 입력 특징 = 가 됩니다. 0은 입력의 첫번째 레이어라는 뜻입니다.
다음으로, 우리는 를 아래와 같은 방정식을 이용해 트랜스포머 레이어에 전달합니다.
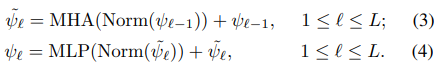
마지막으로, 우리는 최종 출력 벡터인 = 와 문맥 벡터를 다시 연결합니다. 이 문맥 벡터는 아래의 contextual contrasting 모듈의 입력으로 사용됩니다.
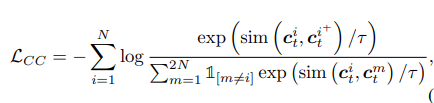
Figure 2: Architecture of Transformer model used in Temporal Contrasting module. The token c in the output is sent next to the Contextual Contrasting module.
TS TCC에서는 시계열 데이터를 처리하기 위한 트랜스포머를 별도로 seq_Transformer로 정의하였습니다. 해당 코드는 아래와 같습니다.
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, mlp_dim, dropout):
super().__init__()
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Residual(PreNorm(dim, Attention(dim, heads=heads, dropout=dropout))),
Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout=dropout)))
]))
def forward(self, x, mask=None):
for attn, ff in self.layers:
x = attn(x, mask=mask)
x = ff(x)
return x
class Seq_Transformer(nn.Module):
def __init__(self, *, patch_size, dim, depth, heads, mlp_dim, channels=1, dropout=0.1):
super().__init__()
patch_dim = channels * patch_size
self.patch_to_embedding = nn.Linear(patch_dim, dim)
self.c_token = nn.Parameter(torch.randn(1, 1, dim))
self.transformer = Transformer(dim, depth, heads, mlp_dim, dropout)
self.to_c_token = nn.Identity()
def forward(self, forward_seq):
x = self.patch_to_embedding(forward_seq)
b, n, _ = x.shape
c_tokens = repeat(self.c_token, '() n d -> b n d', b=b)
x = torch.cat((c_tokens, x), dim=1)
x = self.transformer(x)
c_t = self.to_c_token(x[:, 0])
return c_t
forward의 함수 부분을 보면, 첫 번째 줄의 x = self.patch_to_embedding(forward_seq)에서 인풋인 forward_seq의 피쳐들을 인코딩하게 됩니다.
그리고 세 번째 줄에서 가운데 차원이 n인 x를 입력으로 하고 출력의 가운데 차원이 1인 문맥벡터 c_tokens를 출력하게 됩니다. x를 트랜스포머에 넘기기 전, x와 c_tokens를 같이 합쳐 넘겨주게 됩니다.
트랜스포머는 LayerNormalization+multi-head attention 블록과
LayerNormalization+Multi-layer perceptron의 잔차 연결로 이루어져 있습니다.
이러한 구조를 seq_transformer로 정의하며, 이 클래스를 통해 입력에서 feature들을 추출하게 됩니다.
In paper, 3.3 Contextual Contrasting
여기서는 Contextual Contrasting에 관한 설명을 하고 있습니다.
우리의 목적은 결정적인 특징을 학습하기 위한 contextual contrasting 모듈을 만드는 것 이었습니다. 이것은 문맥으로부터 비선형 프로젝션 헤드를 통한 비선형적인 변환을 함으로써 실행할 수 있습니다. 프로젝션 헤드는 컨텍스트 벡터를 contextual contrasting 공간에 매핑할 수 있게 해 줍니다.
N개의 입력 샘플을 가진 배치를 생각해 봅시다. 우리는 두 개의 컨텍스트 벡터를 두개의 각기 다른 변조된 데이터로 부터 얻을 수 있습니다. 그리고 우리는 2N개의 문맥을 가지고 있게 됩니다.
context 벡터 에 대해, 우리는 같은 샘플에서 온 다른 변조된 뷰를 의 positiva pair로 하겠습니다. 그리고, (,)는 positive pair로 간주됩니다. 반면에, 남아있는 (2N - 2)개의 컨텍스트 벡터들은 negative pair로 간주됩니다. 그러므로, 우리는 contextual contrasting을 positive pair의 유사도를 늘리고, negative pair들에 대해선 줄이는 방향으로 훈련시킵니다. 그래서, 마지막 특징들은 구별적으로 됩니다. 아래의 식은 contextual contrasting loss 함수이며, 라고 정의하겠습니다. 컨텍스트 벡터 에 대해, 우리는 그것의 positive sample인 과의 유사도를 나머지 (2N-1)개의 샘플들의 유사도로 나눠줍니다. 즉, 2N개의 positive pair과 2N-2의 Negative pair이 됩니다.
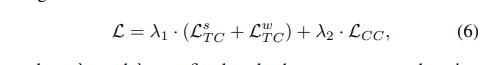
sim(u,v)는 코사인 유사도입니다.
어떻게 유사도를 이용해 loss값을 줄이는 지는 포스트 1편(https://velog.io/@ahj6377/TS-TCC-%EC%A0%95%EB%A6%AC-%EB%B0%8F-%EB%B6%84%EC%84%9D-1)에 나와있으니 참고하시면 되겠습니다.
종합한 self-supervised 로스함수는 두개의 temporal contrasting loss값과 contextual contrasting loss 값을 합친 아래와 같은 식이 됩니다.
과 는 스칼라 하이퍼 파라미더로 각 로스들간의 가중치라고 볼 수 있습니다.
loss = (temp_cont_loss1 + temp_cont_loss2) * lambda1 + nt_xent_criterion(zis, zjs) * lambda2코드에서 나온 self supervised loss의 최종식은 다음과 같습니다. 특이하게, 에는 NT-Cross Entropy가 사용되었는데, 이는 논문에서 해당 로스 함수로 최적의 성능을 보였다고 언급되었습니다.
이로써 논문의 3인 Method에 대한 번역과 관련 코드 리뷰가 끝났습니다.
이 다음 포스팅에서는 TS TCC를 이용한 사전학습과 파인 튜닝에 관한 실험 내용과, TS-TCC가 어떻게 파인 튜닝을 진행하는 가에 대해 쓰겠습니다.
