
SQL문 기본
SELECT 문의 정렬
이 책에서는 MySQL을 사용하며 MySQL 내에 기본적으로 저장되어있는 world table을 사용하여 실습을 합니다.
ORDER BY
SELECT * FROM city ORDER BY 정렬키1 [, 정렬키2, ..] [ASC/DESC]조회한 데이터의 열을 정렬하기 위해 ORDER BY 키워드가 사용된다.
여기서 주의해야할 점은, 정렬키로 사용된 열의 값이 중복된 행들이 있다면, 그 행들의 순서는 일정하지 않다.
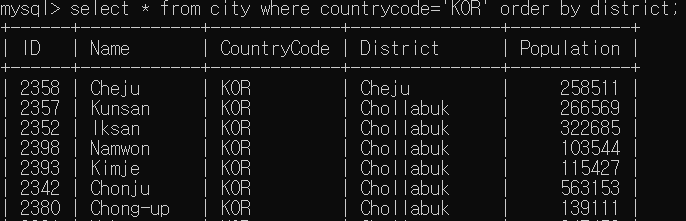
행의순서를 확실하게 하기 위해서는 값이 unique한 열을 정렬키로 사용하거나, 정렬키로 지정하는 열을 여러개로 둬서 정렬키 값의 중복을 방지해야한다.
집약 함수(집계함수)
복수의 행에 대해 집계를 수행하는 함수를 집약함수라고 한다. 집약 함수에는 COUNT, SUM, AVG, MAX, MIN이 포함된다.
집약함수는 기본적으로 NULL을 제외하고 집계되나, COUNT 함수만은 NULL을 포함한 전체 행을 집계하는 경우가 있다.
SELECT DISTINCT 문
SELECT DISTINCT 열이름 FROM 테이블이름선택한 열에서 '중복되지 않는' 값만을 결과로 얻기 위해 DISTINCT 키워드를 사용한다.
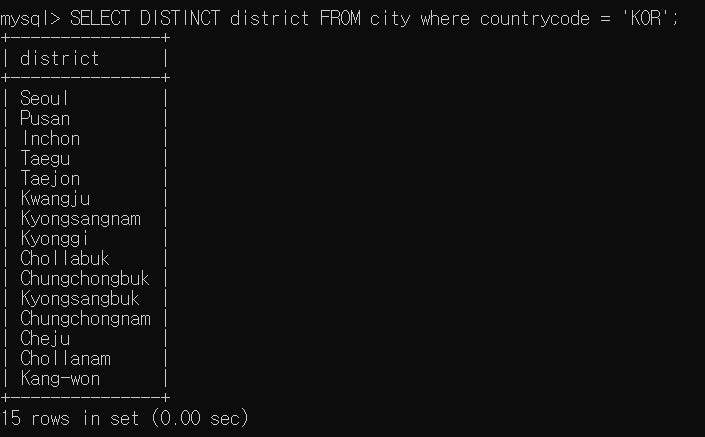
GROUP BY
SELECT 열이름 FORM 테이블이름 GROUP BY 열명1 [, 열명2 ...]데이터를 그룹으로 나눠서 집계하고 싶을 때 GROUP BY 키워드를 사용한다.
GROUP BY 뒤에 작성하는 열 명을 '그룹화 키'라고 한다.
예를 들어, 대한민국의 도나 광역시별 도시의 수를 집계하려고 한다. 이 집계의 기준이 되는 열은 district이므로, district을 그룹화 키로 설정하여 SELECT문을 작성한다.
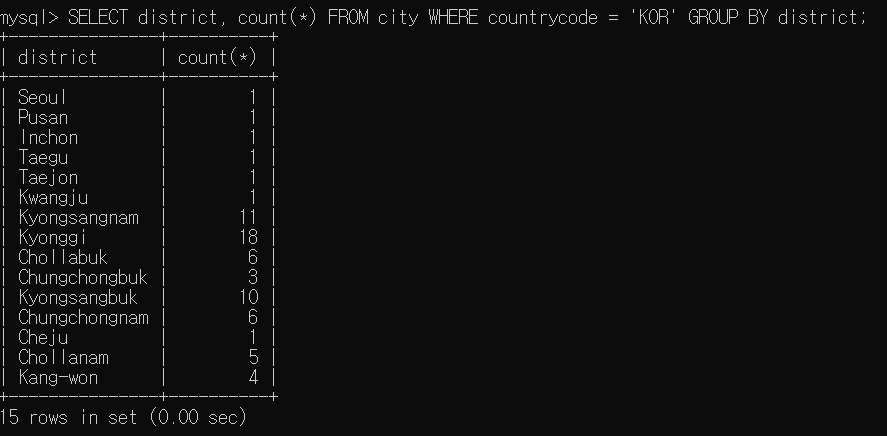
HAVING
SELECT 열 명 FROM 테이블 이름 GROUP BY 그룹화 키 HAVING 조건GROUP BY 키워드를 사용하여 그룹으로 나눠 집계한 결과에 조건을 추가하고 싶다면 HAVING을 사용할 수 있다.
앞에서 설명한 키워드를 작성할 때에는 이 순서대로 작성해야한다
1. SELECT
2. FROM
3. WHERE
4. GROUP BY
5. HAVING
6. ORDER BY
뷰
Views are stored queries that when invoked produce a result set. A view acts as a virtual table.
MySQL문서에 따르면 뷰란 저장된 쿼리이다. 매번 복잡한 select문을 타이핑해서 데이터를 조회하지 않고 쿼리를 저장하여 내가 원하는 열과 행만 볼 수 있다. 마치 새로운 테이블을 만든 것처럼.
아래는 뷰를 생성하는 구문이다.
CREATE VIEW 뷰 명 (열 명1 [, 열 명 2, ...] AS SELECT ... FROM ...;(테이블이랑 비슷해서 뷰를 생성할 때 테이블을 만드는 것처럼 CREATE 키워드를 쓰는 걸까?)
뷰에 입력 또는 갱신(UPDATE, DELETE, INSERT)을 할 수 있을까?
답은 '부분적으로 그렇다'이다. 뷰에 입력, 갱신을 한다는 것은 뷰를 만드는데 사용한 기본 테이블(들)에 입력과 갱신을 한다는 뜻이다. 기본적으로 뷰가 updatable되기 위해서는 뷰의 행과 기본 테이블의 행이 1:1 관계여야한다. 그러나 뷰를 만들기 위해 집계함수를 사용했거나 여러 기본 테이블을 조인한 경우 등, 뷰와 기본테이블의 관계가 1:다수 인 경우가 많기 때문에 뷰에 입력, 갱신을 할 때에는 많은 제약조건이 따른 다는 것을 기억해야한다.
https://dev.mysql.com/doc/refman/8.0/en/view-updatability.html
서브쿼리
statement 안에 포함된 또 다른 select statement를 서브쿼리라고 한다. 쿼리 결과를 외부 쿼리에서 사용할 수 있도록 한다.
서브쿼리의 결과는 하나의 행과 하나의 열로 구성된 테이블, 즉 단일값(scalar 값이라 부른다) 일 수도 있고 하나 또는 여러 행이 될 수도 있다.
이 책에서는 서브쿼리를 설명하기 위한 예제는 아래와 같다
select district, name, population
from citykorea as c1
where population > (select avg(population)
from citykorea as c2
where c1.district = c2.district group by district);이 예제를 보면서 외부(outer) 쿼리에서 사용되는 테이블(c1)을 서브 쿼리에서 참조하는데, 쿼리가 어떤 순서로 실행되는지가 궁금해졌다.(정확히는 'c1.district = c2.district group by district' 에서 헷갈리기 시작) 그래서 찾아보니,
The name of correlated subqueries means that a subquery is correlated with the outer query. The correlation comes from the fact that the subquery uses information from the outer query and the subquery executes once for every row in the outer query. (geeksengine.com)
외부 쿼리와 연관되었다는 의미의 correlated(연관되) 서브쿼리는 외부 쿼리의 실행에 종속되어 외부 쿼리의 각 행마다 한 번씩 실행된다고 한다. 각 행마다 서브쿼리가 반복적으로 계속 실행되는 것은 분명 효율적이지 않다. 실행 시간을 줄여 성능을 향상시키기 위해서는 서브쿼리 대신 join을 사용할 수 있다. 아래는 위의 쿼리를 join을 사용하여 바꾼 쿼리이다.
select c1.district, c1.name, c1.population
from citykorea as c1
inner join (select c2.district, avg(c2.population) as
avg_pop
from citykorea as c2
group by c2. district) as sub
on c1.district = sub.district and c1.population > sub.avg_pop;참조 :
https://www.geeksengine.com/database/subquery/correlated-subquery.php
