
대규모 시스템장애를 뉴스에서 보고 또 겪기도 하면서 견고한 시스템을 구축하는 것이 사회적으로나 개인적으로 얼마나 중요한 문제인지를 우리는 알고 있습니다. 지난 글에 이어 이 글에서는(데이터베이스와 관련된) 아키텍처 설계에서 가용성과 확장성을 확보하기 위해 어떤 전략을 취해야하는지 또 알고 있어야하는 기본 지식에 대해 정리합니다.
이 글은 데이터베이스 첫걸음 4장을 읽고 정리한 글입니다.
가용성의 확보
가용성이란 전체 서비스 시간에서 장애 없이 지속적으로 서비스를 제공하는 시간의 비율을 말합니다. DB서버가 한대 뿐인 상황을 가정해봅시다. DB서버에 장애가 발생한다면 이 서버가 속한 시스템의 가용성은 어떻게 될까요? 당연히 서비스는 정지되고 가용성은 떨어질 수 밖에 없습니다.
이처럼 가용성을 낮추는 상황들을 방지하기 위한 전략에는 크게 두 가지가 있습니다.
- 고품질 소수전략
- 성능이 높은(비싼)컴포넌트를 사용하여 장애발생 확률을 억제하는 것
- 다른 컴포넌트로의 전환시간을 짧게 함
- ex. FT(Fault Tolerant) 서버
- 저품질 다수 전략
- 성능이 비교적 낮은 컴포넌트 여러개를 병렬로 배치하여 장애 발생에 대비하는 전략
- 장애 발생시 다른 컴포넌트로의 전환시간에는 불가피하게 시스템이 정지된다
- 현재 많이 사용하고 있는 전략
클러스터링
가용성을 획득하기 위해 저품질 다수 전략을 취하여, 같은 기능을 하는 여러개의 컴포넌트들을 준비하여 하나의 기능을 구현하는 것을 클러스터링이라고도 합니다. 안경 분실이나 파손을 대비해 여러개의 안경을 구비해놓는 것을 생활속의 예로 들 수 있습니다. 클러스터링을 통해 가동률을 향상시키는 것을 '여유도를 확보'한다 또는'다중화'한다라고 말합니다.
클러스터링 == 가용성 인가?
가용성을 확보하기 위해 장애 발생률이 10%인 DB서버를 다중화한다고 가정해봅시다. 아래는 다중화 정도에 따른 가동률(전체 서비스시간 - 장애발생시간)을 그래프로 나타낸 그림입니다.
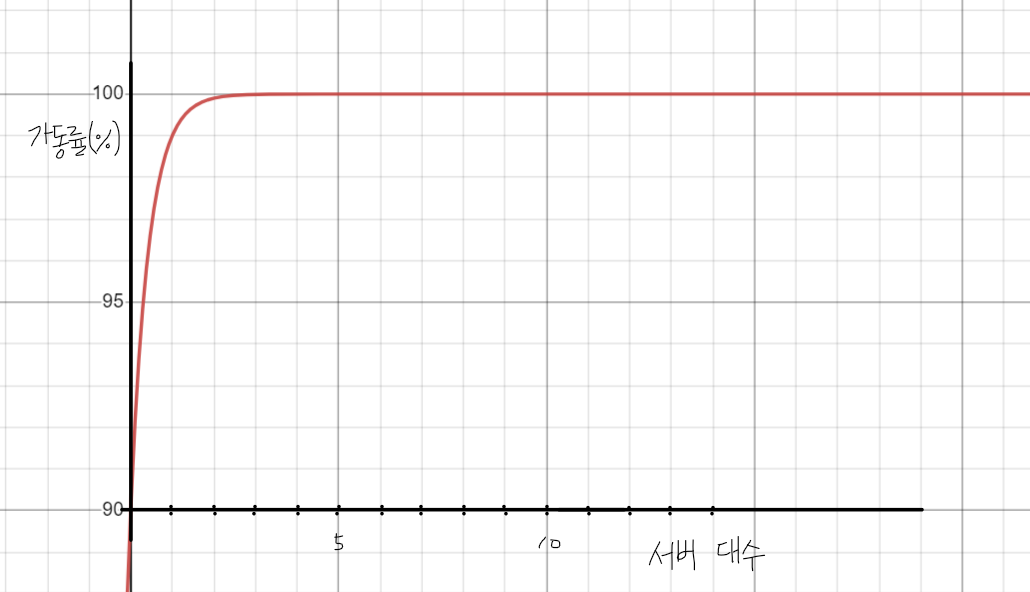
(안그렇게 보이지만 100에 수렴하는 그래프입니다)
위의 그림을 통해 알 수 있는 것은 아무리 다중화를 한다고 해도 **가동률 100%는 확보할 수 없다**는 것입니다. 가동률은 90% -> 99% -> 99.9% -> ... 로 계속해서 늘어갑니다. 그러나 서버 전체가 심각한 자연재해와 같은 상황으로 문제가 생길 수 있는 가능성을 배제하지 못하기 때문에 100%를 확보할 수는 없습니다.또한 DB서버를 다중화 할 수록, 다중화에 비용을 더 들일 수록 가동륙 상승의 폭이 줄어듭니다. input을 늘리지만 그만큼의 output이 나오지 않는 것을 수확체감의 법칙이라고 합니다.
클러스터링이 가용성을 확보하기 위한 방법이지만 100% 절대적인 방법은 아님을 기억합시다.
단일장애점을 다중화하기
다중화가 되어있지 않아서 전체 시스템의 계속성에 영향을 주는 컴포넌트를 단일 장애점이라고 합니다. 단일 장애점의 신뢰성이 시스템의 가용성을 결정하기 때문에 예산 내에서(다중화는 돈이 문제이니까) 다중화를 고려해야합니다.
이제부터 본격적으로 데이터베이스의 다중화 전략에 대해 다뤄보겠습니다.
DB서버 다중화
DB서버는 왜 다중화가 어려울까?
DB서버는 다른 서버에 비해 다중화하기가 어렵습니다. 데이터베이스는 데이터를 영구적으로 보존해야하기 때문입니다. 데이터(DB 저장소)를 다중화할 때 데이터의 정합성(데이터가 모순되지 않고 서로 일치하는 상태)을 충족해야하기 때문에 DB의 다중화가 어렵습니다.
DB의 다중화는 아래와 같은 구성으로 나뉩니다.
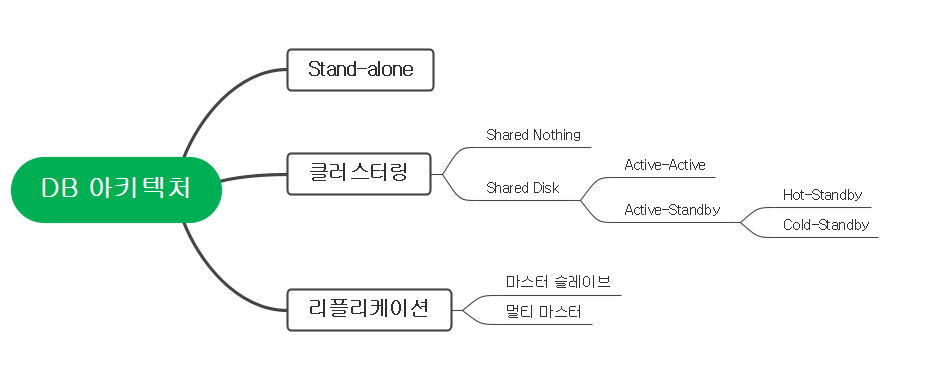
1-1. DB서버만 다중화 하기
DB서버만 다중화하고 저장소는 하나만 사용하는 경우(=Shared Disk)입니다. 이 구성에서는 데이터의 정합성을 고려하지 않아도 되는 장점이 있습니다. 다중화하는 DB서버의 작동 여부에 따라 또 두 가지 경우로 나눌 수 있습니다.
active-active
- 다중화한 두 개의 DB서버가 동시에 작동 됨
- 하나의 DB서버에 문제 발생시 전환시간이 걸리지 않음
- 서버를 동시에 작동하기 때문에 성능이 좋아짐(CPU, 메모리등) 단, 저장소가 하나이기 때문에 병목현상이 발생하여 생각보다 성능이 좋지 않은 경우가 있음
active-standby
- DB서버 컴포넌트 중 가동중인 active 서버, 사용하지 않고 대기중인(active 서버에 장애가 생겼을 때만 사용되는) standby서버가 있습니다.
- 대기 중인 standby 서버는 일정 간격마다 active 서버로 정상작동하고 있는지 확인하기 위해 신호를 보내 통신을 합니다. active서버에 문제가 생겨 신호가 오지 않을 경우, standby 서버가 작동합니다.
- 다시 두 가지 경우로 나눌 수 있습니다
- active-standby(Cold standby)
- standby서버가 사용되지 않고 있다가, active서버에 에러 발생 후에 standby서버를 사용하고 작동시키는 것
- 서버 전환시간이 걸림(수 초 ~ 수 분). 그 동안 시스템은 다운 됨
- active-standby(Hot standby)
- active, standby서버 둘 다 사용하고는 있으나, active서버에 에러 발생 후 사용하고 있는 standby서버를 작동시킴
- 서버 전환시간이 비교적 적게 걸림
- 라이선스 료가 비싸지만 여전히 active-active 보다는 저렴
- active-standby(Cold standby)
1-2 Shared Nothing
앞에서 DB서버를 다중화하고 하나의 저장소를 사용하는 방식(Shared Disk)의 active-active구성을 언급했습니다. 이 구성은 DB서버를 계속 늘려도 처리율이 무한으로 향상되지 않고 한계점에 도달한다는 문제점이 있습니다. 이는
-
저장소가 공유자원이기 때문에 쉽게 늘릴 수 없고
-
DB서버를 늘릴 수록 DB간의 정보 공유를 위한 오버헤드가 크기 때문입니다
*오버헤드:어떤 작업을 하는 데 있어서 그 과정에서 발생하는 간접적인 비용
Shared Disk 성능 한계의 문제점을 해결하기 위한 아키텍쳐가 Shared Nothing입니다. 말 그대로 네트워크를 제외한 아무것도 공유하지 않습니다. DB 서버-저장소 세트를 여러개를 가지고 있는 것입니다. (뒤에 나오는 리플리케이션과 헷갈릴 수 있는데, 리플리케이션은 DB서버와 저장소 세트를 '병렬화'하여 데이터를 다중화하고 부하를 분산시키는 것에 목적이있는 반면, sharedNothing은 데이터 다중화를 고려하지 않고 DB서버 다중화에 따른 성능 문제를 해결하는 것에 초점을 맞춤을 기억합시다.)
Shared Nothing의 특징
- shared Nothing은 DB서버수에 비례해 저장소의 수가 늘어남
- 저장소-서버 세트를 늘려 저장소가 병목이 되는 것을 방지
- 각각의 DB서버가 동일한 하나의 데이터에 접근할 수 없음
우리나라의 각 광역시에 하나씩 있는 DB서버는 또한 각각의 저장소에 각도 시의 시민의 개인정보를 저장하고 있다고 가정해봅시다. 서울시의 DB서버는 서울 시 저장소에만 접근할 수 있고 부산시의 저장소에는 접근할 수 없습니다. - 그렇기 때문에 하나의 DB서버가 다운됐을 때, 그 서버에 연결된 저장소에 다른 DB서버가 접근할 수 없음
- DB서버가 다운돼었을 때 다른 서버가 이어받아 작업을 처리할 수 있게하는 커버링 구성을 고려해야함
2. 리플리케이션
리플리케이션이란
DB서버와 저장소 세트를 병렬화하는 것을 말합니다.
리플리케이션은 왜 필요할까?
작년 10월에 카카오톡 접속 장애가 있었습니다. 화재로 인해 카카오톡 서버 3만대 이상이 멈췄고 예비서버로 전환하는 기간도 오래 걸려 수시간에서 길게는 하루 이틀정도 카카오톡에서 제공하는 서비스를 사용하지 못했습니다. 이렇듯 서버가 한 곳에 집중되어있는데 천재지변이나 화재등으로 서버와 저장소가 한번에 문제가 생길 때 가용성을 높이고 데이터를 잃지 않기 위해 리플리케이션이 필요합니다. 이런 특수한 상황 뿐 아니라 서버의 부하를 분산시키기 위해서 사용되기도 합니다.
리플리케이션에서 주의해야할 것
active측 저장소의 데이터는 사용자가 갱신한다. 따라서 standby측 저장소의 데이터도 최신 데이터로 갱신(동기화)을 해야하는데 그 주기를 얼마로 설정해야할지, 또 주기를 늘리면 성능을 향상시킬 수 있는데 이 둘의 타협점을 고민해야 합니다.
DB서버, 저장소 세트를 여러개 두면, 원칙적으로는 손자 증손자 세트를 만들 수 있습니다. 갱신 주기가 길어 오래된 데이터를 가진 저장소라도 그 데이터를 참조만 하면 되는 작업이라면 이 처리를 손자나 증손자 세트에 맡기면 되기 때문에 부모에 걸리는 부하를 분산할 수 있습니다.
정리
아키텍쳐 설계는 물리레벨의 구성을 시스템에 목적과 기능에 맞게 결정하는 것으로 이후 단계에서 수정하기가 매우 어렵습니다. 그렇기 때문에 시스템의 요구사항을 파악하고 제한된 자원들을 고려한 아키텍쳐 설계를 해야합니다.
