상속 관계 매핑
관계형 데이터베이스에는 객체지향 언어에서 다루는 상속이라는 개념이 없다. 대신 슈퍼타입 서브타입 관계라는 모델링 기법이 객체의 상속 개념과 가장 유사하다.
슈퍼타입 서브타입 논리 모델을 실제 테이블로 구현할 때는 세 가지 방법을 선택할 수 있다.
- 조인 전략(Joined Strategy) - 각각의 테이블로 변환
- 단일 테이블 전략(Single-Table Strategy) - 통합 테이블로 변환
- 구현 클래스 마다 테이블 전략(Table-per-Concrete-Class Strategy) - 서브타입 테이블로 변환
조인 전략
@Inheritance(strategy = InheritanceType.JOINED)
엔티티 각각을 모두 테이블로 만들고 자식 테이블이 부모 테이블의 기본 키를 받아서 기본 키 + 외래 키로 사용하는 전략이다.
필연적으로 조회할 때 조인을 자주 사용한다.
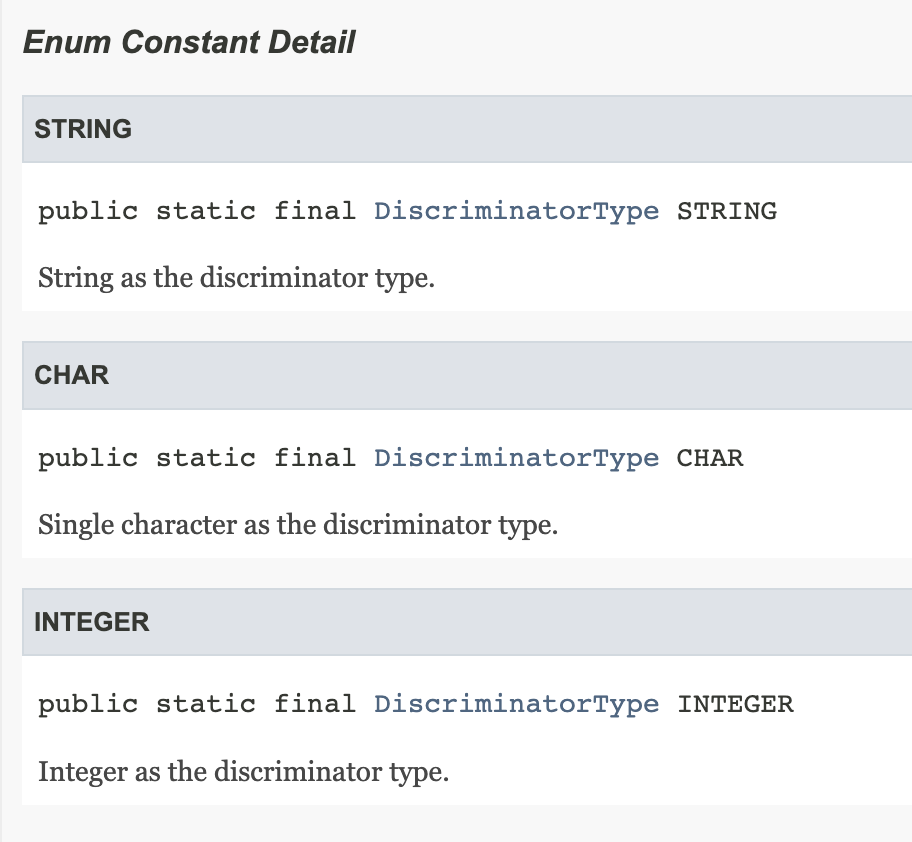
객체는 타입으로 구분할 수 있지만 테이블은 타입의 개념이 없다. 따라서 타입을 구분하는 컬럼을 데이터베이스에서 슈퍼타입에 해당하는 테이블에 컬럼으로 넣어 주어야 한다.
해당 컬럼은 JPA에서 @DiscriminatorColumn 어노테이션을 통하여 넣어줄 수 있다.
@DiscriminatorColumn(name = "DTYPE")
부모 클래스에 구분 컬럼을 지정한다. 이 컬럼을 통하여 저장된 자식 테이블의 글래스를 구분할 수 있다.
DiscriminatorType을 설정하여DTYPE컬럼의 타입을 Stirng, Char, Integer로 변경할 수 있다. 기본 값은 String이다.
@DiscriminatorValue("<Customized Name>")
부모 클래스에 있는 DTYPE컬럼에 저장할 값을 자식 클래스에 지정할 수 있다. 지정하지 않았고, DTYPE의 타입이 STRING이면 엔티티 이름이 기본 값으로 지정된다.
If the
DiscriminatorTypeis STRING, the discriminator value default is the entity name. - Java Docs
@PrimaryKeyJoinColumn(name = "<Customized Id>")
기본 값으로 자식 테이블은 부모 테이블의 ID 컬럼명을 그대로 사용하는데, 만약 자식 테이블의 기본 키 컬럼명을 변경하고 싶으면 @PrimaryKeyJoinColumn 어노테이션을 사용하면 된다.
장점
테이블이 정규화 된다.
외래 키 참조 무결성 제약조건을 활용할 수 있다.
저장공간을 효율적으로 사용한다.
단점
조회할 때 조인이 많이 사용되므로 성능 저하가 있을 수 있다.
조회 쿼리가 복잡하다.
데이터를 등록할 INSERT 쿼리가 두 번 실행된다.
JPA 표준 명세는 구분 컬럼을 사용하도록 하지만 하이버네이트를 포함한 몇몇 구현체는 구분 컬럼 없이도 동작한다.
단일 테이블 전략
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
테이블을 하나만 사용하여 상속 관계를 매핑하는 것이다. 여러 타입의 엔티티가 한 테이블에 저장되므로 타입을 구분하는 DTYPE을 필수로 사용해야한다. 조회할 때 조인을 사용하지 않으므로 일반적으로 가장 빠르다.
이 전략을 사용할 때 주의점은 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다는 점이다.
장점
조인이 필요 없으므로 일반적으로 조회 성능이 빠르다
조회 쿼리가 단순하다
단점
자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 한다
단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다. 그러므로 상황에 따라서는 조회 성능이 오히려 느려질 수 있다.
구분 컬럼을 꼭 사용해야한다. 따라서
@DiscriminatorColumn을 꼭 설정해야 한다.
구현 클래스마다 테이블 전략
@Inheritance(strategy = InheritanceType.TABLE_PER_CLASS)
자식 엔티티마다 테이블을 만들고 자식 테이블 각각에 필요한 컬럼이 모두 있도록 하는 전략이다. 따라서 따로 슈퍼타입에 해당하는 테이블은 없다.
일반적으로 추천하지 않는 전략이다. 데이터베이스 설계자와 ORM 전문가 둘 다 추천하지 않는 전략이다.
장점
서브 타입을 구분해서 처리할 때 효과적이다.
not null 제약 조건을 사용할 수 있다.
단점
여러 자식 테이블을 함께 조회할 때 성능이 느리다. (SQL에 UNION을 사용)
자식 테이블을 통합해서 쿼리하기 어렵다.
구분 컬럼을 사용하지 않는다.
Reference
자바 ORM 표준 JPA 프로그래밍 7장
