Chapter 04. 데이터 요약하기
학습목표
- 전체 데이터를 숫자로 요약하는 방법을 배웁니다.
- 데이터 분포를 살펴보고 그래프를 통해 이해하는 방법을 알아봅니다.
04-1 통계로 요약하기
- 기술통계(descriptive statistics): 자료 내용을 압축하여 설명하는 방법으로 요약통계(summary statistics)라고도 함.
- 탐색적 데이터 분석(exploratory data analysis): 데이터 시각화를 아우르는 데이터 분석 방법
1) 기술통계 구하기
2) 평균 구하기
mean() 메서드
3) 중앙값 구하기
median() 메서드
중복값 제거하고 중앙값 구하기
4) 최솟값, 최댓값 구하기
5) 분위수 구하기
quantile() 메서드
백분위 구하기
6) 분산 구하기
var() 메서드
7) 표준편차 구하기
std() 메서드
8) 최빈값 구하기
mode() 메서드
9) 데이터프레임에서 기술통계 구하기
10) 넘파이의 기술통계 함수
평균 구하기
중앙값 구하기
최솟값, 최댓값 구하기
분위수 구하기
분산 구하기
표준편차 구하기
최빈값 구하기
[기본 숙제]
p. 279의 확인 문제 5번 풀고 인증하기
ns_book7 남산도서관 대출 데이터에서 1980년~2022년 사이에 발행된 도서를 선택하여 다음과 같은 '발행년도' 열의 히스토그램을 그려 보세요.
codeselected_rows = (1980 <= ns_book7['발행년도']) & (ns_book7['발행년도'] <= 2022) plt.hist(ns_book7.loc[selected_rows, '발행년도']) plt.show()
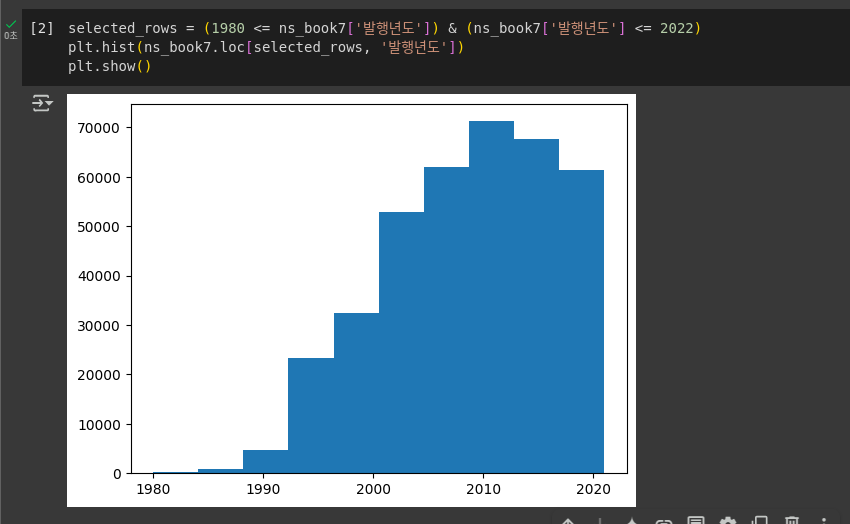
[추가 숙제]
Ch.04(04-1)에서 배운 8가지 기술통계량(평균, 중앙값, 최솟값, 최댓값, 분위수, 분산, 표준편차, 최빈값)의 개념을 정리하기
- 평균(mean): 데이터값을 모두 더한 후 데이터 개수로 나눈 값
- 중앙값(50%): 전체 데이터를 크기 순서대로 일렬로 늘어 놓았을 때 중간에 위치한 값
- 최솟값(min): 전체 데이터를 크기 순서대로 일렬로 늘어 놓았을 때 가장 처음에 위치한 값
- 최댓값(max): 전체 데이터를 크기 순서대로 일렬로 늘어 놓았을 때 가장 마지막에 위치한 값
- 분위수: 순서대로 나열된 데이터를 일정한 간격으로 나누는 기준점
- 사분위수: 데이터를 4등분하며, 25%, 50%, 75%에 위치한 값
- 백분위수: 데이터를 100개 의 구간으로 나눈 값들
- 분산: 데이터가 평균에서 얼마나 멀리 퍼져 있는지를 알려주는 값으로, 각 데이터를 평균에서 뺀 다음 제곱한 후 전체 데이터 개수로 나누어 구함.
- 표준편차: 분산의 제곱근으로 분산과 마찬가지로 데이터의 분포 정도를 알려주고, 표준편차는 원본 데이터와 단위가 같기 때문에 분산보다 해석하기 쉬움.
- 최빈값: 데이터에서 가장 많이 등장하는 값을 알려줌.

42 Gyeongsan Learner