Chapter 01. 데이터 분석을 시작하며
학습목표
- 데이터 분석과 데이터 과학을 비교하면서 데이터 분석이 무엇인지 알아봅니다.
- 예제를 실습하기 위해 구글 코랩과 주피터 노트북을 다뤄 봅니다.
- 판다스를 사용해 첫 번째 데이터를 다운로드하고 내용을 확인해 봅니다.
01-1 데이터 분석이란
1) 데이터 분석과 데이터 과학
-
데이터 분석: 유용한 정보를 발견하고 결론을 유추하거나, 의사 결정을 돕기 위해 데이터를 조사, 정제, 변환, 모델링하는 과정
=> 올바른 의사 결정을 돕기 위한 통찰 제공 -
데이터 과학: 통계학, 데이터 분석, 머신러닝, 데이터 마이닝을 아우르는 큰 개념
=> 한 걸음 더 나아가 문제 해결을 위한 최선의 솔루션을 만드는데 초점
2) 통계적 관점에서의 데이터 분석 (좁은 의미의 데이터 분석)
- 기술 통계: 관측이나 실험을 통해 수집한 데이터를 정량화하거나 요약하는 기법
- 탐색적 데이터 분석: 데이터를 시각적으로 표현하여 주요 특징을 찾고 분석하는 방법
- 가설검정: 주어진 데이터를 기반으로 특정 가정이 합당한지 평가하는 통계 방법
3) 데이터 분석가
- 자격 요건: 프로그래밍, 수학 및 통계, 도메인 지식이 모두 필요
- 작업 과정(넓은 의미의 데이터 분석): 데이터 수집, 데이터 처리, 데이터 정제, 데이터 분석, 모델링
- 좁은 의미의 데이터 분석 + 넓은 의미의 데이터 분석
4) 데이터 분석을 위한 도구
- 프로그래밍 언어: 파이썬
- 프로그래밍 환경: 구글 코랩
- 파이썬 필수 패키지(라이브러리): PyPI - NumPy, pandas, matplotlib, SciPy, scikit-learn
+ 데이터 마이닝과 머신러닝
- 데이터 마이닝: 데이터에서 패턴 혹은 지식을 추출하는 작업
- 머신 러닝: 데이터에서 자동으로 규칙을 학습하여 문제를 해결하는 소프트웨어를 만드는 기술, 규칙이나 패턴을 사용하는 주체가 사람이 아닌 컴퓨터
- 모델: 머신러니으로 학습한 소프트웨어 객체
01-2 구글 코랩과 주피터 노트북
1) 구글 코랩
- 웹 브라우저에서 무료로 파이썬 프로그램을 테스트하고 저장할 수 있는 서비스
텍스트 셀
- 셀: 코랩에서 실행하는 최소 단위
- HTML, 마크다운 혼용해서 사용 가능
코드 셀
- 파이썬 코드를 입력하고 실행할 수 있는 셀
- 위아래 셀을 오가며 코드를 실행할 수 있어 실행 순서에 주의가 필요
- Shift + Enter: 현재 셀 실행 후 다음 셀 이어서 실행
2) 노트북
- 노트북은 구글 클라우드의 컴퓨트 엔진에 연결
- 서버 메모리 약 12GB, 디스크 공간 100GB
- 코랩 노트북으로 동시에 사용할 수 있는 구글 클라우드의 가상 서버는 최대 다섯 개
깃허브에 저장된 노트북 불러오기
01-3 이 도서가 얼마나 인기가 좋을까요?
1) 도서 데이터 찾기
2) 코랩에서 데이터 확인하기
- 엑셀파일(.xlsx) 대신 csv 파일 사용
csv 파일
- 콤마(,)로 구분된 텍스트 파일
- 한 줄이 하나의 레코드, 레코드는 콤마로 구분된 여러 필드로 구성
- 행은 한 줄, 열은 콤마로 구분
gdown 패키지
코드import gdown gdown.download('https://bit.ly/3eecMKZ', '남산도서관 장서 대출목록 (2021년 04월).csv', quiet=False)
2) 파이썬으로 CSV 파일 출력하기
- open(), readline()
- with 문 활용
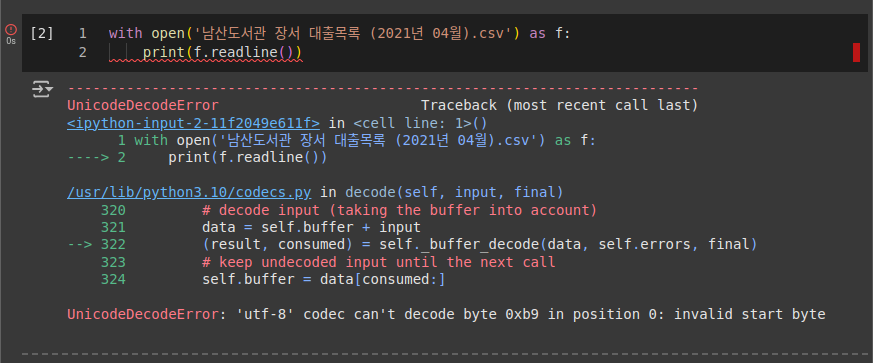
파일 인코딩 형식 확인하기: chardet.detect() 함수
- 바이너리 읽기 모드: 문자 인코딩 형식에 상관없이 파일을 열 수 있으나, 모든 글자를 1바이트로 인식하기 때문에 유니코드 문자를 화면에 올바르게 출력할 수 없음.
코드import chardet with open('남산도서관 장서 대출목록 (2021년 04월).csv', mode='rb') as f: d = f.readline() print(chardet.detect(d))
실행 결과{'encoding': 'EUC-KR', 'confidence': 0.99, 'language': 'Korean'}
인코딩 형식 지정하기
- encoding 매개변수로 인코딩 형식을 'EUC-KR'로 지정
코드with open('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='EUC-KR') as f: print(f.readline()) print(f.readline())
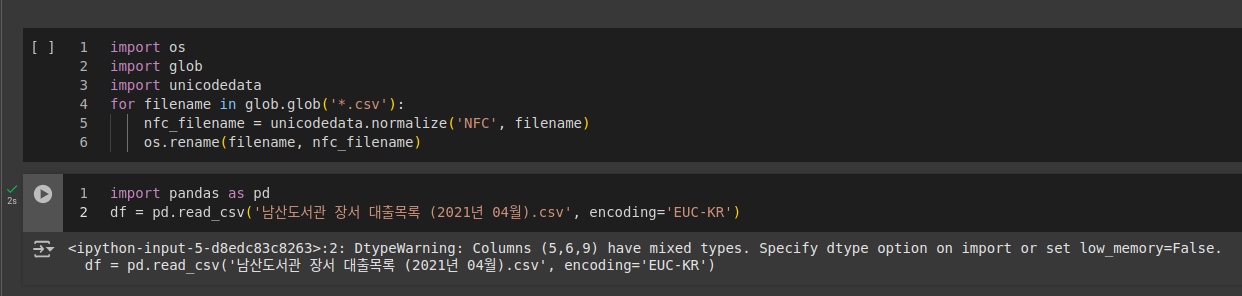
+ NFC, NFD
- NFC 방식: 혼공
- NFD 방식: ㅎㅗㄴㄱㅗㅇ
- NFD -> NFC
코드import os import glob import unicodedata for filename in glob.glob('*.csv'): nfc_filename = unicodedata.normalize('NFC', filename) os.rename(filename, nfc_filename)
3) 데이터프레임 다루기: 판다스
- 판다스는 CSV 파일을 읽어 데이터프레임이라는 표 형식 데이터로 저장
- 시리즈: 1차원 배열
- 데이터프레임: 2차원 배열, 같은 열에 있는 데이터는 모두 같은 종류
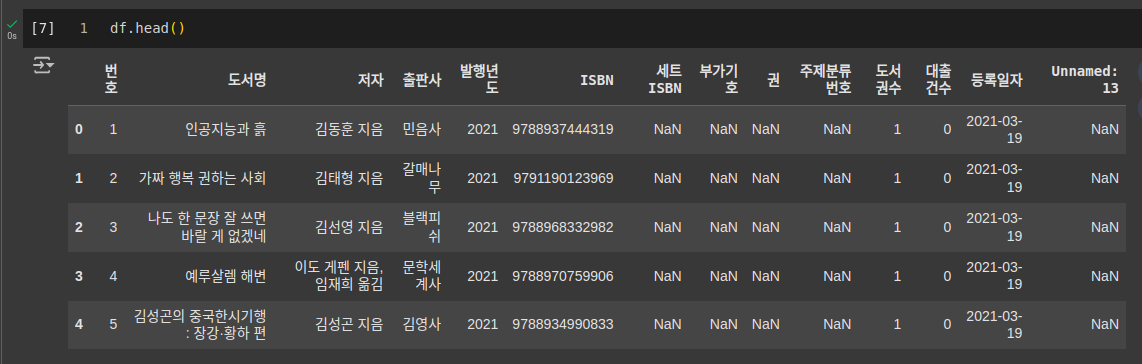
CSV 파일을 데이터프레임으로 읽기: read_csv() 함수
- low_memory 매개변수를 False로 지정
코드df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='EUC-KR', low_memory=False)
- 열의 데이터 타입을 자동으로 찾지 않도록 dtype 매개변수로 데이터 타입을 지정할 수 있음.
코드df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding='EUC-KR', dtype={'ISBN': str, '세트 ISBN': str, '주제분류번호': str})
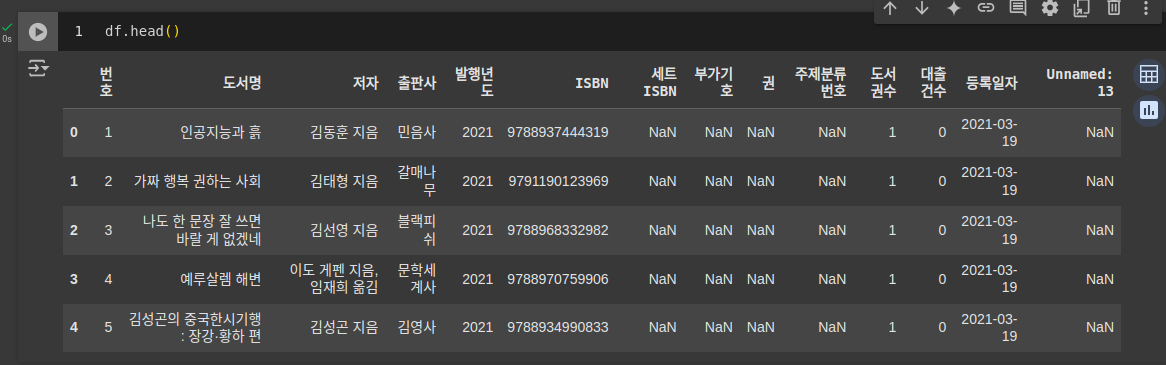
- head() 메서드 사용하여 데이터프레임의 처음 다섯 개 행을 확인
- header 매개변수 None으로 지정: csv 파일의 첫 행이 열 이름이 아닌 경우
- names 매개변수에 열 이름 리스트를 따로 전달, 중복된 이름이 있어서는 안됨
- Unnamed: 13열은 csv 파일이 올바르지 않은 경우에 생길 수 있음.
판다스의 read_table() 함수
- csv 파일을 읽을 때 read_table() 함수도 사용할 수 있음.
- 콤마 대신 탭으로 구분된 파일을 읽을 때 사용
- read_csv(sep='\t')과 동일
데이터프레임을 CSV 파일로 저장하기: to_csv() 메서드
코드df.to_csv('ns_202104.csv')
- 저장한 파일을 open() 함수로 확인

- 다시 데이터프레임으로 읽으면 인덱스가 중복 발생
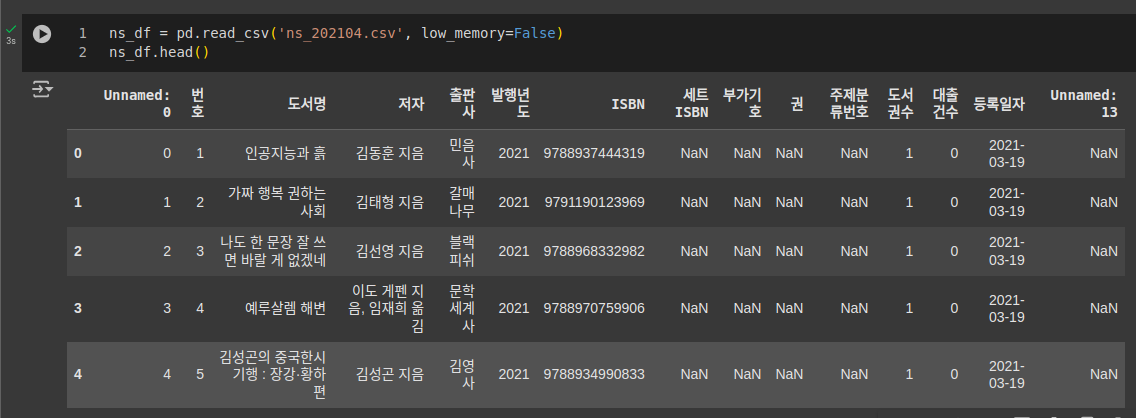
- index_col 매개변수를 사용하여 인덱스가 이미 있음을 알림.
코드ns_df = pd.read_csv('ns_202104.csv', index_col=0, low_memory=False) ns_df.head()
- 데이터프레임을 csv 파일로 저장할 때 인덱스 빼고 저장
코드df.to_csv('ns_202104.csv', index=False)
- 데이터프레임을 엑셀로 저장하기
코드ns_df.to_exel('ns_202104.xlsx', index=False)
- 한글 데이터의 경우 오류가 발생할 수 있어 xlsxwriter 패키지 사용
코드!pip install xlsxwriter ns_df.to_exel('ns_202104.xlsx', index=False, engine='xlsxwriter')
4) 공개 데이터 세트 대표 사이트와 유명 포럼
- 국내 사이트
- 공공데이터포털
- 통합 데이터 지도
- AI 허브
- 국가통계포털
- 해외 사이트
- 구글 데이터 세트 검색
- 캐글 데이터 세트
- 위키피디아 머신러닝 데이터 세트
- 아마존 웹서비스 오픈 데이터
- UCI 머신러닝 데이터 저장소
- 온라인 포럼
- 데이터 분석 커뮤니티
- 캐글 코리아
- 텐서플로 코리아
- 파이토치 코리아
- 사이킷런 코리아
[기본숙제]
p. 81의 확인 문제 4번 풀고 인증하기
- 판다스 read_csv() 함수의 매개변수 설명이 옳은 것은 무엇인가요?
답: 3번1) header 매개변수의 기본값은 1로 CSV 파일의 첫 번째 행을 열 이름으로 사용합니다.
=> header 매개변수의 기본값은 'infer'로 CSV 파일의 첫 번째 행을 열 이름으로 사용하고, header 매개변수를 1로 설정하면 CSV 파일의 두 번째 행을 열 이름으로 사용합니다.2) names 매개변수에 행 이름을 리스트로 지정할 수 있습니다.
=> names 매개변수에 열 이름을 리스트로 전달하여 지정할 수 있다.3) encoding 매개변수에 csv파일의 인코딩 방식을 지정할 수 있습니다.
4) dtype 매개변수를 사용하려면 모든 열의 데이터 타입을 지정해야 합니다.
=> dtype 매개변수로 특정 열의 데이터 타입을 지정할 수 있음.
[추가숙제]
p. 71 ~ 73 남산 도서관 데이터를 코랩에서 데이터프레임으로 출력하고 화면 캡처하기

42 Gyeongsan Learner